Ввод:
Subclassification(Wikipedia, Encyclopedia)
Результат:
Английский: Wikipedias are encyclopedias.
Немецкий: Wikipedien sind Enzyklopädien.Фонд Wikimedia представила новый энциклопедический проект — Абстрактную Википедию. Идея в том, что здесь пользователи вводят информацию в абстрактном виде, используя слова и сущности из Wikidata. Поскольку Wikidata представлена на разных языках, то и «абстрактный» текст становится доступным на всех языках, без необходимости в дополнительном переводе.
Это первый новый проект фонда Wikimedia за последние семь лет.
Wikidata (Викиданные) — это свободная совместно редактируемая база знаний обо всём на свете, доступная для чтения и редактирования как людьми, так и машинами. Хранилище проекта предоставляет данные на всех языках проектов Wikimedia и позволяет создать технологические условия для централизованного доступа к данным. База используется для обеспечения централизованного хранения данных, которые могут содержаться в статьях Википедии — например, интервики-ссылок, значков статусных статей и списков или статистической информации: дат рождения, численности населения и т. п.
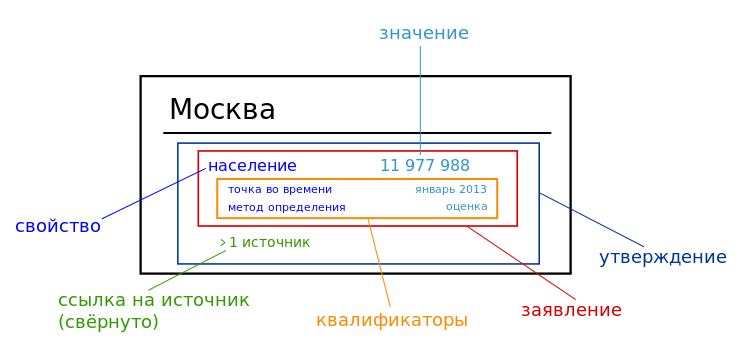
Терминология утверждений в Викиданных
Абстрактная Википедия — это фактически новый способ генерирования энциклопедического контента на нескольких языках. Авторы идеи считают, что она позволит большему числу авторов и читателей делиться большим количеством знаний на большем количестве языков.
Проект впервые предложен в 22-страничной статье Денни Врандечича (Denny Vrandečić), основателя Wikidata, в апреле 2020 года. Он выдвинул новую идею создавать контент, используя абстрактные обозначения, которые затем могут быть переведены на различные естественные языки, более равномерно «уравновешивая» контент независимо от вашего языка.

Пример двух предложений в Абстрактной Википедии с описанием Сан-Франциско, из статьи Денни Врандечича

Рендер на английский язык некоторых конструкторов из предыдущего примера, из статьи Денни Врандечича

Рендер на немецкий язык некоторых конструкторов из первого примера, из статьи Денни Врандечича
Денни Врандечич предложил проект для ввода информации в виде абстрактной нотации, а также инструмент под названием Wikilambda с набором функций, которые могут превратить нотацию в текст на естественном языке. По его мнению, проект не требует серьёзного прорыва в современных знаниях о генерации естественного языка или представлении лексических знаний.
Глобальная цель проекта в том, чтобы все версии Википедии, независимо от языка, приблизились по масштабу к англоязычной Википедии с точки зрения содержания.
В официальном объявлении упоминается, что это экспериментальный проект, который является особо ценным для некоторых сообществ, в то время как участники на других языках могут принимать меньшее участие в нём.
Теперь проект одобрен. После официального запуска волонтёры смогут переводить абстрактные «статьи» на свои языки с помощью программного инструмента. Врандечич присоединится к Фонду Wikimedia в качестве штатного сотрудника и возглавит эту инициативу.
Прототип инструмента Wikilambda для Абстрактной Википедии опубликован на GitHub.
См. также: «„Архив Интернета“ поставил новый рекорд трафика ресурса: 60 Гбит/с в любой момент»
