Comments 323
?
Чую где-то подвох, но не пойму где :)
P.S. А топик холиварный :)
P.S. А топик холиварный :)
результаты настолько неожиданны, правда?
Честно говоря не знаю, Smarty для меня как-то быстро промелькнул в паре проектов, не мною начатых, его быстродействие не оценивал, потом использовал нативные шаблоны. XSLT тоже пытался использовать и отказался тоже не из-за быстродействия. А единственный, имхо, недостаток нативных шаблонов — возможность из шаблона делать всё что угодно, — секурных проблем для наших проектов не представлял (смена шаблонов пользователями не планировалась), а разделение логики и представления осуществлялось силой воли и архитектурой :)
необходимость ручного экранирования данных — тоже недостаток
В шаблонах экранирование практически не использую, экранирую перед помещением данных в БД. Может не совсем верно идеологически, зато несомненный выигрыш в производительности — один заэкранировали при помещении данных вместо тысяч и миллионов раз при просмотре. Кстати, может поэтому такой неожиданный результат, что вы вручную экранируете данные при выводе?
ага, и в шаблон передаёшь переменные $name_for_html, name_for_js, name_for_url? x)
опять мимо %-) экранирование слабо влияет на результат.
опять мимо %-) экранирование слабо влияет на результат.
Для экранизации можно написать элегантное и красивое решение, это совершенно не проблема, мне кажется у смарти/пхп лучше будут обстоять дела с поддержкой нежели у xslt.
что за решение? о0
Вы не можете написать красивое решение для экранирования данных в пхп? я сомневаюсь. я к тому что Ваш аргумент что экранирование — недостаток не оправдан.
Выковырять из симфони sfOutputEscaper, например.
как он работает?
Заворачивает в себя объекты, переданные шаблону, и, используя магические методы на лету экранирует результаты, возвращаемые методами «обернутого» объекта.
То есть, в шаблоне, вы оперируете только инстансами sfOutputEscaper, получая доступ к данным через его магический метод.
www.symfony-project.org/gentle-introduction/1_4/en/07-Inside-the-View-Layer#chapter_07_output_escaping
То есть, в шаблоне, вы оперируете только инстансами sfOutputEscaper, получая доступ к данным через его магический метод.
www.symfony-project.org/gentle-introduction/1_4/en/07-Inside-the-View-Layer#chapter_07_output_escaping
а кто будет оборачивать? если шаблонизатор, то программист не сможет подсунуть сырые данные. если программист, то придётся вручную оборачивать все переменные.
В Symfony — оборачивается автоматически при передаче переменных из контроллера в вид.
Даже многомерные массивы?
а если нужно передать пользовательский хтмл без экранирования?
<?php echo $myObject->getUserHtml(ESC_RAW); ?>
проблема такого подхода в том, что формирование данных и принятие решения об отключении экранирования находятся в разных слоях. а значит существует риск рассинхронизации. например: программист не обезвредил данные, а верстальщик думает, что они безопасны для вставки.
Программист может запретить использование ESC_RAW и добавить настроить OutputEscaper таким образом, чтобы он не экранировал объект нужных классов.
Хотя, да, проблема такая может существовать. Мне проще, я верстальщик и программист в одном лице:)
Хотя, да, проблема такая может существовать. Мне проще, я верстальщик и программист в одном лице:)
В xslt разве такой проблемы не существует? Верстальщик пишет xslt, думает, что данные безопасны и использует disable-output-escaping=«yes», а php-программист их не обезвредил
Имея автоматический эскейпинг данных при подстановке, есть ли смысл заниматься этим на уровне PHP, одновременно насильно отключая output-escaping?
Если кто-то не в курсе про последствия вставки произвольного/нефильтрованного HTML кода (XSS) — это его личное упущение, будь он хоть верстальщик, хоть разработчик.
Если кто-то не в курсе про последствия вставки произвольного/нефильтрованного HTML кода (XSS) — это его личное упущение, будь он хоть верстальщик, хоть разработчик.
Может я на столько банален и туп, но я всегда экранирую данные тольк при непосредственном показе их… не важно где они их показывают, в смарти значит |escape в пхп значит htmlspechialchars, в друхих другое… я вообще к чему веду — дайте ключевому звену решить нужно ли экранирование или нет, он ведь последний!
Я про другую ситуацию: нужно было вставлять неэкранированные данные (например шаблону передаётся уже готовый html из доверенного источника), верстальщик отключил экранирование (в смарти, пхп, ксслт — не важно), потом задача расширилась и в шаблон стало возможным попадание html-кода из недоверенных источников, но верстальщику об этом не сообщили.По-моему, вероятность такой ситуации не зависит от используемого шаблонизатора.
не существует. верстальщику никогда не нужно отключать экранирование потому как в случае безопасных данных программист передаёт ему дерево, а не строку. и это дерево он может дополнительно разукрасить. например — добавить какую-нибудь финтифлюшку у заголовков первого уровня.
данные сначала могут быть безопасными и передаваться строкой (->setParameter() ), а не деревом, а потом стать опасными — неужели не видите возможности рассинхронизации?
а готовый хтмл передаётся в виде dom-дерева
как в случае безопасных данных программист передаёт ему дерево
однако это само по себе ещё не меняет сути уязвимости к вставке вредоносного кода
В смарти — используй модификаторы и пользовательские функции и будет все красиво.
На быстродействие конечно влияет но не на столько критично чтобы этим пренебрегать… Для радикального решения быстродействия используй механизмы кеширования, храниения данных в оперативке и т д… (куча технологий для этого есть)
На быстродействие конечно влияет но не на столько критично чтобы этим пренебрегать… Для радикального решения быстродействия используй механизмы кеширования, храниения данных в оперативке и т д… (куча технологий для этого есть)
может дело в том как предоставлены данные?
всегда можно изменить некий набор символов лишь для того чтоб код одного примера выглядел «нужней» чем код другого примера…
всегда можно изменить некий набор символов лишь для того чтоб код одного примера выглядел «нужней» чем код другого примера…
а что не так с представлением данных? о0
Есть еще один вариант: берем данные отсортированные нужным образом и отдаем их клиенту, затем с помошью ЖС строим элегантно и красиво (а главное быстро) дерево. Смарти ведь не используют из-за скорости. А о элегантности у каждого свое мнение, не стоит на это давить.
перенести половину шаблонизации на js — совсем некрасивое решение
Это другое решение а не некрасивое, и оно, как и все остальные решения, имеет право на жизнь, может еще и на хабре кнопочка «обновить каменты» — плохое решение? это ведь шаблонизация с помошью JS в чистом виде… Вообще шаблонизация в JS не было смысловой нагрузкой в моем каменте, я про элегантность и простоту. Смарти используют не из-за элегантности, это простое и гибкое решение, с одной стороны оно не лишено недостатков, но с другой оно очень удобно и просто… а еще оно позволяет преображать данные в любой желаемой форме, чего по сути лишено (покрайней мере я не знаю решения) XSLT
да, плохое. я бы хотел, чтобы она нажималась автоматически при появлении новых сообщений.
просто и гибко — это и есть элегантно. посмотри на вывод дерева в смарти и в хслт. скажешь в смарти легко/просто/эелегантно/быстро или хоть что-нибудь ещё?
просто и гибко — это и есть элегантно. посмотри на вывод дерева в смарти и в хслт. скажешь в смарти легко/просто/эелегантно/быстро или хоть что-нибудь ещё?
У Вас волшебная возможность изменять смысл моих слов :)
Про хабр я имел ввиду шаблонизацию JS, каменты строятся при нажатии на кнопку с помошью JS.
Да, XSLT красиво выглядит, но на сколько я видел в коде, вы ему уже отдаете дерево, это двойная работа, сперва построить дерево, а потом по нему проходимся и показываем его… можно отдать чистые данные в смарти/пхп, и там уже строить дерево внутри.
Код в пхп/смарти выглядит страшней потому как в хтмл находятся вставки кода, как ни крути этого в серверных языках не избежать стандартными способами, поэтому кажется страшней, но на мой взгляд это не плохо.
Про хабр я имел ввиду шаблонизацию JS, каменты строятся при нажатии на кнопку с помошью JS.
Да, XSLT красиво выглядит, но на сколько я видел в коде, вы ему уже отдаете дерево, это двойная работа, сперва построить дерево, а потом по нему проходимся и показываем его… можно отдать чистые данные в смарти/пхп, и там уже строить дерево внутри.
Код в пхп/смарти выглядит страшней потому как в хтмл находятся вставки кода, как ни крути этого в серверных языках не избежать стандартными способами, поэтому кажется страшней, но на мой взгляд это не плохо.
вот именно что всю шаблонизацию. а не половину. да и всё-равно xslt тут был бы эффективней
тесты показывают, что эта двойная работа не так уж и много времени занимает в отличие от одинарной работы смарти
это усложняет поддержку — это плохо
тесты показывают, что эта двойная работа не так уж и много времени занимает в отличие от одинарной работы смарти
это усложняет поддержку — это плохо
В данном случае XSLT вообще не эффективен так как каменты вставляются в разные места страницы, с этим JS стравляется лучше всего
тесты показывают что рекурсия в пхп отрабатывает не лучшим образом, и прибегать к ней дважды не стоит
поддержку усложняет не встраиваемый код, а плохо написанный код, а это не одно и то же, можно встроить пхп код в XTML так что он будет не так уж и плохо читаем
тесты показывают что рекурсия в пхп отрабатывает не лучшим образом, и прибегать к ней дважды не стоит
поддержку усложняет не встраиваемый код, а плохо написанный код, а это не одно и то же, можно встроить пхп код в XTML так что он будет не так уж и плохо читаем
Если мне нужно обработать строки в шаблоне? Допустим мне нужно длинные строки обрезать до 100 символов и добавить троеточие, как это сделать в XSLT? Можно ли в XSLT применять свои функции/классы для обработки данных?
шаблонизация и вставка элементов на страницу — перпендикулярные понятия
поэтому вместо простой рекурсии мы будем городить стековый велосипед?
любой код со временем растёт. это факт. как бы ты не написал код вначале, после 10 переделок там будет каша.
не надо обрабатывать строки в шаблоне. впрочем, это не сложно. и свои функции добавлять можно.
поэтому вместо простой рекурсии мы будем городить стековый велосипед?
любой код со временем растёт. это факт. как бы ты не написал код вначале, после 10 переделок там будет каша.
не надо обрабатывать строки в шаблоне. впрочем, это не сложно. и свои функции добавлять можно.
Вставка камента — шаблонизация, потому как камент имеет структуру хтмл кода, и как ни крути, его нужно должным образом обработать перед вставкой в дерево каментов
вместо двух рекурсий можно использовать одну
лююой код растет, и когда он начинает превращаться в кашу, можно сделать рефакторинг, написать несколько функций для скрытия функционала итд, Ваш XSLT шаблон тоже будет расти, и не факт что в кашу он не превратится
вместо двух рекурсий можно использовать одну
лююой код растет, и когда он начинает превращаться в кашу, можно сделать рефакторинг, написать несколько функций для скрытия функционала итд, Ваш XSLT шаблон тоже будет расти, и не факт что в кашу он не превратится
>Можно ли в XSLT применять свои функции/классы для обработки данных?
Можно — www.php.net/manual/en/xsltprocessor.registerphpfunctions.php
Можно — www.php.net/manual/en/xsltprocessor.registerphpfunctions.php
> Результат: 3 + 5 = 8
Что эти цифры означают?
Что эти цифры означают?
Тут ключевое слово «производительность», которое подразумевает цифры, графики или хотя бы объяснение критериев по которым эта самая производительность оценивалась, а 3+5 или 1 + 200 как-то не очень наглядны для человека «из вне».
Что касается субъективной оценки 2х технологий, то я бы в любом случае предпочел XSLT, т.к. это стандарт, рекомендованный W3C и имеющий официальную поддержку консорциума, как минимум.
Что касается субъективной оценки 2х технологий, то я бы в любом случае предпочел XSLT, т.к. это стандарт, рекомендованный W3C и имеющий официальную поддержку консорциума, как минимум.
а разве не очевидно, что это время? о_0"
//Что касается субъективной оценки 2х технологий, то я бы в любом случае предпочел XSLT, т.к. это
//стандарт, рекомендованный W3C и имеющий официальную поддержку консорциума, как минимум.
А что и с чем вы сравниваете?
//стандарт, рекомендованный W3C и имеющий официальную поддержку консорциума, как минимум.
А что и с чем вы сравниваете?
>Что касается субъективной оценки 2х технологий, то я бы в любом случае предпочел XSLT, т.к. это стандарт, рекомендованный W3C и имеющий официальную поддержку консорциума, как минимум.
В топике всё-таки 3 технологии сравнивается (хотя в заголовок и вынесено только две), в защиту Smarty сказать мне нечего, кроме того, что он близок к PHP, а вот native PHP vs XSLT… Необходимость введения дополнительного слоя с не самой простой, мягко говоря, технологией достаточно далёкой и от HTML, и, тем более, от PHP в небольших проектах, которые вряд ли будут мигрировать на другие языки, весьма сомнительна, по-моему.
В топике всё-таки 3 технологии сравнивается (хотя в заголовок и вынесено только две), в защиту Smarty сказать мне нечего, кроме того, что он близок к PHP, а вот native PHP vs XSLT… Необходимость введения дополнительного слоя с не самой простой, мягко говоря, технологией достаточно далёкой и от HTML, и, тем более, от PHP в небольших проектах, которые вряд ли будут мигрировать на другие языки, весьма сомнительна, по-моему.
а что там такого непростого в этой технологии? о0
На императивное (читай — привычное большинству PHP разработчиков) программирование мало похоже. Согласитесь, что чтобы связать HTML-код верстальщика и PHP-код программиста, знаний и опыта для связки их через XSLT нужно поболее, чем внедрить PHP-код (или конструкции Smarty) в HTML. Кроме того, эффективные XSLT шаблоны предполагают же ещё и хорошее знание XPath?
А может просто XSLT мало приспособлен к самостоятельному изучению по спецификации сразу на живых проектах, дедлайны которых не за горами, а поправить или наставить на путь истинный некому. Или я такой тупой, что попытки использования XSLT приводили к шаблонам в разы большим исходного HTML с километровыми XPath-выражениями или такой тупой, что счёл это неприемлемым :-/ А может стоило попробовать новый движок в PHP5 — в том, что был в PHP4 кажется (давно это было) спецификация поддерживалась не полностью
P.S. А идея языка красивая, духом сразу проникся, учебные примеры завораживали, а вот как дошло до практики… :(
А может просто XSLT мало приспособлен к самостоятельному изучению по спецификации сразу на живых проектах, дедлайны которых не за горами, а поправить или наставить на путь истинный некому. Или я такой тупой, что попытки использования XSLT приводили к шаблонам в разы большим исходного HTML с километровыми XPath-выражениями или такой тупой, что счёл это неприемлемым :-/ А может стоило попробовать новый движок в PHP5 — в том, что был в PHP4 кажется (давно это было) спецификация поддерживалась не полностью
P.S. А идея языка красивая, духом сразу проникся, учебные примеры завораживали, а вот как дошло до практики… :(
переделывать проект на другую идеологию — неблагодарное занятие %-) особенно когда ещё не знаешь как делать…
Переделывания не было, была попытка использовать XSLT в проекте с самого начала. Пока разрабатывалась и тестировалась логика с простейшим html выводом только основного контента без всякого оформления и «контекстных сайдбаров» всё было нормально, но как началось «натягивание» реального дизайна… В общем пришлось в авральном порядке отказываться от использования XML+XSLT и переходить на native PHP шаблоны (благо они использовались для формирования исходного XML, а не DOM собиралась динамически как у вас в примерах :) )
а какие там сложности с сайдбарами? о0
Судя по всему у вас XML нескладный вышел, раз такие траблы с обработкой начались
О, узрел знакомые лица.
tenshi, запакуй исходники из теста куда-нибудь и дай поиграть. Авось другие результаты получятся :)
tenshi, запакуй исходники из теста куда-нибудь и дай поиграть. Авось другие результаты получятся :)
PHP:
total(усредненно за 20 пробегов): 93
Smarty:
total(усредненно за 20 пробегов): 970
XSLT:
total(усредненно за 20 пробегов): 90
Вывод- молодцы те люди, что писали php_xsl.dll.
total(усредненно за 20 пробегов): 93
Smarty:
total(усредненно за 20 пробегов): 970
XSLT:
total(усредненно за 20 пробегов): 90
Вывод- молодцы те люди, что писали php_xsl.dll.
а ведь есть ещё XSL Cache Extension… :-]
кто потестит XSLT на стероидах?
кто потестит XSLT на стероидах?
Тестил, толку ноль. Зато очень хорошо кушает процессорное время.
По логике, то как описал разработчик XSL Cache должно было бы работать на ура, но по тестам получил несколько иной результат. На скорости рнедеринга вообще никак не отразилось или просто это не заметно на 100к запросах.
Советую использовать родной php_xsl и не заморачиваться. А кеши, если уж так надо хранить уже в готовом виде.
По логике, то как описал разработчик XSL Cache должно было бы работать на ура, но по тестам получил несколько иной результат. На скорости рнедеринга вообще никак не отразилось или просто это не заметно на 100к запросах.
Советую использовать родной php_xsl и не заморачиваться. А кеши, если уж так надо хранить уже в готовом виде.
Использую XSL Cache
Насчет толку ноль — неправда
производительность в конкретном моем случае повышается где то на 10%
Насчет толку ноль — неправда
производительность в конкретном моем случае повышается где то на 10%
Возможно зависит от сложности XSLT шаблона… я тестил на простой страничке без излишеств. Но ради 10% производительности, отдавать на 40% процессорного времени больше я не готов, поэтому кеширую уже готовые страницы и раздаю через nginx — это дает более ощутимый прирост. Но кеш только на пару десятков страниц который в топе по просмотрам, остальное формируется динамично.
У меня в одном проекте он тоже использовался. Замеры я не делал, но так понял что суть этого расширения в том, что XSLT шаблон не парсится при каждом
а загружается из кешированного бинарного представления. Само преобразование происходит все тем же стандартным libxml и вряд ли его скорость поменяется.
В общем это своего рода opcode кеш для xslt как тот же xCache или APC для PHP
$xsl->load( 'tpl.xsl' );
$proc= new XSLTProcessor( );
$proc->importStyleSheet( $xsl );а загружается из кешированного бинарного представления. Само преобразование происходит все тем же стандартным libxml и вряд ли его скорость поменяется.
В общем это своего рода opcode кеш для xslt как тот же xCache или APC для PHP
Смотрю я на это и у меня тока одна мысль:
WTF? FAIL? EPIC FAIL?!
WTF? FAIL? EPIC FAIL?!
На сколько я знаю синтаксис смарти, то в конструкции
{foreach from=$childs item=child}в каждой итерации происходит включение файла tpl.smarty из ФС сервера. Просмотрев исходный код для XSLT я подобных вещей не обнаружил, как вы этот момент прокомментируете? Оверхэд I/O операций мог дать то самое замедление относительно XSLT.
{include file='tpl.smarty' color=$child.color shape=$child.shape childs=$child.childs}
{/foreach}
смарти настолько «умный» что загружает шаблон каждый раз заново? х) впрочем, я тоже первым делом подумал на инклуды, но даже без них отставание на порядок.
смарти настолько «умный» что загружает шаблон каждый раз заново?Судя по коду, нет, но должен быть выставлен параметр ['smarty_once'], если есть — то файл грузится как include_once, если нет, то как include.
тогда он и исполнится один раз и тогда рекурсия станет бесконечной %-)
Да, я спутал include и include_php в коде смарти. А вообще — вы ведь измеряли время вывода шаблона на экран, а вот кэширование вызовом $smarty->caching = true; не включили, для скомпилированных шаблонов время может быть другим. Имеется в виду, что смарти с выключенным кэшем вряд-ли будет использоваться в настоящем проекте.
Оно не будет быстрее голого php.
Однако переучивать дизайнеров и верстальщиков дорогого стоит. Посему- пока невозможно. Эхх.
Однако переучивать дизайнеров и верстальщиков дорогого стоит. Посему- пока невозможно. Эхх.
наоборот %-) кеширование вывода наврятли кто-либо вообще включает. разве что что на статичных сайтах-визитках.
Так оно ж не вечное. Поставил лимит в 20 минут и будь уверен, что 20 минут нагрузку не жди.
PS: Нафиг на сайтах-визитках вообще шаблонизатор? :D
PS: Нафиг на сайтах-визитках вообще шаблонизатор? :D
ага, добавил коммент к статье, а появится он только через 20 минут %-)
Я немного не в статьях. Да и мыслить категориями страниц имхо прошлый век. В умах людей во всю эпичное блочное кэширование и вся сила его с нами.
Как оно у меня: есть страница, побитая на блоки(назовём её главная). В странице три динамических элемента и туева хуча настраиваемых(телефоны, тайтлы, тексты). Так зачем нам по 6 тысяч раз на дню псевдо-статику перерисовывать при том, что мы знаем, что она редко изменяется? Такие части сохраняются в кэш и успешно из него тыкаются, пока кто-то что-то на псевдо-статике не изменит. Получается шустро.
Как оно у меня: есть страница, побитая на блоки(назовём её главная). В странице три динамических элемента и туева хуча настраиваемых(телефоны, тайтлы, тексты). Так зачем нам по 6 тысяч раз на дню псевдо-статику перерисовывать при том, что мы знаем, что она редко изменяется? Такие части сохраняются в кэш и успешно из него тыкаются, пока кто-то что-то на псевдо-статике не изменит. Получается шустро.
и когда изменит — извольте ждать появления изменений 20 минут.
А что мешает при сохранении нового контента обновлять кеш? Вроде многие системы именно так и делают.
вот именно ;-) так какой смысл кэшировать на 20 минут?
редко, но метко. кеширование по времени — глупость несусветная
участвовал в 3? а что?
и почему же это глупо, о, великий гуру?
если кеш не мешает — почему бы его и не похранить?
кеширования чего? ленты новостей?
если кеш не мешает — почему бы его и не похранить?
кеширования чего? ленты новостей?
очень просто — пока никто не пытается его стереть, значит не мешает %-)
для меня дикость — слушать эти банальности от человека который не в теме :-Р
например, затем, что каждый комментарий — это дополнительный шанс, что он нажмёт кнопку «зарегистрироваться, чтобы ответить». а вообще, мне не нравится этот фашизм по отношению к незарегистрированным пользователям. экономия от этого мизерная получается.
да-да, я дурак, не спорь со мной *о*
кэш — не мусор. одноразовые данные в нём ничего не забыли.
для меня дикость — слушать эти банальности от человека который не в теме :-Р
например, затем, что каждый комментарий — это дополнительный шанс, что он нажмёт кнопку «зарегистрироваться, чтобы ответить». а вообще, мне не нравится этот фашизм по отношению к незарегистрированным пользователям. экономия от этого мизерная получается.
да-да, я дурак, не спорь со мной *о*
кэш — не мусор. одноразовые данные в нём ничего не забыли.
Оставлять в оперативе то, что не понадобилось в последние несколько часов — тоже глупость.
не использовать свободную память — ещё большая
Ну так и вопрос как раз в том, что бы найти оптимальное время жизни кеша, зависящее от частоты обращения к оному.
а почему не в том, как сделать нормальную инвалидацию?
Инвалидация по времени — это тоже инвалидация. Я же не говорю, что ttl шаблона исключает другие варианты инвалидации.
Просто это удобный способ выкинуть из кеша то, что не может быть полностью контролируемым. Например, помещенный в кеш шаблон может стать неактуальным из-за того, что мы удалим физический шаблон (т.е. решили убрать эту страницу как таковую). Так как это действие происходит вне рамок движка, то и инвалидировать другими методами мы не сможем. Единственное — это в случае обращения к этому шаблону. Но если обращений не будет, то по вашему (с безлимитным ttl) этот шаблон будет жить в кеше вечно.
Просто это удобный способ выкинуть из кеша то, что не может быть полностью контролируемым. Например, помещенный в кеш шаблон может стать неактуальным из-за того, что мы удалим физический шаблон (т.е. решили убрать эту страницу как таковую). Так как это действие происходит вне рамок движка, то и инвалидировать другими методами мы не сможем. Единственное — это в случае обращения к этому шаблону. Но если обращений не будет, то по вашему (с безлимитным ttl) этот шаблон будет жить в кеше вечно.
а обновлять кеш при добавлении слабо ?)
Зря вы так считаете, у смарти гибкие возможности работы с кэшем, с учетом инвалидации, удаления только части кэшированного и возможностью оставить часть кэшированной страницы динамической.
супер. ковыряться с настройкой частичного кэширования и инвалидацией только чтобы догнать по скорости xslt x)
ковыряться с настройкой частичного кэширования и инвалидациейВы так говорите, как будто это что-то плохое. Профит на выходе может оказаться намного выше, в прямопропорционально нагрузке на ваш проект.
откуда взяться профигу, если по тестам кеширование еле-еле хватает на то, чтобы справиться с привнесёнными смарти задержками?
Обожаю троллей, они вместе с рекламой двигают человечество вперед :) Где у вас в тестах кэширование?
Да, мне вообще напомнило рекламу:
«Поместим обычную газету в соляную кислоту, а журнал ТВ-Парк в дистилированную воду...».
Каков же результат? — «Ваши волосы будут мягкими и шелковистыми!»
А суть такова, что во всех трёх вариантах используются разные алгоритмы. Если в нативном PHP тоже использовать include вместо обычной рекурсивной функции, результат вполне может оказаться еще более неожиданным O_o
«Это пульс. А вот палец. Далеко от пульса и глубоко в заднице. Вы любите зефир в шоколаде?»
Я не за какую-то технологию. Я за чистоту эксперимента!
«Поместим обычную газету в соляную кислоту, а журнал ТВ-Парк в дистилированную воду...».
Каков же результат? — «Ваши волосы будут мягкими и шелковистыми!»
А суть такова, что во всех трёх вариантах используются разные алгоритмы. Если в нативном PHP тоже использовать include вместо обычной рекурсивной функции, результат вполне может оказаться еще более неожиданным O_o
«Это пульс. А вот палец. Далеко от пульса и глубоко в заднице. Вы любите зефир в шоколаде?»
Я не за какую-то технологию. Я за чистоту эксперимента!
а с какого фига алгоритмы должны быть одинаковыми? каждая технология используется по максимуму возможностей, как в реальных условиях.
как на смарти убрать рекурсию?
предлагаешь включить кеширование для всех и получить в результате одинаковое число попугайчиков? х)
предлагаешь включить кеширование для всех и получить в результате одинаковое число попугайчиков? х)
Наверное, лучше просто нормально реализовать рекурсию в Smarty 3 без инклюдов:
{function name="tree"}
{foreach $pages as $page}
<li>
<span>{$page.name}</span>
{if $page.childs}<ul>{tree pages=$page.childs}</ul>{/if}
</li>
{/foreach}
{/function}
<ul id="pages-tree" class="filetree">
{tree pages=$tree}
</ul>
Fatal error: Smarty error: [in tpl.smarty line 1]: syntax error: unrecognized tag 'function' (Smarty_Compiler.class.php, line 590)
Стоит быть немного более внимательным: Smarty 3 (три).
включите кеширование
не думаете, что это уже будут не очень равные условия?
Нет, Вы явно заблуждаетесь. И я привел конкрентый пример, почему это так.
Вы заставляете Smarty каждый раз инклудить шаблон (сомневаюсь, что это не так), когда нативный код использует обычную рекурсивную функцию. Ну и как Вы это сравниваете?
Давайте тогда сравним скорость работы винчестера и оперативной памяти. Да пусть даже кэша винчествера. Все равно скорости не сопоставимы. Отсюда и полученные цифры.
А Вы бы написали для Smarty плагинчик, который реализовывал рекурсивную функцию. Или нативный шаблон запустили через include(). И тогда бы мы посмотрели, что вышло…
В конце концов, мы не бараны, чтобы биться рогами об забор и для каждого конкретного случая лучше использовать именно тот подход, который будет наиболее подходящим.
Например в Джумле рекурсивное меню вообще строиться по средствам SimpleXML ))) Просто разработчики решили, что так будет наиболее оптимально по каким-то их критериям. Но это уже их дело.
А что касается конкретно построения рекурсивных менюх, то тут вполне естественно пользоваться нативными коммандами и не городить огород. А если уж городить, то еще подумать, как можно сделать лучше.
Вы заставляете Smarty каждый раз инклудить шаблон (сомневаюсь, что это не так), когда нативный код использует обычную рекурсивную функцию. Ну и как Вы это сравниваете?
Давайте тогда сравним скорость работы винчестера и оперативной памяти. Да пусть даже кэша винчествера. Все равно скорости не сопоставимы. Отсюда и полученные цифры.
А Вы бы написали для Smarty плагинчик, который реализовывал рекурсивную функцию. Или нативный шаблон запустили через include(). И тогда бы мы посмотрели, что вышло…
В конце концов, мы не бараны, чтобы биться рогами об забор и для каждого конкретного случая лучше использовать именно тот подход, который будет наиболее подходящим.
Например в Джумле рекурсивное меню вообще строиться по средствам SimpleXML ))) Просто разработчики решили, что так будет наиболее оптимально по каким-то их критериям. Но это уже их дело.
А что касается конкретно построения рекурсивных менюх, то тут вполне естественно пользоваться нативными коммандами и не городить огород. А если уж городить, то еще подумать, как можно сделать лучше.
я заставляю его применить один шаблон к разным данным. зачем он делает при этом инклуды? почему бы при компиляции не слить все в один файл? а писать хелпер для каждого инклуда, чтобы обмануть тупой алгоритм — не вариант.
вот в quicky сделали блок {helper}. молодцы. смотрится по уродски и в 2 раза медленней xslt.
а нативный код тут приведён только для того, чтобы показать каким быстрым мог бы быть смарти, если бы был написан по уму. но он написано через задницу и фейлит всю производительность.
что за нативные команды?
вот в quicky сделали блок {helper}. молодцы. смотрится по уродски и в 2 раза медленней xslt.
а нативный код тут приведён только для того, чтобы показать каким быстрым мог бы быть смарти, если бы был написан по уму. но он написано через задницу и фейлит всю производительность.
что за нативные команды?
Ну дело в том, что Смарти делает ровным счетом то, что ему говорят.
Сказано приинклудить — он будет инклудить. Таким способом Вы и осуществляете рекурсию в шаблоне, верно? Ведь при компиляции Смарти еще ничего не знает, на сколько глубокой эта рекурсия будет и сколько раз ему необходимо включить этот файл в шаблон.
Другой путь, которым могли пойти разработчики Смарти — это кэшировать шаблон в переменную. Потом дополнять этот код кодом с переменными и после евалить. Но этот путь еще более тернист и опасен, чем простое включение инклуда.
Так что разработчики все правильно сделали. А нам лишь остается забивать молотком гвозди, а не крошить черепа!
PS1: Возьмите и откройте файл Smarty.class.php на строке 1869 и Вы увидите тот самый инклуд, который и вызвал негодование цифр этого теста.
PS2: native command — родная команда — в нашем случае чистый PHP.
Сказано приинклудить — он будет инклудить. Таким способом Вы и осуществляете рекурсию в шаблоне, верно? Ведь при компиляции Смарти еще ничего не знает, на сколько глубокой эта рекурсия будет и сколько раз ему необходимо включить этот файл в шаблон.
Другой путь, которым могли пойти разработчики Смарти — это кэшировать шаблон в переменную. Потом дополнять этот код кодом с переменными и после евалить. Но этот путь еще более тернист и опасен, чем простое включение инклуда.
Так что разработчики все правильно сделали. А нам лишь остается забивать молотком гвозди, а не крошить черепа!
PS1: Возьмите и откройте файл Smarty.class.php на строке 1869 и Вы увидите тот самый инклуд, который и вызвал негодование цифр этого теста.
PS2: native command — родная команда — в нашем случае чистый PHP.
они могли бы как минимум превращать все шаблоны в функции и сливать их в один файл.
ещё раз: такие цифры вызваны НЕ инклудами.
я не хочу поддерживать такие шаблоны, где используются «родные команды»
ещё раз: такие цифры вызваны НЕ инклудами.
я не хочу поддерживать такие шаблоны, где используются «родные команды»
я заставляю его применить один шаблон к разным данным. зачем он делает при этом инклуды? почему бы при компиляции не слить все в один файл? а писать хелпер для каждого инклуда, чтобы обмануть тупой алгоритм — не вариант.
Это кстати очень важное утверждение. XSLT — язык функциональный а потому, процессор точно знает что, когда и как вызывать / применять. Простой пример, возьмите и приинклудьте документ в XSLT, к примеру так:
Что сделает процессор когда он наткнется на эту инструкцию? Ничего! Вообще ничего, файл даже не будет прочитан с диска, а вот если где нибудь в шаблоне вы сделаете что нибудь типа:
Вот в этот момент файл будет запрошен )))
Другая ситуация, в шаблоне:
Документ будет загружен единожды, и даже если его состояние изменилось, получить мы сможем только первое, потому как единожды вычисленное повторному вычислению не подвергается, никогда! Мне кажется именно эти функциональные фишки и делают XSLT удобным, гибким и расширяемым средством, для создания шаблонизации.
Это кстати очень важное утверждение. XSLT — язык функциональный а потому, процессор точно знает что, когда и как вызывать / применять. Простой пример, возьмите и приинклудьте документ в XSLT, к примеру так:
Что сделает процессор когда он наткнется на эту инструкцию? Ничего! Вообще ничего, файл даже не будет прочитан с диска, а вот если где нибудь в шаблоне вы сделаете что нибудь типа:
Вот в этот момент файл будет запрошен )))
Другая ситуация, в шаблоне:
Документ будет загружен единожды, и даже если его состояние изменилось, получить мы сможем только первое, потому как единожды вычисленное повторному вычислению не подвергается, никогда! Мне кажется именно эти функциональные фишки и делают XSLT удобным, гибким и расширяемым средством, для создания шаблонизации.
Инклуды на каждом шаге в смарти можно и убрать:
плагин напиши.
плагин напиши.
на реальных шаблонах (больших) XSLT жуткий тормоз, с увеличением шаблонов скорость падает гораздо быстрее чем у смарти и, тем более, натива
Увеличил до 4 тысяч интераций. Пропорции результата те же.
Может быть разовьем идею тестов и вы покажите действительно сложный шаблон, на котором будет иметь место проводить тесты?
Может быть разовьем идею тестов и вы покажите действительно сложный шаблон, на котором будет иметь место проводить тесты?
Меня вот с иной стороны подход к вопросу интересует, а как у XSLT-преобразования в качестве шаблонизатора с гибкостью? Если взять смарти — тут пост- / препроцессор, фильтры и т.п., а как с этим у XSLT? Плюс есть ли какой-либо аналог системы плагинов? Просто скорость на голых тестах это одно, а скорость разработки и ее удобство — немного другое.
xslt может шаблонизировать даже сам себя х)
а вам для чего всё это нужно?
а вам для чего всё это нужно?
«Для себя интересуюсь». Постпроцессинг помогает в тех случаях, когда нужно обрабатывать уже готовый HTML, как простейший пример — редирект всех исходящих ссылок через собственный срипт, когда в руки попал уже готовый движок. Могу еще придумать.
а если готовый движок не на смарти — что будешь делать?
давай ещё %-)
давай ещё %-)
редирект исходящих ссылок можно на xslt сделать как то так
<code>
<xsl:template match="a[not(starts-with(@href, 'http://our-domain') and starts-with(@href, 'http://')]">
<a href="http://our-domain/our-regirect-script?p={@href}">
<xsl:apply-templates/>
</a>
</xsl:template>
</code>Лучше тогда сказать: преобразовывать XSL шаблоны (как любое другое подмножество XML) с помощью XSL шаблонов.
Но на самом деле это не всегда будет разумным решением.
Но на самом деле это не всегда будет разумным решением.
таким образом можно упростить и расширить синтаксис xsl, что сделает его более дружелюбным.
например:
[?v ../@title ?]
можно развернуть в:
[xsl:value-of select=" ../@title " /]
например:
[?v ../@title ?]
можно развернуть в:
[xsl:value-of select=" ../@title " /]
Где-то я уже подобное видел…
dklab.ru/lib/Dklab_ShortXSLT/
Но, честно говоря, никакого смысла не вижу в подобных «оптимизациях». XSL — стандарт, так и надо работать со стандартом, а не надстраивать собственный диалект.
dklab.ru/lib/Dklab_ShortXSLT/
Но, честно говоря, никакого смысла не вижу в подобных «оптимизациях». XSL — стандарт, так и надо работать со стандартом, а не надстраивать собственный диалект.
Если вам того надо, существует exslt с кучей разных функций (есть даже своеобразная имплементация замыканий). Но практика показывает, что это практически никогда не требуется.
неужто пост-препроцессоры и фильтры входят в задачи шаблонизации?
Насчет гибкости и плагинов www.exslt.org/ но, IMHO, и без них неплохо
Насчет гибкости и плагинов www.exslt.org/ но, IMHO, и без них неплохо
Увеличте не кол-во итераций, а сложность шаблона, вашу! Никто не делает сайты с выводом блока 100 раз, шаблоны более сложные, с большим кол-вом элементов.
Я это понимаю. Потому и попросил пример со сложным шаблонам. Так уж получилось, что голова пока не мыслит не о каких трансформациях. Да, есть xml- с ним приятно работать как с callback`ами, есть html- на нём все собаку сьели, есть xslt, о котором много говорят, но в моей сфере он используется лишь в одном проекте(однако и в нём есть быстрая кнопка-'хочу smarty').
Зачем же кричать?
Зачем же кричать?
может нарисуешь такой?
м… есть тесты? *о*
XSLT на больший объёмах сильно много памяти есть, об этом тоже надо помнить когда выбираешь технологию.
м… новая страшилка %-) ждите следующую статью *о*
Так не надо лепить один огромный шаблон, весом в мегабайты. И подавать на вход преобразования всё содержимое БД разом, в надежде, что XPath вам заменит SQL.
>Так не надо лепить один огромный шаблон, весом в мегабайты.
А как надо, если, например, вес итогового HTML те самые мегабайты?
А как надо, если, например, вес итогового HTML те самые мегабайты?
пожалейте браузер…
Я жалею пользователя :) Очень бесит пагинация, когда хочется/нужно смотреть файл целиком
сделайте ему загрузку по мере прокрутки
Имхо, очень нетривиальная задача (с полноценной навигацией по анчорам), а главное исключает возможность «оффлайнового» просмотра. То есть достоинства есть только для случайных посетителей, а для неслучайных всё равно весь документ нужно грузить. А при нормальной вёрстке браузер и так начнёт показывать контент как только он начнёт приходить от сервера
Хотите сказать, существенно бОльшую часть в объёме итоговой страницы занимает разметка, а не собственно данные? Интересные, должно быть, страницы…
Интересно посмотреть какие будут результаты Blitz vs Smarty vs XSLT. Попробую провести тест на досуге. Сам привык к Blitz и чисто интуитивно мне кажется он быстрее Smarty, хотя могу ошибаться

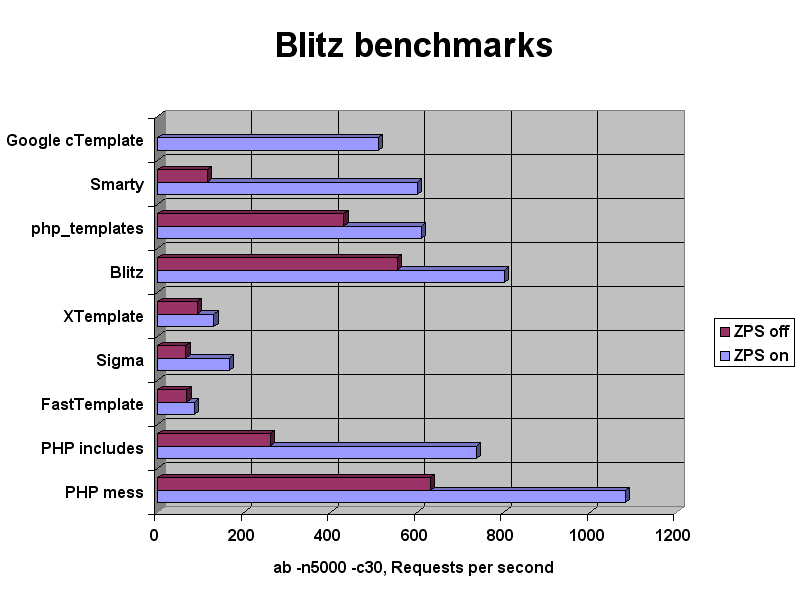{kind=link}
Поюзайте Quicky.
ну он процентов на 30-40% быстрее смарти.
А Вы проверьте ;-)
{helper myfunc($a,$b)}...{/}
Он будет ооочень близок к скорости быдлокода.
{helper myfunc($a,$b)}...{/}
Он будет ооочень близок к скорости быдлокода.
а ты думаешь я эти проценты из пальца высосал? =_="
Думаю, если не из пальца, то из неоптимального шаблона. Quicky это только не волшебные пузырьки которые ускоряют код шаблона, эта штука позволяет написать код шаблона оптимальнее.
Если использовать include, то конечно будет достаточно медленно, особенно без кэша оп-кода.
Если использовать объявление функции в шаблоне, то будет быстро. Переписать с использованием функции в шаблоне реально просто.
Если использовать include, то конечно будет достаточно медленно, особенно без кэша оп-кода.
Если использовать объявление функции в шаблоне, то будет быстро. Переписать с использованием функции в шаблоне реально просто.
как? у меня выдаёт странные варнинги: Notice: Undefined variable: this in Z:\home\test\www\xslt-vs-smarty\tpl.quicky.631921.php on line 38
пишу так:
{helper proc( $color, $shape, $childs )}
…
{foreach from=$childs item=child}
{proc color=$child.color shape=$child.shape childs=$child.childs}
{/foreach}
…
{/helper}
{proc color=$color shape=$shape childs=$childs}
пишу так:
{helper proc( $color, $shape, $childs )}
…
{foreach from=$childs item=child}
{proc color=$child.color shape=$child.shape childs=$child.childs}
{/foreach}
…
{/helper}
{proc color=$color shape=$shape childs=$childs}
А еще есть такая штука — кэш…
и она есть типа только у смарти?
Кстати о кэше, мы наверно по разному его понимаем. Я изучал как работает Smarty результатом разбора шаблона как ни странно является native PHP код вот про его кэширование я и хочу услышать (а не про кэширование результатов), а было ли оно? Если было то первую итерацию smarty сделает медленно, а вот во всех последующих итерациях разбором шаблона никто заниматься уже не будет будет выстреливать нативный код, что очень быстро.
И лучше было в заголовке написать versus (vs.), а не «против». А то можно подумать что Smarty против.
Не осилил все комменты, но не кажется ли вам, что искомый подвох не столько в синтаксисе, красоте или сложности изучения, сколько в принципе работы с увязкой на функциональность?
Ведь основной целью XSL является функциональная составляющая отображения данных. Данная технология позволяет не только шаблонизировать вывод, но произвести логические операции над данными в процессе «сборки», и вот здесь ключевой момент. Если провести тестирование на скорость с учетом этой специфики, то приемущества работы через XML-XSL прослойку будут более заметны, в отличии от статичной сборки по шаблону.
Может немного сумбурно описал, но суть в том, что в данном посте рассматривается не совсем корректная постановка задачи, с учетом особенностей технологий. В частонсти про XSLT — это как на гоночный трек поставить Феррари, калину и какой-нибудь скоростной тонар от Мерседес, и сравнить скорость доставки бандероли. Результат будет примерно одинаковым, но если поставить задачу перевезти 20 тонн бандеролей — результат уже будет более наглядным.
Ведь основной целью XSL является функциональная составляющая отображения данных. Данная технология позволяет не только шаблонизировать вывод, но произвести логические операции над данными в процессе «сборки», и вот здесь ключевой момент. Если провести тестирование на скорость с учетом этой специфики, то приемущества работы через XML-XSL прослойку будут более заметны, в отличии от статичной сборки по шаблону.
Может немного сумбурно описал, но суть в том, что в данном посте рассматривается не совсем корректная постановка задачи, с учетом особенностей технологий. В частонсти про XSLT — это как на гоночный трек поставить Феррари, калину и какой-нибудь скоростной тонар от Мерседес, и сравнить скорость доставки бандероли. Результат будет примерно одинаковым, но если поставить задачу перевезти 20 тонн бандеролей — результат уже будет более наглядным.
я не понял твою метафору о_0"
в статье рассматривается только скорость, ибо это обычно главный аргумент против xslt в спорах.
в статье рассматривается только скорость, ибо это обычно главный аргумент против xslt в спорах.
>но произвести логические операции над данными в процессе «сборки», и вот здесь ключевой момент.
Smarty, как и подавляющее большинство шаблонизаторов, тоже позволяет применять логику отображения, не говоря уж о чистом PHP. Или вы о бизнес-логике?
Smarty, как и подавляющее большинство шаблонизаторов, тоже позволяет применять логику отображения, не говоря уж о чистом PHP. Или вы о бизнес-логике?
Уже запасся поп-корном, ночка обещает быть веселой. Ох, люблю же я околопэхапэшные холивары! :-)
А почему функция так няшно названа?
function akeurwbkurlycqvaelkuyrc( $data )
Вам за плашку в конце поста по башке уже стукнули?
Smarty? Да что вы в него вцепились то, ни один адекватный MVC фреймворк его не использует и 3-ья версия уже не исправит этого.
XSLT конечно всем хорошо, только гибкости в нем маловато.
Zend_View отличненько так написан в ZF кстати…
XSLT конечно всем хорошо, только гибкости в нем маловато.
Zend_View отличненько так написан в ZF кстати…
Редактор блогов чет сломался у вас
Strict Standards: date() [function.date]: It is not safe to rely on the system's timezone settings. Please use the date.timezone setting, the TZ environment variable or the date_default_timezone_set() function. In case you used any of those methods and you are still getting this warning, you most likely misspelled the timezone identifier. We selected 'Europe/Moscow' for 'MSD/4.0/DST' instead in /home/grey/domains/softcoder.ru/public_html/system/libraries/loger.php on line 15
Strict Standards: is_a(): Deprecated. Please use the instanceof operator in /home/grey/domains/softcoder.ru/public_html/system/libraries/page.php on line 24
Раз уж на то пошло, то наше всё — это давно уже не Smarty. Имхо лучший на сегодняшний день PHP-шаблонизатор — это Twig. И дело тут даже не столько в перформансе (хотя твиг компилируется в пхп), а в сочетании удобства/мощи/простоты.
Реализовывать все шаблоны сложного веб-приложения на XSLT просто неудобно — особенно если предварительно посмотреть Twig (или непосредственно Jinja2 или шаблоны Django, на основных принципах которых построен Twig). Основные киллер-фичи (так для справки): наследование шаблонов и синтаксис в стиле Django, кастомные тэги, инклуды с контекстом, сендбоксинг, базовая защита от XSS (автоэскейпинг, выключается), очень качественный код в соотв. с ZF coding style для PHP5 и солидные авторы (разработчик symfony/symfony2).
Я не имею ничего против XSLT — отличная вещь, если нужно превратить одну хмлку в другую :) Не более. А в плане удобства использования, так даже сам PHP в качестве шаблонизатора намного удобнее. Имхо использовать XSLT имеет смысл только если интересует трансформация на клиенте, если он поддерживает, с целью разгрузить сервер (и решать проблемы кроссбраузерности).
Реализовывать все шаблоны сложного веб-приложения на XSLT просто неудобно — особенно если предварительно посмотреть Twig (или непосредственно Jinja2 или шаблоны Django, на основных принципах которых построен Twig). Основные киллер-фичи (так для справки): наследование шаблонов и синтаксис в стиле Django, кастомные тэги, инклуды с контекстом, сендбоксинг, базовая защита от XSS (автоэскейпинг, выключается), очень качественный код в соотв. с ZF coding style для PHP5 и солидные авторы (разработчик symfony/symfony2).
Я не имею ничего против XSLT — отличная вещь, если нужно превратить одну хмлку в другую :) Не более. А в плане удобства использования, так даже сам PHP в качестве шаблонизатора намного удобнее. Имхо использовать XSLT имеет смысл только если интересует трансформация на клиенте, если он поддерживает, с целью разгрузить сервер (и решать проблемы кроссбраузерности).
В комментах выше многие указывают на кеширование, как на преимущество Smarty. Но что мешает кешировать результат XSLT преобразования?
а зачем? о0
производительность в ущерб читабельности — не наш метод В-)
А если нужен именно pattern matching этот foreach придется заменять на template. Про то, что решение с foreach и choose не обладает адекватностью, думаю, говорить не приходится. Так что чисто в практическом плане решение очень адекватное.
Я проводил тесты, xsl:for-each быстрее получается, но незначительно.
в том же запросе — наврятли.
ну, разве что если fast-cgi используется — тогда можно закешировать DOM в памяти между запросами
без fast-cgi — да, каждый раз =(
Есть глобальный per-thread кэш компилированных регэксопов, если его не получается использовать, то да, каждый раз компилируются. Более того, при каждом вызове происходит трансляция текста в байт-код (если не ставить/включать акселераторы — кэшеры байт-кода)
Вы, вероятно, на Python пишите? Я вот начал на него переходить с PHP и сталкиваюсь со многими вещами, о которых в PHP даже не задумывался. Одни приятные (например, однократная компиляция регэкспов), другие (та же перезагрузка скрипта) не очень (это если не брать различия в в синтаксисе и т. п.). Основное различие в том, насколько я разобрался, что python-скрипт через wsgi создаёт по сути полноценный сервер, постоянно висящий в памяти и на новые запросы создаёт лишь новые экземпляры обработчиков (если в тонкости не вдаваться), а PHP скрипт вызывается таким сервером, отрабатывает параметры и выгружается, то есть является таким обработчиком (есть даже реализации вызова PHP скриптов из python wsgi приложения). Вероятно возможно написать на PHP и такой сервер, но насколько это оправдано будет, особенно если учесть, что многие фичи PHP (суперглобальные массивы, например) работать перестанут привычным образом и последние свои преимущества перед языками общего назначения PHP потеряет.
phpfm — по сути полноценный демон для fastсgi, его можно так же использовать на свое усмотрение, у него свой демон и свой порт, он никем не вызывается и никуда не вгружается… это очень оправдано
Можно, но тут уже, по-моему, python будет терять свои преимущества перед PHP :)
Суперглобальные массивы — например, _GET['reply_to'] или _SESSION['username'] — при старте скрипта инициализируются GET и POST параметрами запроса, окружением, серверными переменными и т. п. Если скрипт запустить как демон, то надо будет что-то мудрить с ними или писать код на них не рассчитывая (например передавать обработчикам как параметр объект request со всеми деталями запроса).
Суперглобальные массивы — например, _GET['reply_to'] или _SESSION['username'] — при старте скрипта инициализируются GET и POST параметрами запроса, окружением, серверными переменными и т. п. Если скрипт запустить как демон, то надо будет что-то мудрить с ними или писать код на них не рассчитывая (например передавать обработчикам как параметр объект request со всеми деталями запроса).
Это понятно (я как раз python на GAE осваиваю) и во многих PHP фреймворках так же реализовано, а значит внутреннюю логику приложения (нормально спроектированного) менять почти не придётся, только диспетчер запросов и вывод результатов. Почему такой способ не пользуется популярностью не знаю :) Возможно просто традиция (читай — требования совместимости), возможно потому что сложно написать универсальное решение, возможно ещё почему-то
разве в PHP-fcgi можно хранить что-то в памяти между запросами???? Покажите как!!!
Смарти и XSLT — просто разные технологии. И не надо их сравнивать. Те, кто выбирает XSLT (не просто так, а когда понимают что к чему), и так знают где они выиграют, а где могут проиграть. Писать надо не сравнения, а преимущества технологии в плане написания кода.
Кстати, при желании можно написать преобразование XSLT — native PHP, это если скорость совсем критична…
ЗЫ: после активного использования XSLT 2.0, версия 1.0 ощущается неким костылем.
Кстати, при желании можно написать преобразование XSLT — native PHP, это если скорость совсем критична…
ЗЫ: после активного использования XSLT 2.0, версия 1.0 ощущается неким костылем.
вы ставите include внутри foreach и беретесь рассуждать о производительности?
ты реальный xslt когда-нибудь видел?
> Результат: 1 + 200 = 201
Эта время компиляции + вывод или только вывод?
Эта время компиляции + вывод или только вывод?
т.е. я незря в свое время нарисовал https://sourceforge.net/projects/php-xhtml/
а что это?
обертка над пхпшным DOM для упрощения его генерации. оказывается не такая уж и тормозная вещь. единственное я заметил — если дерево большое (больше 20000 элементов), то не влезает в 32 метра стандартное у многих хостеров ограничение.
32 метра — довольно смешной лимит, учитывая средние объёмы RAM на хороших серверах и объёмы обрабатываевых данных :)
кстати, некоторые особо прогрессивные хостеры, позволяют создавать свой локальный php.ini с необходимыми настройками
а там глядишь и лимит памяти можно увеличить самому себе
кстати, некоторые особо прогрессивные хостеры, позволяют создавать свой локальный php.ini с необходимыми настройками
а там глядишь и лимит памяти можно увеличить самому себе
Да пусть XSLT будет таким же быстрым, как native PHP, однако это добавляет additional complexity в проект. Ну и зачем?
Есть только одна проблема с XSLT, единственный продукт поддерживающий стандарт XSLT2 — это Saxon XSLT processor, только Java. Потому я бы предпочел Smarty первой версии XSLT.
И да… XSLT можно сделать еще быстрее, путем его препроцессинга (это ведь XML!), с помощью самого XSLT. К примеру можно разресолвить все внешние зависимости и тупо сделать один большой файл, который можно скомпилировать, и запускать трансформацию уже на скомпилированном шаблоне. Можно вставить в шаблон специфические конструкции (сниппеты), к примеру для полупрозрачных ПНГ для ИЕ6, или для скругленных уголков, очень удобно.
>который можно скомпилировать, и запускать трансформацию уже на скомпилированном шаблоне.
Это общие рассуждения или практика использования XSL в PHP?
Это общие рассуждения или практика использования XSL в PHP?
какая разница?
Всегда казалось, что в PHP только во время обработки запроса можно загрузить xsl файл (вернее его DOM или SimpleXML) в процессор, а процессор, естественно (для PHP), для каждого запроса создаётся по новой. То есть для каждого запроса необходимо:
— создать процессор
— создать DOM для XSL
— импортировать этот DOM в процессор 9компиляция, насколько я понимаю, происходит на этом этапе)
— создать DOM для исходного XML
— «натравить» процессор на исходный DOM
— по окончанию обработки запроса процессор, как и все остальные объекты, уничтожается (если не был уничтожен ранее ручками)
Какой-то профит можно извлечь если необходимо за один запрос сделать несколько трансформаций по одному шаблону, тогда первые три пункта повторять для каждой трансформации не нужно, но в веб-деве это, по-моему, очень редкая задача.
Или я где-то ошибаюсь?
— создать процессор
— создать DOM для XSL
— импортировать этот DOM в процессор 9компиляция, насколько я понимаю, происходит на этом этапе)
— создать DOM для исходного XML
— «натравить» процессор на исходный DOM
— по окончанию обработки запроса процессор, как и все остальные объекты, уничтожается (если не был уничтожен ранее ручками)
Какой-то профит можно извлечь если необходимо за один запрос сделать несколько трансформаций по одному шаблону, тогда первые три пункта повторять для каждой трансформации не нужно, но в веб-деве это, по-моему, очень редкая задача.
Или я где-то ошибаюсь?
Все зависит от задач. Для моих больше подходит нативный компилятор. Главное уметь отделять бизнес-логику от логики отображения.
Попробовал переписать include в функцию для Smarty 3.
Результаты для Smarty 2 с include:
Результаты для Smarty 3 с функцией:
Это ощутимый прирост производительности. Хотя на мой взгляд если бы Smarty каждое обращение переменной компилировал в нечто более простое, нежели $_smarty_tpl->tpl_vars['child']->value, то с производительностью было ещё лучше.
{function name="tree"}
<div style="color:{$color|escape}">{$color|escape} {$shape|escape}</div>
<blockquote>
{foreach $childs as $child}
{tree color=$child.color shape=$child.shape childs=$child.childs}
{/foreach}
</blockquote>
{/function}
{tree color=$color shape=$shape childs=$childs}Результаты для Smarty 2 с include:
preprocessing: 1.98510742188
templating: 183.681152344
total: 185.666259766
Результаты для Smarty 3 с функцией:
preprocessing: 1.97705078125
templating: 36.2878417969
total: 38.2648925781
Это ощутимый прирост производительности. Хотя на мой взгляд если бы Smarty каждое обращение переменной компилировал в нечто более простое, нежели $_smarty_tpl->tpl_vars['child']->value, то с производительностью было ещё лучше.
А если до вывода поставить ob_start(); а после вывода — ob_end_clean(); то результаты будут совсем другими =)
php test-xslt.php
— total: 29.31005859375
php test-smarty.php
— total: 713.7099609375
php test-php.php
— total: 18.787841796875
Фактически получается, что в твоих тестах XSLT борется с функцией _smarty_include класса Smarty (если что — я не в курсе часто ли она используется на практике)
ЗЫЖ Смарти — зло! =)
php test-xslt.php
— total: 29.31005859375
php test-smarty.php
— total: 713.7099609375
php test-php.php
— total: 18.787841796875
Фактически получается, что в твоих тестах XSLT борется с функцией _smarty_include класса Smarty (если что — я не в курсе часто ли она используется на практике)
ЗЫЖ Смарти — зло! =)
smarty 3 rc2
Вы что, издеваетесть? Третяя версия смарти примерно в два-три раза медленнее, чем второй смарти.
Реализация function в 3-м смарти медленная, defun/fun плагин из второго работает гораздо быстрее.
Вы не могли взять еще проще XML и еще проще трансформацию?
Вы проводили тесты? Разработчики Smarty так не думают.
Our preliminary performance tests are already showing us very promising speed improvements over Smarty 2 (2-5x on average), and we're not done!
Обращение к переменной $_smarty_tpl->getVariable('thing')->value['color'] явно медленнее, чем $this->_tpl_vars['color']
Резонный вопрос, а на каких задачах? То, что нужно было мне, а это темплейт в 50 килобайт, работало от 2х до 3х раз медленнее. Иногда смарти 3 выдавал совершенно депрессивную скорость.
покажи этот мегатемплейт
NDA. Не могу.
По-другому там никак не сделать, я и так из него почти максимум соков выжал.
По-другому там никак не сделать, я и так из него почти максимум соков выжал.
Я лично сталкивался с файлом в 5000 строк на 350 кил, в которых использовалось максимум 3-4 класса и 3-4 функции, и создатель оного говорил что по «другому не может и все соки из него выжал»… Можно всегда, Ваш шаблон плохой
Как может человек, который мало того, что не видел исходный код, так еще и не знает задачу, говорить, что мой шаблон плохой? Представьте себе набор инструкций и данных, которые нужно отобразить в разных видах: табличном, строковом, как дерево. Ячейка данных может иметь как сложную, так и простую структуру. Инструкции могут быть как простыми, так и более интеллектуальными. Одни и те же данные могут отображаться несколько раз.
Подумайте над сложностью задачи, для начала, а потом уже рассказывайте о похом шаблоне.
Подумайте над сложностью задачи, для начала, а потом уже рассказывайте о похом шаблоне.
где скачать и как использовать?
мог. а что?
мог. а что?
Вот тут исходный код
Там же есть обсуждение того, как использовать.
Там же есть обсуждение того, как использовать.
я не собираюсь читать 11 страниц форума в поисках актуальной версии плагина
А не надо читать 11 страниц, приведенный код в посте messju и является самым актуальным.
Я тоже проводил тесты, результат аналогичен. Так что пора этому мифу идти на свалку, XSLT не медленный, просто нужно уметь его использовать. Конечно при гигантских шаблонах, или при загрузке лишних данных в XML (например в случае полной XSLT пагинации) получим тормоза.
По поводу удобства XSLT шаблонов, зачастую этот язык используют не надлежащим образом, получая нечитабельную кучу xsl:variable и xsl:choose. Достаточно ознакомиться со статьей «10 ошибок XSLT-программистов».
По поводу удобства XSLT шаблонов, зачастую этот язык используют не надлежащим образом, получая нечитабельную кучу xsl:variable и xsl:choose. Достаточно ознакомиться со статьей «10 ошибок XSLT-программистов».
Здравая мысль заключается в том, что нужно смотреть на сложные варианты, а не на примитивные тесты. Я использую XSLT помимо Smarty, но для тех вариантов, где это необходимо.
А сложные варианты показывают еще лучшие результаты, с увеличением сложности PHP шаблоны стремительно приближаются по скорости к XSLT (хотя все равно останутся быстрее, но уже не в разы). Просто я как-то решил сделать аналогичные имеющимся XSLT шаблонам шаблоны на чистом PHP, поначалу PHP шаблоны были гораздо быстрее, по мере реализации всех нюансов скорость очень быстро падала, и в итоге оказалось где-то раза в 2 быстрее, хотя до конца так и не доделал всю функциональность. Удобство написание шаблонов XSLT гораздо выше, меньше ошибок в них получается, если шаблон заработал, то с большой вероятностью он не будет сбоить в будущем, а вот в PHP все печально с этим. Поэтому мой выбор — XSLT. К тому же он есть везде, изучив однажды, можно применять его в своей работе где бы то ни было.
В XSLT можно реализовать кэширование отдельных блоков. То есть разделить страницу, например, на десяток блоков (хидеры, футеры, сайдбары, меню и т. п.), заранее трасформировать их в HTML, а потом при запросах лишь трансформировать основной контент (динамический) и собирать страницу из готовых блоков?
конечно, можно их даже вкомпилировать в сам шаблон %-)
Как-то этот момент упустил, думал можно только импортировать или инклудить другие xslt шаблоны, а вот что в произвольное место можно вставить произвольный html файл. Не подскажете каким элементом это делается?
xi:include
document()
document()
хм… XSLTProcessor поддерживает XInclude? Нигде не встречал упоминания об этом, надо будет поэкспериментировать
нет, конечно. но некоторые xml парсеры — вполне
вы не в теме
php.net/manual/en/domdocument.xinclude.php
$xsl = new DOMDocument();
$xsl->loadXML(file_get_contents('layout.xsl'));
$xsl->xinclude();
$xslt = new XSLTProcessor;
$xslt->importStyleSheet($xsl);
echo $xslt->transformToXML($data);>Достаточно ознакомиться со статьей «10 ошибок XSLT-программистов».
Киньте адрес, плиз.
Киньте адрес, плиз.
webcache.googleusercontent.com/search?q=cache:http://toivonen.ru/books-articles/xslt-articles/10-xslt-mistakes.html
Переписал все на fun/defun
Получил среднее время smarty 3.1, для xslt — 2.6
Предлагаю автору расширить методику тестирования.
Нужно отображать
Получил среднее время smarty 3.1, для xslt — 2.6
Предлагаю автору расширить методику тестирования.
Нужно отображать
для всех shapes кроме rectangle. Для последнего нужно использовать div
'blue', 'yellow', 'magenta', 'cyan' должны быть жирными, остальные нормальным текстом
(по поводу 3-го варианта)
Если вы «это» называете «РНР Быдлокод», то как вы тогда называете остальные 95% РНР кода?
(Счастлив был бы безмерно, если бы приходилось работать с таким «быдлокодом», увы в реальной практике работая с чужим кодом, мне встречается то на что у вас видимо цензурных слов просто не найдётся)
Если вы «это» называете «РНР Быдлокод», то как вы тогда называете остальные 95% РНР кода?
(Счастлив был бы безмерно, если бы приходилось работать с таким «быдлокодом», увы в реальной практике работая с чужим кодом, мне встречается то на что у вас видимо цензурных слов просто не найдётся)
Smarty против XSLT