Большинство систем редактирования текста имеют инструмент для автоматической проверки орфографических ошибок (когда в слове написаны неправильно одна или несколько букв; по-английски — speller). Их принцип действия: программа анализирует в тексте каждое слово и ищет такое же в Базе Данных всех слов и их всевозможных форм.
Такая проверка текста гарантирует, что слова в тексте будут написаны правильно (как в словаре), но не защищает от ошибок согласования и синтаксических ошибок в предложении. Например, предложение «Я читаешь интересными журналом» неправильно, но система редактирования текста не покажет правильный вариант: «Я читаю интересный журнал».
Избежать таких ошибок помогает программа проверки грамматических ошибок в предложении (по-английски — grammar checker).
Создано немало программ проверяющих орфографические ошибки. Но до сих пор (насколько я знаю) нет программ проверяющих грамматические ошибки в предложении (для флексивных/флективных языков — в которых слова имеют много форм); то есть проверяющих ошибки не только орфографические но и ошибки согласования и синтаксиса. Поэтому я хотел бы представить программу которая это делает (насколько это получается).
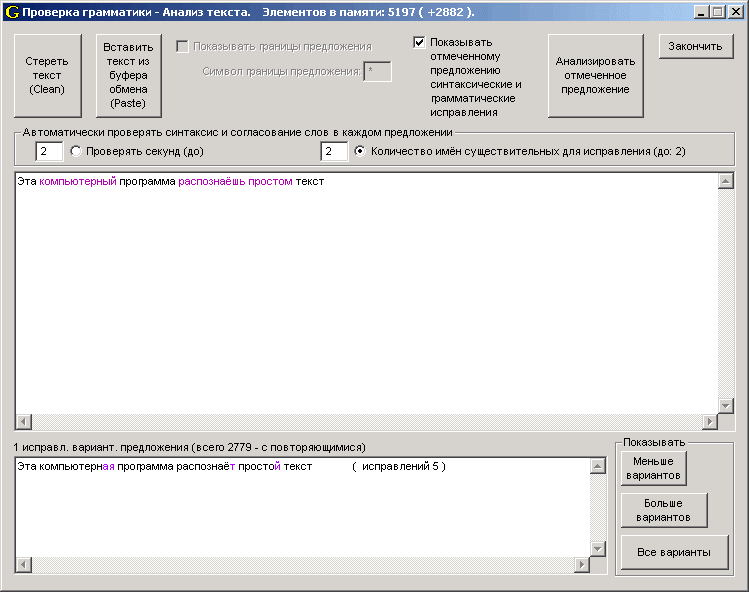
В 2003-2007 годах я написал программку (три её версии), которая максимально быстро анализировала текст (на литовском языке) и выдавала исправления не только для орфографических ошибок, но и исправляла грамматические ошибки и ошибки связи в предложении.
В январе 2011, через википедию, я набрёл на сайт habrahabr.ru, а затем и на статьи пользователя rg_software «Заметки об NLP» и «NLP: проверка правописания — взгляд изнутри» и встретив фразу «как составить паттерн для правила «сказуемое должно иметь тот же род, что и подлежащее?» подумал, что стоит написать про свою работу — возможно она будет интересна специалистам и неравнодушным.
Затем я сделал за полтора месяца русскую версию программы.
Программа работает по принципу синтаксического анализатора для языков программирования: используется большой «универсальный шаблон/паттерн предложения», в котором описаны все возможные варианты согласования слов в предложении; все возможные варианты предложения.
Синтаксический анализатор немного модифицирован под человеческий язык (подробнее — в pdf-е описания); кроме того, чтобы программа предложила более удачный (на ее взгляд) вариант входного предложения — для этого нужно рассматривать все формы у каждого слова из входного предложения. Например, для предложения «Эта компьютерная программа распознаёт простой текст» предпологается рассмотерть 13.934.592 комбинаций вариантов (24*24*12*7*24*12); это выполняется примерно за 5 секунд.
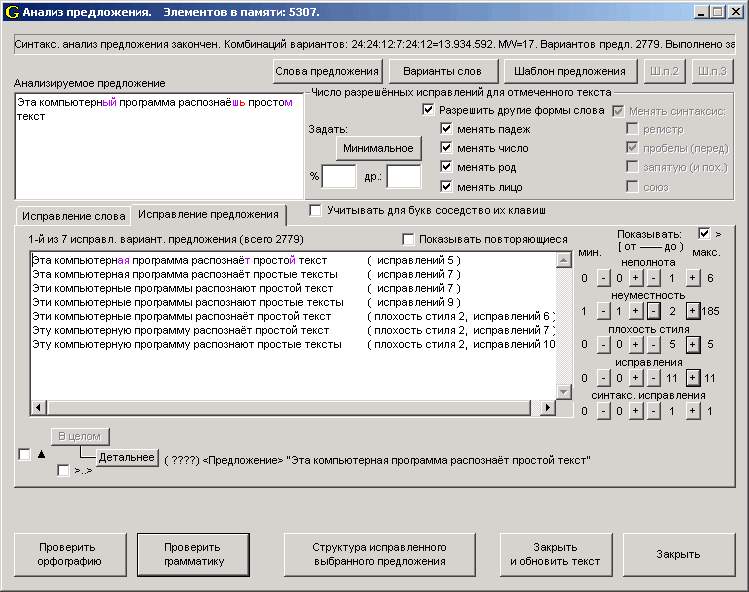
Кроме исправления грамматики программа:
* Поддерживает многовариантность слов и фраз на всех уровнях синтаксического дерева предложения.
* Показывает графически дерево выбранного (исправленного) варианта предложения или распознанной его части; так же показываются «деревья» универсального шаблона предложений, «слова» входного предложения и их варианты.
** В окнах графического отображения структуры исправленного предложения и универсального шаблона предложений можно: двигать вид, щёлкать левой или правой кнопкой мыши по пустому
месту (отменяет выделение элемента), по элементам (левой — распахивает/сворачивает элемент (связка "-EXP-"), правой — выделяет его) или по их частям (только левой кнопкой мыши — по связям "-AND-" (горизонтальные) и "-OR-" (вертикальные) — распахивает/сворачивает их).
Вот ссылки (для быстрого ознакомления) на страничку этой программы на разных языках:
На русском: sites.google.com/site/sergprogrammer/main/main_ru/grammar_ru
На английском (in english): sites.google.com/site/sergprogrammer/main/main_en/grammar_en
На данный момент там можно скачать литовскую «урезанную» версию программы, в которой отключён графический показ элементов всех деревьев/графов и отключены некоторые особенности, и более открытую русскую версию.
Последняя версия программы (на русском языке и для работы с русским языком) находится на сайте проекта «мультиграммар» по адресу: sourceforge.net/projects/grammar-multi/files
Там же можно скачать большое pdf или doc описание «как оно всё примерно работает».
Там же есть форум, на котором я смогу ответить на вопросы незарегистрированных пользователей.
Интерфейс «русской» версии программы меняется в файле «messages.txt», словарь (микроскопический) — в файле «dic.txt», универсальный шаблон предложения — в файле «rules.txt».
Английскую версию я всё ещё пытаюсь создать; получится версия больше не для использования а для демонстрации принципа работы.
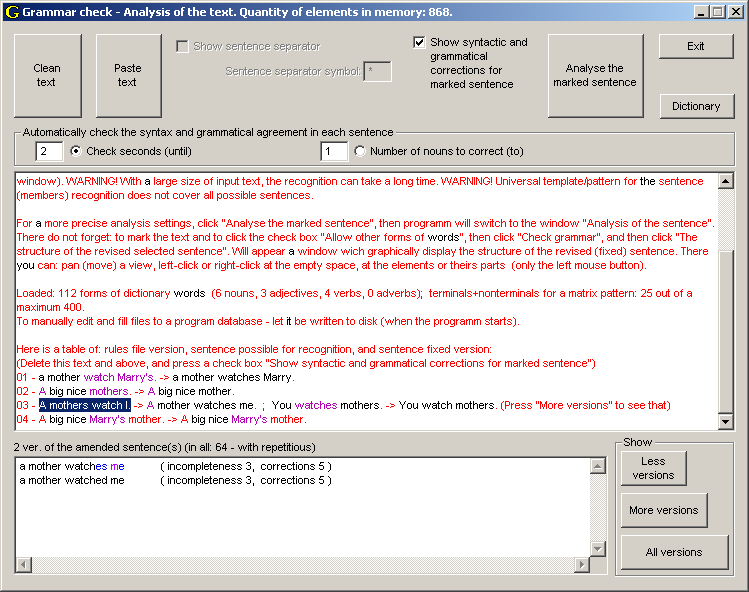
Обновление от 15 ноября 2011: решил добавить сюда скриншоты английской версии граммара:

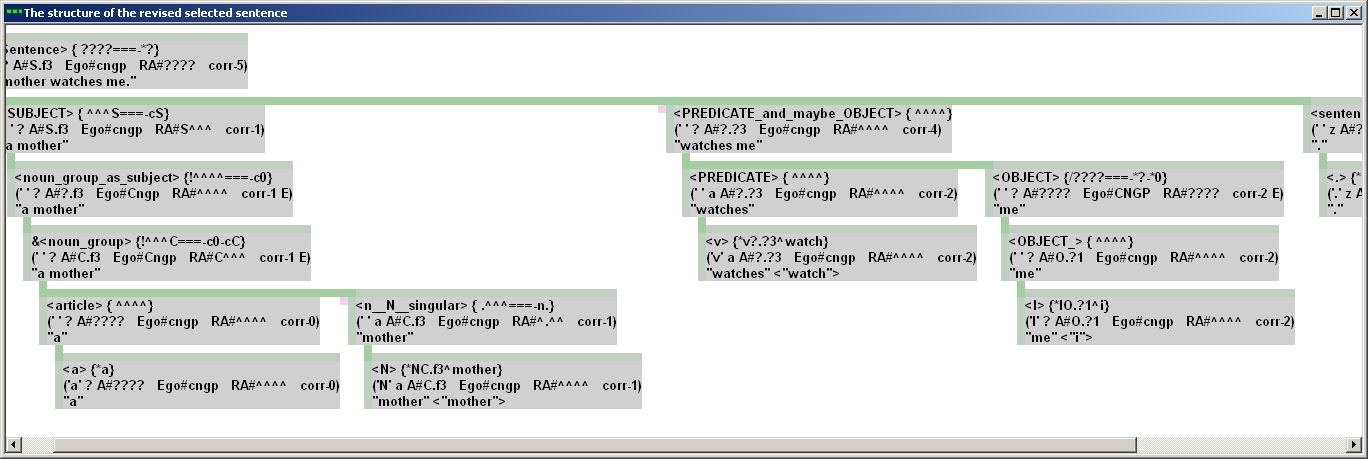
На последнем, кстати, структура разобранного предложения в представлении программы по версии файла «универсального шаблона предложения» rules.txt
Такая проверка текста гарантирует, что слова в тексте будут написаны правильно (как в словаре), но не защищает от ошибок согласования и синтаксических ошибок в предложении. Например, предложение «Я читаешь интересными журналом» неправильно, но система редактирования текста не покажет правильный вариант: «Я читаю интересный журнал».
Избежать таких ошибок помогает программа проверки грамматических ошибок в предложении (по-английски — grammar checker).
Создано немало программ проверяющих орфографические ошибки. Но до сих пор (насколько я знаю) нет программ проверяющих грамматические ошибки в предложении (для флексивных/флективных языков — в которых слова имеют много форм); то есть проверяющих ошибки не только орфографические но и ошибки согласования и синтаксиса. Поэтому я хотел бы представить программу которая это делает (насколько это получается).
В 2003-2007 годах я написал программку (три её версии), которая максимально быстро анализировала текст (на литовском языке) и выдавала исправления не только для орфографических ошибок, но и исправляла грамматические ошибки и ошибки связи в предложении.
В январе 2011, через википедию, я набрёл на сайт habrahabr.ru, а затем и на статьи пользователя rg_software «Заметки об NLP» и «NLP: проверка правописания — взгляд изнутри» и встретив фразу «как составить паттерн для правила «сказуемое должно иметь тот же род, что и подлежащее?» подумал, что стоит написать про свою работу — возможно она будет интересна специалистам и неравнодушным.
Затем я сделал за полтора месяца русскую версию программы.
Программа работает по принципу синтаксического анализатора для языков программирования: используется большой «универсальный шаблон/паттерн предложения», в котором описаны все возможные варианты согласования слов в предложении; все возможные варианты предложения.
Синтаксический анализатор немного модифицирован под человеческий язык (подробнее — в pdf-е описания); кроме того, чтобы программа предложила более удачный (на ее взгляд) вариант входного предложения — для этого нужно рассматривать все формы у каждого слова из входного предложения. Например, для предложения «Эта компьютерная программа распознаёт простой текст» предпологается рассмотерть 13.934.592 комбинаций вариантов (24*24*12*7*24*12); это выполняется примерно за 5 секунд.
Кроме исправления грамматики программа:
* Поддерживает многовариантность слов и фраз на всех уровнях синтаксического дерева предложения.
* Показывает графически дерево выбранного (исправленного) варианта предложения или распознанной его части; так же показываются «деревья» универсального шаблона предложений, «слова» входного предложения и их варианты.
** В окнах графического отображения структуры исправленного предложения и универсального шаблона предложений можно: двигать вид, щёлкать левой или правой кнопкой мыши по пустому
месту (отменяет выделение элемента), по элементам (левой — распахивает/сворачивает элемент (связка "-EXP-"), правой — выделяет его) или по их частям (только левой кнопкой мыши — по связям "-AND-" (горизонтальные) и "-OR-" (вертикальные) — распахивает/сворачивает их).
Вот ссылки (для быстрого ознакомления) на страничку этой программы на разных языках:
На русском: sites.google.com/site/sergprogrammer/main/main_ru/grammar_ru
На английском (in english): sites.google.com/site/sergprogrammer/main/main_en/grammar_en
На данный момент там можно скачать литовскую «урезанную» версию программы, в которой отключён графический показ элементов всех деревьев/графов и отключены некоторые особенности, и более открытую русскую версию.
Последняя версия программы (на русском языке и для работы с русским языком) находится на сайте проекта «мультиграммар» по адресу: sourceforge.net/projects/grammar-multi/files
Там же можно скачать большое pdf или doc описание «как оно всё примерно работает».
Там же есть форум, на котором я смогу ответить на вопросы незарегистрированных пользователей.
Интерфейс «русской» версии программы меняется в файле «messages.txt», словарь (микроскопический) — в файле «dic.txt», универсальный шаблон предложения — в файле «rules.txt».
Английскую версию я всё ещё пытаюсь создать; получится версия больше не для использования а для демонстрации принципа работы.
Обновление от 15 ноября 2011: решил добавить сюда скриншоты английской версии граммара:
На последнем, кстати, структура разобранного предложения в представлении программы по версии файла «универсального шаблона предложения» rules.txt
