 Задача № 5, около 6200 фрагментов, размер каждого фрагмента около 150 х 60 px.
Задача № 5, около 6200 фрагментов, размер каждого фрагмента около 150 х 60 px.Агентство DARPA огласило результаты конкурса по восстановлению документов после шредера. В конкурсе приняли участие почти 9000 команд.
Каждый «паззл» состоял из фрагментов рукописного текста, измельчённого на новом коммерческом шредере и отсканированного с разрешением 400 DPI. В самом сложном задании № 5 было около 6200 фрагментов от неизвестного количества страниц — с этим заданием справились только две команды.
Победителем стала команда All Your Shreds Are Belong To U.S. — она смогла набрать максимально возможные 50 очков, выполнив все задания. Ближайшие конкуренты набрали 30 и 26 баллов.
Полностью автоматического решения никто не сумел разработать, все команды предусматривали участие одного или нескольких людей-операторов, которые проверяют правильность совпадения фрагментов. Польская команда попыталась использовать краудсорсинг. Пара десятков пользователей совместными усилиями относительно быстро решили первый паззл, но дальше так и не продвинулись.
Программист Марк Ньюлин (команда wasabi), который занял третье место, опубликовал свою методику восстановления документов. Все модули разработаны на C# / .NET 4.0 / MSSQL. На первом этапе осуществляется подготовка для сборки: разбиение изображения на отдельные фрагменты, очистка от фона и выравнивание.
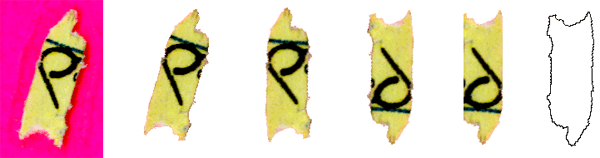
Выделение границ осуществляется после заливки фона. Выравнивание фрагментов автоматизируется по стороне с максимальным количеством пикселов, а в спорных случаях помогает ручное выравнивание (по словам Марка, таких было около 1%). Верхняя и нижняя границы фрагментов тоже легко идентифицируются по характерным следам шредера, так что в случае необходимости фрагмент поворачивается на 180°. Каждый фрагмент паззла сохраняется в файл. Отдельно сохраняется «очищенная» версия фрагмента, обрезанная с длинных сторон — она нужна, чтобы найти точки соединения следа ручки.
Перед сборкой составляется база данных с информацией о каждом фрагменте: размеры в «грязном» и чистом виде, координаты линий (если заметен фрагмент листа в линейку), форма границы, точки выхода следа ручки, цвет каждой точки на границе, а также распознанный символ. Поскольку программы OCR с такой задачей справляются плохо, то распознавание символов осуществлялось вручную, говорит Марк, с принятием бокала пива после каждой тысячи фрагментов.
Вероятность соседства для каждой пары фрагментов вычислялась с учётом точек соприкосновения следа от ручки на границах фрагмента (по координатам и количеству таких точек), по точкам соприкосновения линеек на бумаге и сходстве фрагментов по цвету.
На основе этой информации сборка документа осуществляется вручную в графическом редакторе. Марк использовал GIMP и Paint.NET, но для сложных паззлов четвёртого и пятого заданий с тысячами фрагментов ему пришлось сделать отдельный интерфейс, чтобы фильтровать просмотр фрагментов из базы данных по разным параметрам: вероятность соседства, цвет ручки, наличие пятна от кофе и т.д.

Был добавлен также интерфейс для вывода на экран наиболее подходящих фрагментов, что повысило точность и скорость сборки.

Общий документ со всеми найденными совпадениями постепенно дополнялся, а вероятности пересчитывались.

Марк Ньюлин говорит, что потратил на этот проект всё свободное время за последние несколько недель. Ему удалось решить четыре из пяти задач конкурса, кроме самого сложного пятого паззла из 6200 кусочков, за который давали 24 очка. Видимо, Марку просто не хватило времени, потому что он работал в одиночку. Сейчас он собирается купить пару коммерческих шредеров, чтобы продолжить эксперименты и улучшить свою технологию. Возможно, в будущем Марк напишет книгу или откроет собственную фирму, чтобы составить конкуренцию Unshredder.com. Хотя, он будет не одинок. После конкурса DARPA наверняка сформировалось большое сообщество людей, заинтересованных этой темой.
Команда-победитель All Your Shreds Are Belong To U.S. тоже обещает раскрыть свой алгоритм решения в ближайшее время. В комментариях к сообщению в блоге Марка они сказали, что во многом использовали такие же методы. В сопроводительной записке они сообщили, что решение всех задач заняло около 600 человеко-часов.
На сайте DARPA опубликованы сканы решений (PDF), которые прислала команда-победитель. Например, ниже показаны оригиналы и восстановленные фрагменты трёх страниц из пятого задания. В задании все фрагменты были вперемешку, на каждой странице были недостающие фрагменты, а вторая страница отсутствовала почти полностью. Для получения баллов требовалось не просто собрать паззл, но ещё и расшифровать сообщение. Так, в пятом задании сообщение было закодировано азбукой Морзе (решение каждого задания, PDF).
Страница 1, азбука Морзе в последней строчке

Страница 2 измельчалась вверх ногами

Страница 3

Стандарт безопасности для шредеров DIN 32757 указывает минимальный размер фрагментов после измельчения для каждого уровня безопасности:
Уровень 1 = полоски 12 мм или фрагменты 11 x 40 мм
Уровень 2 = полоски 6 мм или фрагменты 8 x 40 мм
Уровень 3 = полоски 2 мм или фрагменты 4 x 30 мм (маркировка Confidential)
Уровень 4 = фрагменты 2 x 15 мм (маркировка Commercially Sensitive)
Уровень 5 = фрагменты 0,8 x 12 мм (маркировка Top Secret или Classified)
Уровень 6 = фрагменты 0,8 x 4 мм (маркировка Top Secret или Classified)
В пятом задании конкурса размер фрагментов составляет около 148 х 59 пикселов, то есть 9,4 х 3,7 мм, что примерно соответствует шредеру 4-го уровня по стандарту безопасности DIN 32757. Если верить Википедии, стандарты безопасности ЦРУ для шредеров предусматривают размер фрагментов не более 1 х 5 мм, в Российской Федерации — 1 х 1 мм.
