 Данная статья предназначена для разъяснения сути фундаментальных методов построения и оптимизации «искусственного интеллекта» для компьютерных игр (в основном антагонистических). На примере игры в зайца и волков будет рассмотрен алгоритм «Минимакс» и алгоритм его оптимизации «Альфа-бета отсечение». Помимо текстового описания, статья содержит иллюстрации, таблицы, исходники, и готовую кроссплатформенную игру с открытым кодом, в которой вы сможете посоревноваться с интеллектуальным агентом.
Данная статья предназначена для разъяснения сути фундаментальных методов построения и оптимизации «искусственного интеллекта» для компьютерных игр (в основном антагонистических). На примере игры в зайца и волков будет рассмотрен алгоритм «Минимакс» и алгоритм его оптимизации «Альфа-бета отсечение». Помимо текстового описания, статья содержит иллюстрации, таблицы, исходники, и готовую кроссплатформенную игру с открытым кодом, в которой вы сможете посоревноваться с интеллектуальным агентом.Игра «Заяц и волки»
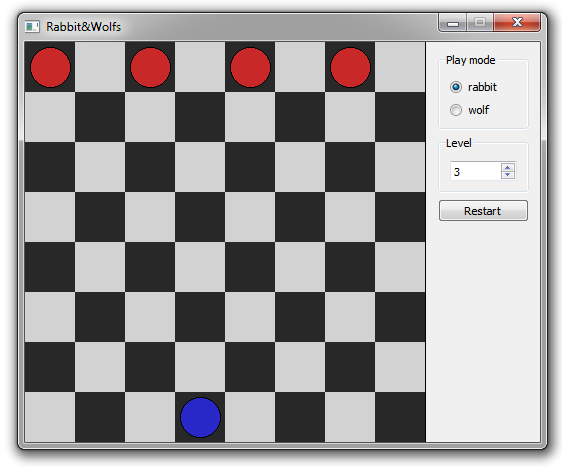
На шахматной доске есть 4 волка сверху (на черных клеточках), и 1 заяц снизу (на одной из черных). Заяц ходит первым. Ходить можно только на одну клеточку по диагонали, притом волки могут ходить только вниз, а заяц в любую сторону. Заяц побеждает, когда достиг одной из верхних клеточек, а волки, когда они окружили или прижали зайца (когда зайцу некуда ходить).
Перед продолжением чтения, рекомендую поиграть, так будет легче понимать.
Эвристика
В практическом инженерном понимании, метод минимакса опирается на эвристику, которую мы рассмотрим прежде, чем переходить к сути алгоритмов.В контексте минимакса, эвристика нужна для оценки вероятности победы того или иного игрока, для какого-либо состояния. Задача состоит в том, чтобы построить эвристическую оценочную функцию, которая достаточно быстро и точно, в выбраной метрике, сможет указать оценку вероятности победы конкретного игрока для конкретного расположения фигур, не опираясь на то, каким образом игроки к этому состоянию пришли. В моем примере оценочная функция возвращает значения от 0 до 254, где 0 — победа зайца, 254 — победа волка, промежуточные значения — интерполяция двух вышеуказанных оценок. Оценка вероятности — не вероятность, и не обязана быть ограниченной, линейной, непрерывной.
Пример оценочной функции 1. Чем заяц выше, тем больше у него шансов на победу. Такая эвристика эффективна с точки зрения быстродействия (О(1)), но совершенно не пригодна алгоритмически. «Высота» зайца коррелирует с вероятностью победы, но искажает основную цель зайца — победить. Эта оценочная функция говорит зайцу двигаться вверх, но при небольшой глубине расчета будет приводить к тому, что заяц двигается вверх, не взирая на преграды, и попадает в ловушки.
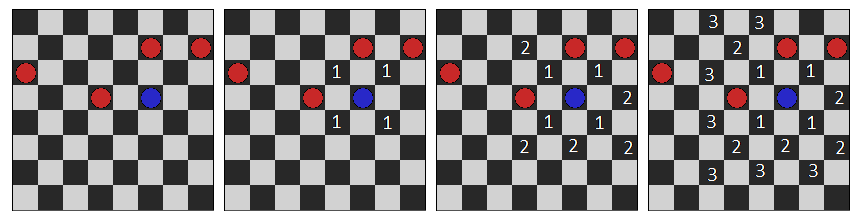
Пример оценочной функции 2. Заяц тем вероятней победит, чем меньше ему нужно сделать ходов для победы, при замороженных волках. Это более громоздкий алгоритм со сложностью О(n), где n – количество клеточек. Расчет количества ходов сводится к поиску в ширину:
Внимание. Исходники, приведенные в статье, видоизменены таким образом, чтобы читатель смог понять их суть вне контекста основного приложения. Достоверные исходники ищите в конце статьи.
Код, выполняющий поиск в ширину, а точнее заполнение карты значениями равными “расстоянию” от зайца:
this->queue.enqueue(this->rabbitPosition);
while (!this->queue.empty())
{
QPoint pos = this->queue.dequeue();
for (int i = 0; i < 4; i++)
if (canMove(pos + this->possibleMoves[i]))
{
QPoint n = pos + this->possibleMoves[i];
this->map[n.y()][n.x()] = this->map[pos.y()][pos.x()] + 1;
this->queue.enqueue(n);
}
}
Результатом оценочной функции должно быть значение равное «расстоянию» до ближайшей верхней клеточки, либо 254, если дойти до них невозможно. Несмотря на недостатки, которые я опишу ниже, именно эта эвристика используется в игре.
Тем, кто будет смотреть исходники и разбираться — внимание! Архитектура приложения построена таким образом, чтобы оценочную функцию можно было переделать, не затрагивая другие части кода. Но, следует использовать ранее выбранную метрику, иначе алгоритмы не будут понимать показания функции оценки.
Минимакс
Введем некоторые понятия и обозначения:- Состояние, оно же узел дерева решений — расположение фигур на доске.
- Терминальное состояние — состояние, с которого больше нет ходов (кто-то победил / ничья).
- Vi — i-ое состояние.
- Vik — k-ое состояние, к которому можно прийти за один ход из состояния Vi. В контексте дерева решений, это дочерний узел Vi.
- f(Vi) — расчетная оценка вероятности победы для состояния Vi.
- g(Vi) — эвристическая оценка вероятности победы для состояния Vi.
f(Vi) отличается от g(Vi) тем, что g(Vi) использует информацию только о Vi, а f(Vi) — также Vik и другие состояния, рекурсивно.
Метод разработан для решения проблемы о выборе хода с состояния Vi. Логично выбирать ход, для которого оценка вероятности будет максимально выгодной для игрока, который ходит. В нашей метрике, для волков — максимальная оценка, для зайцев минимальная. А оценка считается следующим образом:
- f(Vi) = g(Vi), если Vi — терминальное состояние, либо достигнут предел глубины расчетов.
- f(Vi) = max(f(Vi1), f(Vi2)… f(Vik)), если Vi — состояние, с которого ходит игрок с поиском максимальной оценки.
- f(Vi) = min(f(Vi1), f(Vi2)… f(Vik)), если Vi — состояние, с которого ходит игрок с поиском минимальной оценки.
Метод опирается на здравый смысл. Мы ходим так, чтобы максимизировать оценку собственной победы P, но чтобы просчитывать хоть что-то, нам нужно знать, как будет ходить враг, а враг будет ходить так, чтобы максимизировать оценку своей победы (минимизировать оценку P). Другими словами, мы знаем как будет ходить враг, и таким образом можем строить оценки вероятностей. Самое время указать о том, что алгоритм является оптимальным, если у врага такая же оценочная функция, и он действует оптимально. В таком случае, интеллектуальность зависит от глубины просчета, и от качества оценочной функции.
Самое время привести пример:
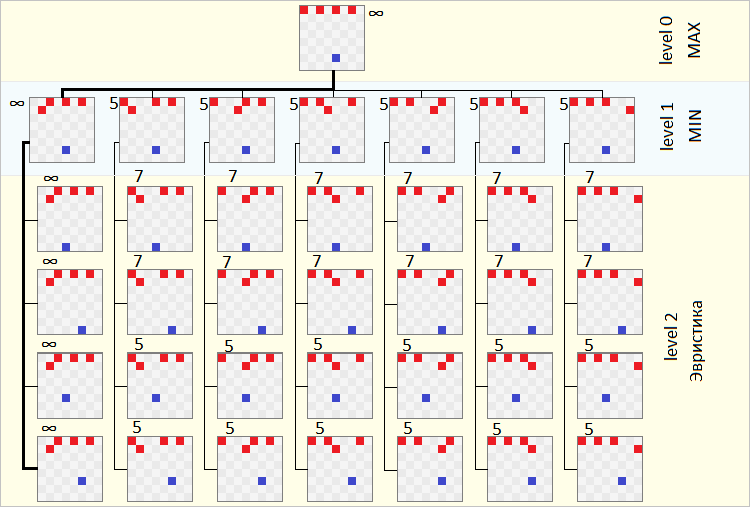
На этом примере, игрок играет зайцем, а компьютер волками. После того как заяц походил, компьютер запускает алгоритм минимакса, на этом примере с глубиной 1. Что делает алгоритм?
Этот пример будет легче понимать, если рассматривать его снизу. На втором уровне у нас состояния, для которых мы получаем эвристическую оценку (она записана числами). По второму уровню, первый получает свои оценки, соответственно выбрав минимальные значения из тех, что проверены на следующем уровне. Ну и нулевой уровень, выбирает максимальную оценку, из тех, что предоставлены ему первым уровнем.
Теперь, когда у нас есть все оценки, что делать?
Пример реализации алгоритма:
//возвращает оценку текущего состояния f(Vi)
int Game::runMinMax(MonsterType monster, int recursiveLevel)
{
int test = NOT_INITIALIZED;
//на последнем уровне дерева (на листах) возвращаем значение функции эвристики
if (recursiveLevel >= this->AILevel * 2)
return getHeuristicEvaluation();
//индекс выбранного пути. 0-7 - возможные ходы волков, 8-11 - возможные ходы зайца
int bestMove = NOT_INITIALIZED;
bool isWolf = (monster == MT_WOLF);
int MinMax = isWolf ? MIN_VALUE : MAX_VALUE;
//перебираем все возможные хода данного монстра
for (int i = (isWolf ? 0 : 8); i < (isWolf ? 8 : 12); i++)
{
int curMonster = isWolf ? i / 2 + 1 : 0;
QPoint curMonsterPos = curMonster == 0 ? rabbit : wolfs[curMonster - 1];
QPoint curMove = possibleMoves[isWolf ? i % 2 : i % 4];
if (canMove(curMonsterPos + curMove))
{
//...ходим, после чего обрабатываем ситуацию
temporaryMonsterMovement(curMonster, curMove);
//оцениваем, насколько хорош ход, который мы выбрали
test = runMinMax(isWolf ? MT_RABBIT : MT_WOLF, recursiveLevel + 1);
//если он лучше всех, что были до этого - запомним, что он лучший
if ((test > MinMax && monster == MT_WOLF) ||
(test <= MinMax && monster == MT_RABBIT))
{
MinMax = test;
bestMove = i;
}
//... и восстанавливаем исходное состояние
temporaryMonsterMovement(curMonster, -curMove);
}
}
if (bestMove == NOT_INITIALIZED)
return getHeuristicEvaluation();
//ну и собственно, ходим, коль уже выбрали лучший ход
if (recursiveLevel == 0 && bestMove != NOT_INITIALIZED)
{
if (monster == MT_WOLF)
wolfs[bestMove / 2] += possibleMoves[bestMove % 2];
else
rabbit += possibleMoves[bestMove % 4];
}
return MinMax;
}
Внимание! Тут переменная bestMove инкапсулирует много смысла (уточню при запросе), взываю вас никогда не вкладывать столько смысла в 4 бита, если вы не уверены в том, что вы делает все правильно.
Будучи грамотными и образованными людьми, вы уже догадались, что там где есть деревья поиска решений, там есть и клад для оптимизаций. Данный пример не исключение.
Альфа-бета отсечение
Альфа-бета отсечение основано на той идее, что анализ некоторых ходов можно прекратить досрочно, игнорируя результат их показаний. Альфа-бета отсечение часто описывается как отдельный алгоритм, но я считаю это недопустимым и буду описывать его как оптимизирующую модификацию. Альфа-бета относится к классу методов ветвей и границ.Грубо говоря, оптимизация вводит две дополнительные переменные alpha и beta, где alpha — текущее максимальное значение, меньше которого игрок максимизации (волки) никогда не выберет, а beta — текущее минимальное значение, больше которого игрок минимазации (заяц) никогда не выберет. Изначально они устанавливаются в -∞, +∞ соответственно, и по мере получения оценок f(Vi) модифицируются:
- alpha = max(alpha, f(Vi)); для уровня максимизации.
- beta = min(beta, f(Vi)); для уровня минимизации.
Как только условие alpha > beta станет верным, что означает конфликт ожиданий, мы прерываем анализ Vik и возвращаем последнюю полученную оценку этого уровня.
На нашем примере, на втором рисунке, с помощью альфа-бета отсечений, полностью отсекаются 3 нижних ряда, но без самого левого столбца. Я считаю, что это не удачный пример для объяснения, а потому возьму пример из википедии, который чуть более удачный.
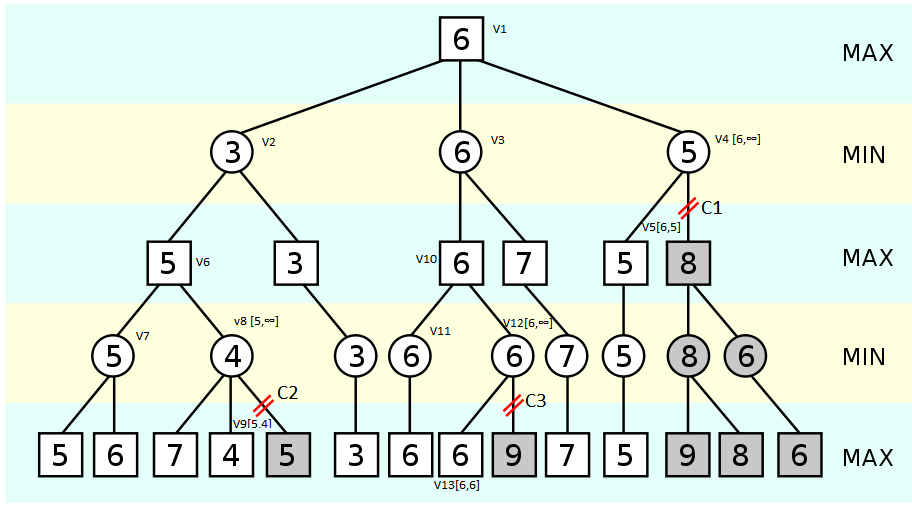
Обозначения в примере:
- Vi — узлы дерева поиска решений, i никоим образом не коррелирует с порядком обхода дерева.
- Vi[alpha, beta] — узлы с указанными текущими значениями alpha, beta.
- Ci — i-ое альфа-бета отсечение.
- MIN, MAX — уровни максимизации и минимазации соответственно. Будьте внимательны, состояния на уровне максимума будут выбирать свои максимумы из состояний следующего уровня, на которых указан MIN, и наоборот. То есть максимальный выбирается из тех, на которых написан MIN, а минимальный из тех, на которых написан MAX, не перепутайте.
Рассмотрим отсечение 1. После того, как для узла V1 был полностью обработан вариант с узлом V3, и получена его оценка f(V3) = 6, алгоритм уточняет значение alpha для этого узла (V1), и передает его значение в следующий узел — V4. Теперь для всех дочерних узлов V4 минимальный alpha = 6. После того как узел V4 обработал вариант с узлом V5, и получил оценку f(V5) = 5, алгоритм уточняет значение beta для узла V4. После обновления, для узла V4 мы получили ситуацию в которой alpha > beta, и следовательно другие варианты узла V4 рассматривать не нужно. И нам не важно, какая оценка будет у отсеченного узла:
- Если значение отсеченного узла меньше или равно 5 (beta), то в узел V4 будет выбрана оценка, которая не больше 5, и соответственно вариант с узлом V4 никогда не будет выбран узлом V1, потому что оценка узла V3 — лучше.
- Если значение отсеченного узла больше или равно 6 (beta + 1), то узел тем более не будет рассматриваться, поскольку узел V4 выберет вариант с узлом V5, так как его оценка меньше (лучше).
Отсечение 2 абсолютно идентично по структуре, и я бы рекомендовал вам попробовать разобрать его самостоятельно. Отсечение 3 намного интересней, внимание, пример на википедии явно в чем-то не прав. Он позволяет себе проводить отсечения, если (alpha >= beta), хотя альфа-бета должна была бы быть оптимизацией, и не влиять на выбор пути. Дело в том, что везде пишут, что отсечение должно срабатывать, когда alpha >= beta, хотя в общем случае, только когда alpha > beta.
Допустим, для некоторого дерева решений, все дети показывают одинаковую оценку. Тогда можно было бы выбрать из них любую, случайным образом, и это было бы правильно. Но у вас не получится так делать, используя условия alpha >= beta, потому что после первой оценки все остальные могут быть отсечены. Но это не беда, допустим, не будет ваш алгоритм реализовывать стохастическое поведение, это не так важно, но если в вашем алгоритме выбор лучшего из значений с одинаковой оценкой важен, то такое условие отсечения приведет к тому, что алгоритм просто поломается, и будет ходить не оптимально. Будьте бдительны!
Альфа-бета отсечение – очень простой для реализации алгоритм, и суть его сводится к тому, что в функцию минимакса нужно добавить 2 переменные alpha и beta в интерфейс процедуры минимакса, и небольшой кусок кода в ее тело, сразу после получения оценки.
Пример модификации алгоритма минимакса с альфа-бета отсечением (для большей наглядности, внесенные модификации закомментированы, но помните, что это важный код, а не комментарии):
int Game::runMinMax(MonsterType monster, int recursiveLevel/*, int alpha, int beta*/)
{
int test = NOT_INITIALIZED;
if (recursiveLevel >= this->AILevel * 2)
return getHeuristicEvaluation();
int bestMove = NOT_INITIALIZED;
bool isWolf = (monster == MT_WOLF);
int MinMax = isWolf ? MIN_VALUE : MAX_VALUE;
for (int i = (isWolf ? 0 : 8); i < (isWolf ? 8 : 12); i++)
{
int curMonster = isWolf ? i / 2 + 1 : 0;
QPoint curMonsterPos = curMonster == 0 ? this->rabbit : this->wolfs[curMonster - 1];
QPoint curMove = this->possibleMoves[isWolf ? i % 2 : i % 4];
if (canMove(curMonsterPos + curMove))
{
temporaryMonsterMovement(curMonster, curMove);
test = runMinMax(isWolf ? MT_RABBIT : MT_WOLF, recursiveLevel + 1, alpha, beta);
temporaryMonsterMovement(curMonster, -curMove);
if ((test > MinMax && monster == MT_WOLF) ||
(test <= MinMax && monster == MT_RABBIT))
{
MinMax = test;
bestMove = i;
}
/* if (isWolf)
alpha = qMax(alpha, test);
else
beta = qMin(beta, test);
if (beta < alpha)
break; */
}
}
if (bestMove == NOT_INITIALIZED)
return getHeuristicEvaluation();
if (recursiveLevel == 0 && bestMove != NOT_INITIALIZED)
{
if (monster == MT_WOLF)
this->wolfs[bestMove / 2] += this->possibleMoves[bestMove % 2];
else
this->rabbit += this->possibleMoves[bestMove % 4];
}
return MinMax;
}
Как я уже говорил ранее, альфа-бета отсечение очень эффективно, и доказательством тому является приведенные ниже показатели. Для каждого случая, на трех разных уровнях глубины расчетов, я замерял количество входов в функцию эвристической оценки (меньше – лучше), и вот что получилось:
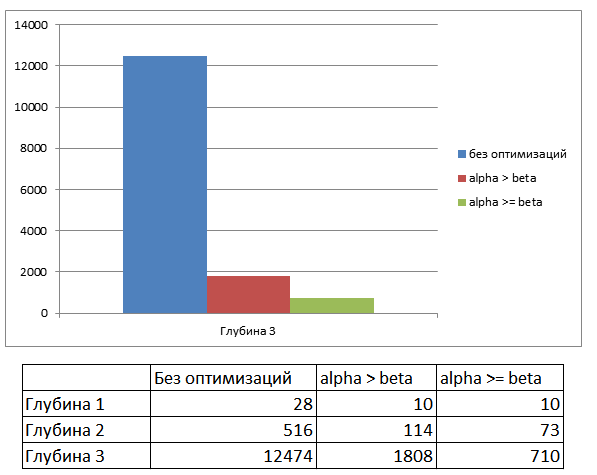
Как вывод, могу сказать что использование этого алгоритма отсечения не только ускорит работу интеллекта, но и позволит повысить его уровень.
Нюансы
Алгоритм делает оптимальные ходы, только если его противник мыслит оптимально. Качество хода в основном зависит от глубины рекурсии, и от качества эвристики. Но следует отметить, что этот алгоритм оценивает качество хода достаточно глубоко, и никоим образом не завязывается (если явно не прописать где-то в эвристике) на количество ходов. Другими словами, если применить этот алгоритм к шахматам, без дополнительных модификаций, он будет ставить маты позже, чем мог бы. А в данном примере, если заяц поймет, что у него нет пути на победу, при оптимальной стратегии волков, он может покончить жизнь самоубийством, несмотря на то, что он мог бы оттягивать проигрыш.Еще раз, никогда не делайте условием для альфа-бета отсечения alpha >= beta, если вы не на 100% уверены, что для вашей реализации это допустимо. Иначе ваша альфа-бета ухудшит интеллектуальность алгоритма в целом, с высокой долей вероятности.
Алгоритм фундаментальный, в том смысле, что он является фундаментом для большого множества разных модификаций. В том виде, в котором он представлен тут, его нельзя применять для шашек, шахмат, го. В основном модификации стремятся:
- Повторно использовать вычисления.
- Анализировать разные ситуации с разной глубиной
- Увеличивать количество отсечений, за счет общих принципов и эвристик для конкретной игры.
- Внедрять шаблоны ходов. Например, в шахматах первые несколько ходов – дебюты, а не работа минимакса.
- Внедрять сторонние мерки качества ходов. Например, проверять, можно ли победить одним ходом, и если можно — победить, а не минимакс запускать.
- Многое другое.
Колоссальное количество модификаций и позволяют компьютеру играть в шахматы, и даже обыгрывать человека. Без таких модификаций, минимакс к шахматам практически не применим, даже на современных супер компьютерах. Без оптимизаций, в шахматах для трех ходов нужно было бы проверить порядка 30^6 ходов (729 миллиардов), а нам нужно, чтобы глубина расчета была побольше…
