Comments 29
Вопрос на миллион: как таблицу заразмерить, невозможно смотреть.
долго ждали такого полного мануала (all-in-one). спасибо.
/me дочитал до упоминания NFS в пределах одного физического сервера и забил читать дальше.
интро унылое, но сам ресурс обещает соки. если бы не эти ребята и www.howtoforge.com
Я к тому, что правильно приготовленные локальные ФС тут правильнее будут. Намного. Ну и быстрее, само собой.
www.softpanorama.org/Net/Application_layer/NFS/nfs_performance_tuning.shtml
Это исследование за 2008 мохнатый год.
А вот тут вас обозвали малазийцем. ;)
storagegaga.com/tag/nfsv4/
Я пытаюсь найти за вас аргументацию «против» этого решения, но может быть я изначально не верно понимаю ваш посыл? Вы подкинете какую-нибудь пищу для размышления, что бы мой гипотетический отказ я мог сопроводить умным взглядом и цифрами.
По поводу падения производительности: думаю если речь идет о чем-то серьезном (напомню, что у нас самый недорогой веб-сервер у хецнера с 200k посетителями и трафиком в 350Gb ежемесячно), то уж не столь ощутимо падение в производительности чтения файлов. Запись/удаление — надо смотреть на реальных задачах. Но вы говорите, что это вторично, так что же первично?
Это исследование за 2008 мохнатый год.
А вот тут вас обозвали малазийцем. ;)
storagegaga.com/tag/nfsv4/
Я пытаюсь найти за вас аргументацию «против» этого решения, но может быть я изначально не верно понимаю ваш посыл? Вы подкинете какую-нибудь пищу для размышления, что бы мой гипотетический отказ я мог сопроводить умным взглядом и цифрами.
По поводу падения производительности: думаю если речь идет о чем-то серьезном (напомню, что у нас самый недорогой веб-сервер у хецнера с 200k посетителями и трафиком в 350Gb ежемесячно), то уж не столь ощутимо падение в производительности чтения файлов. Запись/удаление — надо смотреть на реальных задачах. Но вы говорите, что это вторично, так что же первично?
А зачем бегать из контекста в контекст? Всё равно ж раза в 2-3 медленнее будет. И seek'и страшные.
Смотрите, я часто встречаю выражение о NAS «double the cost for half the performance» в сравнении с DAS. Но в нашем конкретном примере конфигурации это не чистый NAS, а пара-NAS, т.к. речь идет не то что об одной шине, а о физически том же диске. Неужели такие потери связаны с сетевым протоколом, что в 2-3 раза падает производительность? Даже если исключить кеширование файлов в память на этом embeded-NAS, откуда такой пессимизм?
Ну, допустим вы уже «трогали» живые цифры. Представьте себе новостной сайт, где чуть ли не 95% трафика приходится на главную страницу, а архив материалов — за десять лет. Условно нарисую число запросов к файлам и материалам по годам:
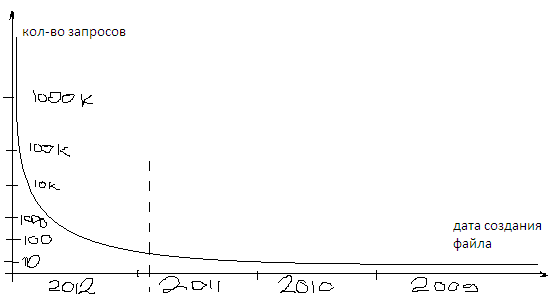
Ну и вот нафига мне в DAS нужны 90% файлов на которые приходится 2-4% всех просмотров? По хорошему, выпнуть бы это все в облака за те же деньги, что стоит поставить еще один диск архива. Не говоря уже о еженедельном бэкапе длинной в 8 часов (не я настраивал).
Ну, допустим вы уже «трогали» живые цифры. Представьте себе новостной сайт, где чуть ли не 95% трафика приходится на главную страницу, а архив материалов — за десять лет. Условно нарисую число запросов к файлам и материалам по годам:
Ну и вот нафига мне в DAS нужны 90% файлов на которые приходится 2-4% всех просмотров? По хорошему, выпнуть бы это все в облака за те же деньги, что стоит поставить еще один диск архива. Не говоря уже о еженедельном бэкапе длинной в 8 часов (не я настраивал).
> На каждом узле VM также работают iptables и доступ разрешен только к необходимым портам.
если речь идет о виртуализации, то выгоднее (лучше) прописать порты на хост-машине.
опять таки, на практике, чаще всего VM-ки общаются между собой по внутрисети, поэтому интранет можно не закрывать.
снаружи доступ есть только к балансеру (реверс-прокси), который будет проксировать во внутрь исключительно HTTP(s?) трафик
можно еще пробросить отдельные порты для внешнего сервиса мониторинга. остальное все изолировано.
если речь идет о виртуализации, то выгоднее (лучше) прописать порты на хост-машине.
опять таки, на практике, чаще всего VM-ки общаются между собой по внутрисети, поэтому интранет можно не закрывать.
снаружи доступ есть только к балансеру (реверс-прокси), который будет проксировать во внутрь исключительно HTTP(s?) трафик
можно еще пробросить отдельные порты для внешнего сервиса мониторинга. остальное все изолировано.
Там вопрос был в том, что если будет скомпрометирован один из узлов этого виртуал-нета, то не хотелось бы, что бы остальные постигла такая же участь из-за открытых портов во все стороны. Пока у самого не появилось ясности, как будет организовано управление узлами. Будет ли это все же открытый наружу ssh-канал или это VNC в духе Аркипеловского. Тема для меня актуальная, но новая и тут я в полуслепую тыкаюсь.
узлы достаточно зависимы друг от друга, чтобы система продолжила полноценно функционировать если один из них будет скомпромитирован.
более-менее независимыми будут апп-ноды, которые можно свободно убирать-добавлять и от этого мало что поменяется в общей архитектуре. но эти ноды в идеале будут точными копиями друг-друга, поэтому вероятность того, что будут скомпроментированы менее двух апп-нод не очень велика.
я на самом деле не против дополнительного файрвола, но делюсь из того, к чему мы пришли у себя (не факт что идеальный вариант) — iptables на хост-машинах, внешний трафик жестко рубится, виртуалки общаются между собой через интранет, большинство машин изолированы от внешнего мира вообще (DRAC не в счет)
более-менее независимыми будут апп-ноды, которые можно свободно убирать-добавлять и от этого мало что поменяется в общей архитектуре. но эти ноды в идеале будут точными копиями друг-друга, поэтому вероятность того, что будут скомпроментированы менее двух апп-нод не очень велика.
я на самом деле не против дополнительного файрвола, но делюсь из того, к чему мы пришли у себя (не факт что идеальный вариант) — iptables на хост-машинах, внешний трафик жестко рубится, виртуалки общаются между собой через интранет, большинство машин изолированы от внешнего мира вообще (DRAC не в счет)
Т.е. если я под эту архитектуру попытаюсь впихнуть сервера разработки и тест.сервера — вся избыточность и секьюрность утеряет всякий и без того хлипкий смысл? Мне кажется, что заморочиться с iptables на гостевых системах все же имеет смысл.
У нас сейчас чудовищная ситуация — разработчики «шастают» по ssh на большой сервер, на котором крутится несколько проектов, с общей нагрузкой в 250k посетителей, и меня это хозяйство повергает в ужасное уныние. Сижу, смотрю мониторинг и не понимаю, где и что вызвало скачки нагрузки, кто долбит дисковую систему, а кто сожрал память.
Безусловно, я сплю и вижу, что выстрелит очередной проект и я «выкину» его в готовом контейнере за пару часов вовне. Этому будет посвящена вторая статья цикла. Надеюсь на ваше пристальное внимание.)
У нас сейчас чудовищная ситуация — разработчики «шастают» по ssh на большой сервер, на котором крутится несколько проектов, с общей нагрузкой в 250k посетителей, и меня это хозяйство повергает в ужасное уныние. Сижу, смотрю мониторинг и не понимаю, где и что вызвало скачки нагрузки, кто долбит дисковую систему, а кто сожрал память.
Безусловно, я сплю и вижу, что выстрелит очередной проект и я «выкину» его в готовом контейнере за пару часов вовне. Этому будет посвящена вторая статья цикла. Надеюсь на ваше пристальное внимание.)
ну у нас немного проще — один проект + шастающих по серверам людей можно на пальцах пересчитать.
а с избыточностью файрволов мы расстались после одного случая, когда при одном всплеске трафика именно за счет файрволов система «захлебнулась».
стихийным развертыванием системы на новых серверах мы не увлекаемся: купили сервера, неспешно настроили, скопировали виртуалку, расклонировали ее, проверили, добавили в апстрим.
когда у нас был могучий сисадмин, мы еще умели лихо малой кровью на амазоне разворачивать свои виртуалки.
спустя год попробовали (уже без мегоодмина) так же лихо развернуться из существующего образа — не вышло. пришлось разворачиваться практически руками (благо один раз, а потом наклонировали)
а с избыточностью файрволов мы расстались после одного случая, когда при одном всплеске трафика именно за счет файрволов система «захлебнулась».
стихийным развертыванием системы на новых серверах мы не увлекаемся: купили сервера, неспешно настроили, скопировали виртуалку, расклонировали ее, проверили, добавили в апстрим.
когда у нас был могучий сисадмин, мы еще умели лихо малой кровью на амазоне разворачивать свои виртуалки.
спустя год попробовали (уже без мегоодмина) так же лихо развернуться из существующего образа — не вышло. пришлось разворачиваться практически руками (благо один раз, а потом наклонировали)
Начало если честно какое-то унылое, и слишком многое неясно. Надеюсь, следующие части будут интереснее и полнее.
Спасибо за перевод. :)
Спасибо за перевод. :)
Задавайте вопросы, вторая часть на изготовье.
У меня вопросы больше как у NOC'а. Если статья ориентированна на новичков, то про настройку сети тоже можно было уделить небольшую статью. Как в «inside network» будут соединены между собой сервера? Какие линки между ними? Какие коммутаторы лучше использовать?
Ну и в довесок не совсем понятно зачем lighttpd когда с отдачей статики, имхо, лучше справится nginx. И как собственно, добавлять новые ноды, например, с web-серверами на борту? Если не планируется, то зачем memcached?
Ну и в довесок не совсем понятно зачем lighttpd когда с отдачей статики, имхо, лучше справится nginx. И как собственно, добавлять новые ноды, например, с web-серверами на борту? Если не планируется, то зачем memcached?
У нас виртуальная сеть, об каких коммутаторах речь? Стаит-сервер стоит в ДЦ Хецнера, хочется сделать его девелопмент-тест-продакшеном для пары тройки проектов, которые в прокаченном виде легко и недорого будут деплоится на новые машина уже в настроенном контейнере, или в облака уходить, по достижению каких-то серьезных показателей посещаемости и нагрузки на имеющуюся железяку.
lighttpd не я придумал использовать, мне вообще кажется, что в рунете он редкость (относительная). Кто-то собирает непонятные мне конфиги из кеширующего энджинкса и ставит перед ним варниш. Зачем так делать — ума не приложу. Но, блин, ведь делают зачем-то? Сейчас допереведем этот цикл, а по фидбэку в комментах станет ясно, что еще нужно/можно посмотреть, так как академической литературы по построению ± сложных архитектур на один-два дэдика с пятью-десятью проектами на борту я не знаю. Есть идеи, что поискать?
lighttpd не я придумал использовать, мне вообще кажется, что в рунете он редкость (относительная). Кто-то собирает непонятные мне конфиги из кеширующего энджинкса и ставит перед ним варниш. Зачем так делать — ума не приложу. Но, блин, ведь делают зачем-то? Сейчас допереведем этот цикл, а по фидбэку в комментах станет ясно, что еще нужно/можно посмотреть, так как академической литературы по построению ± сложных архитектур на один-два дэдика с пятью-десятью проектами на борту я не знаю. Есть идеи, что поискать?
> У нас виртуальная сеть, об каких коммутаторах речь?
Есть виртуальные свитчи, например, у ESX/ESXi свой, есть не привязанный ни к какому гипервизору Open vSwitch. Да и NaaS (Network-as-a-Service) все больше набирает оборотов.
Есть виртуальные свитчи, например, у ESX/ESXi свой, есть не привязанный ни к какому гипервизору Open vSwitch. Да и NaaS (Network-as-a-Service) все больше набирает оборотов.
Да и у нас не много, но они же приходят и уходят, следят и мусорят, ставят и удаляют, а потом черт ногу сломит разобрать, что половину бы неплохо, для порядка, стереть к такой-то матери, что бы новый входящий не мучался вопросом, с какого края ему подойти к серверу. Каждый чточку мусорит, а в конце — помойка. Сейчас заведем журнал, регламенты, переставим все хозяйство и будем чаи гонять, но это все потом.
Мониторите через munin+nasios или какое-то более общее решение нашли? Уже третью неделю пытаюсь прикручивать метрики munin'овские (отдельная задача) попутно разбирая, что же это все значит и откуда что растет (в смысле нагрузок и iowait'ов). Будет готова метрика на фаервол — будем думать, видимо на новом сервере, куда и мигрируем. Всплыли неполадки в файловой системе, теперь мониторим SMART и потеем от мысли, что что-нибудь схлопнится раньше переезда. Как в одной хорошей лекции по мониторингу серверов тут, на хабре, говорил мужик из Битрикса — никакой романтики. Кровь и мозги на стенах.
Могучих сисадминов не видел, чудаков — да, могучих не встречал. Это какой-то полумифический кадр, который где-то есть, но стоит попробовать приблизится к нему — и его сразу же нет.
Как у вас управление виртуалками выстроена? В плане, если все порты наружу, кроме 80/443 закрыто? Что-то из этого набора? На центОСе или Дебиане? Любопытно просто. Не очень бурная аудитория по администрированию серверов вообще в рунете, проще сиськи найти. Я бы у вас интервью взял, было бы круто, если вдруг и вам взбредет это в голову. ;)
Мониторите через munin+nasios или какое-то более общее решение нашли? Уже третью неделю пытаюсь прикручивать метрики munin'овские (отдельная задача) попутно разбирая, что же это все значит и откуда что растет (в смысле нагрузок и iowait'ов). Будет готова метрика на фаервол — будем думать, видимо на новом сервере, куда и мигрируем. Всплыли неполадки в файловой системе, теперь мониторим SMART и потеем от мысли, что что-нибудь схлопнится раньше переезда. Как в одной хорошей лекции по мониторингу серверов тут, на хабре, говорил мужик из Битрикса — никакой романтики. Кровь и мозги на стенах.
Могучих сисадминов не видел, чудаков — да, могучих не встречал. Это какой-то полумифический кадр, который где-то есть, но стоит попробовать приблизится к нему — и его сразу же нет.
Как у вас управление виртуалками выстроена? В плане, если все порты наружу, кроме 80/443 закрыто? Что-то из этого набора? На центОСе или Дебиане? Любопытно просто. Не очень бурная аудитория по администрированию серверов вообще в рунете, проще сиськи найти. Я бы у вас интервью взял, было бы круто, если вдруг и вам взбредет это в голову. ;)
разрозненные ответы :)
— мониторим через nagios + cacti. в отдельных случаях читаем логи atop-а и/или проблемного сервиса (если удалось его определить)
— могучие сисадмины редки и со временем все равно переходят в разные более комфортные места (где видимо скапливаются в больших количествах)
— у нас все на CentOS + xen устроено. управление вируалками ручками из консоли (там три с половиной команды да и не такая уж частая задача ими управлять с хоста)
— да я и не админ вовсе =)
— мониторим через nagios + cacti. в отдельных случаях читаем логи atop-а и/или проблемного сервиса (если удалось его определить)
— могучие сисадмины редки и со временем все равно переходят в разные более комфортные места (где видимо скапливаются в больших количествах)
— у нас все на CentOS + xen устроено. управление вируалками ручками из консоли (там три с половиной команды да и не такая уж частая задача ими управлять с хоста)
— да я и не админ вовсе =)
Меня соблазнил munin тем, что под него можно легко писать плагины. Кто б мне сказал, что надо было задаться вопросом «а каких тебе плагинов не хватало в nagios?».
Та же фигня с админами. «Был, сделал, ушел». Куда они уходят и почему становясь как будто бы профессионалами, частенько превращаются в ленивых парнокопытных — это отдельная тема для разговора.
Я пока еще не начал вирутализировать проекты, но пока склоняюсь в сторону KVM, во всяком случае это более «модная тема» обсуждать, как последний лучше подходит для 6-й версии CentOS.
А кто вам сказал, что я — админ? ;) Просто возникает необходимость делать что-то хорошо или искать тех, кто знает и делает много лучше тебя. А как это проверить? Сделать хорошо хотя бы раз самостоятельно. Вобщем, общая беда всех технических проектов.
В любом случае, спасибо за комменты. Чувствую, что в чем-то моя и ваша ситуации похожи между собой. ;)
Та же фигня с админами. «Был, сделал, ушел». Куда они уходят и почему становясь как будто бы профессионалами, частенько превращаются в ленивых парнокопытных — это отдельная тема для разговора.
Я пока еще не начал вирутализировать проекты, но пока склоняюсь в сторону KVM, во всяком случае это более «модная тема» обсуждать, как последний лучше подходит для 6-й версии CentOS.
А кто вам сказал, что я — админ? ;) Просто возникает необходимость делать что-то хорошо или искать тех, кто знает и делает много лучше тебя. А как это проверить? Сделать хорошо хотя бы раз самостоятельно. Вобщем, общая беда всех технических проектов.
В любом случае, спасибо за комменты. Чувствую, что в чем-то моя и ваша ситуации похожи между собой. ;)
Честно говоря не вижу никаких преимуществ перед тем же apparmor + нормальное распределение прав + iptables. Вижу минус в неэффективности использования памяти, размазанному файловому кешу и большей нагрузке на процы (да и на диск тоже).
Когда я ломаю сайт в вашей схеме, я автоматически получаю доступ к БД как минимум под учёткой для работы с сайтом (ибо в конфигах сайта эти данные есть), к рассылке почты и мемкешу. То есть я спокойно смогу сделать фишинговый сайт и/или разослать спам или поддосить кого-нибудь. То же самое я смогу сделать и на обычном хостинге, где все службы на одном физическом компе, где профит?
Когда я ломаю сайт в вашей схеме, я автоматически получаю доступ к БД как минимум под учёткой для работы с сайтом (ибо в конфигах сайта эти данные есть), к рассылке почты и мемкешу. То есть я спокойно смогу сделать фишинговый сайт и/или разослать спам или поддосить кого-нибудь. То же самое я смогу сделать и на обычном хостинге, где все службы на одном физическом компе, где профит?
плюс мы получаем больше проблем с администрированием этой всей красоты в разы
Конечно тут будет некоторый оверхед. Но если будет мониторинг, если под БД в 50Мб не будет выделено 50 процессов, при учете того, что стоит memcached а к самой БД идет не более 500 запросов в сутки, из которых 490 — селекты… Что бы все это надежно отмониторить неплохо бы разделить и выявить, что и сколько в стэке реально требует ресурсов, думаю не жалко и 10% от производительности на это дело потратить. Пока же все без оверхедов, как-то само по себе «работает и слава яйца» — ну о какой оптимизации и мониторинге может быть речь в подобном случае? Реально на том проекте, из-за которого меня на переводы потянуло, я не видел, что бы процессор нагружался хотя бы до 10%. Постоянный idle. А вот диски — уже визжат. Особенно на выходных, когда бэкап, настроенный из plesk-панели, на 8 часов кряду вгоняет всю систему в полумертвое состояние. А это происходит из-за беспорядка на дисках. Почему там беспорядок? Потому что нет регламента никакого. Почему нет регламента никакого? Потому что всем удобнее позвать кого-то, кто решит очевидные проблемы, подкинув следующему за ним админу пачку новых проблем. И вот так и получается этот круг ненависти, где все друг-другу гадят таким милым и незатейливым образом.
Я решил их всех сделать. ;)))
Я решил их всех сделать. ;)))
Всё что в написали поможет и в случае когда все службы установлены на одном сервере =)
Опять же с правильно выделенными правами администратор(ы) каждого сервиса смогут нормально работать и в пределах одного сервера, если я не прав, приведите пример, пожалуйста.
Опять же с правильно выделенными правами администратор(ы) каждого сервиса смогут нормально работать и в пределах одного сервера, если я не прав, приведите пример, пожалуйста.
Ага, «безопасность обратно пропорциональна удобству». Всё это может произойти, когда все установлено, как у нас сейчас — на одном сервере. Когда ftp — немного больше, чем доступ к своей папочке и код правиться на живом сервере. Т.е. тест, девелопмент, продакшен, — эдакий continious integration, — по-хардкору.
В статье есть только на уровне доп.ссылок материалы о логировании iptables и прочем. О мониторинге — нужно писать отдельную статью. Вот чесслово, был бы материал/книга, которая назывался бы «Безопасность сервера. Регламенты и рецепты управления» — сел бы и перевел.
Если к первому вашему комменту вернуться, то вот что я скажу
Буду, наверно, разбираться и с SElinux, но пока мы прислушиваемся к авторам туториала и, временно, его выключаем.
В чем же преимущество над AppArmor/SElinux у нашей виртуализации? Могу ответить лишь о части перечисленного в тексте: Масштабируемость/Оптимизация/Простота мониторинга. «Безопасность» и «Простота использования» немного не ясны для меня, но что-то уже начинает проясняться.
В статье есть только на уровне доп.ссылок материалы о логировании iptables и прочем. О мониторинге — нужно писать отдельную статью. Вот чесслово, был бы материал/книга, которая назывался бы «Безопасность сервера. Регламенты и рецепты управления» — сел бы и перевел.
Если к первому вашему комменту вернуться, то вот что я скажу
Честно говоря не вижу никаких преимуществ перед тем же apparmor + нормальное распределение прав + iptablesНе могу ответить, т.к. настройка AppArmor/SElinux для меня начинается и заканчивается одной командой конфига:
SELINUX=disabled
Буду, наверно, разбираться и с SElinux, но пока мы прислушиваемся к авторам туториала и, временно, его выключаем.
В чем же преимущество над AppArmor/SElinux у нашей виртуализации? Могу ответить лишь о части перечисленного в тексте: Масштабируемость/Оптимизация/Простота мониторинга. «Безопасность» и «Простота использования» немного не ясны для меня, но что-то уже начинает проясняться.
Вижу минус в неэффективности использования памяти, размазанному файловому кешу и большей нагрузке на процы (да и на диск тоже).Честно говоря, сейчас я вижу общую нагрузку всех проектов, общее потребляемое ими количество памяти, общую нагрузку и общие ошибки. Мне легче и проще выстроить с ноля сервер и его стек, чем оставить инструкцию для будущих поколений, что и почему у нас так странно работает и выглядит, и оптимизировать каждый новый сайт/приложение на сервере в поисках причин сжираемой памяти и дисковой нагрузки. После такой настройки можно брать специалиста по конкретному узкому кругу вопросов и, не передавая ему рутовые пароли, давать настраивать и оптимизировать «от и до» на отдельной секьюрно-огороженной виртуальной машине
Когда я ломаю сайт в вашей схеме, я автоматически получаю доступ к БД как минимум под учёткой для работы с сайтом (ибо в конфигах сайта эти данные есть), к рассылке почты и мемкешу. То есть я спокойно смогу сделать фишинговый сайт и/или разослать спам или поддосить кого-нибудь. То же самое я смогу сделать и на обычном хостинге, где все службы на одном физическом компеВот когда вы будете ломать проксирующий сервер или бэкенд статики и скриптовый бэкенд, которые доступны только для этого самого проксирующего сервера по локалке, то наверно речь идет о сплойтах, SQLInjection, XSS и прочем, у меня будут оганиченные права к БД (чуть ли не SELECT-only), а CMS будут под версионным контролем и всякие робкие вздрагивания будут логироваться и мониторится системой уведомления… Т.е. тут комплекс мер нужен, а не просто виртуалки. Это ясно. А в какой схеме вам будет тяжело получить доступ к БД/мэмкешеду?
где профит?Ну… мне заплатят за настрйоку. )))
Кстати, была тут в мае 2012 миленькая статья об апликейшн фаерволе SElinux от Positive Technologies. Весьма поучительная. Для разработчиков кода и администраторов ресурсов.
Sign up to leave a comment.
Повышаем безопасность стека web-приложений (виртуализация LAMP)