Comments 245
Я видел код, который перегружает оператор '%' чтобы обозначить продукт с точкой
это dot product что ли? вашу ж мать, переводчики…
Второй закон кододинамики: энтропия кода не убывает.
Для повышения читаемости кода автору можно только посоветовать включить антиалиасинг, сменить шрифт и цветовую схему.
Так в оригинале статьи.
Но в целом да — весьма странно писать о читабельности кода, и не позаботиться о нормальных шрифтах. Черные куски кода на светлом фоне режут глаз, фигурная скобка слабо отличается от круглой (особенно чудесно смотрится в K&R стиле).
Но в целом да — весьма странно писать о читабельности кода, и не позаботиться о нормальных шрифтах. Черные куски кода на светлом фоне режут глаз, фигурная скобка слабо отличается от круглой (особенно чудесно смотрится в K&R стиле).
меня больше радует примеры кода в png
Шрифты — это вообще отдельная тема войны. Я вот все хочу увидить грамотный срач статью на эту тему на хабре :)
Он тут хотя бы моноширный. У меня есть книга по C++, где автор (издатели?) решили не делать его таким. Через час чтения вставки кода превращаются в не читаемый комок текста.
Было :) — habrahabr.ru/post/120316/
Сложилось впечатление, что автор назовет прекрасным любой код, обработанный code beautifier'ом с нужными настройками :)
Интересно было почитать, спасибо за перевод!
Вообще, при чтении таких статей нужно понимать, что многие вещи субъективны и являются делом вкуса.
Например, расстановка фигурных скобок в таком виде:
Аргумент атвора — экономия вертикального места на экране. Но это также и дело привычки — например, для моих глаз намного читабельнее текст с бОльшими вертикальными отступами:
Читать гораздо приятнее. Исключительно ИМХО.
По поводу написания комментариев в коде и вынесения всего, что только можно, в отдельные функции — если сранивать с более длинными функциями, разделёнными на «подсекции» при помощи комментариев-подзаголовков, то это просто-напросто два разных подхода к организации кода. Мы к такому выводу пришли в нашей команде после пары недель ожесточённых споров :)
Вообще, при чтении таких статей нужно понимать, что многие вещи субъективны и являются делом вкуса.
Например, расстановка фигурных скобок в таком виде:
if(smth) {
doSmth();
} else if(smthElse) {
doSmthElse();
}
Аргумент атвора — экономия вертикального места на экране. Но это также и дело привычки — например, для моих глаз намного читабельнее текст с бОльшими вертикальными отступами:
if(smth)
{
doSmth();
}
else if(smthElse)
{
doSmthElse();
}
Читать гораздо приятнее. Исключительно ИМХО.
По поводу написания комментариев в коде и вынесения всего, что только можно, в отдельные функции — если сранивать с более длинными функциями, разделёнными на «подсекции» при помощи комментариев-подзаголовков, то это просто-напросто два разных подхода к организации кода. Мы к такому выводу пришли в нашей команде после пары недель ожесточённых споров :)
Поддерживаю Shedal. Код 2го вида более читабельный!
Когда «плоская» функция разрастается в длину и делится на «секции» комментариями — это нормально. Главное, чтобы глубина циклов-условий не была по пять уровней. :)
Конечно более читаемый, мозгу не надо выискивать где какая скобка кончается и начинается ли другая. Автор может не очень богат и не может себе позволить монитор full hd, который поворачивается вертикально и места становится просто завались. да т 1200пх вполне достаточно.
Соглашусь с Вами, у нас половина разработчиков сидит на full hd мониторах с вертикальной ориентацией — очень удобно.
Еще была шутка: «Вы там говорили, функция должна помещаться на одном экране? У меня помещается». :)
Еще была шутка: «Вы там говорили, функция должна помещаться на одном экране? У меня помещается». :)
Не надо выискивать скобки. Надо выискивать отступы — это гораздо быстрее. А скобки всегда будут располагаться либо в начале либо в конце строки.
чувствуется голос питон-адепта :)
А вот и нет. Python уважаю, но практически на нём ничего не пишу, в основном Java.
Ещё вот что — обычно расцветка синтаксиса в различных редакторах такова, что скобки как можно сильнее выделяются из фона (в этой статье ярко-красные, например). Я, напротив, использую цветовые схемы, где скобки от фона отличаются слабо (например, светлый серо-голубой на белом фоне), именно потому что нет нужды, чтобы глаз на них спотыкался.
Ещё вот что — обычно расцветка синтаксиса в различных редакторах такова, что скобки как можно сильнее выделяются из фона (в этой статье ярко-красные, например). Я, напротив, использую цветовые схемы, где скобки от фона отличаются слабо (например, светлый серо-голубой на белом фоне), именно потому что нет нужды, чтобы глаз на них спотыкался.
Тю, такое скажет и лиспер, и хаскелист, и рубист, и ассемблероид… Везде принято делать отступы и ориентироваться по ним. Что касаемо расстановки скобок, то один мой коллега предложил простой и логичный вариант — ставить их тогда, когда тело оператора содержит более одной строки. То есть:
foreach (item; list)
process(item);
но
foreach (item; list)
{
if (!item.isProcessed())
process(item);
}
Соответственно, пример из топика будет выглядеть так:
while (a)
{
if (b > c)
d = c;
else if (c > d)
e = f;
else
{
if (q)
a = 0;
else
b = 0;
}
}
foreach (item; list)
process(item);
но
foreach (item; list)
{
if (!item.isProcessed())
process(item);
}
Соответственно, пример из топика будет выглядеть так:
while (a)
{
if (b > c)
d = c;
else if (c > d)
e = f;
else
{
if (q)
a = 0;
else
b = 0;
}
}
По итогам голосования на моём комментарии и карме можно видеть, что 2/3 людей любят переносить открывающую фигурную скобку, 1/3 не любит, и 1 человек ОЧЕНЬ не любит :)
По итогам голосования на моём комментарии
На самом деле сказалось то, что люди охотнее ставят «плюс», чем «минус». Я вот не люблю, а минусовать даже не думал. Скорее всего, если бы любил, то плюсанул бы. На самом деле стронников каждого из вариантов практически равное количество.
Мой комментарий о голосовании — полушутка. Понятное дело, что здесь много факторов, и одним из основных является общепринятое форматирование для конкретного языка форматирования.
общепринятое форматирование для конкретного языка форматирования
Не встречал такого ни для одного из языков. Соответствующие стандарты так же молчат на эту тему.
Что касается открывающих скобок, расположенных на строке с выражением, то контраргументом, наверное будет то, что если кому-то мешает открывающая скобка на новой строке, потому как код метода не влезает в монитор, то может стоит пересмотреть код метода и уменьшить лапшеобразность?
вроде как java code style рекомендует не переносить фигурные скобки, хотя я это не соблюдаю )
А как же Python и его pep8?
Для C#, в примерах кода как в конвенциях от MS, так и в MSDN, открывающая фигурная скобка всегда переносится на новую строку. То же самое — во всех проектах на C#, что я видел.
Это я и называю общепринятым форматированием — когда в подавляющем большинстве кода есть какая-то закономерность.
Это я и называю общепринятым форматированием — когда в подавляющем большинстве кода есть какая-то закономерность.
По итогам голосования на моём комментарии и карме можно видеть, что 2/3 людей любят переносить открывающую фигурную скобку, 1/3 не любит, и 1 человек ОЧЕНЬ не любит :)
Интересно, что «проголосовало» уже втрое больше участников, но соотношение между «остроконечниками» и «тупоконечниками» всё время сохранялось :)
Почему-то принято считать, что первый стиль — для Джавы, второй — для Си, Си-шарпа. Иногда, к сожалению, доходит до холиваров.
Но это также и дело привычки — например, для моих глаз намного читабельнее текст с бОльшими вертикальными отступами Читать гораздо приятнее. Исключительно ИМХО.
Я думаю, что дело в опыте. С опытом более компатные куски кода воспринимаются лучше, потому что легко заметить паттерны, какие-то «решения по-умолчанию», опытный программист просматривает программу кусками и чем больше можно захватить одним взглядом — тем лучше.
Менее опытный же требует «пространства», разделения програмы на мелкие кусочки, выделения ключевых слов. Я и сам раньше любил код с бОльшими вертикальными отступами, но чем дальше, чем больше стараюсь «экономить» вертикальное место и, при этом, не расти вширь
Ну, вы, наверное, судите только по себе. Я знаю людей с 15-летним стажем, которые читают код как книжку, и любят, чтобы он был «свёрстан» эстетично — со смысловыми разносами блоков, и т.п. В том числе, используют и перенос открывающей фигурной скобки на новую строку.
Думаю, что всё-таки, это дело привычки и вкуса.
Думаю, что всё-таки, это дело привычки и вкуса.
которые читают код как книжку, и любят, чтобы он был «свёрстан» эстетично — со смысловыми разносами блоков
Странная манипуляция смыслом. Кто сказал, что компактный код свёрстан не эстетично?)
Эстетика кода начинается только после его компиляции (или при его выполнении, если это скрипт). Эстетика — в искусстве управления машиной!
Когда через каждые три машинные команды воткнуты call'ы в отладочную процедуру, а каждая пустяковая процедура обернута каскадом из push и pop — это неэстетично.
Еще пример: Регулярные выражения: PHP(POSIX) vs Perl. Ускорение 60-200%
Когда через каждые три машинные команды воткнуты call'ы в отладочную процедуру, а каждая пустяковая процедура обернута каскадом из push и pop — это неэстетично.
Еще пример: Регулярные выражения: PHP(POSIX) vs Perl. Ускорение 60-200%

Также выскажусь в поддержку второго варианта — симметрично расположенные скобки позволяют глазам «цепляться».
Я использую этот вариант даже в Java, хотя «родным» там все таки считается первый вариант.
Еще скажу кое-что о правой границе: очень маленькая граница в купе с использованием первого варианта делают код почти не читаемым. Для примера посмотрите на исходный код Android. Правая граница у них приблизительно 100 символов (странно что не 80 :D) — это 1/3 ширины моего рабочего стола. Понимаю, что у них наверное стандарт такой, но стандарт должен отвечать текущим требованиям, а не требованиям времен текстового режима.
Я использую этот вариант даже в Java, хотя «родным» там все таки считается первый вариант.
Еще скажу кое-что о правой границе: очень маленькая граница в купе с использованием первого варианта делают код почти не читаемым. Для примера посмотрите на исходный код Android. Правая граница у них приблизительно 100 символов (странно что не 80 :D) — это 1/3 ширины моего рабочего стола. Понимаю, что у них наверное стандарт такой, но стандарт должен отвечать текущим требованиям, а не требованиям времен текстового режима.
Извините, но 80 символов — это очень много. Когда у меня код даже приближается к этой отметке, то я уже думаю, что с ним не так. Сам стараюсь делать не больше 60-ти. Широкий код в большинстве случаев признак плохой архитектуры.
Не вижу тесной связи между шириной кода и его архитектурой.
А впрочем смотрите сами:
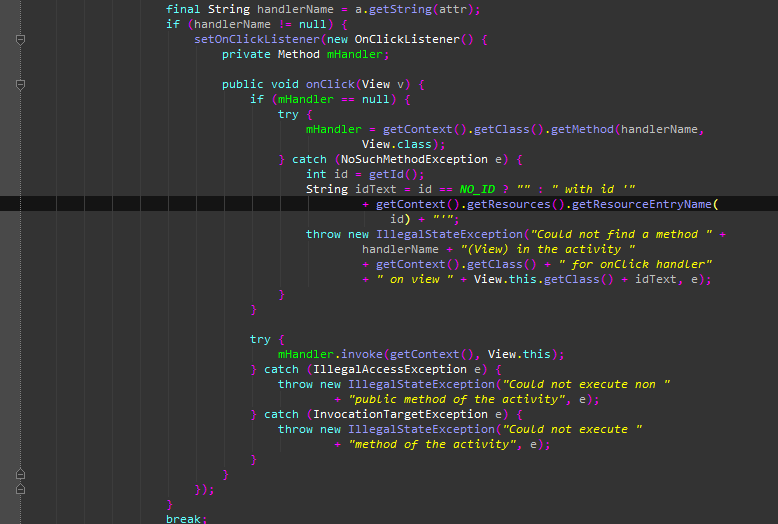
Это часть конструктора класса android.view.View
А впрочем смотрите сами:
Это часть конструктора класса android.view.View
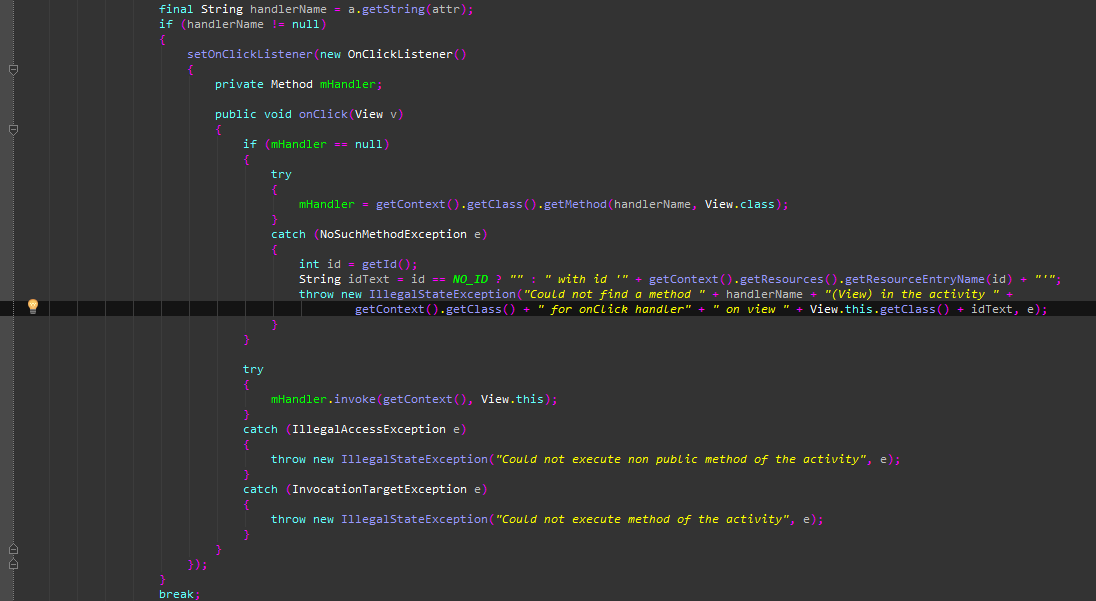
Я, пожалуй, с вами соглашусь, но C++ здесь явное исключение, для него соблюдать ширину в 80 символов без переносов ну никак не получится. С их-то шаблонами, unordered_map-ами да неймспейсами, а уж, если еще и итераторы сюда добавить.
>> Широкий код в большинстве случаев признак плохой архитектуры.
Не забывайте ставить «ИМХО».
В C#/.NET с его naming guidelines в 60 ничего не уместится. Чаще вижу ограничение в 120.
Не забывайте ставить «ИМХО».
В C#/.NET с его naming guidelines в 60 ничего не уместится. Чаще вижу ограничение в 120.
Я пользовался bsd-стилем (видимо, дело в том, что первый язык был паскаль), пока не начал коммитить в проект с более компактной версией. Компактность рулит.
а можно же ещё и так, если одна строка
if(smth) doSmth();
else if(smthElse) doSmthElse();
if(smth) doSmth();
else if(smthElse) doSmthElse();
да там в каждом абзаце праздник
с условиями и фигурными скобками автор окончательно запутался, так и не разобравшись, насколько важна экономия места.
в целом правила «для того, что мне нравится, приводим хорошие примеры, для остального — плохие» придерживается строго.
ну а на расскаже о прекрасности printf я просто заплакал. я сам стрингстримом не пользуюсь, но рассказывать про великолепие printf — это уже перебор. особенно удобен и прекрасен он, когда начинаешь пересчитывать проценты и сопоставлять их с параметрами.
с условиями и фигурными скобками автор окончательно запутался, так и не разобравшись, насколько важна экономия места.
в целом правила «для того, что мне нравится, приводим хорошие примеры, для остального — плохие» придерживается строго.
ну а на расскаже о прекрасности printf я просто заплакал. я сам стрингстримом не пользуюсь, но рассказывать про великолепие printf — это уже перебор. особенно удобен и прекрасен он, когда начинаешь пересчитывать проценты и сопоставлять их с параметрами.
Я понимаю, что Вы написали про «исключительное ИМХО», но все равно никогда не мог понять, что в этом стиле может быть такого приятного. Открывающаяся фигурная скобка является чистым синтаксическим мусором, поскольку фактически закрывающаяся скобка соответствует самому оператору, а не фигурной скобке. Именно поэтому открывающаяся скобка никому не нужна (кроме удовольствия компилятора) и хочется засунуть ее в самое неприметное место. Т.е. если бы вместо закрывающейся скобки надо было писать fi для if и rof для for, то было бы гораздо логичнее (нотация Гриса).
Дело, наверное, не в самой скобке, а в визуальных отступах между строками. Я даже когда на JS пишу, и открывающую скобку не переношу на новую строку, всё равно следующую строку оставляю пустой.
Для меня это что-то вроде логического отступа между заголовком блока и его телом.
Плюс, когда обе скобки находятся на одном уровне, глаз их мгновенно схватывает. Впрочем, это уж точно исключительно дело привычки.
Для меня это что-то вроде логического отступа между заголовком блока и его телом.
Плюс, когда обе скобки находятся на одном уровне, глаз их мгновенно схватывает. Впрочем, это уж точно исключительно дело привычки.
Статья — красота! Спасибо!
Всегда считал, что красота кода заключается не в выборе способа расстановки скобок или форматирования, а в его сруктуре — разбиении на классы, модули, выделение ключевых компонентов, что в результате приводит к простоте и ясности, отсутсвию лишнего кода и быстроте, как следствию. А то о чем написал автор в большой сепени сугубо индивидуально. Особенно то, что касается форматирования. В общем, анализ тут очень поверхностный, имхо.
Как-то поверхностно выглядит статья, например абзац про комментарии.
С большинством дифирамбов мне как-то трудно согласиться. Например, с хвалой форматированию кода. Мне кажется, что это вкусовщина. Меня, например раздражают открывающие скобки в той же строке или несколько выражений, записанных в одной строке. Но мне не лень нажать две кнопки в IDE и привести форматирование любого исходника к удобному для меня виду.
На мой взгляд, трюки, вроде
С большинством дифирамбов мне как-то трудно согласиться. Например, с хвалой форматированию кода. Мне кажется, что это вкусовщина. Меня, например раздражают открывающие скобки в той же строке или несколько выражений, записанных в одной строке. Но мне не лень нажать две кнопки в IDE и привести форматирование любого исходника к удобному для меня виду.
На мой взгляд, трюки, вроде
...split(..., const float epsilon, ...) только снижаю читабельность, потому как, подсознание нашептывает, что epsilog передается по ссылке, но не модифицируется, ан нет.А вообще, зачем это const float? Как будто float может измениться, странно смущает меня это почему-то.
Про выравнивание. Есть два понятия: indentation и alignment, вот для первого табы — самое оно, а второе делать табами — сомнительно, потому, что кто-то может не любит табы в 4 пробела, сделает в 2, и все поедет к черту.
Про выравнивание. Есть два понятия: indentation и alignment, вот для первого табы — самое оно, а второе делать табами — сомнительно, потому, что кто-то может не любит табы в 4 пробела, сделает в 2, и все поедет к черту.
А вообще, зачем это const float? Как будто float может измениться, странно смущает меня это почему-то.
Это защита не от изменения переменных по отношению к вызываемой функции, а гарантия того, что программист ничего не перепутает и не начнет пользоваться переменной внутри самой функции кроме как в виде входного параметра. Т.е. таким образом четко разделяются входные параметры от переменных функции, чтобы увеличить читаемость кода.
У них свой стиль кода по всему проекту.
Один из пунктов Use ‘const’ as much as possible, я думаю вы поняли.
Что значит «кто-то может не любит»? Опять же у них свой стиль…
Один из пунктов Use ‘const’ as much as possible, я думаю вы поняли.
Что значит «кто-то может не любит»? Опять же у них свой стиль…
финальный модификатор const после списка параметров — мой самый любимый. Он указывает на то, что idSurface::Split() не будет изменен самой поверхностью (surface).Небольшая неточность: не «не будет изменен самой поверхностью», а «не будет изменять саму поверхность».
Автор имеет в виду, что const-метод не может менять объект, для которого вызван. Хотя полностью надеяться на это нельзя, поскольку mutable-переменные никто не отменял.
За последние 6 недель разработки Dyad я дописал 13k строк кода.Вот это скорость! При стандартном 8-часовом рабочем дне получается примерно 1 строчка кода в минуту.
Видимо, проект так нравился автору, что он его и дома не оставлял ;)
> Он указывает на то, что idSurface::Split() не будет изменен самой поверхностью (surface).
Ээ, чего? Функция изменяется поверхностью?
Может, наоборот, а?
Ээ, чего? Функция изменяется поверхностью?
Может, наоборот, а?
Любопытно, почему это геттеры-сеттеры лишние. Понадобится ввести валидацию входных данных — это будет намного проще ввести с сеттером, чем лазить по всему коду и ставить проверки где нужно. Я лично стараюсь вводить геттеры-сеттеры даже тогда, когда уверен что эта переменная может быть свободно модифицирована и считана.
А понадобится многопоточный доступ к полю сделать так вообще здорово с сеттерами-геттерами.
Еще бывает нужно логгировать доступ к полю. Главным образом для дебага, но все же.
Еще бывает нужно логгировать доступ к полю. Главным образом для дебага, но все же.
Если так подумать то если понадобится валидации или что-то еще, то можно сделать сетер и гетер, когда весь исходный код под контролем не должно быть с этим проблем. Искать все места по коду чаще всего довольно просто и из-за статической типизации компилятор не допустит того что вы где-то забудете поменять обращение к переменной на метод (в отличие например от JavaScript). Ведь действительно очень часто геттеры/сеттеры остаются тривиальными всю жизнь, сколько лишнего кода приходится добавлять из-за принципа, которое прививают С++ программистам чуть ли не с детского сада.
Эх, дело-то в том, что по C++ плачет нормальная IDE, способная делать с кодом на С++ всё то, а лучше больше, что может делать с кодом на Java IntelliJ IDEA. Тогда и сеттеры-геттеры будут автоматически в код вставляться (при первом создании класса), и все обращения к полю будут мгновенно корректироваться (при добавлении геттеров-сеттеров впоследствии) — и многое другое. Вряд ли кто-то станет спорить, что код на C++ довольно шумный — и очень многое может сделать IDE автоматически. Надежда вот на Clang — что его инструменты развяжут руки разработчикам плагина к той же IDEA, QtCreator'а, KDevelop'a и пр.
Если код написан так, что его поддержка в notepad более затруднительна, чем в специальной IDE — это распространённая и печальная проблема.
Что-то мне подсказывает, что поддержка кода любого приложения, для которого имеет смысл понятие «поддержка», в notepad более затруднительна, чем в специальной IDE. Как бы профессионально этот код не был выполнен.
Так обычно и бывает. Но это в первую очередь проблемы средств языка и качества кода, нежели проблемы среды разработки. Программисты слишком часто полагаются на возможности IDE там, где простого текстового редактора в сочетании с grep могло бы хватить. Я имел удовольствие работать с сорцами на несколько миллионов строк plain C, где этого было достаточно.
Еще немного, и мы выясним, что «простой текстовый редактор» — это vim или emacs, а под «работой с сорцами» и «поддержкой» понимается внесение незначительных изменений в части проекта, надо которыми вы уже давно и много работаете — и знаете их почти наизусть :) Никто не спорит, что хороший код поддерживать легче. Но совершенно ясно, что в первоначальной форме ваше заявление, мягко говоря, абсурдно.
Кстати, JetBrains по-тихому уже пилят задел для C++ IDE, в рамках AppCode (C++ она тоже должна поддерживать же)
Мда… Кастомный поиск всегда печальный: C++ (JetBrains), C++ (google, site: JetBrains). У второго по первой же ссылке можно найти пункт «C/C++ Support» для AppCode — и звучит он довольно вкусно. Надо попробовать :)
Процесс превращения явы в ту многословную хрень, которой она является сейчас, во многом произошел из-за введения этих самых IDE-фишечек вместо нормальной эволюции языка. Никакому языку не надо такого счастья, в особенности С++.
Для С++ нормальная поддержка IDE невозможна, потому что грамматика языка контекстно-зависима. Подробности есть в C++ FQA
Не совсем так: для нормальной поддержки С++ IDE должна иметь полноценный парсер C++. В частности, одной из целей создания Clang была нормальная поддержка С++ IDE.
Одной из главных задач Clang является поддержка инкрементной компиляции, позволяющей более тесно интегрировать компилятор и графический интерфейс среды разработки, в отличие от GCC, который был создан для работы в классическом цикле «компиляция-линковка-отладка». В отличие от GCC, ориентированного преимущественно на кодогенерацию, Clang стремится предоставить универсальный фреймворк для парсинга, индексации, статического анализа и компиляции языков семейства Си. В частности, Clang не производит упрощений исходного кода на этапе парсинга (как это делает GCC), гарантируя точное воспроизведение исходного текста в AST.
Всегда думал что функции типа serVar(..) и getVar() создаются только если надо контролировать значение.
Например чтобы переменная никогда не была равна нулю.
Поэтому думаю что не всегда следует использовать переменную в public.
Например чтобы переменная никогда не была равна нулю.
Поэтому думаю что не всегда следует использовать переменную в public.
Если не изменяет память то вообще не рекомендуется использовать паблик-переменные. Они потенциально опаснее, ибо их модификации неконтролируемы.
вообще это дань инкапсуляции. Класс не должен показывать никакие свои поля во вне. Общение с объектом класса только через интерфейс. Это полезно не только для проверки переменной на ноль, но и возможностью в любой момент поменять в одном только методе getX() способ получения этого самого X без изменения другого кода программы. Ну и при наследовании всякое может случиться, в том числе и возможная перегрузка сеттеров и геттеров.
Некоторые моменты весьма спорны. Вот с const и с выравниванием табуляцией имен методов и переменных согласен.
довольно забавно, автор предлагает сделать все переменные константными, но при этом восхищается «открытыми» полями в классе. вообще мне кажется только в С++ какой-то особый культ поклонения const :)
Мм, а разве есть противоречие между этими двумя пунктами?
Есть. Открытые переменные могут быть модифицированы как угодно без заведомо созданной проверки значения. Константы — не могут быть модифицированы. Вот и противоречие.
Мне кажется автор имел в виду, что следует сделать все переменные константными по умолчанию, и открывать нужные для редактирования вручую. А открывать хоть паблики, хоть обычные переменные это не важно.
это все понятно, но пока такое не сделано делать поля в классе «открытыми»(при этом трепетно относясь к возможности случайного изменения переменных) нелогично. а вообще мне одному его предложение насчет всеобщей константности кажется бредовой? ошибок от случайной записи неконстанты в моей практики было ничтожно мало, зато утечек памяти и переполнения буфера хоть отбавляй. в других языках к этому относятся проще, зато здесь как будто это корень всех зол
class ClassType {
public:
const int var;
ClassType(int var) : var(var) {}
};
не только в C++. Последнее время до всех доходит что иммутабельность — это хорошо :)
Возможно, я еще пожалею об этом, но напишу:
Я ненавижу else и else if в условиях, и пишу «ленивые» функции и циклы.
Ленивые — потому, что они хотят как можно быстрее завершиться.
В этом случае нет многоступенчатой вложенности
В циклах — тоже самое. Сперва проверяются условия для break или continue, а потом идет сам код цикла.
Кажется, этому стилю есть какое-то название, но я его не смог выгуглить — придумал «ленивое».
Я ненавижу else и else if в условиях, и пишу «ленивые» функции и циклы.
Ленивые — потому, что они хотят как можно быстрее завершиться.
оригинал
int check_param_and_do_someting(int param)
{
if( param > 0 )
{
if( param % 3 == 0 )
{
//do something
return 0;
}else
{
return -2;
}
}else
{
return -1;
}
}
"ленивый" вариант:
int check_param_and_do_someting(int param)
{
if( param <= 0 )
{
return -1;
}
if( param % 3 != 0 )
{
return -2;
}
//do something
return 0;
}
В этом случае нет многоступенчатой вложенности
В циклах — тоже самое. Сперва проверяются условия для break или continue, а потом идет сам код цикла.
Кажется, этому стилю есть какое-то название, но я его не смог выгуглить — придумал «ленивое».
Ага, но если это си, то все используемые ресурсы придется перед каждым ретурном освобождать руками. Вот вам и дублирование. Так что палка о двух концах.
А если на С, goto писать.
Ну, даже если не вдаваться, насколько goto зло, то по большинству стайлгайдов оно запрещено. То есть велика вероятность, что не дадут.
Если умеешь пользоваться goto, то никакого зла за этим нет. Тем более, что вот именно в этом случае goto был бы к месту, ибо не мешает читаемости и даже наоборот.
На си goto cleanup общепринятый стандарт, который я встречал чаще, чем не встречал.
Про goto cleanup писали выше. Встречал не раз в весьма серьезных проектах (Linux и CPython, к примеру).
Его нужно аккуратно использовать. Не злоупотреблять. Так же как макросы, например. Он много где используется в крупных проектах, в ядре linux, например.
Речь скорее не о выходе из функции, а об инвертировании слишком разветвленных условий — тогда уменьшается степень вложенности.
> если это си, то все используемые ресурсы придется перед каждым ретурном освобождать руками
Как и в исходном варианте.
Как и в исходном варианте.
я тоже так пишу, сразу видны предусловия функции. ну и, конечно, многоуровневая вложенность серьезно затрудняет чтение кода ИМХО
Возможно это — www.codinghorror.com/blog/2006/01/flattening-arrow-code.html
Тоже заметил за собой «сдвиг» в сторону подобного стиля: выявить «нестандартные» ситуации как можно раньше и выйти.
И код более плоским и читабельным получается.
И код более плоским и читабельным получается.
+1 Вот — редкий(?) пример пользы лени, в итоге выйдет более красивый машинный код. Только я бы писал if'ы еще ленивее: пишется и читается проще (прокрутка исходника туда-сюда из-за его длины по вертикали ворует время, следовательно — скрытые издержки и не Lean):
int check_param_and_do_someting(int param)
{
if( param <= 0 ) return -1;
if( param % 3 != 0 ) return -2;
//do something
return 0;
}
По объективным причинам всегда предпочтительнее писать условное выражение под условием. Например, bp на выражении поставить не получится (по крайней мере, в известных мне IDE).
А можно к вам вопрос? Как часто вы оцениваете «красоту машинного кода», какими инструментами пользуетесь, чтобы до него добраться и/или оценить красоту, и… каковы критерии этой красоты? И еще, позвольте еще один вопрос: скажите, вы не пробовали писать на C++ код, который компилируется в машинный, содержащий стихотворения на hexspeak'е? Это было бы просто потрясающе, особенно если исходный код не содержит таких текстов — а именно получается в процессе компиляции! Заранее спасибо за ваши ответы.
Кстати сказать, стиль традиционный для Форта и для Перла. Очень удобный, поскольку позволяет сразу проверить и отсеять ошибочные аргументы. Еще удобнее инвертировать условие проверки, чтобы проверка превратилась в аналог охраняющего выражения (guard).
Автор мог бы просто прочесть code convention ftp.idsoftware.com/idstuff/doom3/source/CodeStyleConventions.doc
вместо того, что бы пытаться восстановить его по исходникам
вместо того, что бы пытаться восстановить его по исходникам
В Doom 3 действительно очень хороший код, это уже ни раз обсуждалось. Как с точки зрения выбранного стиля, так и архитектурно.
Но большая часть того, что описывает автор в статье — результат жесткого придерживания корпоративному стилю, что и породило однообразие и удобочитаемость. Я могу привести другой пример отличного исходного кода, но с другим, во многом противоположным, соглашением — Ogre3D. Его читабельность не хуже, а как по мне — даже лучше.
В статье Кармак не зря упоминает«Эффективное использование C++» Скотта Майерса — настоятельно рекомендую к прочтению. Отпадут простые вопросы «зачем везде нужен const?», возможно, научитесь писать безопасные относительно исключений функции и многое другое.
Если пробежаться по пунктам статьи, я могу сказать следующее:
1) Мало комментариев — плохо. Много комментариев — тоже плохо.
Их должно быть ровно столько, чтобы убрать любые неоднозначности. Так же я за достаточно подробные комментарии в объявлении функции (тут, видимо, сказывается общая приверженность к инструменту для генерации документации — Doxygen).
Например, прочитав это объявление, даже незнакомый с остальной частью кода программист, сразу все поймет:
2) Отступы — дело привычки, ровно как и расположение открывающейся скобки. Тут даже странно говорить про удобство, профессионализм или что-то еще. Как я уже писал выше, у нас половина разработчиков работают на Full HD мониторах в вертикальной ориентации — все всегда помещается.
3) Отказ от шаблонов в основном API — скорее правильный выбор, нежели нет. В конце-концов, хорошо оперируют шаблонами достаточно малое количество программистов.
Но на низком уровне убирать шаблоны — странное решение. То, что привел в пример автор, смотрится как минимум странно. Вполне возможно, у него какое-то странное представление о шаблонах.
А boost сложен в чтении обычно потому, что он предельно универсален. Они ведь не знают, что будут писать конечные пользователи библиотеки, в отличие от ребят из id, которые четко знали, зачем и для чего они переписывают STL.
4) Использование get/set в именах функции — опять же удобство для программиста.
Например, используя автодополнения кода в своей IDE, я, даже не сильно зная API, могу просто написать get и получить полный список всех доступных мне функции, возвращаемых данным классом. Аналогично с set.
Использование же функции, возвращающих значение без префикса get, иногда просто приводит к неоднозначности.
Например:
Что значит этот код? Мы инициализируем систему рендера? Или мы просто устанавливаем систему рендера, но ничего с ней не делаем? А может мы ее добавляем в какой-то список доступных систем рендера? Неоднозначно.
Другое дело:
Тут все яснее — мы устанавливаем систему рендера. Инициализации или что-то там еще в этой функции проходить не должны.
5) stringstream
Лучше всего использовать boost::format. Это и безопасно, и понятно. Рекомендовать вместо stringstrean использовать printf — очень, очень странно. printf небезопасен, в местах его использования очень часто вылезают ошибки (о чем, кстати, написано в статье). Я не стал бы слушать человека, который рекомендуют использовать printf, когда рядом есть огромное число куда более хороший инструментов.
10) Собственно, не использовать перезагрузку операторов — тоже весьма странный совет. Перезагрузка operator() и operator= — это вообще фундамент C++.
11) Горизонтальные отступы — тоже на любителя. Если привыкнуть, я думаю, это нормально.
На вертикальный мониторах это будет хрен знает как смотреться. А на больших горизонтальных (у меня 32") — придется мотать головой влево-вправо, чтобы найти соответствие возвращаемому типу функции и самой функции. Можно, конечно, подсвечивать линии, но все же это спорное удобство.
Пожалуй, на этом можно закончить. Выбирайте свой стиль, синхронизируйте его с местом работы и в путь! :)
Но большая часть того, что описывает автор в статье — результат жесткого придерживания корпоративному стилю, что и породило однообразие и удобочитаемость. Я могу привести другой пример отличного исходного кода, но с другим, во многом противоположным, соглашением — Ogre3D. Его читабельность не хуже, а как по мне — даже лучше.
В статье Кармак не зря упоминает«Эффективное использование C++» Скотта Майерса — настоятельно рекомендую к прочтению. Отпадут простые вопросы «зачем везде нужен const?», возможно, научитесь писать безопасные относительно исключений функции и многое другое.
Если пробежаться по пунктам статьи, я могу сказать следующее:
1) Мало комментариев — плохо. Много комментариев — тоже плохо.
Их должно быть ровно столько, чтобы убрать любые неоднозначности. Так же я за достаточно подробные комментарии в объявлении функции (тут, видимо, сказывается общая приверженность к инструменту для генерации документации — Doxygen).
Например, прочитав это объявление, даже незнакомый с остальной частью кода программист, сразу все поймет:
/** Find all file or directory names matching a given pattern
in this archive.
@note
This method only returns filenames, you can also retrieve other
information using findFileInfo.
@param pattern The pattern to search for; wildcards (*) are allowed
@param recursive Whether all paths of the archive are searched (if the
archive has a concept of that)
@param dirs Set to true if you want the directories to be listed
instead of files
@return A list of filenames matching the criteria, all are fully qualified
*/
virtual StringVectorPtr find(const String& pattern, bool recursive = true,
bool dirs = false) = 0;
2) Отступы — дело привычки, ровно как и расположение открывающейся скобки. Тут даже странно говорить про удобство, профессионализм или что-то еще. Как я уже писал выше, у нас половина разработчиков работают на Full HD мониторах в вертикальной ориентации — все всегда помещается.
3) Отказ от шаблонов в основном API — скорее правильный выбор, нежели нет. В конце-концов, хорошо оперируют шаблонами достаточно малое количество программистов.
Но на низком уровне убирать шаблоны — странное решение. То, что привел в пример автор, смотрится как минимум странно. Вполне возможно, у него какое-то странное представление о шаблонах.
А boost сложен в чтении обычно потому, что он предельно универсален. Они ведь не знают, что будут писать конечные пользователи библиотеки, в отличие от ребят из id, которые четко знали, зачем и для чего они переписывают STL.
4) Использование get/set в именах функции — опять же удобство для программиста.
Например, используя автодополнения кода в своей IDE, я, даже не сильно зная API, могу просто написать get и получить полный список всех доступных мне функции, возвращаемых данным классом. Аналогично с set.
Использование же функции, возвращающих значение без префикса get, иногда просто приводит к неоднозначности.
Например:
void renderSystem(RenderSystem* system);
Что значит этот код? Мы инициализируем систему рендера? Или мы просто устанавливаем систему рендера, но ничего с ней не делаем? А может мы ее добавляем в какой-то список доступных систем рендера? Неоднозначно.
Другое дело:
void setRenderSystem(RenderSystem* system);
Тут все яснее — мы устанавливаем систему рендера. Инициализации или что-то там еще в этой функции проходить не должны.
5) stringstream
Лучше всего использовать boost::format. Это и безопасно, и понятно. Рекомендовать вместо stringstrean использовать printf — очень, очень странно. printf небезопасен, в местах его использования очень часто вылезают ошибки (о чем, кстати, написано в статье). Я не стал бы слушать человека, который рекомендуют использовать printf, когда рядом есть огромное число куда более хороший инструментов.
10) Собственно, не использовать перезагрузку операторов — тоже весьма странный совет. Перезагрузка operator() и operator= — это вообще фундамент C++.
11) Горизонтальные отступы — тоже на любителя. Если привыкнуть, я думаю, это нормально.
На вертикальный мониторах это будет хрен знает как смотреться. А на больших горизонтальных (у меня 32") — придется мотать головой влево-вправо, чтобы найти соответствие возвращаемому типу функции и самой функции. Можно, конечно, подсвечивать линии, но все же это спорное удобство.
Пожалуй, на этом можно закончить. Выбирайте свой стиль, синхронизируйте его с местом работы и в путь! :)
10) Собственно, не использовать перезагрузку операторов — тоже весьма странный совет. Перезагрузка operator() и operator= — это вообще фундамент C++.
Как я понял имелос в виду злоупотребление перегрузкой операторов, типа как всю векторную алгебру сделать через перегруженные операторы.
И что плохого в этом коде?
inline Vector3& operator = ( const Vector3& rkVector )
{
x = rkVector.x;
y = rkVector.y;
z = rkVector.z;
return *this;
}
Может быть, то, что он не нужен вообще, поскольку эквивалентен дефолному копированию?
Если x/y/z, в своюю очередь, имеют нетривиальный operator= — не эквивалентны, т.к. умолчательный конструктор копирования побитовый ;) Один раз начав, трудно остановиться, именно тот случай.
Как ни странно, нет. Я проверил вот такой код:
Оказалось, что при копировании структур Vector оператор Coord::operator=() вызывается, несмотря на то, что Vector::operator=() переопределён не был.
struct Coord{
double *CX;
Coord(){ CX=new double[2]; }
~Coord(){ delete CX; }
Coord(Coord const &p){
CX=new double[2];
CX[0]=p.CX[0]; CX[1]=p.CX[1];
}
Coord &operator=(Coord const &p){
printf("Coord::operator=(%p): %p\n",&p,this);
CX[0]=p.CX[0]; CX[1]=p.CX[1];
return *this;
}
};
struct Vector{
Coord X,Y,Z;
};
Оказалось, что при копировании структур Vector оператор Coord::operator=() вызывается, несмотря на то, что Vector::operator=() переопределён не был.
Да, стал проверять стандарт и понял, что ошибся. 15й параграф пункта 12.8 из С++11 говорит о том, что оно должно быть memberwise. Не знаю, откуда в памяти взялось такое заблуждение.
Опечатка
~Coord(){ delete [] CX; }
И чем же они отличаются в случае double*?
Я не совсем Вас понял. Вы имеете в виду почему delete[], а не просто delete?
У Вас же
Вот если бы было как-то так
то, соответственно и удаляли бы
Я правильно Вас понял?
У Вас же
CX — массив из 2х элементов, а масивы, если память под них выделена с помощью operator new[] — соответственно и зачищаются с помощью operator delete[].Вот если бы было как-то так
double* CX = new double(0.5);
то, соответственно и удаляли бы
delete CX;
CX = NULL;
Я правильно Вас понял?
Наверное, это правильно.
Просто еще со времен Borland C++ 1.0 я не доверяю оператору delete[] (там были какие-то баги), и с тех пор никогда не захватываю массивы из объектов с деструкторами. А если массив состоит из чисел или указателей, то для него оба оператора всё равно сводятся к free(), так что delete работает точно так же… Но да, пожалуй, в правильном коде [] действительно нужны.
Просто еще со времен Borland C++ 1.0 я не доверяю оператору delete[] (там были какие-то баги), и с тех пор никогда не захватываю массивы из объектов с деструкторами. А если массив состоит из чисел или указателей, то для него оба оператора всё равно сводятся к free(), так что delete работает точно так же… Но да, пожалуй, в правильном коде [] действительно нужны.
Пожалуй, действительно не самый удачный пример, хотя, возможно, на некоторых компиляторах такая запись даст некоторый прирост.
Лучше взять operator+(). Без него делать Vector3 vec4 = vec1 + vec2 + vec3; будет несколько проблематично, а в 3д-графике это используется повсеместно.
Лучше взять operator+(). Без него делать Vector3 vec4 = vec1 + vec2 + vec3; будет несколько проблематично, а в 3д-графике это используется повсеместно.
operator +() — да. Но уже для умножения придётся каждый раз вспоминать, какое умножение скаляное, а какое векторное. А при умножении матриц преобразования — лезть в документацию, чтобы вспоминать, какое преобразование первое, а какое второе (если не работаете с этим каждый день). Конечно, они сильно навредили, когда заставили людей работать с векторами-строками, а не столбцами.
Я, видимо, не очень понял мысли.
Допустим, переопределили мы operator*() для скаляра и для вектора:
Vector3 operator*( const float scalar ) const
Vector3 operator*( const Vector3& rhs ) const
Зачем теперь что-то вспоминать?
Допустим, переопределили мы operator*() для скаляра и для вектора:
Vector3 operator*( const float scalar ) const
Vector3 operator*( const Vector3& rhs ) const
Зачем теперь что-то вспоминать?
Нет, я определил
Как я потом вспомню, кто из них *, а кто %?
Собственно, в следующем комментарии всё это обсуждается.
Vector3 operator*( const Vector3& rhs ) const;
и
double operator%( const Vector3& arg ) const { return X*arg.X+Y*arg.Y+Z*arg.Z; }
Как я потом вспомню, кто из них *, а кто %?
Собственно, в следующем комментарии всё это обсуждается.
А, речь о скалярном произведении векторов. Но тут я согласен с автором статьи, нужно определить функцию dotProduct, которая и обозначает скалярное произведение.
Естественно, нужно переопределять операторы без фанатизма. Я полностью согласен, что в приведенном Вами примере это достаточно серьезная неоднозначность при перемножении векторов.
Но, согласитесь, определить стандартные операторы для умножения, сложения, вычитания и т.д. для векторов можно и нужно.
Естественно, нужно переопределять операторы без фанатизма. Я полностью согласен, что в приведенном Вами примере это достаточно серьезная неоднозначность при перемножении векторов.
Но, согласитесь, определить стандартные операторы для умножения, сложения, вычитания и т.д. для векторов можно и нужно.
Возможно, надо определить как раз CrossProduct, а DotProduct оставить как *. Векторное произведение встречается намного реже, чем скалярное.
Либо сделать так:
Во всяком случае, в этом случае пользователь получит именно то, что кажется логичным.
Vector3 operator* ( const Vector3& rhs) const
{
return Vector3(
x * rhs.x,
y * rhs.y,
z * rhs.z);
}
float dotProduct(const Vector3& vec) const
{
return x * vec.x + y * vec.y + z * vec.z;
}
Vector3 crossProduct( const Vector3& rkVector ) const
{
return Vector3(
y * rkVector.z - z * rkVector.y,
z * rkVector.x - x * rkVector.z,
x * rkVector.y - y * rkVector.x);
}
Во всяком случае, в этом случае пользователь получит именно то, что кажется логичным.
Ни dot, ни cross не надо делать операторами. Операторами нужно делать матричное произведение, поэлементное и умножение на скаляр.
А поэлементное-то зачем? Оно вообще хоть где-нибудь встречается? Вижу, что его можно использовать для преобразования цвета (имитация применения цветного фильтра), но это какой-то чересчур экзотический случай.
Оно встречается чаще всего, если мы говорим о нормальной библиотеке, в которой есть векторы произвольной размерности и матрицы. Чисто для аналитической геометрии применений, наверное, мало.
При этом путаницы меньше всего — * — это умножение на скаляр и матричное умножение, а какой-нить % — поэлементное умножение, которое в математических формулах редко встречается и очевидно, что нужно RTFM, прежде чем понимать данный код.
При этом путаницы меньше всего — * — это умножение на скаляр и матричное умножение, а какой-нить % — поэлементное умножение, которое в математических формулах редко встречается и очевидно, что нужно RTFM, прежде чем понимать данный код.
Давайте перечитаем:
Т.е. автор ничего не имеет ничего против умеренной перегрузки операторов. Его восхищение (как я его понял) вызвано тем что используется перегрузка только там где она семантически понятна, и авторы Дум3 не пошли дальше когда перегружали операции для векторов.
Действительно когда видишь сложение и двух векторов всем понятно что здесь происходит. Если увидишь код вида myVar = vector1*vector2, то семантически уже не ясно что это, скалярное или покомпонетное произведение. Было много библиотек где векторно-матричную арифметику реализовывали через перегрузку операций, после этого уже не так ясно что значат эти «val = v1%v2», "!myMatrix", "~myMatrix2".
На мой взгляд здесь нет ничего особо нового, вроде авторы крутых книжек по C++ уже давно предупреждали что не следует злоупотреблять перегрузкой операций там где это может запутать людей. Даже перегрузка << в stl кому-то не очень нравится.
Без перегрузки эти операции станут менее очевидными и потребуют больше времени на написание и чтение. Здесь Doom и останавливается. Я видел код, которые идет дальше. Я видел код, который перегружает оператор '%' чтобы обозначить скалярное произведение векторов, или оператор Vector * Vector, который выполняет умножение векторов.
Т.е. автор ничего не имеет ничего против умеренной перегрузки операторов. Его восхищение (как я его понял) вызвано тем что используется перегрузка только там где она семантически понятна, и авторы Дум3 не пошли дальше когда перегружали операции для векторов.
Действительно когда видишь сложение и двух векторов всем понятно что здесь происходит. Если увидишь код вида myVar = vector1*vector2, то семантически уже не ясно что это, скалярное или покомпонетное произведение. Было много библиотек где векторно-матричную арифметику реализовывали через перегрузку операций, после этого уже не так ясно что значат эти «val = v1%v2», "!myMatrix", "~myMatrix2".
На мой взгляд здесь нет ничего особо нового, вроде авторы крутых книжек по C++ уже давно предупреждали что не следует злоупотреблять перегрузкой операций там где это может запутать людей. Даже перегрузка << в stl кому-то не очень нравится.
И они там немного не так сделали, они используют шаблоны для всяких утилитарных, низкоуровневых вещей, например для реализации контейнеров, но не используют их для реализации чего-то более сложного.
Собственно, я именно это и написал в своем сообщении: убрать шаблоны с высокого уровня, использовать шаблоны на низком.
printf куда лучше читается, нежели stringstream
Это дело привычки. Лично мне нравится либо бустовское format, либо Qt'шное arg.
По поводу более хороших инструментов — printf, это часть nt.dll, он есть всегда, а вместе с «хорошими инструментами» придется притащить в проект половину boost-а. Современные компиляторы С++ умеют находить ошибки форматирования, также, есть safe версии printf, не способные переполнить буфер.
Вы, видимо, разрабатывали только под Windows.
Какая вообще разница, что там есть по умолчанию в винде? Там есть WinAPI с огромным множеством структур и функции почти на все случаи жизни, но их использование жестко привязывает Вас к винде. Собственно, та безопасная версия функции printf, о которой Вы говорите — printf_s — это расширение стандартной библиотеки Майкрософтом, в других ОС Вы таких функции не найдете.
Далее, boost. У Вас какое-то странное представление о бусте, скорее всего, Вы его либо не использовали вообще, либо использовали крайне мало. Большая часть буста представляет собой просто хедеры, подключаемые к проекту. Это boost::format, boost::shared_ptr, boost:lexical_cast и многое другое. Например, использование того же boost::shared_ptr со всеми включаемыми в него хедерами располнит Ваш проект где-то на 1000 строк кода. Это что, так много?
Также буст компилируется под всеми ОС почти на всех компиляторах.
Потом, буст универсален. Кто-то использует новые компиляторы, кто-то старые. У одних умные указатели лежат в пространстве имен tr1, у кого-то их вообще нет, а кто-то использует новый стандарт, где они есть лежат просто в std. Использование буста уравнивает всех.
Под «безопасной версией printf» я имел ввиду snprintf, которая есть в glibc, которая знает размер переданного в нее буфера
Да, тут я с Вами соглашусь — snprintf безопасная и годная для использования функция.
А можно без менторского тона? Я начал использовать boost в 2006-м году и использую до сих пор :)
Прошу прощения, просто по предыдущему Вашему сообщению мне показалось, что Вы только слышали о бусте. К сожалению, многие программисты С++ избегают буст за его сложность и объемность, поэтому я привык, что это почти нормальное явление.
можно запросто раздуть размер своего исходника, который будет потом долго компилироваться и генерировать объектный файл разером в десятки мегабай
Само собой, подключать все — не самая лучшая идея.
Для таких дутых проектов есть предкомпилированные заголовки и unity builds, которые весьма неплохо повышают скорость компиляции.
У буста действительно есть проблемы и не для всякого проекта он подходит. В game-dev обычно очень консервативно относятся к таким вещам и их можно понять.
Само собой, он может не подходить.
Другое дело, что я не думаю, что в 3D проекте нужно очень много всего из буста.
Прекомпилированные заголовки — не всегда решают задачу.
Нет инструмента, который всегда будет решать все проблемы.
На моих проектах Ogre3d + boost предкомпилированные заголовки сокращают время компиляции в разы.
Аналогично могу сказать про проекта, в которых используется Qt (это тоже большие проекты).
Unity Builds — хороший хак для компиляции. Она не призвана заменить инкрементную сборку, это просто еще один способ сборки, который можно использовать наряду с используемыми Вами. Когда нужно быстро собрать проект, приятнее ждать не 30 минут, а 4.
В Visual Studio? От gcc сложно добиться чего-то лучшего чем -20%.
Да, msvc-9.0 (2008).
С другими компиляторами с ходу не могу сказать, как будет. Можно попробовать собрать на неделе.
Ну в этом-то вся и фишка, собственно.
Анонимные пространства действительно не получится использовать. Хотя, наверное, во вложенных (т.е. namespace Test { namespace { int a; } }; ) можно попробовать сделать так, чтобы имена не пересекались.
Отрефакторить код так, чтобы не использовать анонимных пространств — не так уж и сложно и долго. Нужно ли оно? Я не знаю, нужно смотреть в каждом конкретном случае. В больших проектах это давало очень крутой прирост к компиляции.
Да, msvc-9.0 (2008).
С другими компиляторами с ходу не могу сказать, как будет. Можно попробовать собрать на неделе.
Это вообще нельзя использовать, потому что оно кладет весь код в одну единицу трансляции
Ну в этом-то вся и фишка, собственно.
Анонимные пространства действительно не получится использовать. Хотя, наверное, во вложенных (т.е. namespace Test { namespace { int a; } }; ) можно попробовать сделать так, чтобы имена не пересекались.
Отрефакторить код так, чтобы не использовать анонимных пространств — не так уж и сложно и долго. Нужно ли оно? Я не знаю, нужно смотреть в каждом конкретном случае. В больших проектах это давало очень крутой прирост к компиляции.
Лучше всего использовать boost::format.
Но только не в 3D и не там, где требуется производительность.
Первый же запуск профайлера заставляет пересмотреть его использование.
Вы шутите?
Какое Вы пишите 3D, что у Вас узкое место в форматировании строки?
При написания графических 3D-движков, можно спотыкнуться на миллионе разных вещей, но узкое место в формате — бред. Это же не парсер какой-то, в конце-концов.
Какое Вы пишите 3D, что у Вас узкое место в форматировании строки?
При написания графических 3D-движков, можно спотыкнуться на миллионе разных вещей, но узкое место в формате — бред. Это же не парсер какой-то, в конце-концов.
А как вы читаете и сохраняете файлы моделей? Неакоторые из них имеют текстовый формат. И даже подгрузка PTX в миллиард точек может быть весьма долгой.
Если вам требуется скорость загрузки, то использовать модели в текстовом формате — бред в любом случае.
Как уже было сказано, не нужно модели хранить в текстовом формате.
Ваш случай со стандартом Лейка — это, скорее, исключение из правила, и для каждого такого исключения нужно придумывать свои костели. Вполне возможно, что Вам стоит отказаться от boost::format в пользу парсера boost::spirit, либо вообще отказаться от буста и использовать что-то другое (хоть тот же snprintf).
Но все же парсить текстовый файл — это явно не 3д задача.
Ваш случай со стандартом Лейка — это, скорее, исключение из правила, и для каждого такого исключения нужно придумывать свои костели. Вполне возможно, что Вам стоит отказаться от boost::format в пользу парсера boost::spirit, либо вообще отказаться от буста и использовать что-то другое (хоть тот же snprintf).
Но все же парсить текстовый файл — это явно не 3д задача.
Не пойму никак ваше предложение про использование спирита вместо формата. Может поясните чуть подробнее.
Касательно производительности — это есть даже в доках A Note about performance.
Касательно производительности — это есть даже в доках A Note about performance.
Речь шла о чтение модели из текстового файла. В таком случае, вполне логично не printf или format использовать для парсинг, а spirit.
Эта производительность мерилась на gcc версии 3.3.3, ему уже почти 10 лет. Я не утверждаю, что все будет намного лучше, но все же это совсем неактуальные тесты.
Вот тут хоть тесты и из спирита, но буст в сравнении тоже есть. Медленнее, но не на порядок. Для обычного формирования строки хватит, для парсинга больших файлов — нет, конечно.
Эта производительность мерилась на gcc версии 3.3.3, ему уже почти 10 лет. Я не утверждаю, что все будет намного лучше, но все же это совсем неактуальные тесты.
Вот тут хоть тесты и из спирита, но буст в сравнении тоже есть. Медленнее, но не на порядок. Для обычного формирования строки хватит, для парсинга больших файлов — нет, конечно.
Я мечтаю о том, чтобы все переменные в C++ по умолчанию были const
Как-раз один из пунктов, за которые я люблю Rust.
В целом отношение к const как автора статьи, так и Кармака, очень радует. Фактически, это показатель доли функционального стиля в их программировании. Противники такого подхода могут заметить, что для этого нужно писать много буков — и будут совершенно правы. Поэтому внимание пора обратить более подходящие инструменты, где функциональный стиль смотрится компактно и естественно (Scala,Rust).
Хотел бы отметить, что наряду с красотой кода важна и производительность. И пример с SetVar и GetVar это показывает. Он не только выглядит ужасно, но и выполняется в разы медленнее чем код с просто публичной переменной. Конечно, для такого просто случая это не настолько важно, но в сложных объектах разница в скорости может быть очень велика. Поэтому, мне кажется, Кармак уделял внимание этим обеим аспектам, ведь его код не просто красив, но и оптимален с точки зрения производительности.
Постойте, а разве компилятор не видит, что метод маленький и не виртуальный? Мне казалось, что такие SetVar и GetVar всегда (inline) встраиваются и в скомпилированном виде ничем не отличаются от публичной переменной.
Все верно, при оптимизации такие функции всегда становятся встраиваемые, и никакой разности в производительности нет.
А вот болтающиеся переменные в открытой секции класса, скорее всего, будут серьезным архитектурным косяком при проектировании системы. Так что практически всегда настоятельно рекомендую использовать setVar и getVar.
А вот болтающиеся переменные в открытой секции класса, скорее всего, будут серьезным архитектурным косяком при проектировании системы. Так что практически всегда настоятельно рекомендую использовать setVar и getVar.
Если тело метода будет находиться в *.cpp, то скорее всего он не сможет стать встроенным.
Да, действительно, я проверил, оба варианта кода генерируют строго идентичные ассемблерные листинги. Мои представления об оптимизирующих компиляторах С++ несколько устарели :)
Надеюсь и в случае более сложного кода оптимизация на стадии компилирования будет работать.
Надеюсь и в случае более сложного кода оптимизация на стадии компилирования будет работать.
Сомневаюсь, что из-за этого следует беспокоиться. 80% процентов ресурсов использует 20% кода. Не стоит с самого начала так зацикливаться на таких мелочах.
Ладно C, а вот когда это бездумно используют в php те кто заражён ООП головного мозга, то хочется показать этим недалёким людям профайл, где видно что это замедляет код раза в 2.
Чтобы вы получили какое-то представление: Dyad содержит 193k строк кода, все на С++. Doom 3 — 601k, Quake III — 229k и Quake II — 136k. Это большие проекты.
Это не большие проекты, это херня!
Я уже 11 лет работаю в компании, в которой с тремя другими программистами поддерживаем и развиваем проект, в котором больше 2 миллионов строк С++/MFC кода, преимущественно спагетти. Все 11 лет хочется найти и поломать пальцы оригинальным разработчикам. Все. По одному.
Для примера — вся репорт-система состоит из двух!!! двух классов, один из которых > 35000 строк С++ кода! Чувак, который выродил это чудовище, давно уволился, переодически встречаясь на обеде, я ему честно говорю:
— Боб, твой код — полное говно!
— Да, но зато это твоя гарантия от увольнения, поскольку больше в нем хрен кто разберется :)
193k строк кода весь проект — удивил!..
P.S. Только вчера добавлял фичу в код, который был моим первым заданием когда я прошел в компанию — выглядит все еще достойно, хотя сейчас, конечно, так я уже не пишу.
P.S.S. К счастью 5 лет назад ушел в web-разработку и на этого монстра отвлекают редко.
Это не большие проекты, это херня!
Я уже 11 лет работаю в компании, в которой с тремя другими программистами поддерживаем и развиваем проект, в котором больше 2 миллионов строк С++/MFC кода, преимущественно спагетти. Все 11 лет хочется найти и поломать пальцы оригинальным разработчикам. Все. По одному.
Для примера — вся репорт-система состоит из двух!!! двух классов, один из которых > 35000 строк С++ кода! Чувак, который выродил это чудовище, давно уволился, переодически встречаясь на обеде, я ему честно говорю:
— Боб, твой код — полное говно!
— Да, но зато это твоя гарантия от увольнения, поскольку больше в нем хрен кто разберется :)
193k строк кода весь проект — удивил!..
P.S. Только вчера добавлял фичу в код, который был моим первым заданием когда я прошел в компанию — выглядит все еще достойно, хотя сейчас, конечно, так я уже не пишу.
P.S.S. К счастью 5 лет назад ушел в web-разработку и на этого монстра отвлекают редко.
Нечего негодовать. За 11 лет втроем можно было и переписать весь продукт, а не поддерживать. Даже если учесть то, что вы сначала год разбирались в продукте и учились программированию, и 5 лет назад забили на этот продукт — в промежутке было 5 лет, за которые можно было и перелопатить весь проект.
Я бы с удовольствием переписал, но на тот момент, когда я пришел в компанию, бОльшая часть из этих двух миллионов там уже была. И как вы себе представляете «переписывание», когда вам постоянно дают задания на добавление новых фич? Т.е. у компании тупо нет средств и ресурсов на переписывание.
Я предложил переписать особо злобную и важную часть ядра. По прикидкам получилось, что мне одному потребуется год. Руководство посмеялось и оставило все как есть.
Даже если учесть то, что вы сначала год разбирались в продукте и учились программированию, и 5 лет назад забили на этот продукт
Во-первых, я уже пришел в компанию с >8 лет опыта по С++ и меня наняли для добавления новых фич, а именно — обертывания существующей бизнес-логики в COM, для последующего ее вызова из web.
Во-вторых, на проект никто не забил и все 11 лет в ного добавлялись новые части. За то что добавлял я — мне и сейчас не стыдно.
Я предложил переписать особо злобную и важную часть ядра. По прикидкам получилось, что мне одному потребуется год. Руководство посмеялось и оставило все как есть.
Даже если учесть то, что вы сначала год разбирались в продукте и учились программированию, и 5 лет назад забили на этот продукт
Во-первых, я уже пришел в компанию с >8 лет опыта по С++ и меня наняли для добавления новых фич, а именно — обертывания существующей бизнес-логики в COM, для последующего ее вызова из web.
Во-вторых, на проект никто не забил и все 11 лет в ного добавлялись новые части. За то что добавлял я — мне и сейчас не стыдно.
Во-первых, я уже пришел в компанию с >8 лет опыта по С++ и меня наняли для добавления новых фич, а именно — обертывания существующей бизнес-логики в COM, для последующего ее вызова из web.
Про ваш опыт я не знал, моя фраза была написана как пример.
Но все же мало кому поверится что 11 лет подряд был неугомонный поток заданий(я сам работаю в маленькой конторе с маленькими отделом разработки, на который наваливается кроме крупных постоянных проектов еще и мелочь разная), но все же если так, то об этом следовало бы сразу написать.
ПС: и лично я не в карму не куда больше вам не срал
Про ваш опыт я не знал, моя фраза была написана как пример.
Но все же мало кому поверится что 11 лет подряд был неугомонный поток заданий(я сам работаю в маленькой конторе с маленькими отделом разработки, на который наваливается кроме крупных постоянных проектов еще и мелочь разная), но все же если так, то об этом следовало бы сразу написать.
ПС: и лично я не в карму не куда больше вам не срал
Чем срать в карму, разобрались бы сначала.
И скольким людям принесли удовольствие ваши 2 миллиона спагетти-строк? А 229 тысяч аккуратных строчек Quake III?
Ваше неумение лаконично выражать мысли в коде афишировать совершенно не стоило.
Ваше неумение лаконично выражать мысли в коде афишировать совершенно не стоило.
Еще раз, те 2 млн — это не мой код. Это уже было написано до меня.
Я не говнокодю и за свой код мне не стыдно.
Я не говнокодю и за свой код мне не стыдно.
Ну раз оно было написано до вас то и не шумите что 229 тысяч строк это мало. Ведь вы то ничего не написали и понятия не имеете что такое написать большой проект, а ребята из id взяли и написав довольно внушительный объем кода создали шикарное произведение искусства, как в коде, так и в результате.
Я не говнокодю и за свой код мне не стыдно.
Никто не признается что говнокодит. Многие ярые борцы за чистый код сами пишут такой код от которого реальные трукодеры будут плакать кровавыми слезами. Ну и по пунктам почему вы неправы
1. Называть Doom и Quake словами «Это не большие проекты, это херня!» мягко говоря странно от разработчика с 11 летним стажем
2. Примеры кода что привел ТС красивы, и список принятых на момент написания кода соглашений в большинстве своем правильны. Ваш же код мы не видели, и остается только «поверить» вам на слово что ваш код написанный еще в «безусые» времена до сих пор выглядит «достойно». Обычно же у «правильных» разработчиков линия роста профессионализма имеет немного больший угол наклона к оси времени и код написанный даже месяц назад вызывает вопрос «и как я такое мог написать», в вашем же случае линия судя по всему идет практически параллельно оси времени.
Мне кажется что код Q3 — образец прагматичности, правильного баланса между достижением цели и гибкостью, а также демонстрация дичайшего скилла авторов — посредственный девелопер запутался бы и на 10-й части этого кода.
При этом любой современный java-enterprise-архитектор, прочитавший 100500 книжек по паттернам и ООП, сблевал бы от этого кода немедленно — там нет никаких паттернов, там тупое процедурное программирование, там куча весьма размазанного стейта, куча длинных нетривиальных алгоритмов.
И я считаю что вот этих современных java-enterprise-архитекторов, вместо чтения очередной книжки по канбан-методикам, надо сажать за код Q3, давать ведро, и пусть сидит блюет до наступления просветления.
Впрочем, вероятно java-проекты так и не напишешь — для этого надо не 30 индусов, а 3 мега-нидзя.
При этом любой современный java-enterprise-архитектор, прочитавший 100500 книжек по паттернам и ООП, сблевал бы от этого кода немедленно — там нет никаких паттернов, там тупое процедурное программирование, там куча весьма размазанного стейта, куча длинных нетривиальных алгоритмов.
И я считаю что вот этих современных java-enterprise-архитекторов, вместо чтения очередной книжки по канбан-методикам, надо сажать за код Q3, давать ведро, и пусть сидит блюет до наступления просветления.
Впрочем, вероятно java-проекты так и не напишешь — для этого надо не 30 индусов, а 3 мега-нидзя.
Паттерны нужны для упрощения общения между разработчиками, в качестве более высокоуровневых понятий, чем базовое ООП — у каждого паттерна есть семантика.
Если не знать паттерны, их всегда при необходимости можно придумать самому — большинство очень просты. А вот обсуждение кода очень затрудняется при их незнании: вместо «здесь у нас адаптер» начинается длинное объяснение на пальцах.
Если не знать паттерны, их всегда при необходимости можно придумать самому — большинство очень просты. А вот обсуждение кода очень затрудняется при их незнании: вместо «здесь у нас адаптер» начинается длинное объяснение на пальцах.
Код Doom 3 — это доработанный код Quake 3, который в свою очередь взял многое из Q2 и Q1. Кроме того, на коде этих движков, была написана масса игр, и от них ответвилось еще много других движков. Т.е. люди сильно лезли в этот код, а не просто использовали внешние скрипты да редактор.
Это разве не устойчивость к сильным изменениям?
Я уже много лет вижу эти все гибкие архитектуры. И могу точно сказать что оверэнджинеринг на фоне заболевания GoF-ами и Фаулерами — реальная боль современных .net и java-проектов. Я предпочту изменять 5-ти страничные алгоритмы вот отсюда github.com/id-Software/Quake-III-Arena/blob/master/code/botlib/be_aas_move.c (первый файл наугад), чем разбираться в нагромождении стратегий и адаптеров, которые будут делать ровно тоже самое, но в 20-ти файлах.
Это разве не устойчивость к сильным изменениям?
Я уже много лет вижу эти все гибкие архитектуры. И могу точно сказать что оверэнджинеринг на фоне заболевания GoF-ами и Фаулерами — реальная боль современных .net и java-проектов. Я предпочту изменять 5-ти страничные алгоритмы вот отсюда github.com/id-Software/Quake-III-Arena/blob/master/code/botlib/be_aas_move.c (первый файл наугад), чем разбираться в нагромождении стратегий и адаптеров, которые будут делать ровно тоже самое, но в 20-ти файлах.
Код Doom 3 — это доработанный код Quake 3
Вроде как там многое с нуля переписано. Вот как говорит об этом википедия:
During development, it was initially just a complete rewrite of the engine's renderer, while still retaining other subsystems, such as file access, and memory management. The decision to switch from C to the C++ programming language necessitated a restructuring and rewrite of the rest of the engine; today, while id Tech 4 contains code from id Tech 3, much of it has been rewritten
Так что здесь скорее нет устойчивости к сильным изменениям, а исконно программерское желание написать все с нуля, но на этот раз правильно :)
Написать заново и потихоньку переписать — это таки разные вещи. Если код можно не просто выкинуть и забыть, а потихоньку переписать весь — это уже хороший код.
Тем более что технологически q3 и doom3 действительно разительно отличаются. Начиная с того, что базовая структура данных — BSP, перестала быть актуальной, а это за собой уже тянет переделку кучи подсистем.
Тем более что технологически q3 и doom3 действительно разительно отличаются. Начиная с того, что базовая структура данных — BSP, перестала быть актуальной, а это за собой уже тянет переделку кучи подсистем.
Это пустая трата строк кода и последующего времени на его чтение. Такой вариант съест больше вашего времени, чем...Код (любой) пишется для того, чтобы превратиться в ассемблерные команды, поэтому самое главное, во сколько команд он превратится и сколько процессорного времени будет потрачено при выполнении.
Если при прочих равных есть возможность напечатать высокоуровневые инструкции так, чтобы с т.з. ассемблера получилось легковеснее — надо делать именно так.
Сравните стоимость часа работы программиста, и часа процессорного времени — чтобы нелепость вашего утверждения стала очевидной.
Потом рассмотрите языки типа SQL, чтобы разобраться ещё и с утверждением "Код (любой) пишется для того, чтобы превратиться в ассемблерные команды"
Потом рассмотрите языки типа SQL, чтобы разобраться ещё и с утверждением "Код (любой) пишется для того, чтобы превратиться в ассемблерные команды"
Сравните стоимость часа работы программиста, и часа процессорного времени — чтобы нелепость вашего утверждения стала очевидной.
Ну это же тупость! Особенно применительно к таким проектам как 3d шутеры. Хорош был бы Кармак если бы выпустил продукт который бы показывал 20 fps и сказал бы «ничего, ребяты, вы просто будте терпеливее и подождие когда картинка прорисуется, мое время дороже так что я не буду ничего оптимизировать».
Экономически час времени программиста не конвертируется ровно в час времени какого-то определенного процессора. Код написанный программистом может выполнятся на миллионах компьютеров, так что один час программиста может экономить намного больше часов конечных пользователей. Такая ситуация может быть с хостингом, вам потребуется меньшая ежемесечная плата если сервер потребляет меньше ресурсов.
Понятно что где-то можно жертвовать производительностью в угоду скорости разработки, но этот выбор совсем не всегда очевиден, чтобы его однозначно так тупо сравнивать.
Собственно, RT-игры — это единственный тип проектов, для которых быстродействие важнее поддержки кода, потому что через год после выпуска игру всё равно забудут и пользователи, и разработчики.
Но даже там приоритеты неочевидны: гляньте-ка недавний пост и комментарии к нему.
Ещё позволю себе процитировать мой собственный пост 8-летней давности с одного форума, где вёлся похожий спор:
Но даже там приоритеты неочевидны: гляньте-ка недавний пост и комментарии к нему.
Ещё позволю себе процитировать мой собственный пост 8-летней давности с одного форума, где вёлся похожий спор:
Задали мне задание: рассчитать значения хитрой комбинаторной функции, и чем в большем числе точек, тем лучше. Функция такая, что время на её вычисление экспоненциально зависит от величины аргумента, т.е. «с наскоку» её не сосчитать.
Я сел и неделю писал прогу на VB с разными наворотами вроде возможности приостановки вычисления (типа Hibernate) и последующего продолжения; упаковки восьми булевских переменных в один байт; всяческой оптимизацией и т.п.
За 20 часов (три ночи) эта прога сосчитала мне значения до 250.
Я сел и переписал прогу на VC, уже без наворотов, а просто чтобы прикинуть скорость. Скорость была совершенно та же. Сейчас эта программа работает девятый час, и сосчитала значения до 140.
Я пошёл к преподу выяснять, как быть — получается, уже для 1000 потребуется месяц вычислений, а то и больше. И он мне показал свою прогу на JS для решения этой же задачи. Мои результаты до 250 она получает за несколько минут, за 20 часов — примерно до 400, а за пару суток — до 600. Естественно, у него там более хитроумный алгоритм, выгода от которого в тысячи раз превышает разницу в быстродействии языков.
Моя мысль была про то что экономическую целесообразность от времени программиста потраченного на производительность надо считать по другому, а не сравнивать ее со стоимостью такого же количества процессорного времени. Но вы добавили еще пару новых тезисов с которыми я бы тоже поспорил :)
Мой личный пример о экономической пользе оптимизации, это небольшой сайт/приложении которое работает на бесплатной квоте на Google App Engine уже несколько лет. Я специально потратил какое-то количество усилий и времени чтобы уменьшить потребление ресурсов, и в результате ничего не плачу несколько лет.
- Производительность важна не только для real time игр, но и для других приложений. Например при прочих равных выбирая вспомогательные серверные приложения в компанию мы откажемся от тех про которые известно что они прожорливее по ресурсам.
- Игры не обязательно забываются, на том же Id Tech 4 (дум3) написано штук 6 других игр, ММО и мультиплееры живут годами. Может быть правда это не типичный случай в индустрии
- Увеличение производительности на мой взгляд не означает автоматически ухудшения поддерживаемости кода.
Мой личный пример о экономической пользе оптимизации, это небольшой сайт/приложении которое работает на бесплатной квоте на Google App Engine уже несколько лет. Я специально потратил какое-то количество усилий и времени чтобы уменьшить потребление ресурсов, и в результате ничего не плачу несколько лет.
Я же не призываю полностью пренебречь производительностью кода — я спорил с noldo32, который призывал к противоположной крайности — выжиманию процессорных тактов любой ценой.
Я утверждаю, что высшая производительность достигается не агрессивной низкоуровневой оптимизацией и «подходом «от машины»», а наоборот — оптимизацией высокоуровневой и корректировкой алгоритмов. Для этого не нужно ни пытаться понять, какой машинный код фактически генерируется, ни пытаться повлиять на его генерацию.
Кроме того, я привёл конкретный пример — популярную игру, которую во имя производительности так заоптимизировали, что 15 лет спустя Microsoft была вынуждена её выкинуть, не смогши разобраться в когде.
Я утверждаю, что высшая производительность достигается не агрессивной низкоуровневой оптимизацией и «подходом «от машины»», а наоборот — оптимизацией высокоуровневой и корректировкой алгоритмов. Для этого не нужно ни пытаться понять, какой машинный код фактически генерируется, ни пытаться повлиять на его генерацию.
Кроме того, я привёл конкретный пример — популярную игру, которую во имя производительности так заоптимизировали, что 15 лет спустя Microsoft была вынуждена её выкинуть, не смогши разобраться в когде.
noldo32, который призывал к противоположной крайности — выжиманию процессорных тактов любой ценойА где, спрашивается, я говорил про "любую цену"?
Если при прочих равных есть возможность напечатать высокоуровневые инструкции так, чтобы с т.з. ассемблера получилось легковеснее — надо делать именно так.(внимание: выделено жирным шрифтом)
Согласен с тем что выжимание тактов везде где угодно может быть экономически нецелесообразно. Однако на для программиста было бы неплохо понимать какую производительность имеет тот код который он пишет. Для C/C++ в принципе неплохо хотя бы ориентировочно представлять во что на уровне инструкций процессора превратится его код. Для Явы есть свой набор правил, есть хорошая статья во что выливается непонимание производительности в тех или иных средств языка www.odi.ch/prog/design/newbies.php. Прикольный пример как простая конкатенация строк (казалось бы обычная конструкция языка) может существенно ударить по производительности.
Не просто «в принципе неплохо», а «замечательно и весьма полезно» — лишних знаний вообще не бывает.
Но не «критически важно».
Думаю, можно быть отличным водителем, и даже гонщиком, не разбираясь в подробностях устройства ДВС, или отличным художником, не разбираясь в химическом составе красок.
Применение достоинств инкапсуляции к реальному миру :-)
Но не «критически важно».
Думаю, можно быть отличным водителем, и даже гонщиком, не разбираясь в подробностях устройства ДВС, или отличным художником, не разбираясь в химическом составе красок.
Применение достоинств инкапсуляции к реальному миру :-)
Гонщику, конечно, достаточно знать реакцию своего болида на ту или иную последовательность действий (в зависимости от условий). Но чтобы добиться реакции, которая требуется, но известными действиями пока не достигалась, было бы неплохо понять, почему болид именно так реагирует. И исходя из этого — придумать, как заставить его реагировать нужным образом. А для этого полезно знать и устройство двигателя, и физику сцепления покрышек с асфальтом, и чувствительность различных датчиков (и использование их показаний в программе управления). Лучше, когда гонщик сам расскажет, какие настройки и как следует поменять, чем когда это будут пытаться понять исключительно по телеметрии.
То же и у нас. Очень полезно знать, когда разумнее пользоваться массивом, когда указателями, а когда писать foreach (если язык это позволяет). Но еще полезнее понять, почему та или иная конструкция оказалась лучше — и для этого лучше хотя бы иногда заглядывать в ассемблерный код.
Разница будет — как между человеком, который знает приёмы и успешно выбирает наиболее подходящий, и тем, кому приёмы знать не нужно — они для него возникают, как следствия более общих принципов… Мечты, мечты…
То же и у нас. Очень полезно знать, когда разумнее пользоваться массивом, когда указателями, а когда писать foreach (если язык это позволяет). Но еще полезнее понять, почему та или иная конструкция оказалась лучше — и для этого лучше хотя бы иногда заглядывать в ассемблерный код.
Разница будет — как между человеком, который знает приёмы и успешно выбирает наиболее подходящий, и тем, кому приёмы знать не нужно — они для него возникают, как следствия более общих принципов… Мечты, мечты…
Полагаю, если гонщик на полной скорости примется обдумывать действия, основываясь на механических принципах устройства своего болида — он просто вылетит с трассы. Его мастерство может подкрепляться пониманием механических принципов, дающих рациональное объяснение наблюдаемому поведению болида; но без неосознаваемого, интуитивного принятия решений на ходу — о мастерстве вряд ли можно говорить.
То же и у нас. Времени на обдумывание решений у программиста намного больше, но и подконтрольная система сложнее; предсказать, ускорит ли код развёртывание цикла, или рассчитать, как перестановка полей повлияет на cache locality, нелегко усилием чистого разума, тем более что экспериментальная проверка ничего не стоит. Ну так и зачем рассчитывать?
Тем более, что вызубренные ассемблерные тонкости всё равно потеряют актуальность при апгрейде компилятора / переходе на другую архитектуру CPU / переходе на компилятор другого производителя / переходе на другой язык с похожей семантикой, но совсем другим нутром, хотя бы с Java на C++ или обратно. Разница будет — уже не в пользу программиста, чьи «следствия более общих принципов» оказываются намного более частными, чем приёмы написания программ «от семантики» и без заглядывания в ассемблерные листинги.
То же и у нас. Времени на обдумывание решений у программиста намного больше, но и подконтрольная система сложнее; предсказать, ускорит ли код развёртывание цикла, или рассчитать, как перестановка полей повлияет на cache locality, нелегко усилием чистого разума, тем более что экспериментальная проверка ничего не стоит. Ну так и зачем рассчитывать?
Тем более, что вызубренные ассемблерные тонкости всё равно потеряют актуальность при апгрейде компилятора / переходе на другую архитектуру CPU / переходе на компилятор другого производителя / переходе на другой язык с похожей семантикой, но совсем другим нутром, хотя бы с Java на C++ или обратно. Разница будет — уже не в пользу программиста, чьи «следствия более общих принципов» оказываются намного более частными, чем приёмы написания программ «от семантики» и без заглядывания в ассемблерные листинги.
Про другие компиляторы/архитектуры/языки полностью согласен. Действительно, у гонщика, который пересел на трактор или ракету, или которого выпустили на трассу на Луне или под водой, гораздо больше шансов вылететь с трассы, чем у обычного водителя. Тот, пусть в 5 раз медленнее, но проедет. Хотя трактор или болид у него вполне могут несколько раз заглохнуть.
Будет ли код «гонщика», перенесенный на другую архитектуру (если он вообще заработает) эффективнее, чем код обычного программиста (при условии, что алгоритм использован одинаковый)? Как повезет. Думаю, что в общем случае, да, но не обязательно. Но когда «гонщик» начнет писать под эту новую архитектуру, ему будет очень непросто. Постоянно будут мешать вопросы «что быстрее»:
— int64 или double?
— разворачивать цикл, или оставить его как можно более компактным?
— вызов виртуальной функции или обращение к полю структуры из массива? А если это массив ссылок?
— if или конструкция из 3-4 битовых операций?
— умеет ли компилятор оптимизировать деление на константу? И как быстро вообще работает целочисленное деление?
— Нет ли других тонкостей, замедляющих или ускоряющих вычисления?
Ну и так далее. Без тщательного тестирования начать программировать просто невозможно :)
Будет ли код «гонщика», перенесенный на другую архитектуру (если он вообще заработает) эффективнее, чем код обычного программиста (при условии, что алгоритм использован одинаковый)? Как повезет. Думаю, что в общем случае, да, но не обязательно. Но когда «гонщик» начнет писать под эту новую архитектуру, ему будет очень непросто. Постоянно будут мешать вопросы «что быстрее»:
— int64 или double?
— разворачивать цикл, или оставить его как можно более компактным?
— вызов виртуальной функции или обращение к полю структуры из массива? А если это массив ссылок?
— if или конструкция из 3-4 битовых операций?
— умеет ли компилятор оптимизировать деление на константу? И как быстро вообще работает целочисленное деление?
— Нет ли других тонкостей, замедляющих или ускоряющих вычисления?
Ну и так далее. Без тщательного тестирования начать программировать просто невозможно :)
Применение инкапсуляции к реальному миру: все скрытые переплаты в области ИТ (раза в 2 по наблюдениям) — из-за неё.
Более страшный пример. 99% «человеческого фактора» в авиакатастрофах — следствие незнания низкого уровня: аэродинамики, устройства самолёта. Когда лётчик при падающем из-за нехватки скорости самолёте тянет ручку на себя, срывается и убивается вместе с пассажирами — это следствие инкапсуляции: тянешь на себя — летит вверх, от себя — вниз. А как оно там на низком уровне — ХЗ.
Более страшный пример. 99% «человеческого фактора» в авиакатастрофах — следствие незнания низкого уровня: аэродинамики, устройства самолёта. Когда лётчик при падающем из-за нехватки скорости самолёте тянет ручку на себя, срывается и убивается вместе с пассажирами — это следствие инкапсуляции: тянешь на себя — летит вверх, от себя — вниз. А как оно там на низком уровне — ХЗ.
Прикольный пример как простая конкатенация строк (казалось бы обычная конструкция языка) может существенно ударить по производительности.
К слову, вспомнилась видеозапись выступления JavaScript на сервере, 1ms на трансформацию, где они рассказывали, что конкатенация строк у них работала быстрее, чем более правильный вариант с join массива.
Но это скорее исключение, чем правило.
Если какая-нибудь программа 3D моделирования будет строить сложную модель (из миллиардов треугольников) за сутки, то ей с болью, но будут пользоваться. Если у другой программы, написанной с учетом стоимости труда программистов и с архитектурой, рассчитанной на развитие на годы вперед, на ту же модель уйдёт месяц — то, скорее всего, пользоваться ей будут гораздо меньше. Для очень богатой компании второй вариант, возможно, будет лучше, но для остальных — вряд ли.
Код, с меньшим количеством строк — как правило тратит меньше времени и на его чтение, и на его выполнение после компиляции. Но важен сам подход — «от машины». Делай легковесный код для машины — а польза в виде экономии времени программистом придет сама, автоматически.
Что SQL, что bash, что javascript приводит к возникновению того или иного количества машинных команд. Капитан Очевидность напоминает: абсолютно всё в мире софта в конечном итоге сводится к ассемблерным инструкциям, и чем их выполняется больше — тем медленнее работает система.
P.S. Есть «дорогие» по времени низкоуровневые действия — переключения контекста например. Если программист знает про 2 примерно равных по числу строк приема, один из которых приведет, а другой не приведет к переключению контекста, он обязан выбрать тот, что не приведет. Я уже не говорю про лишние действия с файлами…
Что SQL, что bash, что javascript приводит к возникновению того или иного количества машинных команд. Капитан Очевидность напоминает: абсолютно всё в мире софта в конечном итоге сводится к ассемблерным инструкциям, и чем их выполняется больше — тем медленнее работает система.
P.S. Есть «дорогие» по времени низкоуровневые действия — переключения контекста например. Если программист знает про 2 примерно равных по числу строк приема, один из которых приведет, а другой не приведет к переключению контекста, он обязан выбрать тот, что не приведет. Я уже не говорю про лишние действия с файлами…
> Код, с меньшим количеством строк — как правило тратит меньше времени и на его чтение
Ага, особенно JaPh-перлы ;-)
Капитан Очевидность умеет предсказывать количество ассемблерных команд и переключений контекста по SQL-коду хотя бы с точностью до порядка?
Если нет, то как он может писать SQL-код «так, чтобы с т.з. ассемблера получилось легковеснее»?
Ага, особенно JaPh-перлы ;-)
Капитан Очевидность умеет предсказывать количество ассемблерных команд и переключений контекста по SQL-коду хотя бы с точностью до порядка?
Если нет, то как он может писать SQL-код «так, чтобы с т.з. ассемблера получилось легковеснее»?
На хабре не любят низкоуровневую оптимизацию, полностью доверяют компиляторам и ценят время работы программиста больше, чем время работы программы :)
Потому что здесь много ГСМ менеджеров
Протому что здесь много программистов жизненных задач и мало эстетов демосцены и эмбеддедщиков с историями-одного-байта.
Я до пенсии буду наверное вспоминать мобильный 2гис, с аппетитами, растущими от версии к версии, при незначительном росте функциональности. Зато его поддержывать легко и рекламодатели платят.
Но вы же им продолжали пользоваться?
Чем не показатель их успеха?
Чем не показатель их успеха?
И так во всём (за редкими исключениями) софте. Между прочим, чтобы написать новую версию «с аппетитами», нужно переписать старую, да еще увеличив число строк кода. Это трудозатраты. И удешевление мифической «поддержки» может их не отбить. Не лучше ли привести в порядок (с т.з. простоты добавления функционала и быть может документированности-понятности) уже имеющийся код, заодно и оптимизировав производительность в «узких местах»?
Странно, может я чего-то не понял из статьи, но github.com/badsector/Doom3-for-MacOSX-/blob/master/neo/game/AFEntity.cpp тут вот явно каждая функция комментируется когда нужно и не нужно, на пример:
/*
================
idAFEntity_WithAttachedHead::Restore
================
*/
void idAFEntity_WithAttachedHead::Restore( idRestoreGame *savefile ) {
head.Restore( savefile );
}
да уж… и константами не пахнет («const idRestoreGame &savefile»)
Ну это не комментарии, а скорее визуальные разделители между методами. Если редактор/IDE не отрисовывает разделители — то это полезная практика.
Под комментариями тут скорее подразумевались вот такие ситуации:
или
Под комментариями тут скорее подразумевались вот такие ситуации:
/*
================
idAFEntity_Base::DropAFs
The entity should have the following key/value pairs set:
"def_drop<type>AF" "af def"
"drop<type>Skin" "skin name"
To drop multiple articulated figures the following key/value pairs can be used:
"def_drop<type>AF*" "af def"
where * is an aribtrary string.
================
*/
void idAFEntity_Base::DropAFs( idEntity *ent, const char *type, idList<idEntity *> *list ) {
...
или
// get the initial origin and axis for each AF body
for ( i = 0; i < af->bodies.Num(); i++ ) {
fb = af->bodies[i];
...
А меня больше всего зацепило что они написали свою реализацию String и STL. Был я на таком проекте. 1/3 времени я проводил в изучении того как же работают ихние стандартные контейнеры, auto_ptr'ы, Int'ы и прочие переписанные стандартные сущности.
А потом мы долго плювались и ругались когда у нас вылезла какая то фатальная страшная трудно уловимая и обсолютно неявная ошибка, в связи с чем появился auto_ptr2, а мы благополучно мигрировали наш проект на STL.
А потом мы долго плювались и ругались когда у нас вылезла какая то фатальная страшная трудно уловимая и обсолютно неявная ошибка, в связи с чем появился auto_ptr2, а мы благополучно мигрировали наш проект на STL.
финальный модификатор const после списка параметров — мой самый любимый. Он указывает на то, что idSurface::Split() не сможет изменить саму поверхность (surface). Это одна из моих самых любимых возможностей в С++, по которой я так скучаю в других языках. Она позволяет мне вытворять подобное:
void f(const idSurface &s) {
s.Split(....);
}
если Split не была бы определена как Split(...) const; этот код бы не скомпилировался. Теперь я всегда буду знать, что при любом вызове f() не изменит поверхность, даже если f() передается поверхности другой функцией или вызывает какой-либо из методов Surface::method().
Вот тут я не понял. Метод Split() по логике вещей предназначен для того, чтобы разбивать грань, то есть, должен менять её.
При этом (в данном случае) он разбивает грань так, что не меняет её.
Как? Это? Возможно?
И еще: «я всегда буду знать, что при любом вызове f() не изменит поверхность». Вы это будете знать на этапе компиляции, или блокирование изменения поверхности произойдет в рантайме?
Вы это будете знать на этапе компиляции, или блокирование изменения поверхности произойдет в рантайме?На этапе компиляции.
Однако возможно использование mutable-переменных или различных const_cast, так что на 100% «константному методу» доверять нельзя.
> При этом (в данном случае) он разбивает грань так, что не меняет её.
> Как? Это? Возможно?
Так же, как System.String.Split разбивает строку, не меняя её: результаты разбития возвращаются в новых объектах.
> Как? Это? Возможно?
Так же, как System.String.Split разбивает строку, не меняя её: результаты разбития возвращаются в новых объектах.
Есть такая идиома, что не нужно модифицировать объект нужно возвращать новый.
Самый очевидный пример это строки в Python и кажется Javа
Самый очевидный пример это строки в Python и кажется Javа
И C#.
Разбивать существующую грань, или создавать две новых — во многом зависит от алгоритма. На порядок сложности это, скорее всего, не повлияет, но константа может измениться существенно (когда нужно будет переключать все ссылки на грань из соседних рёбер/граней/… плюс время на лишний захват памяти). Впрочем, в хорошем алгоритме грань вообще не обязана быть постоянно существующим объектом — она может быть ссылкой в сеть, представляющую мультиграф вершин/рёбер/граней…
Из всей статьи согласен только с const ( и то именно в С++ он ущербен ). Всё остальное — либо фобии, либо придирки к не принципиальному.
Предложение экономить вертикальное место в ущерб читаемости вообще привело в ужас.
Предложение экономить вертикальное место в ущерб читаемости вообще привело в ужас.
Sign up to leave a comment.
Исключительная красота исходного кода Doom 3