Comments 82
Почему нельзя было iconv воспользоваться?
Наверно потому, что неизвестна исходная кодировка
Для таких случаев есть enca и enconv
habrahabr.ru/post/147843/ может помочь
enca же. Практически стандарт в этом плане.
$ echo йПЮЙНГЪАПШ АКЕЮРЭ | enca -L russian
Universal transformation format 8 bits; UTF-8
Doubly-encoded to UTF-8 from CP1251
Хотя
$ echo йПЮЙНГЪАПШ АКЕЮРЭ | iconv -f utf8 -t koi8r | iconv -f cp1251 -t utf-8
Кракозябры блеать
Или я неправильно готовлю enca?
enca — это детектор кодировки, а конвертер — это enconv. Но ваш пример не пройдёт, потому что терминал в UTF-8, а двойное преобразование (как в вашем примере с iconv) оно не сделает — ведь это вполне себе валидный юникод. enconv по умолчанию будет стараться преобразовать из любой кодировки в кодировку текущей локали.Например, если текст в кодировке CP1251 был отображён в кодировке KOI8-R, то получится примерно такая фигня: йПЮЙНГЪАПШ АКЕЮРЭ.Да когда это всё уже кончится)
Когда каждый разработчик будет понимать, что понятия «текст» самого по себе не существует: если есть текст, то у него есть и кодировка.
Или все просто перейдут на UTF-8.
Он в плане производительности сильно проигрывает кодировкам с фиксированным числом байт в символе.
Да бросьте экономить на спичках. Сейчас даже в часах уже вайфай, блютус, цветной экран, акселерометр и куча всякой фигни, а мы будем на кодировках экономить.
Вот пожалуйста только не говорите, что индексация в строке — это самая частая операция. Это абсолютная неправда. А других «проблем» с производительностью UTF-8 не имеет.
utf8everywhere.org/
utf8everywhere.org/
Я говорю по опыту перевода WackoWiki на UTF-8. А у вас какая аргументация?
То что php плохо работает с utf-8 не говорит о том, что utf-8 это плохо и медленно.
А что хорошо работает с UTF-8?
Ну например .NET CLR использует UTF-16 в качестве Internal encoding. JavaScript engines используют в качестве родной UCS-2 or UTF-16.
Спасибо за информацию.
А что с ответом на вопрос?
А что с ответом на вопрос?
Ох, прошу прощения, вот это троллинг, аж просто из кресла выбили меня. Мой опыт участия в подобного рода дискуссиях, когда оппонент вместо конструктивного обсуждения переходит на натужные шутки, показывает, что лучше их даже не начинать.
Видимо из моего сообщения ответ был не очевиден, чтож я поясню. В ответ на вашу просьбу привести пример того, что хорошо работает с многобайтовыми кодировками, я привел языки, интерпритаторы\комплияторы которых используют многобойтовые кодировки в качестве родных и работают с ними хорошо.
Ваши утверждения о том, что «с позиции моего опыта UTF-8 медленнее», и «я переводил xxx на UTF-8 и он стал медленнее», а также «я знаю о чем говорю», по большому счету не являются аргументами, без, хотя бы, тестов, а лучше анализа причин, по которым ваше приложение стало медленнее. Нет даже информации о том, что его замедлило, работа базы или самого php движка. В таких условиях попытка выехать на голом «я делал xxx, и знаю о чем говорю» выглядит очень слабо.
Но учитывая ваш настрой, я признаю свое полное поражение, заранее соглашаюсь со всеми вашими тезисами и высказываниями касательно кодировок, крутости php как лучшего в мире языка програмирования и чего бы то ни было еще, и самоустраняюсь из дискуссии.
Видимо из моего сообщения ответ был не очевиден, чтож я поясню. В ответ на вашу просьбу привести пример того, что хорошо работает с многобайтовыми кодировками, я привел языки, интерпритаторы\комплияторы которых используют многобойтовые кодировки в качестве родных и работают с ними хорошо.
Ваши утверждения о том, что «с позиции моего опыта UTF-8 медленнее», и «я переводил xxx на UTF-8 и он стал медленнее», а также «я знаю о чем говорю», по большому счету не являются аргументами, без, хотя бы, тестов, а лучше анализа причин, по которым ваше приложение стало медленнее. Нет даже информации о том, что его замедлило, работа базы или самого php движка. В таких условиях попытка выехать на голом «я делал xxx, и знаю о чем говорю» выглядит очень слабо.
Но учитывая ваш настрой, я признаю свое полное поражение, заранее соглашаюсь со всеми вашими тезисами и высказываниями касательно кодировок, крутости php как лучшего в мире языка програмирования и чего бы то ни было еще, и самоустраняюсь из дискуссии.
Причём здесь троллинг?
Вы что, реально не понимаете в чём принципиальная разница между UTF-8 и USC-2? Зачем вы мне на вопрос про эффективную работу с UTF-8 пишете что-то про языки, которые работают не с UTF-8?!
UTF-8 — с переменным числом байт на символ, USC-2 — с постоянным. Не знаю как в .NET устроена эффективная работа с UTF-16, надо поинтересоваться. Возможно они не парятся и просто считают суррогатную пару ещё одним символом.
Соответственно, все операции взятия символа по индексу, взятия подстроки и прочие сходные будут выполняться не O(1), а за O(n). Насколько замедлится работа с регулярными выражениями, не берусь оценить.
Вы что, реально не понимаете в чём принципиальная разница между UTF-8 и USC-2? Зачем вы мне на вопрос про эффективную работу с UTF-8 пишете что-то про языки, которые работают не с UTF-8?!
UTF-8 — с переменным числом байт на символ, USC-2 — с постоянным. Не знаю как в .NET устроена эффективная работа с UTF-16, надо поинтересоваться. Возможно они не парятся и просто считают суррогатную пару ещё одним символом.
Соответственно, все операции взятия символа по индексу, взятия подстроки и прочие сходные будут выполняться не O(1), а за O(n). Насколько замедлится работа с регулярными выражениями, не берусь оценить.
Соответственно, WackoWiki замедлилась не потому что там код плохой, а потому что вики — это работа с текстом и там упомянутых операций — вагон.
И PHP тут не причём. Просто вы написали, что PHP плохо работает с UTF-8, я и спросил какой язык работает с этой кодировкой хорошо, а вы ответили на какой-то другой вопрос, который я не задавал.
И PHP тут не причём. Просто вы написали, что PHP плохо работает с UTF-8, я и спросил какой язык работает с этой кодировкой хорошо, а вы ответили на какой-то другой вопрос, который я не задавал.
Т.е. веб-приложение на скриптовом языке использующее внешнюю БД замедлилось из-за того, что строка стала представляться в другой кодировке? Это профилирование действительно показало или вы на глазок прикинули?
Ну да. А что вас смущает, собственно? Вы привыкли небольшие сайтики делать что ли? Есть веб-приложения где всё в базу не упирается.
Ну да. А что вас смущает, собственно? Вы привыкли небольшие сайтики делать что ли? Есть веб-приложения где всё в базу не упирается.Так делалось профилирование? Что именно показало, данные в студию!
Это три года назад было, я по-вашему, данные как память храню?
Какой смысл делать было профилирование, когда две версии, различающиеся лишь кодировкой уже на тестовом сервере показали разницу в производительности, заметную на глаз? А в продакшне (какая бы ни была производительность, переходить было необходимо) она стала уж совсем очевидной.
Какой смысл делать было профилирование, когда две версии, различающиеся лишь кодировкой уже на тестовом сервере показали разницу в производительности, заметную на глаз? А в продакшне (какая бы ни была производительность, переходить было необходимо) она стала уж совсем очевидной.
а потому что вики — это работа с текстом и там упомянутых операций — вагонДа хоть два вагона с тележкой работы с текстом, всё что кроме конечного вывода пусть делается в любом internal-представлении, как это, собственно, и делается во всех языках. Вы перед каждой из упомянутых операций над текстом что, каждый раз перекодируете чтоли туда-сюда? Причём тут их количество тогда? Вообще никакого отношения к кодировке конечной страницы в браузере (раз мы говорим сейчас конкретно о веб-приложении) тут нету и быть не должно.
А причём тут внутреннее представление (которое в PHP просто строка байт, без кодировки)? Мы тут UTF-8 обсуждаем, я делюсь своими сомнениями в разумности перехода именно на UTF-8, а не ещё на какую-то другую кодировку.
в разумности перехода именно на UTF-8, а не ещё на какую-то другую кодировкуПро какой переход на UTF-8 речь? Откуда, где, куда? Про переход в клиентской части приложений — он уже де-факто состоялся (ну, почти), к счастью. А ваши описываемые проблемы относятся к конкретному языку, который к 6й версии может быть осилит нормальные строки.
И PHP тут не причём.И именно что PHP как раз причём в том о чём вы рассказываете, т.к. это проблемы (если они и правда есть, конечно) именно внутреннего представления строки в конкретной платформе. Но даже в вашем случае непонятно как связаны потери производительности с количеством операций над строками. Ещё раз повторяю вопрос: вы что, перекодируете их при каждой операции?
Про какой переход на UTF-8 речь? Откуда, где, куда?Вы начало дискуссии-то прочтите.
И именно что PHP как раз причём в том о чём вы рассказываете, т.к. это проблемы (если они и правда есть, конечно) именно внутреннего представления строки в конкретной платформе.Причём тут внутреннее представление? Я вообще про кодировку UTF-8 говорю. Свой опыт я привёл в качестве примера того, что UTF-8 далеко не всегда хороший выбор.
Но даже в вашем случае непонятно как связаны потери производительности с количеством операций над строками. Ещё раз повторяю вопрос: вы что, перекодируете их при каждой операции?Нет, из-за этого и потери. Строки в этом проекте всегда UTF-8.
Вообще не понимаю причём тут внутреннее представление строки. Я не говорю о других кодировках (работает с ними язык — чудесно), говорю только об UTF-8.
где в вики используются операции вида: вставить символ в позицию n, взять подстроку с символа n по k?
Мда… вы вообще с вики знакомы? Посмотрите как в любой вики парсер разметки работает.
любой парсер работает по принципу «взять следующий символ», никаких операций по работе с индексами там нет.
Вы код-то посмотрите. Любой парсер, да. Хотя бы ту же WackoWiki скачайте, R4.2.
И это не отменяет необходимости понимать, что текст и кодировка неделимы :)
Перевод титульной картинки
"ËÒÁËÏÚÑÂÒÙ ÂÌÅÁÔØ" => «кракозябры блеать» :)
Неожид.
Неожид.Ой, а шо ви таки имеете пготив?
Вы сильно рискуете призвать Mithgol'a (http://habrahabr.ru/users/mithgol/) в обсуждение и устроить срач в столь безобидной теме.
Вы вообще, о чем?
«неожид» — сленговое от «неожиданно», если это требует пояснения.
«неожид» — сленговое от «неожиданно», если это требует пояснения.
А он о неоЗОГ
Вы многого не знаете.
Помимо уже озвученных iconv и enca существует масса online-сервисов, среди них даже есть с наличием API, чтобы дергать из скриптов.
А еще на хабре были отличные графические схемы для определения кодировки: раз два
Интересный был бы велосипед, реализующий алгоритм по блок-схеме. С графическим анализом символов, openal и генетикой, разумеется.
А еще на хабре были отличные графические схемы для определения кодировки: раз два
Картинка, чтобы не лазить по ссылкам

Интересный был бы велосипед, реализующий алгоритм по блок-схеме. С графическим анализом символов, openal и генетикой, разумеется.
Может кто-нибудь знает как бороться с кодировками в PDF с русским текстом? Особый интерес представляют научные статьи, который, судя по всему, компилятся из tex'а. Ни из одного просмотрщика не удалось скопировать текст, пригодный для вставки в какой-нибудь текстовый процессор, более того, тут даже 2cyr decoder
Насколько я понимаю, в PDF может использоваться какая-то кастомная кодировка.
Но знаете что самое интересное? Если просматривать такой проблемный файл в pdf.js вьювере от mozill'ы (который рендерит в html) то текст прекрасно читается на странице, но вот в коде видно всё те же самые "£ÄÇÆÇÐËÇ", при том что у документа указана кодировка utf-8 и никаких выкрутасов со шрифтами не делается. Вот где загадка…
бессилен.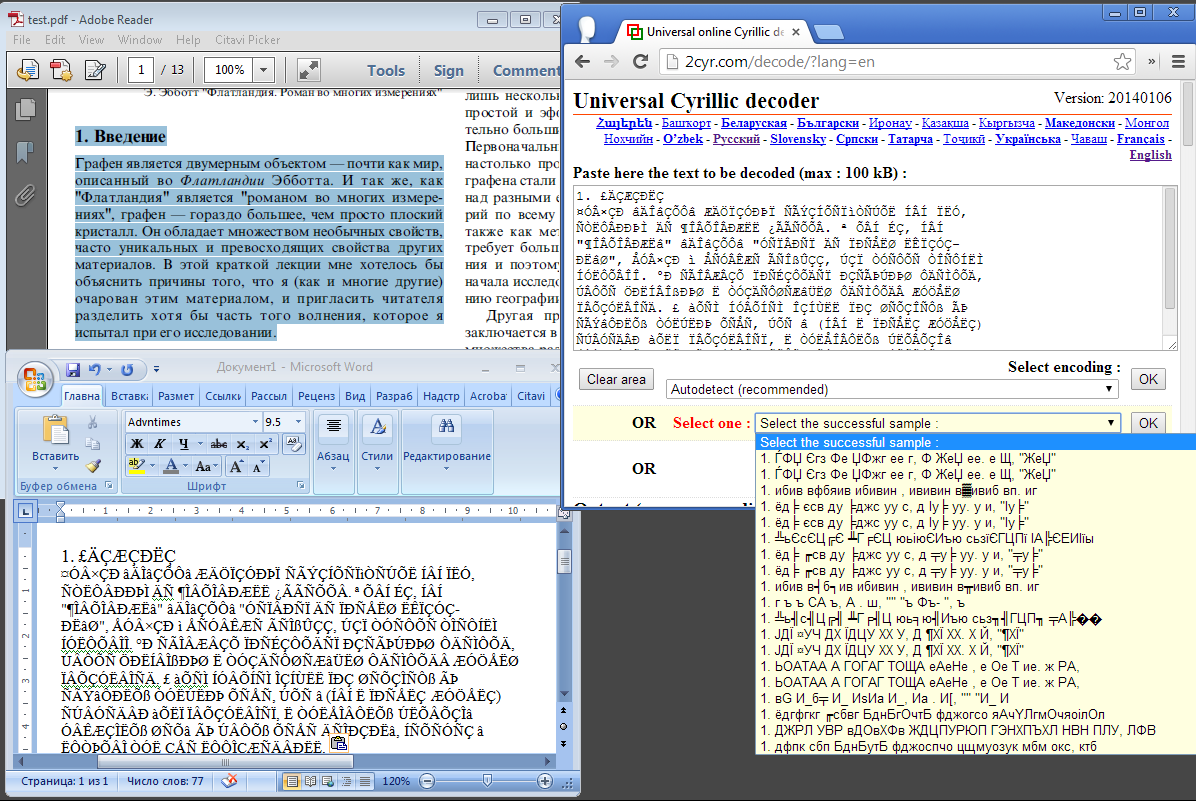
Насколько я понимаю, в PDF может использоваться какая-то кастомная кодировка.
Но знаете что самое интересное? Если просматривать такой проблемный файл в pdf.js вьювере от mozill'ы (который рендерит в html) то текст прекрасно читается на странице, но вот в коде видно всё те же самые "£ÄÇÆÇÐËÇ", при том что у документа указана кодировка utf-8 и никаких выкрутасов со шрифтами не делается. Вот где загадка…
Если в PDF заэмбедден шрифт, да еще и с оптимизацией по использованным символам, то часто исходная буква просто потеряна. Решение от Abby PDF Transformer — рендерить как картинку и распознавать. С кучей неверно распознанных символов как следствие такого подхода.
Abby PDF Transformer не пользовался, но он ведь не бесплатный. Пока единственное спасение это FineReader (который тоже не бесплатный), со всеми проблемами потери форматирования и некорректно распознанными символами.
Если будет время покопаюсь в pdf.js, попытаюсь понять как он хэндлит эти заэмбедденые шрифты.
Если будет время покопаюсь в pdf.js, попытаюсь понять как он хэндлит эти заэмбедденые шрифты.
Попробуйте как посоветовали ниже — частотный анализ шифра подстановки. Символы в шрифте идут по порядку их появления в документе, и теоретически набрав первую строку и выкинув из нее повторные вхождения символов вы получаете словарь замены. Там есть нюансы — порядок символов в отрендеренном документе не означает их порядка в исходном тексте, но частные случаи могут сработать.
Альтернативный вариант — рендерить PDF в растр (tiff/png) через ghostscript, и распознавать бесплатными OCR
Альтернативный вариант — рендерить PDF в растр (tiff/png) через ghostscript, и распознавать бесплатными OCR
Надо будет попробовать…
Да, вот какие задачи приходится решать русским учёным. И это при работе с технологией, которая, вроде как, должна была бы упрощать работу с документами (правда pdf не обязан гарантировать возможность скопировать текст, только воспроизводимость на любых устройствах). Интересно, если собрать свой велосипед со встроенным расшифровщиком, то будет ли он пользоваться спросом?
Да, вот какие задачи приходится решать русским учёным. И это при работе с технологией, которая, вроде как, должна была бы упрощать работу с документами (правда pdf не обязан гарантировать возможность скопировать текст, только воспроизводимость на любых устройствах). Интересно, если собрать свой велосипед со встроенным расшифровщиком, то будет ли он пользоваться спросом?
Если действительно всё так плохо, в голову приходят только методы расшифровки шифра подстановки :)
Костыльное решение для вашей конкретной проблемы (ответ где Iceni Infix)
Где-то ещё существуют сайты с неверно указанной кодировкой? Я лет 10 уже таких не встречал.
Форум популярной прошивки роутеров ASUS — wl500g.info/activity.php
В Хроме/Хромиуме таких открывается, на удивление, много.
В других браузерах такой проблемы давно не встречал.
В других браузерах такой проблемы давно не встречал.
Каждый раз, когда вижу такие символы, в голове начинает играть припев из System Of A Down — I-E-A-I-A-I-O
оффтоп
Между прочим, единственное существительное, которое при преобразовании (cp1251 as ISO-8859-1) as cp1251 даёт ieaiaio — «пигмент».
Регулярка для самостоятельного поиска:
А на самом деле I-E-A-I-A-I-O значит idealization.
Регулярка для самостоятельного поиска:
^[м-п][и-л][а-е][м-п][а-е][м-п][т-ц]$А на самом деле I-E-A-I-A-I-O значит idealization.
Спасибо за статью очень помогает когда скачиваешь субтитры на великом и могучем которые зачастую создают впечатление что у их создателей руки растут из ректального прохода нет представления о существовании юникода и того что мы живем в 21 веке. Скажите а можно так же автоматически ловко делать конвертацию для мета данных mp3 и других медиа файлов? А то такое впечатление создается что их одни и те же люди делают.
Тут я вряд ли подскажу (: Но кажется что можно написать скриптик, который просто будет итерировать по файлам и заменять их метаданные. Наверное нужно посмотреть в сторону чего-то типа eyeD3
А чем chardet неугодил?
Допустим есть у тебя u'йПЮЙНГЪАПШ АКЕЮРЭ'. Как сделать из этого u'Кракозябры блеать' при помощи chardet? У меня не получилось.
Если я правильно понимаю, вы с начала имеете какое-то наличие байтов и не знаете под какой кодировкой этот текст.
И вы СРАЗУ-ЖЕ из этого сделали юникод (u"") без знания что там внутри, не зная какая-же кодировка…
Тут не проблема chardet, тут проблема логики подхода. Chardet выкидывает вам с какой вероятностью та или инная кодировка используется в тексте.
Только после этого можно разумно переводить последовательность байтов в юникод.
Я думаю что тут вы решали что-то что сами с самого начала напортачили, так как не понимали о чём речь идёт…
Многие начинающие питонисты не сразу разбираются в юникоде питона и не сразу это им дается.
Этим не хочу сказать что вы что-то сделали плохо, я наступал на те-же грабли, думаю что Вам надо пересмотреть проблему.
Так как я например решал подобную задачу кучей говнокода, а когда разобрался, всё было намного проще.
И вы СРАЗУ-ЖЕ из этого сделали юникод (u"") без знания что там внутри, не зная какая-же кодировка…
Тут не проблема chardet, тут проблема логики подхода. Chardet выкидывает вам с какой вероятностью та или инная кодировка используется в тексте.
Только после этого можно разумно переводить последовательность байтов в юникод.
Я думаю что тут вы решали что-то что сами с самого начала напортачили, так как не понимали о чём речь идёт…
Многие начинающие питонисты не сразу разбираются в юникоде питона и не сразу это им дается.
Этим не хочу сказать что вы что-то сделали плохо, я наступал на те-же грабли, думаю что Вам надо пересмотреть проблему.
Так как я например решал подобную задачу кучей говнокода, а когда разобрался, всё было намного проще.
Как поспешно Вы делаете выводы и навешиваете ярлыки…
В вебе предостаточно документов, скачав которые старым добрым урллибом и прогнав через чардет — получишь фигню. Я понимаю что такое кодировки и чем они отличаются от юникода. Рассуждать кто тут напортачил — это не особо полезная тема для обсуждения. И поверьте, в вебе множество случаев когда накосячили уже где-то заранее. Тут вопрос в другом. Не важно, u'йПЮЙНГЪАПШ АКЕЮРЭ' или 'йПЮЙНГЪАПШ АКЕЮРЭ' или ещё как то — чардет не поможет восстановить первоначальный текст.
В вебе предостаточно документов, скачав которые старым добрым урллибом и прогнав через чардет — получишь фигню. Я понимаю что такое кодировки и чем они отличаются от юникода. Рассуждать кто тут напортачил — это не особо полезная тема для обсуждения. И поверьте, в вебе множество случаев когда накосячили уже где-то заранее. Тут вопрос в другом. Не важно, u'йПЮЙНГЪАПШ АКЕЮРЭ' или 'йПЮЙНГЪАПШ АКЕЮРЭ' или ещё как то — чардет не поможет восстановить первоначальный текст.
отличный детектор кодировок есть в библиотеке ICU, использовал при импорте метаданных, вобщем-то две функции вызывать и все.
Спасибо за наводку, интересная штука. Но то что нужно не делает, насколько я понимаю. Либо я что-то не так сделал. Вот, смотри:
Сначала:
Далее в питончике:
Сначала:
# sudo apt-get install python-pyicu
Далее в питончике:
import icu
print icu.CharsetDetector('ëÒÁËÏÚÑÂÒÙ').detect().getName() # выведет UTF-8, мою локаль
print icu.CharsetDetector(u'привет'.encode('cp1251').decode('koi8-r').encode('cp1251')).detect().getName() # выведет GB18030
Честно говоря я исходил из такой логики — разгадывать кириллические кракозябры может понадобиться только человеку который владеет… кириллице й!
В плане того, что говорит об этом политика pypi — не задумался как-то даже. Погуглю, если что ридми перепишу. Ну или ты может законтрибьютишь за спасибо? (:
В плане того, что говорит об этом политика pypi — не задумался как-то даже. Погуглю, если что ридми перепишу. Ну или ты может законтрибьютишь за спасибо? (:
Верно. Это, кстати, не учтено при написании ридми, но учтено в коде. Там есть удобная тулза для генерации словарей плюс-слов и 3-граммов. Так что, при желании всё это затачивается под нужную кириллицу довольно просто. По факту, чтобы законтрибьютить ещё один язык в библиотеку — нужно просто немного времени, текстовка для генерации словарей и список кодировок. Всё остальное в коде уже есть.
А ридми… Да, может стоит переписать на англ, но это уже как-нибудь потом в свободное время
А ридми… Да, может стоит переписать на англ, но это уже как-нибудь потом в свободное время
Sign up to leave a comment.
Учимся бороться с ëÒÁËÏÚÑÂÒÙ