Comments 29
Что-то кроме восьми LEDов ничего дебажного на плате нет. Почему ее тогда не сделали на шине PCIe? И что подразумевается под Evaluation в данном случае?
Ну там вообще много всего, судя по списку:
1Gbit Ethernet
USB 2.0 OTG
CAN
SPI
I²C
UART-USB Converter
3.3V GPIOs (62)
User LEDs (8+3)
DIP-Switches (8)
Navigationkey
LVDS connector for e.g. CMOS-Sensor
LCD TFT interface
Embedded USB Blaster II
μSD Card Slot
Temperature Sensor
PCIe на этом чипе вроде как не сделать. Собственно это плата «начального» уровня.
1Gbit Ethernet
USB 2.0 OTG
CAN
SPI
I²C
UART-USB Converter
3.3V GPIOs (62)
User LEDs (8+3)
DIP-Switches (8)
Navigationkey
LVDS connector for e.g. CMOS-Sensor
LCD TFT interface
Embedded USB Blaster II
μSD Card Slot
Temperature Sensor
PCIe на этом чипе вроде как не сделать. Собственно это плата «начального» уровня.
Что разработчики вкладывали в название платы, точно сказать не могу — тут я только пользователь :)
Думаю, что это обозначает возможность оценить все плюсы/минусы работы с SoC такого формата.
По поводу отладки — nerudo ниже указал список того, что есть на плате.
Хочу добавить, что в таких SoC достаточно развитая система дебага и трасировки.
Кроме обычно «защелкивания» внутренностей FPGA при помощи SignalTap, в SoC одна из фич — Cross-trigger,
когда события/breakpoint'ы одного компонента могут использоваться для трассировки другого.
Сам я с этим на практике пока не работал. Но думаю, что поработаю, когда буду «разгонять» интерфейс.
Соответственно, в следующей статье упомяну.
Думаю, что это обозначает возможность оценить все плюсы/минусы работы с SoC такого формата.
По поводу отладки — nerudo ниже указал список того, что есть на плате.
Хочу добавить, что в таких SoC достаточно развитая система дебага и трасировки.
Кроме обычно «защелкивания» внутренностей FPGA при помощи SignalTap, в SoC одна из фич — Cross-trigger,
когда события/breakpoint'ы одного компонента могут использоваться для трассировки другого.
Сам я с этим на практике пока не работал. Но думаю, что поработаю, когда буду «разгонять» интерфейс.
Соответственно, в следующей статье упомяну.
Автор, у вас есть борода?)) Ловите плюс. На хабре очень нужны такие статьи. Спасибо.
Огромное спасибо. Это наверно первая статья на русском с нормальными примерами. В «Компонентах и Технологиях» был сериал ни о чем в трех сериях на эту тему,
И еще 1 плюс.
Кстати а борода тут при чем? Для тех кто в танке :).
Кстати а борода тут при чем? Для тех кто в танке :).

Спасибо большое :))
Очень круто. Спасибо! Пишите еще.
А что означает -O3?
А что означает -O3?
Возможно, повысить скорость обмена можно путем отключения вывода в консоль из memblock.o
Хочу пояснить, что доступ к памяти через отображение /dev/mem выбран для простоты примера.
В реальной жизни такая практика достаточно опасна и чревата ошибками.
Правильнее использовать техники типа Userspace I/O:
Спасибо nymitr за замечание.
В реальной жизни такая практика достаточно опасна и чревата ошибками.
Правильнее использовать техники типа Userspace I/O:
Спасибо nymitr за замечание.
349€ за такую платку, нет, спасибо. Моя ZYBO — умеет так-же, и стоит 189$
Так я же нисколько не против :)
Просто так исторически сложилось, что мы «сидим» на Altera, поэтому мне в руки попала эта платка.
Просто так исторически сложилось, что мы «сидим» на Altera, поэтому мне в руки попала эта платка.
Для каких задач используете эту плату?
Какая скорость на запись/чтение в FPGA у Xillinx?
Какая скорость на запись/чтение в FPGA у Xillinx?
Xilinx предлагает несколько разных шин соединения процессора и FPGA внутри Zynq'а. Для них будут существенно разные скорости. Подозреваю, что и с Alter'ой аналогичная ситуация.
Я тоже так думаю, просто интересно сравнение производительности чипов, если встал вопрос о деньгах. Тот Cyclone, который стоит в этой плате жирнее (больше логики и памяти) чем Z-7010, и не является лоукостом)
От жирности чипа и спидгрейда (если сравнивать серию Cyclone с одинаковым числом ядер) производительность скорее всего не зависит: эти же числа можно получить при самом дешёвом чипе, который около 50-70$ стоит. На плате за 189$ тоже стоит лоукост чип.
Поэтому я предлагаю сравнивать не борды, а чипы, т.к. не все используют готовые борды в своих задачах, кто-то и сам может развести плату и чип поставить) Плюс интересно кто что делает на FPGA)
От жирности чипа и спидгрейда (если сравнивать серию Cyclone с одинаковым числом ядер) производительность скорее всего не зависит: эти же числа можно получить при самом дешёвом чипе, который около 50-70$ стоит. На плате за 189$ тоже стоит лоукост чип.
Поэтому я предлагаю сравнивать не борды, а чипы, т.к. не все используют готовые борды в своих задачах, кто-то и сам может развести плату и чип поставить) Плюс интересно кто что делает на FPGA)
Вряд ли, шина там физически одна. Те измерения, которые приведены — ни о чем, автор совершенно верно отметил, что для измерения пропускной способности надо использовать dma. А так вышло измерение связки процессор+программа, главным образом. Пропусная способность памяти и внутреннего интерконнекта значительно выше.
Не одна, а 2 (с половиной). Одна — высокоскоростная и подключена напрямую к памяти и умеет DMA, другая — для всякой небыстрой периферии. Да и сами шины бывают 3-х видов:
* AXI, шириной 32 или 64 бит.
* AXI-Lite (32бит)
* AXI-Stream — самая интересная из всех, для ЦОС — самое то.
Да и вообще, Xilinx в плане шины ничего особенного не выдумывали, а взяли то, что сделано ARM'ом для своих процов.
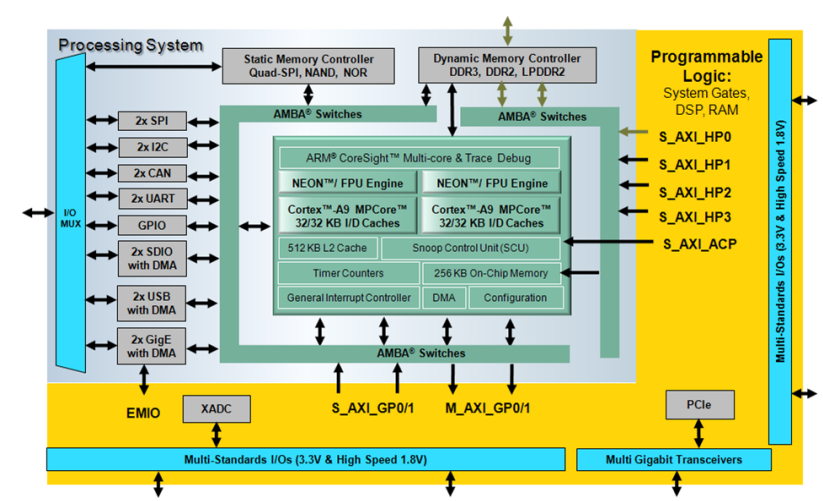
* AXI, шириной 32 или 64 бит.
* AXI-Lite (32бит)
* AXI-Stream — самая интересная из всех, для ЦОС — самое то.
Да и вообще, Xilinx в плане шины ничего особенного не выдумывали, а взяли то, что сделано ARM'ом для своих процов.
Да, согласен, погорячился. Я подразумевал стандартную AXI, AXI-lite несерьезно совсем. А вот на счет AXI-Stream у меня сомнения — разве между HPS и FPGA имеется поддержка такого интерфейса? В доках быстро не нашлось…
Грубо говоря — это надстройка над стандартной AXI, когда мастером выступает не CPU, а блок внутри FPGA, который записывает/читает память в обход процессора. Работает она только с первой шиной (AXI-HP, на рисунке эта шина справа).
Хотя я вот поигрался с AXI-Stream FIFO, которая наоборот — является слейвом, и управляется процессором. Очень простая в освоении (пишешь туда ворды из процессора, а на шине их получаешь). Но уж очень не любит когда процессор начинает загружаться другими процессами. Так что таки надо переходить на DMA, не зря-ж его придумали.
Хотя я вот поигрался с AXI-Stream FIFO, которая наоборот — является слейвом, и управляется процессором. Очень простая в освоении (пишешь туда ворды из процессора, а на шине их получаешь). Но уж очень не любит когда процессор начинает загружаться другими процессами. Так что таки надо переходить на DMA, не зря-ж его придумали.
У нас на этой ПЛИСине тек и не удалось подружить АРМы и сеть. Причём компилили альтеровские примеры, не работают. Звонили в «ЭФО», они отправили запрос в «Альтеру», т.е. ответили «ну да, типа, есть такая бага в некоторых микрухах». И всё. Так что будьте осторожны!
У них багов хватает. Часть багов фиксится переходом на новые версии EDS/Quartus (ага, при этом добавляются новые). А по хорошему — надо заводить аккаунт на техподдержке альтеры (увы, тут надо быть юрлицом), тогда на вопросы отвечают со скоростью пулемёта. Из приятных приколов:
1) В 13.0/13.0 sp1 нельзя было использовать половину LVDS пар — при компиляции трассировщик ругался, что «низя юзать диффпару 1 поскольку оно конфликтует с дифф2», причем даже если там никакого дифф сигнала не было замаплено.
2) 13.1 — есть грабли с F2H мостом — по нему низя подняться по скорости выше 150 мегабайт в секунду.
3) 13.х EDS — тупо не дает нормально работать под baremetal — надо всё делать руками (^#@$@!!! сколько времени я угробил, пока родил условно-рабочий скрипт отладки).
4) С версией 14.0 мне понравился тот фикус, что «64 bit only». Блин, у меня половина дров на системе времен царя гороха, а тут надо на 64битную винду переходить.
5) Классная вешь есть ещё — плис спокойно вешает ARM обращениями к памяти. т.е. перезагрузить ARM отдельно от ПЛИС — плохая идея.
Если кому интересна разработка на этой платформе в baremetal — велкам на семинары, в москве ебвшники оный будут в октябре-ноябре делать. Там будет интересно =)
1) В 13.0/13.0 sp1 нельзя было использовать половину LVDS пар — при компиляции трассировщик ругался, что «низя юзать диффпару 1 поскольку оно конфликтует с дифф2», причем даже если там никакого дифф сигнала не было замаплено.
2) 13.1 — есть грабли с F2H мостом — по нему низя подняться по скорости выше 150 мегабайт в секунду.
3) 13.х EDS — тупо не дает нормально работать под baremetal — надо всё делать руками (^#@$@!!! сколько времени я угробил, пока родил условно-рабочий скрипт отладки).
4) С версией 14.0 мне понравился тот фикус, что «64 bit only». Блин, у меня половина дров на системе времен царя гороха, а тут надо на 64битную винду переходить.
5) Классная вешь есть ещё — плис спокойно вешает ARM обращениями к памяти. т.е. перезагрузить ARM отдельно от ПЛИС — плохая идея.
Если кому интересна разработка на этой платформе в baremetal — велкам на семинары, в москве ебвшники оный будут в октябре-ноябре делать. Там будет интересно =)
Sign up to leave a comment.
Поднимаем SOC: ARM + FPGA