Comments 41
Ура, снова торт!
Скажите, какая из этих текстур дана в глобальных координатах, а какая в касательных к объекту?Первая в глобальных. В ней цвет (значения векторов) очень сильно изменяется от положения в пространстве.
Какой формат текстуры предпочтительнее — касательный или глобальный? Почему?Касательный. Больше диапазон значений, хотя вроде бы для применения нужно на одно умножение векторов больше.
Действительно, синюшняя карта дана в касательной системе координат (репер Френе). А синюшняя она потому, что нормали в карте всё же обычно совпадают с нормалями к базовой поверхности (третья компонента репера).
С обоснованием формата текстуры либо не понял, что вы имеете в виду, либо не согласен.
С обоснованием формата текстуры либо не понял, что вы имеете в виду, либо не согласен.
Наверно чушь. Идея была в том, что мы храним нормали в графическом файле в 8-битных каналах. Это значит, что на каждую координату у нас [0-255] значений. Если мы записываем координаты в глобальном формате, то теряется точность. Но теперь понимаю, что это просто направление, и кол-во возможны вариантов направления не меняется от точки отсчета нулевого направления.
Тогда выгоднее в глобальном из-за лишенго умножения. Так?
Тогда выгоднее в глобальном из-за лишенго умножения. Так?
Если использовать нормаль с единичной длиной, то имея 8 бит на канал вы не используете весь диапазон возможных значений, а только маленькую часть — поверхность сферы.
Но есть простой хак: в шейдере распаковываем нормаль normalize(normal.xyz), сохраняя в текстуре полный диапазон значений из всех возможных векторов N^3.
Геометрию модели в «глобальных координатах» (на самом деле в локальных координатах модели) сложно искажать — нормаль потребует коррекции. Отсюда вытекает дополнительная сложность при наложения декалей (например следов от пуль) и детальных текстур (высокочастотного шума).
Но есть простой хак: в шейдере распаковываем нормаль normalize(normal.xyz), сохраняя в текстуре полный диапазон значений из всех возможных векторов N^3.
Геометрию модели в «глобальных координатах» (на самом деле в локальных координатах модели) сложно искажать — нормаль потребует коррекции. Отсюда вытекает дополнительная сложность при наложения декалей (например следов от пуль) и детальных текстур (высокочастотного шума).
Экономим умножение, да, но если будем использовать глобальную систему, то наткнемся на невозможность анимировать модель.
С чего это вдруг? При анимации просто умножаем на матрицу анимации 3х3 и всё (само собой если анимация в шейдере, сейчас трудно найти где она происходит не в шейдере). И при анимации в глобальных дополнительно выгоднее хранить т.к. ненужно хранить информацию о тангентах и бинормалях чтобы правильно развернуть нормаль. Хранить нормаль в виде касательных выгоднее только потому что точность выше.
Глобальные координаты проще, не надо считать репер Френе.
Но текстуру в касательных координатах можно накладывать на любые модели. Например, если у вас есть кирпичная стена, то вы не будете хранить отдельную текстуру для всех возможных ориентаций стены в сцене. Вы сделаете один маленький кусочек касательной текстуры и все стены получат красивый нормалмап из одного и того же места.
Но текстуру в касательных координатах можно накладывать на любые модели. Например, если у вас есть кирпичная стена, то вы не будете хранить отдельную текстуру для всех возможных ориентаций стены в сцене. Вы сделаете один маленький кусочек касательной текстуры и все стены получат красивый нормалмап из одного и того же места.
Все пишут, что касательный формат лучше, потому что глобальный не подразумевает искажение модели. Это так, но есть еще одна причина: касательный формат использует всего два цветовых канала — а это на треть меньше, чем глобальный. Одна из самых тяжелых операций на гпу — это чтение из текстуры, чем меньше данных — тем лучше. Особенно актуально для мобилок. И поэтому быстрее выполнить преобразование, чем читать дополнительную информацию.
Как модель в лице-то переменилась! А кстати всё равно узнал.
У вас ошибка в реализации работы с Z буфером.
Вы делите вершины на [3] элемент сразу в вершинном шейдере. Этого делать нельзя, т.к. афинные преобразования линейны, а вот глубина у нас уже не линейна.
Нужно интерполировать z и w отдельно, и делить попиксельно. То есть код вершинного шейдера переписать вот так:
В коде функции triangle принимать Vec4f, и переделать проверку в буфере глубины как-то так:
Случай, когда ваш подход с «сразу делением на w» не работает:
Делаем 2 прямоугольника (горизонтальный и вертикальный) с вершинами:
1 — Vec3f(-100.0, -1.0, 0.0) Vec3f(-100.0, 1.0, 0.0) Vec3f(100.0, -1.0, 0.0) Vec3f(100.0, 1.0, 0.0)
2 — Vec3f(-1.0, -100.0, 0.1) Vec3f(-1.0, 100.0, 0.1) Vec3f(1.0, -100.0, 0.1) Vec3f(1.0, 100.0, 0.1)
Крутим эту пару треугольников вокруг OY и наблюдаем артефакт.
Поэтому все графические API получают 4 параметра, и сразу делить на W в вершинном шейдере ни в коем случае нельзя.
p.s. Проблема растет оттуда же: habrahabr.ru/post/248611/#comment_8238683
Хоть вы там и написали в ответе, что это «муторно» и ненужно, в реале же без этой коррекции мы получим некорректный буфер глубины. Так что коррекция нужна, и она не муторная.
Вы делите вершины на [3] элемент сразу в вершинном шейдере. Этого делать нельзя, т.к. афинные преобразования линейны, а вот глубина у нас уже не линейна.
Нужно интерполировать z и w отдельно, и делить попиксельно. То есть код вершинного шейдера переписать вот так:
virtual Vec4f vertex(int iface, int nthvert) {
Vec4f gl_Vertex = embed<4>(model->vert(iface, nthvert)); // read the vertex from .obj file
gl_Vertex = Viewport*Projection*ModelView*gl_Vertex; // transform it to screen coordinates
varying_intensity[nthvert] = std::max(0.f, model->normal(iface, nthvert)*light_dir); // get diffuse lighting intensity
return gl_Vertex; // project homogenious coordinates to 3d
}
В коде функции triangle принимать Vec4f, и переделать проверку в буфере глубины как-то так:
Vec3f c = barycentric(pts[0], pts[1], pts[2], P);
float z = pts[0].z*c.x + pts[1].z*c.y + pts[2].z*c.z;
float w = pts[0].w*c.x + pts[1].w*c.y + pts[2].w*c.z;
P.z = std::max(0, std::min(255, z/w+.5));
Случай, когда ваш подход с «сразу делением на w» не работает:
Делаем 2 прямоугольника (горизонтальный и вертикальный) с вершинами:
1 — Vec3f(-100.0, -1.0, 0.0) Vec3f(-100.0, 1.0, 0.0) Vec3f(100.0, -1.0, 0.0) Vec3f(100.0, 1.0, 0.0)
2 — Vec3f(-1.0, -100.0, 0.1) Vec3f(-1.0, 100.0, 0.1) Vec3f(1.0, -100.0, 0.1) Vec3f(1.0, 100.0, 0.1)
Крутим эту пару треугольников вокруг OY и наблюдаем артефакт.
Поэтому все графические API получают 4 параметра, и сразу делить на W в вершинном шейдере ни в коем случае нельзя.
p.s. Проблема растет оттуда же: habrahabr.ru/post/248611/#comment_8238683
Хоть вы там и написали в ответе, что это «муторно» и ненужно, в реале же без этой коррекции мы получим некорректный буфер глубины. Так что коррекция нужна, и она не муторная.
Ммм, я ещё не проснулся, какой артефакт будет в вашей сцене из двух прямоугольников? Z-fighting?
Что-то я не могу понять про нелинейность глубины.
Что-то я не могу понять про нелинейность глубины.
Прямоугольник из-под низа будет плаво вылазить поверх вверхнего треугольника, когда будет становиться все параллельнее взгляду. Словами сложно описать, вы сделайте такую модельку, и покрутите, все сразу увидите.
Камера где должна быть?
Артефакта не вижу, но спасибо за замечание. Будет время — поправлю.
Скрытый текст
Да, типа такого креста надо покрутить.
У меня нет сейчас возможности показать на примере. Могу показать потерю перспективной информации на текстурах. Создаем пустой проект в RenderMonkey с текутрированный кубиком. Добавляем в вершинном шейдере gl_Position /= gl_Position.w;
Результат такой. Слева без деления на w в вершинном. Справа — с делением на w:
p.s. Сейчас думаю, что насчет буфера глубины возможно был не прав (надо проверить), т.к. скорее всего у нас будет частный случай, при котором оно будет работать. Однако в общем случае нужно делать так, как я описал. Отсутствие деления на w в вершинном шейдере автоматом это решит проблему с текстурированием, т.к. текстурные координаты будут вычисляться по еще линейному xyz.
У меня нет сейчас возможности показать на примере. Могу показать потерю перспективной информации на текстурах. Создаем пустой проект в RenderMonkey с текутрированный кубиком. Добавляем в вершинном шейдере gl_Position /= gl_Position.w;
Результат такой. Слева без деления на w в вершинном. Справа — с делением на w:
Скрытый текст
p.s. Сейчас думаю, что насчет буфера глубины возможно был не прав (надо проверить), т.к. скорее всего у нас будет частный случай, при котором оно будет работать. Однако в общем случае нужно делать так, как я описал. Отсутствие деления на w в вершинном шейдере автоматом это решит проблему с текстурированием, т.к. текстурные координаты будут вычисляться по еще линейному xyz.
С глубиной всё в порядке, с текстурами согласен. Поправлю при случае, спасибо.
Про глубину вот, я убрал третью компоненту, она только мешает. В моей сцене глубина — это игрек. Разделив сразу мы никогда не получим инверсии красного и синего треугольников.
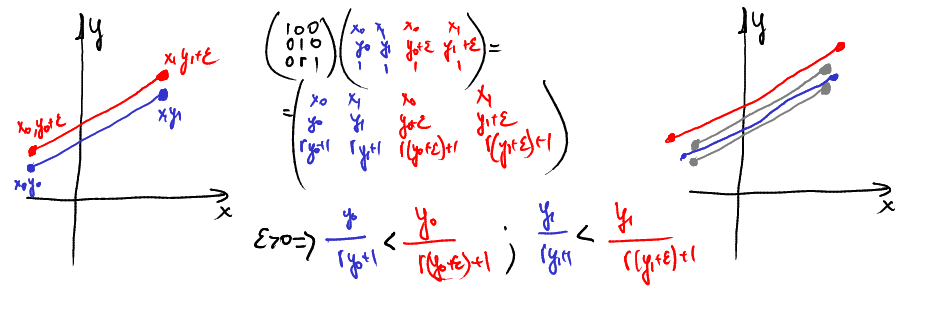
Про глубину вот, я убрал третью компоненту, она только мешает. В моей сцене глубина — это игрек. Разделив сразу мы никогда не получим инверсии красного и синего треугольников.
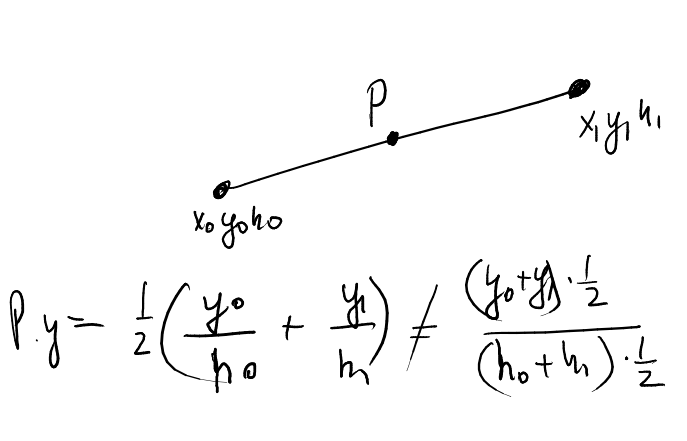
Выкладки у вас верные, но вы их делаете для вершин. И забываете что дальше у вас линейная интерполяция.
После перспективного деления глубина должна меняться не линейно. Вот смотрите, слева сцена (так же без Y), а справа я нарисовал буфер глубины, какой он должен быть после перспективного деления:

а зеленой линией нарисовано то, что сделает линейная интерполяция, т.е. что будет записано в буфере глубины в вашем случае.
После перспективного деления глубина должна меняться не линейно. Вот смотрите, слева сцена (так же без Y), а справа я нарисовал буфер глубины, какой он должен быть после перспективного деления:
а зеленой линией нарисовано то, что сделает линейная интерполяция, т.е. что будет записано в буфере глубины в вашем случае.
Как странно у вас чайник отрендерился =)
На картинке с «формулой» Фонга справа ambient отсутствует.
Поменяйте, пожалуйста, «артиста» на «дизайнера» или «художника» хотя-бы… :)
Очень частая ошибка, которая повсеместно в интернете — забывают, что сумма коэффициентов Kd + Ks = 1. из-за этого модель начинает отражать больше света, чем получает от источника. У вас эта ошибка присутствует.
Очень понравился ваш цикл статей, поэтому я, что называется, решил совместить полезное с полезным и написать рендерер на расте.
К сожалению пока не успел догнать вас, нахожусь лишь на третьем шаге. Имеется голова с диффузной текстурой. Сейчас по-моему удалось избавиться от артефактов, которые по всей видимости возникают из-за арифметики с плавающими числами. Т.к. раст не позволяет автоматически конвертироватьчисловые типы, то чтобы не приводить числа по десять раз туда-сюда в каждой строчке я передаю в функцию triangle векторы с дробными координатами и оперирую ими до самого вывода пикселя. К тому же треугольник я отрисовываю не горизонтальными полосками, а вертикальными. В результате мое изображение немного отличается от вашего, приведенного в третьей статье. Например, есть достаточно заметное отличие на веке левого глаза.
Код выложен на гитхабе, может быть кому-то еще будет интересно. Или опытные «растаманы» подскажут мне, что можно улучшить :)
К сожалению пока не успел догнать вас, нахожусь лишь на третьем шаге. Имеется голова с диффузной текстурой. Сейчас по-моему удалось избавиться от артефактов, которые по всей видимости возникают из-за арифметики с плавающими числами. Т.к. раст не позволяет автоматически конвертировать
Картинка
Код выложен на гитхабе, может быть кому-то еще будет интересно. Или опытные «растаманы» подскажут мне, что можно улучшить :)
К тому же треугольник я отрисовываю не горизонтальными полосками, а вертикальными.Но зачем? Это может сильно ухудшить производительность.
т.к. раст не позволяет автоматически конвертироватьчисловыетипы
Раст позволяет это делать немного по-другому, но из-за бага в компиляторе, я до недавнего времени, пока не обошёл это, висел в первой части. Сегодня только закоммитил доделанные операции с числами, вот тут можно посмотреть: github.com/torkve/habropengl/blob/master/src/vec.rs
В смысле, конвертировать конечно придётся, но всё в одном месте.
Спасибо, ваше решение весьма интересное и очень кстати, два unwrap без проверки, правда, немного смущают. Но вообще я больше жаловался на сложности работы с разными числовыми типами, где нужны постоянные касты. После других языков это кажется избыточным и некрасивым, хотя с другой стороны заставляет больше задумываться о дизайне кода.
Это на самом деле очень правильно, потому что в оригинальном коде, например, есть очень много кастов между u8/u32/i32, которые легко в определённых ситуациях могут выдать нам мусор, и единственное, что спасает — это допущение, что мы не будем рендерить картинки такого большого размера.
Так что мои допущения с unwrap(), по большому счёту, такие же: я предполагаю, что мы будем инициализировать точки исключительно типами, которые можно свободно конвертировать в/из float, т.е. все те же стандартные численные типы с теми же условиями переполнения.
Так что мои допущения с unwrap(), по большому счёту, такие же: я предполагаю, что мы будем инициализировать точки исключительно типами, которые можно свободно конвертировать в/из float, т.е. все те же стандартные численные типы с теми же условиями переполнения.
Касательно «тонировки Гуро» и вообще слова тонировка — оно в русском больше относится к колхозному тюнингу автомобилей, чем к графике. Стандартно это «закраска Гуро» или «модель освещения Гуро» или «затенение Гуро».
Мы друг друга поняли? Ну и славно. А слово я взял отсюда.
В скрытых текстах изображения не прогружаются. Зачем тогда они нужны?
То есть, вы взяли текст семилетней давности и удивляетесь, что ссылки битые? :)
Вот актуальная версия текста: https://github.com/ssloy/tinyrenderer/wiki/Lesson-6:-Shaders-for-the-software-renderer
Вот что мне "нравится" в статьях с картинками - это то что внешние ссылки со временем становятся недоступными. Со временем так здрово повышается "информативность" статьи... (((
Sign up to leave a comment.
Краткий курс компьютерной графики: пишем упрощённый OpenGL своими руками, статья 5 из 6