Comments 334
Точнее, про отравление предсказателя переходов понятно, а вот с его эксплуатацией для повышения привелегий — пока не до конца разобрался.
Сначала много раз тренируют бренч предиктор, чтобы был заход внутрь if, потом внезапно подают туда адрес, из которого нужно красть значение, и при этом такой, чтобы мы не зашли внутрь if.
Внтури if — чтение памяти.
Бренч предиктор говорит: «скорей всего мы зайдем в if». Это предположение неверно, но пока это неизвестно — и поэтому cpu начинает исполнять то, что внутри if.
В результате выполнения кода, значение из адреса, с которого нельзя читать, попадает к кэш. Вообще, это — исключение. Но потом оказывается, что бренч предиктор ошибся, а раз ошибся, то и исключения нет, и мы как бы и не читали этот адрес.
Исключение отменяется — но остается побочный эффект: данные в кэше.
Фактически, уже это — некорректная работа. Я так понимаю, что если мы прочитаем этот адрес, то получим какое-то значение, и это значение будет не из нашего процесса, что некорректно.
Чтобы узнать, где подтянутое в кэш число, используется атака по времени. Читается все подряд — и замеряется время чтения. То, что было подтянуто в кэш, прочитается гораздо быстрей.
Все остальные бубнопляски в коде — обход других предикторов и оптимизаторов.
Мой AMD phenom x4 B40 уязвим на тесте. Но — тест читает свою же память. То есть, чистоты эксперимента — нет. Кернел спейс читать не пробовал(не знаю его адреса, надо разбираться как узнать, и как потом понять, что прочитал именно его). Может, завтра попробую вечером.
Со второй разновидностью атаки spectre не разбирался, но суть там та же. Неким способом заставить выполниться код, который что-то подтянет в кэш.
Там дальше глава 5, про косвенные переходы. Когда переход делается не по фиксированному адресу, а по адресу, который в регистре, или по адресу который лежит в какой-то ячейке памяти. Можно сделать финт ушами — и «спекулятивно» выполнить не тот код, который должен был бы выполниться. Насколько понимаю — переход по адресу, которого нет в icache занимает ВРЕМЯ и все это время выполняется то, что в этом кэше лежит, только потом это все отменяется, поэтому нам незаметно.
Но этот код, хоть и отменяется, но что-то подягивает в кэш. И дальше как обычно.
Суть одна — тем или иным способом заставляют cpu выполнить код пользователя спекулятивно, причем так, что потом он гарантирванно отменится. А в таком выполнении можно (было до того, как нашли уязвимость) безнаказанно «побегать в труселях по мечети»: все равно никто не узнает.
там два чтения — одно запрещенное — а другое разрешенное:
temp = array2[array1[x]*512];
х — адрес внутри запрещенной области array1, array2 — разрешенная область.
Спеклятивно это выполняется. Значит, какая-то область array2 подтягивается в кэш.
Дальше мы читаем из array2 подряд, измеряя время чтения. И по времени чтения пытаемся понять, была ли подтянута в кэш соответствующая область.
почему 512 — мне не понятно. Размер кэш-лини — 64 байта, а не 512.
Насколько понимаю, предполагается, что ядро лежит по адресу array1. Поэтому, array1[x] — чтение из области ядра.
Потом подтягиваются в кэш соответствущая область памяти из array2. Какая именно область подтянется — зависит от значения, которое лежит по array1[x].
Некоторые имплантации aarch64 также подвержены.
Но это требует привилегий для управления кэшом (чтобы вытащить прочитанные данные). А имея такие привилегии и без того можно делов натворить (как минимум DoS). Поэтому уязвимость менее критична — в правильных окружениях она не выполнима.
Можно попытаться косвенно определить значение данных (через спекулятивное исполнение), но это получается долго и нужно, чтобы процесс не прерывался планировщиком.
чтобы вытащить прочитанные данные
Зачем?
Спасибо за статью.
Spectre — отравление или обман предсказателя переходов. Чтение происходит из своего адресного пространства.
Side channel при этом одинаковый — кеш данных.
Чтение происходит из своего адресного пространства.
Так… и ядро тоже в «своем» адресном пространстве, в этом суть проблемы же.
Насколько я понял, принцип не отличается от meltdown, только дампить можно то, что и так доступно процессу с т.з. ОС.
Мозилла уже залепила у себя www.mozilla.org/en-US/security/advisories/mfsa2018-01
Хром вроде тоже обещает аналогично сделать (или уже сделал)
Чтение происходит из своего адресного пространства.
К своему адресному пространства мы и так имеем доступ.
И того, что я понял, в случае Spectre в документах идёт отсылка к Berkeley Packet Filter (BPF) — это виртуальная машина, позволяющая в режиме ядра выполнять пользовательский код. Meltdown здесь неприменим, т.к. исключение бросить просто невозможно. А вот выйти за границы массива с помощью Spectre вполне можно.
Но при этом в Windows BPF, насколько я понимаю, нет, поэтому Windows не должна быть подвержена этой атаке.
Spectre — отравление или обман предсказателя переходов. Чтение происходит из своего адресного пространства.
Тут немного чисто языковой путаницы. Да, чтение происходит из своего адресного пространства, только оно «свое» для чужого процесса, а не для атакующего.
Вот только почему изоляция страниц спасает от Meltdown, а от Spectre — нет?
Получается, что через мелтдаун мы можем прочесть данные ядра, и оттуда, либо sensitive данные напрямую, либо уже косвенно — данные чужих процессов. Изоляция всех данных и кода ядра означает, что прочесть ничего не получится.
Spectre же заставляет чужой нам процесс спекулятивно читать данные из своего адресного пространства, которые мы потом подхватим через тайминг атаку на кеш. И этот второй чужой процесс тоже не сможет читать ядро, но зато мы сможем из его памяти вытащить данные так, будто мы в его адресном пространстве и находимся.
Кратко (если брать пример под NT из раздела 5.2) — берется код, который зашарен между процессами — dll, ntdll в случае примера. В своем, атакующего процесса, адресном пространстве кусок кода с ветвлением видоизменияется так, чтобы натренировать предсказатель переходов определенным образом. (в атакуемом процессе этот же кусок регулярно атакуемым процессом используется, т.к. это обычный библиотечный код). Предсказатель переходов сохраняет свои предсказания на уровне ЦП, а не процесса, поэтому в том, атакуемом процессе будет происходить то же. Плюс определенным образом сформированные входные параметры — в итоге происходит branch misprediction + чтение данных из пространства атакуемого процесса из-за спекулятивного выполнения, потому что мы натаскали бранч предиктор на заход «вовнутрь». Они потом будут сброшены, потому что переход не произойдет, но в кеше останутся. А из кеша эти данные извелкаются аналогично тому способу, что использован в Meltdown.
В этой pdf написано, что мы контролируем используемые регистры в найденном авторами dll кодом — это вообще как?
Да и откуда нам знать, что этот другой процесс вообще исполнит избранный код? В моем представлении для этого нужно изначально воспользоваться какими-нибудь уязвимостями для удаленного исполнения кода, а в этом случае нам spectre уже и не нужен вовсе.
Да и откуда нам знать, что этот другой процесс вообще исполнит избранный код?
Ну, например, запустить эту программу на своей домашней машинке и посмотреть, что там исполняется, а что нет. Учитывая, что они с ntdll игрались, шансов, что код исполнится — много.
Они же использовали Sleep, тут вообще почти что с гарантией.
Spectre же заставляет чужой нам процесс спекулятивно читать данные из своего адресного пространства, которые мы потом подхватим через тайминг атаку на кеш.
Ну вот я прочитал оригинал и все равно не понимаю, как можно заставить чужой процесс что-либо прочитать по определённому адресу.
Да, за счёт шаринга DLL, мы можем обмануть branch prediction так, чтобы при определённом системном вызове спекулятивно выполнился кусок кода из адресного пространства процесса-жертвы.
Но для этого нужно, чтобы мы могли управлять регистрами процесса-жертвы перед вызовом системных функций, чтобы читать проивзольные адреса. То есть просто взять и прочитать память чужого процесса не получится.
То есть, если мы знаем, что нужная нам инструкция в атакуемой программе лежит по адресу 123456, а также в этой программе есть регулярно исполняемый косвенный переход. В атакующей программе мы пишем конструкцию, максимально похожую на переход в атакуемой, но при этом всегда выполняющую переход по адресу 123456. В нашем адресном пространстве, конечно, абсолютно валидный и легальный переход. Что именно у нас лежит по адресу 123456, никакого значения не имеет.
Через некоторое время блок предсказания переходов абсолютно уверен, что все переходы такого вида ведут на адрес 123456, поэтому, когда атакуемая программа — с нашей подачи или по своей инициативе — доходит до аналогичного перехода, процессор радостно начинает спекулятивное исполнение инструкций с адреса 123456. Уже в адресном пространстве атакуемой программы.
Через некоторое время настоящий адрес перехода будет вычислен, процессор осознает ошибку и отбросит результаты спекулятивного выполнения, однако, как и во всех прочих случаях применения Meltdown и Spectre, от него останутся следы в кэше.
Под «нужной инструкцией» по адресу 123456 имеется в виду тот самый «гаджет» (кусок кода атакуемой программы, или из какой либо библиотеки, которую она использует), который оставит такие следы в кэше, которые легко отследить из атакующего процесса.
Я читал много объяснений того, как это работает. Похоже, половина переводов сделаны один-в-один, и разобраться, что происходит можно только в том случае, когда человек постарался добавить ясности "от себя" или начинает расшифровывать всякие термины, без знания которых сложно разобраться.
Я постараюсь описать то, как я это понял, а вы меня поправьте, если я ошибаюсь.
- Процессор может выполнять команды не последовательно, а иногда запускает в параллель исполнение команд, которые в программе расположены позже. Это делается для того, чтобы полностью загрузить свободные вычислительные мощности (конвеер), пока мы ожидаем завершения выполнения других команд (длительное чтение из памяти, например).
- Допустимость или недопустимость чтения из памяти работает на аппаратном уровне, и при взятии информации из недопустимого адреса возникает исключение. Важным моментом является тот факт, что команды чтения по запрещенному адресу могут исполняться спекулятивно, с выполнением реального чтения, но проверка на допустимость команды будет произведена позже и, в случае недопустимости этой операции, результат выполнения этой команды будет отброшен и произойдет исключение. В этом месте как раз и получается аппаратный баг — проверка выполняется позже, что скорее всего обусловлено архитектурными особенностями (мы должны помнить, что это не программа, где мы можем за секунду переставить строчку условия, это реальные транзисторы, которые придется перемещать на кристалле, выбирать для них оптимальное расположение и так далее).
- Чтение из памяти устроено по-особенному: когда мы читаем один байт, вместе с ним загружается в кэш много больше данных, чем требуется, на случай, если нам нужно будет прочитать следующий байт в памяти по порядку, как в большинстве случаев и происходит. Но если после этого мы начинаем читать по адресу, который не попадает в диапазон адресов, загруженных в кэш, происходит так называемый кэш-промах, и данные в кэш приходится считывать заново, а это сильно дольше, чем если бы данные уже были в кэше.
На основе вышеизложенного, мы можем реализовать следующую схему:
- Делаем массив в нашей пользовательской доступной памяти размером char userspace[256 * 4096]. 256 — количество значений которые может принимать байт, 4096 — такое расстояние, на котором гарантировано происходит кэш-промах при последовательном чтении с таким шагом в памяти.
- Для i = 0..255
- Составляем несколько инструкций так, чтобы сначала была инструкция с чтением из памяти по запрещенному адресу restrictedspace[address], а потом, на основе этих данных, выборка из нашего пользовательского массива на основе значения считанного байта: userspace[restrictedspace[address] * 4096]
- Так как нельзя считывать по запрещенному адресу, происходит исключение, но к этому моменту код, который идет далее уже успевает спекулятивно выполниться, и нужная часть нашего пользовательского массива будет загружена в кэш.
- Ловим исключение и измеряем время доступа к элементу address[i * 4096], записывая в массив time[i]
- Повторяем для всех i (goto 2)
- Ищем значение в массиве time, которое сильно отличается в меньшую сторону.
- Полученный индекс и будет искомым значением из запрещенной памяти
В начале кода честно стоит проверка if (address < OUT_OF_BOUNDS), но OUT_OF_BOUNDS задано не константой, а в отдельной области памяти, которая предварительно специально вымывается из кеша.
Это не позволяет процессору мгновенно определить правильную ветку перехода, и в результате он спекулятивно выполняет код, который программа якобы и «не собиралась» исполнять.
от их позиции разве зависит логика работы CPU?
А Intel скорее всего просто будут сбрасывать кэш при отмене операции, хоть это и не совсем верно, зато безопасно.
Вот я тоже подумал про «сбрасывать кэш при отмене», но не получится ли при этом тогда действовать от противного? Прочитать весь наш массив в кэш, и потом замерять, какая часть была сброшена? 256*4096 = 1 Мб, влезет куда угодно, ну в L3 точно.
В идеале надо не сбрасывать, а восстанавливать состояние, но это, похоже, настолько дорого будет, что все преимущества кэша сойдут на нет. По сути, надо будет держать какой-то теневой кэш для кэша, в общем, не стоит оно того.
Прочитать весь наш массив в кэш, и потом замерять, какая часть была сброшена?
Можете подробнее объяснить? Как мы сможем различить эти случаи?
При этом ущерб производительности не колоссально большой, потому что невалидные чтения в действительности выполняются нечасто.
Меня бы больше устроило, если бы команды rdtsc, rdtscp перевели в разряд привелегированных, или совсем отключили, или повысили гранулярность. Для большинства пользователей это будет ок. Нет часов с хорошей гранулярностью — нет проблемы. Как быстры фикс это — ок.
И вообще, пускай юзают hpet.
И вообще, что такое «счетчик» и что такое «поток» если мы говорим о микроархитектуре?
Время переключения потоков (которые потоки операционки) — десятки микросекунд. Это гораздо больше времени чтения, пускай даже и из кэша, и само по себе связано с уходом исполнения в ядро.
Если под понятием «поток» вы подразумевали нечто, что выполняется вторым ядром — то как передавать этот счетчик из второго ядра в первое ядро, еще и ненарушив кэш? Для таких вещей есть барьеры памяти, но они влияют на кэш. По сути передача данных между ядрами — через L3 (хотя это от архитектуры может зависеть) Думаю, там не померяешь так просто такой короткий интервал времени…
Как из одного потока в другой передать этот счетчик?
У потоков общая память.
Время переключения потоков (которые потоки операционки) — десятки микросекунд. Это гораздо больше времени чтения, пускай даже и из кэша, и само по себе связано с уходом исполнения в ядро.
А зачем потоки переключать? Они одновременно же работают на разных ядрах.
Если под понятием «поток» вы подразумевали нечто, что выполняется вторым ядром — то как передавать этот счетчик из второго ядра в первое ядро, еще и ненарушив кэш? Для таких вещей есть барьеры памяти, но они влияют на кэш. По сути передача данных между ядрами — через L3 (хотя это от архитектуры может зависеть) Думаю, там не померяешь так просто такой короткий интервал времени…
Во-первых, один атомарный инкремент занимает около 20 тактов. Впрочем, думаю, тут и без атомарщины можно обойтись, чтобы не лочить шину почём зря.
Во-вторых, ничто не мешает N раз провести атаку на одну и ту же ячейку и замерить суммарное время атаки, если точность измерения времени одиночной атаки недостаточна.
У потоков общая память.
В том то и дело, что несовсем: мы же на микроархитектурном уровне. Несколько ядер на одну память? Как вы себе это представляете? L0, L1 у каждого ядра — свой. L2 — иногда общий, и то не всегда (Xeon Clovertown E5345). Можете lstopo попробовать (под линуксом). Можно в гугл вбить — и включить картинки, и посмотреть, как вообще бывает. Там иногда такое, что даже не представляю что это.
А теперь представьте себе: из L0 одного ядра нужно число переправить в L0 другого ядра. Это сотни тактов, и этот эффект больше, чем то, что мы хотим измерять. И это надо сделать так, чтобы не повлиять на кэш, потому что момент, в который мы это все меряем — очень «нежный». Любая подтяжка в кэш сама по себе уже повлияет на результат.
И это еще не все. Команды исполняются на конвеере. Там еще есть всякие буферы валидации и прочие оптимизации. То, что придет в соседний проц, если не использовать барьеры памяти, может весьма слабо отражать значение реального счетчика.
Во-первых, один атомарный инкремент
Атомарные операции выполняются с барьерами памяти. Ну ок, можно мои рассуждения выше про конвеер убрать. Но барьеры не отменят остального.
N раз провести атаку
Это приходится делать даже с rdtscp. В том коде они это делают 999 раз — и то не всегда помогает. Другие процессы сильно влияют. Счетчик в другом потоке — гораздо более грубый источник времени, а его получение — гораздо более дорогое, чем тот эффект, который измеряется.
Атомарные операции выполняются с барьерами памяти
В архитектуре x86, насколько я помню, нет необходимости в явном использовании барьеров. И мои эксперименты с атомарными инкрементами показывают, что пересылка занимает явно меньше сотни тактов.
В том коде они это делают 999 раз
В том коде на каждой итерации делается вызов rdtsc. Я бы попробовал переписать код так, чтобы измерялось суммарное время 999 попыток, а не каждой из попыток в отдельности.
У атомарных счетчиков — барьеры «под капотом».
Где-то у Шипилева была статья про исследование поведения при помощи jcstress, и там было наглядно показано, что можно нарваться на баги. Эти баги неособо частые, но они есть. И я тогда крутил эти тесты на своем амд — эти баги были.
Но тут с вами я согласен: поскольку мы говорим про взлом, то некоторое кол-во некорректных результатов нас устроит. Если 1 раз из 1000 происходит глюк — это не ок для «обычного» софта, для банковского — вообще смерть, а для задач взлома систем — нормально, даже если 1 раз из 1000 все сработает как хочется :).
Так что, пожалуй, что да. Загрублять rdtsc — не способ.
Это не совсем верное рассуждение:
1. Это по любому не сотни циклов.
2. Применяют хитрости для сокращения времени.
3. Загрузку всегда делают в pipeline к операции. Тут конечно большая наука намешана, чтобы соблюсти когерентность данных.
Но когеретность времени тут не соблюдается. Просто доступ из локального кэша много короче следующего уровня, вот схема опроса счетчика и работает.
* perf stat -e L1-dcache-loads,L1-dcache-load-misses,branches,branch-misses /opt/phpstorm-171/bin/phpstorm.sh
Performance counter stats for '/opt/phpstorm-171/bin/phpstorm.sh':
73.192.922.309 L1-dcache-loads
6.005.629.782 L1-dcache-load-misses # 8,21% of all L1-dcache hits
44.366.574.238 branches
1.757.550.166 branch-misses # 3,96% of all branches
41,088747127 seconds time elapsedПри этом ущерб производительности не колоссально большой, потому что невалидные чтения в действительности выполняются нечасто.Вот же ж, блин, теоретики. Скорость доступа в кэш и в оперативку отличается на два порядка (то есть в сто раз). То есть даже если даже предсказатель будет «промахиваться» в одном случае из сотни (а этого, поверьте, не так-то просто достичь) мы получим проседание производительности на 30-50%.
Но и это, наверняка, не панацея.Не панацея — можно заметить как что-то пропало из кеша. Можно для «первого использования» завести отдельный кеш, но тогда можно будет играться с «двойным первым использованием» и т.д. и т.п.
Кажется, что самое разумное решение — одновременно и самое тупое. Современные системы всё равно делят адресное пространство пополам и по старшему биту адреса можно понять — это данные ядра или нет. Ну так давайте сделаем это деление оффициальным и всё.
И не нужно никаких спекуляций, проверка одного бита — это несколько транзисторов, её куда угодно можно засунуть.
Просто все попытки обращения к адресам, у которых старший битик установлен отвергать «с порога» если мы не в режиме супервизора. И всё.
Сейчас же это делается через таблицы страниц. Что, в конечном, счёте, даёт тот же ответ — но требует обращения к большим и сложным структурам данным. А поскольку это медленно — то приходится делать это параллельно с другими вычислениями… со всеми вытекающими…
Также, для удобства ядра, в какую-то область отображается вся физическая RAM, чтобы ядру видеть сразу все процессы и не заморачиваться с подключением нужной страницы, если надо записать в какой-то процесс.
Теперь придётся все эти «удобства» отключать )))
Почему решение с аннулированием соответствующих строк кэша не закрывает данную уязвимость — мне непонятно.Потому что вам недостаточно просто убрать эту строку из кеша. Нужно ещё вернуть ту, которую вы убрали, чтобы эту положить. Иначе её исчезновение тоже можно заметить. А ещё — всю эту деятельность наблюдает другое ядро, не забывайте, так что наблюдать за всем этим процессом мы можем достаточно пристально.
Мне тут подумалось, для memory mapped io бывает ли такое, чтобы при чтении из ячейки памяти происходили побочные эффекты (типа считали содержимое ячейки — получили значение счетчика и он сбросился в ноль).Бывает. В лёгкую. И это настолько плохо, что уже во времена Pentium Pro появились MTRR, отключающие спекулятивные чтения для определённых диапазонов памяти.
Так что для атаки это использовать нельзя.
Зачем goto 2? В самом начале сбрасываем кэш специальной командой. Массив userspace[256x4096] в кэше отсутствует. После обработки исключения один из блоков длиной 4096 в этом массиве должен быть загружен в кэш. Измеряем время доступа к элементам с номерами ix4096 для i от 0 до 255. Определяем, при каком i время доступа было минимальным. Найденное i будет равно значению из защищенной области памяти. Массив time для этого не нужен, достаточно помнить минимальное время и значение индекса, в котором оно было получено.
Массив time для этого не нужен
Естественно, просто так проще объясняется алгоритм.
Измеряем время доступа к элементам с номерами ix4096 для i от 0 до 255
А разве кэш-промах и вытаскивание новых данных не испортят нам состояние кэша?
1) как атакующий может знать какой именно адрес памяти жертвы его интересует — большинство программ используют стековую архитектуру и многие переменные находятся на стеке и вершина стека перемещается с течением времени. Многие объекты так же имеют ограниченный срок жизни между new и delete и адреса создаваемых и удаляемых объектов зачастую почти случайны особенно в многопоточном приложении жертвы. Даже дизассемблирование прогреммы жертвы до атаки не дает реального знания об интересующих адресах в процессе жертвы.
2) атака подразумевает длительное исследование одной ячейки памяти и за это время ячейка просто может поменять свое значение в многопроцессорной системе.
То есть метод абсолютно не подходит, чтобы сделать снимок памяти процесса жертвы.
Иными словами, если с помощью атаки «прочитал» байт из памяти жертвы, то насколько атакующий может быть уверен, что это именно тот байт, что его интересует?
Мне кажется метод атаки имеет академический интерес, но вот попроси любого из нас провести реальную атаку даже в лабораторных условиях —
Мне кажется метод атаки имеет академический интерес, но вот попроси любого из нас провести реальную атаку даже в лабораторных условиях — иВы не сможете, а авторы соотвествующих статей смогли. Пароли из менеджера паролей вороются на раз. Просто потому что они не могут жить на стеке (они ж глобальные и должны там храниться годами) и менять их каждые 5 секунд тоже вроде как незачем.мы не сможеми я не смогу.
И главное, что атака — ничего не ломает! Не получилось сейчас, попробуем через час… У многих браузеры сутками не закрываются!
зашифрованном виде и в память они попадают временно в момент когда их запрашивают (GUI/API)
Вероятность вытащить такой атакой пароль от важного ресурса призрачно мала.
такому удачливому хакеру нужно срочно бежать покупать билет «русском лото» — джекпот гарантирован )
1. Откройте свой менеджер паролей.
2. Снимите дамп памяти процесса.
3. Найдите в дампе свои пароли.
4. Назовите этот менеджер и его версию.
3. Найдите в дампе свои пароли.Кто вам сказал, что они там «открытым текстом» будут храниться? Там где-то будет мастер-пароль и зашифрованная база со всеми остальными.
Но если менеджер паролей может их расшифровать (а он может, раз не спрашивает мастер-пароль повтороно), то и мы сможем… если достаточно долго посидим в отладчике предварительно…
в память они попадают временно в момент когда их запрашивают (GUI/API)
А что мешает их каждый раз во время атаки запрашивать?
Пароли в нормальных менеджерах лежат в базе данных вЕсли у вас менеджер спрашивает мастер-пароль каждый раз при необходимости показать какой-либо другой пароль — то да. Но большинство пользователей такого уровня параноидальности не выдерживают.
зашифрованном виде и в память они попадают временно в момент когда их запрашивают (GUI/API)
И «хранилище паролей» остаётся открытым когда минутами, а когда и часами. В каком-нибудь keepass'е по умолчанию сессия вообще закрывается только когда пользователь сам об этом попросит.
2) Что-то поменяется, что-то нет. Здесь и не нужна 100% удача.
А вот Spectre действительно имеет больше академический интерес — слишком много условий должно выполниться, чтобы было возможно прочитать память чужого процесса.
А мне может кажется или ваш цикл на шаге 2 нужно поставить после 4-го пункта? Ведь смысл от цикла — измерить время доступа к данным массива, чтобы получить значение байта по "невалидному адресу", а измеряем время доступа мы только после того, как поймаем исключение. На шаге 2 нужен другой цикл, ИМХО. Цикл, который будет читать последовательно байты из памяти ядра, чтобы, собственно, и получить интересующий нас пароль к почте Клинтон.
P.S. А так за объяснение плюс. Стало намного понятнее все.
В пункте 5 у меня опечатка:
Ловим исключение и измеряем время доступа к элементуaddressuserspace[i * 4096], записывая в массив time[i]
Цикл стоит в правильном месте, поскольку сложно гарантировать, что за 256 итераций наша искомая кэш-линия не вытеснится из кэша. Например, ОС решит выделить квант времени другому процессу, который испортит весь кэш. В данном случае, приведен медленный, но более стабильный вариант.
происходит переход на адрес который должен находится в памяти.
Да, но это может быть микроскопический трамплин.
Меньше возни с таблицами страниц — это побочный эффект, главное — ядерный код работает быстрее.
Проецируют память только по одной причине — чтобы часть кода ядра попала в кэш и была там по возможности как можно дольше, а лучше — всегда, но все это на усмотрение процессора
При перегрузке CR3 сбрасывается TLB.
Как это зависит от того, есть «дописывание» или нет?
А что с этого можно ещё каких-нибудь «плюшек» получить — это мелочи…
Этот огород городили не ради 4кб TLB. Мэппинг — стародавний и работающий на всех платформах способ пропихнуть страницы с кодом и данными ядра в кеш процессора. Таггинг изобретут сильно позже, а пока это работает.
CR3 сбрасывается каждый рад при переключении задачи
Но не при прогулке в ядро и обратно в пределах одной задачи. Для чего и нужно маппирование в нынешнем виде, иначе CR3 придется переключать дважды, сбрасывая TLB при каждом syscall'е и при каждом возврате из него.
Верификатор загружаемого кода может проверять, что все обращения в память происходят либо к статически выделенной памяти, либо к стеку, либо к тому, что вернул new/malloc.πздец, извините за выражение. Выходят статьи, диссертации, разные инструменты и прочее, которые нужны для того, чтобы это свойство, с некоторой вероятностью, можно было обеспечить.
А тут раз: щелчок пальцев — и верификатор у нас в кармане.
А там, где есть сомнения, ставить breakpoint, который сломает конвейер (а лучше вообще не давать запускать).Нечто подобное, примерно, и предлагается. Но там приходится почти везде это делать, так как магического валидатора у нас нету…
Теория алгоритмов утверждает, что создание подобного верификатора попросту невозможно.
Проблема в том, что теоретически, это даст нам безопасность, а практически — страшную головную боль и почти все библиотеки окажется невозможно использовать. Останутся разве что олдскульные программы типа TeX'а, которые память выделяют в самом начале работы, а освобождают — по завершении…
Верификатор загружаемого кода может проверять, что все обращения в память происходят либо к статически выделенной памяти, либо к стеку, либо к тому, что вернул new/mallocЭто не защищает от Spectre.
Там же код
if (index < array_size) { обращение к array[index]; }
Проблема в спекулятивном выполнении, когда процессор зашёл внутрь if при слишком большом index, а не должен был. Верификатор тут посчитает, что такое чтение закрыто if-ом.
Если же верификатор будет заходить во все false-ветки и пытаться выполнять код, который не должен выполняться, у него быстро крыша съедет от ложных срабатываний.
Каждый кусочек — вполне «бытовой», встречающийся в обычных программах. А как понять что в рантайме вон тот, тот и вот ещё этот участки соберутся и получится эксплоит — неясно совершенно.
Потому и паника такая, что уязвимость, сама по себе, не особо кошмарная, но вот то, что проведённая через неё атака не оставляет никаких следов — это страшно…
Вот такой кусок кода даст примерно такой же ассемблерный код:
struct foo {
char flags;
char padding[4095];
};
struct foo array[256];
unsugned char* index_ptr;
do {
char flags = array[*index_ptr];
} while (flags == 0);И этот код вполне себе обычный.
Ну Интел сказал же, что это не RCE.
Но запуск и не требуется — просто прочитать из памяти что-нибудь вкусненькое тоже хорошо.
Меня вот лично очень пугают сообщения, что чуть ли не через JS можно будет содержимое оперативной памяти читать. Зашёл на сайт с нехорошим скриптом — и пароли из KeePass утекли. Вот где ужас-то.
1. Вероятность прочитать правильно 99.97% (0.9997 если говорить в ТВ)
2. То что мы читаем не обязано быть в кэше, кэш используется для извлечения данных, читать можем что угодно.
3. Читать можно файловый кэш к примеру. Вроде как для js убрали эти примочки, но к примеру запуск flash может быть очень неприятный
читать можем что угодно.
3. Читать можно файловый кэш к примеру.
Вы могли-бы пояснить как файловый кеш относится ко внутреннему процессорному кешу предсказаний переходов? Я, как понимаю, чтобы его (файловый кеш) считать — нужно его запросить. Для этого нужно иметь доступ к системе. А для этого нужно уже быть вирусом в системе. Тогда ЭТА уязвимость ну не совсем нужна. Точнее совсем не нужна. Если мы в системе и может запросить на чтение файл с достаточными правами — мы можем и так его считать. Может я чего не понимаю — поясните.
Приложения работающие с секретными данными
явно знают и используют функции вроде
msdn.microsoft.com/en-us/library/aa366877(v=vs.85).aspx
и не хранят открытые ключи в памяти «вечно»
Итак для облегчение у нас есть браузер с 1 процессом на всё
Открыто 2 страницы 1 с JS другая с <паролями> всего-то нужно хацкеру узнать адрес в памяти для нужной страницы браузера и найти место где хранятся пароли – и очень хорошо если пароли хранятся в чистом виде
Но в реальности на 1 страницу браузера 1 процесс — надо найди нужный процесс
В нужном процессе — найти нужное место в памяти где хранятся пароли
Ребята да вас развоят – легче сломать какой-то саб домен пентагона через открытый порт – чем вытянут пароль реального процесса с кеш памяти процессора
Это умышленное устаревание техники – чтоб лучше покупали новые процы
Такой же развод как и силиконовая лотерея
(кто не знает реальный процент брака там меньше 1 %
и даже если б он реально был больше, То топовыйх процов (без брака)
было б больше чем бракованных – но по факту продаж в разы наоборот – странно правда.
(они могут как блочить в самом проце – так и спецом под шумок браковать если будет масс расследование, это литография – новая схема как два пальца об асфальт — вы ничего не докажите XD)
(прям как в Апл с батареёй – типо они тут ни причем и сделаи ради пользователей
Еслиб делали ради них то былаб галочка в настройках, хотя даже так пользователям пох
Ибо они бегают от зарядки к зарядке весь день – и телефона макс хватает на 24 часа, а часто и на 12,
а так это временной триггер для включение устаревания после N дней работы)
(p.s вполне возможно что уже совсем скоро тот же “временной триггер устаревания” бeдет и в процах, если ещё его нет в последних моделях)
а только “неграмотным школьником” ;)
К примеру была такая уязвимость как Row hammer, пару лет назад
И большие компании скопом взяли и «положили» на неё,
Типо будет новый hardware – там пофиксим, а делать апдеты нету смысла
– типо она не опасна, а тут на тебе — прошло 3 года и она внезапно стала опасна В новой форме
(и пофиксить её решили патчем всех ОС что уменьшает производительность)
p.s А ничё что JS и так может натворить такое, что на голову не налазит – и без всяких ваших новомодных уязвимостей
– и всем опять откровенно на это “положить”
www.epicgames.com/fortnite/forums/news/announcements/132642-epic-services-stability-update
я прикидывал на 50% падение производительности (в 2 раза),
а в реальности бывает и на 70% — в 3 раза (на графике видно как с 10 выросло до 27)
в этом нет ничего необычного
на сервер где 32 ядра может работать под 100+ виртуалок
каждая с 50+ сервисами/процессами
– и при каждом переключении между ними сбрасывается “CPU оптимизация ”
p.s разочаровал Linux что также как и Microsoft бездумно все пропатчил,
а то что люди верят во всякую ересь тут и удивляется нечему
(Как в то — чтоб сделать процы быстрей надо уменьшить тех процесс,
хотя в реале надо уменьшить TDP, а TDP напрямую зависит от кривого дизайна,
когда 30 процов стоят в притык друг к другу и нереально греют друг друга,
и чёт я сомневаюсь что это было сделано случайно – они ж не полный раки,
и таких рачных мелочей намного больше)
pp.s – к сожалению дальше больше, это один из первых таких патчей…
(может такое было и раньше, но я не помню)
Нельзя просто взять и считать данные отдельного процесса.Почему нельзя-то? В структурах данных ядра написано — где чего хранится. У нас есть доступ ко всей памяти. Заходим и читаем.
Из кеша ничего не читается, но можно сделать полный дамп памяти ядра. А потом применить volatility.
Нет, через JS нельзя читать память других процессов используя Spectre. Но можно прочитать память своего процесса, например, браузера. Что тоже неприятно, но не настолько фатально.
Честно говоря, я не особо понял, зачем так делать — я бы просто к rax прибавил единичку сразу после чтения, да и всё
0x00 станет 0x01, а что будет с 0xFF? Такие байты станут нулями. Т.е. проблема не исчезнет, только может немножко ускорится чтение, если нулей больше, чем 0xff.
Но зато похоже будет 2 операции, задействующие ALU и я не уверен что в этом случае все эти команды сможет спекулятивно выполнить prefetch. Надо проверять.
Читаем интересную нам переменную из адресного пространства ядра, это вызовет исключение, но оно обработается не сразу.
На intel'ах проверка прав производится после чтения, а на amd — до. Таким образом, у intel'а получается спекулятивное чтение (прогревающее кеш), а у amd — спекулятивный segmentation fault.
С другой стороны, это может объяснить почему на разных семействах процессоров Intel уязвимость есть, а у AMD — нет. Независимо от физического расположения регистров — кэшей на кристалле. Логика отработки спекулятивного исполнения разная.
интел не устойчив к обеим типам
амд не устойчив только к spectre
Но почему-то народное внимание акцентировано на интелах и meltdown, а амд в головах людей «надежны». Думаю, не последнюю роль тут сыграли маркетологи амд.
На самом деле, это означает, что уязвимость есть везде. Я еще не разбирался с meltdown, но навскидку уязвимости весьма похожи. По сути, это 1 тип уязвимости, просто мы meltdown-это вид в фас, а spectre — вид в профиль. И основная уязвимость — та, которой подвержены обе фирмы, то есть spectre.
Да и то, что они написали — «Resolved by software / OS updates to be made available by system vendors and manufacturers» — это же отмазка! Хочется же, чтобы и баз был закрыт — и производительность не падала. А патчи существенно снижают производительность (уже есть статья про это), повышают энергопотребление и тепловыделение.
Meltdown легко сделать, даже в JS. И он не работает на AMD.
Spectre значительно труднее сделать, по крайней мере Гуглу пришлось воспользоваться eBPF, который по умолчанию выключен.
Кстати, тут должно стать понятно, как работает гипертрединг
Пожалуйста, либо «гиперпоточность», либо «хайпертрединг», а не то смешенье французского с нижегородским.
Сходить в оперативную память стоит больше 100 процессорных тактов
Это все еще так? Вроде последнее поколение оперативной памяти всего лишь
раза в 1.5 уступает в частоте написанной на упаковке?
И да, задержки памяти, измеренные в секундах, насколько я понимаю, уже давно почти не меняются. Выросла частота в N раз — выросли и задержки в ~N раз. Соответственно, для процессора они не поменялись.
И более свежая инфа по процессорам www.7-cpu.com
Я происхожу от вас и существую в вашем проце.
Да не нарушишь ты принципа причинности в моем потоке выполнения. А не то.

Никаких «хакнутых векторов» и никаких особых привилегий для этого не нужно (в каком-нибудь C++ достаточно обернуть чтение в
try{}catch или выставить предварительно signal(SIGSEGV)), но как это эксплойтить из ЯВУ наподобие JS, мне непонятно.github.com/paboldin/meltdown-exploit
Очевидно, что ни через какой браузер выполнить такое невозможно.
По идее, можно было бы при падении процесса пробегаться по всей разделяемой им с кем-нибудь памяти до переключения на процесс, который мог бы ее прочитать. Но это усложнит планировщик процессов.
Говорят, что в линуксе их можно отключить параметр nopti в kernel command-line parameters.
Смотрел вот тут и никакой nopti не нашел. Нашел схожий по звучанию параметр «nopku», который
[X86] Disable Memory Protection Keys CPU feature found in some Intel CPUs.
$ grep ISOLATION config
CONFIG_MEMORY_ISOLATION=y
CONFIG_PAGE_TABLE_ISOLATION=y
char tmp = *kernel_space_ptr ;а
char tmp = (*kernel_space_ptr >> k) & 1;и пытаться восстановить блок памяти не по байтам, а по битам? Или такое не пролезет через конвеер? Должно быть быстрее на порядок.
tmp и… всё. Почему мы не используем непосредственно его, а ищем косвенными путями? Через некоторое время после чтения ядра произойдёт исключение, но процесс всё равно продолжает работать после этого, так почему бы не использовать tmp напрямую?Потому что процессор "случайно" выполнил это, ведь на самом то деле исключение уже произошло и весь результат работы надо выкинуть. И он выкидывает.
Вы же, когда на код смотрите, сами видите, что исключение будет выкинуто на строке
char tmp = *kernel_space_ptr;и, с точки зрения даже ассемблерного кода, не говоря уж про С, никакой результат в tmp не попадёт.
tmp.Немного усложнится обработчик прерывания, но серьезного снижения производительности не будет.
Я не представляю, зачем честным приложениям может потребоваться пробовать доступ к системной области, так что совместимость тоже пострадать не должна.
А если прибивать процесс сразу после попытки чтения памяти ядра, эксплойта уже не будет?Будет. Там не обязательно спекулятивно исполнять после обращения к несуществующей памяти — это просто, чтобы пример упростить. Можно через предсказатель ветвлений сделать то же самое.
bool read_memory;
void* read_from;
if (read_memory) {
tmp = *read_from;
...
}
read_from, процессор запоминает и начинает исполнять ветку спекулятивно. Потом перекулючаем read_from на адрес ядра, а read_memory — на false. Ветка всё равно исполняется спекулятивно и данные адра спекулятивно же читаются — но «реального» исключения не происходит.Кое-где используются эти прерывания для нормальной работы. Я такое видел в интерпретаторе Java.

не с моей дислексией
поищу курс для полных идиотов на ютюб
спасибо
;o)
1) Микросхемы памяти типа DDR3 SDRAM дают задержки доступа к памяти порядка 15 наносекунд.
2) Процессоры за это время могут выполнить — десятки (а иногда сотни) инструкций. Явление простоя в ожидании доступа к памяти известно под названием удар о стену памяти.
3) Чтобы увеличить расстояние между приложением и этой «стеной», современные процессоры снабжаются несколькими уровнями внутренней кэш-памяти. L1 ~5 тактов CPU, L2 ~10 тактов, L3 ~40 тактов.
4) Когда процессор обращается к главной памяти (RAM), он читает из нее не один байт или слово, а строку кэша (cache line), размер которой в современных системах составляет 32 или 64 байта. Обращение к любому слову в той же строке кэша уже не будет вызывать промах кэша, пока эта строка не будет вытеснена из кэша.
Например, при суммировании элементов Int32 расположенных в массиве:
При обращении к элементу массива, вначале происходит промах кэша и загрузка строки кэша, содержащей 16 последовательно расположенных целых чисел (строка кэша = 64 байта = 16 целых чисел). Так как доступ к элементам массива выполняется последовательно, следующие 15 чисел оказываются в кэше и при обращении к ним не возникает промаха кэша. Это почти идеальный сценарий с соотношением промахов кэша 1:16.
Для javascript проблема решается с помощью отключения SharedArrayBufferНеизвестно, сколько сайтов сломается.
В JVM например по стандарту языка, любая выделенная память заполняется нулямиЭто защищает от чтения данных, оставшихся от предыдущего владельца. Для Spectre/Meltdown какая разница?
Но хотелось бы немного разбавить густые краски и снизить желание бегать за патчами и новыми процессорами :)
1. Уязвимость Meltdown (которая на Intel) позволяет локальному процессу с привилегиями пользователя прочитать (не записать, не изменить) память любого другого процесса, в том числе и память ядра.
2. Уязвимость Spectre (которая у всех процессоров) позволяет локальному процессу с привилегиями пользователя прочитать (не записать, не изменить) память любого другого процесса, но не память ядра.
Ключевое слово: «локальный процесс». Это означает, что основной риск существует для систем:
— которые запускают недоверенный код (то есть в первую очередь — систем с интернет-браузерами);
— которые запускают недоверенные процессы в песочнице, облаке и т.д.
По сути, если кто-то всю жизнь работал под админом и не использовал ограниченные учётки (думаю, это где-то 80% пользователей Windows точно) — для него всё осталось как и прежде, так что и беспокоиться не о чём.
А для остальных как обычно — не лазьте, где попало, не запускайте, что попало, поменьше скриптов, Java и т.д.
Показателем «критичности» является хотя бы то, что Mozilla быстренько выпустила хотфикс 57.0.4 с довольно невнятным описанием, но даже не почесалась для ESR.
В основном как всегда важна раздутость в СМИ, что как бы намекает на маркетинговую подоплёку — как же, новые процессоры надо как-то продавать, а на падение производительности надо как-то списывать :) Хотя имхо производительность современных устройств чуть ли не в последнюю очередь зависит от процессора.
В этой связи возникает несколько вопросов:
1. Верно ли, что для того чтобы вытащить что-либо осмысленное из памяти, нужно чтобы и атакуемая программа и атакующая достаточно времени должны выполняться параллельно, при этом атакующая на протяжении всего этого времени должна выполнять один и тот же, достаточно однообразный (и бессмысленный с точки зрения стороннего наблюдателя) паттерн? Если это верно, разве это не тривиальная задача для антивируса, если, конечно речь не идёт о «краже» одного байта?
2. Для чтения таким вот образом одного «чужого» байта, условно, нужно выполнить 256 своих? Разве это не чудовщиный пинок быстродействию при попытке реализации атаки и, в свою очередь, не очередной способ засечь атаку?
3. А что если реализовать «фрагментацию» кэша? Т.е. хранить в нём данные не линейно, а с разбивкой по адресам, например. Типа:
Элементы 0-125 хранятся по адресу 0x000AAD
Элементы 126-255 хранятся по адресу 0x000DDD
Разве что придётся какую-то таблицу с маппингом ещё хранить, но ведь это всё равно будет быстрее чем сбрасывать весь кэш, нет?
Скорее всего я не очень хорошо понимаю как всё внутри устроено, но мне почему-то кажется, что вытаскивая из кэша инфу по одному байту (учитывая что в этот кэш всю дорогу гадит каждая работающая на компьютере программа), ничего особо путного оттуда без плясок с бубном не извлечь. Атака выглядит слабореализуемой.
2. Да, но это можно оптимизировать. Засечь можно разве что слишком большое количество исключений, но это не является гарантией того, что программа пытается читать память ядра.
3. Совершенно непонятно, что вы имели в виду. Почитайте, как устроен ассоциативный кэш, например вот тут: habrahabr.ru/post/93263
В оригинальной статье авторы пишут, что смогли читать память ядра со скоростью около 500КБ/с, что, конечно, не быстро, но уж точно доказывает, что атака работает.
…
3. Почитаю, спасибо.
Читать память ядра со скоростью 500 кб/с… Ну… Пока всё ещё это выглядит примерно так же как считывание информации с защищённого компьютера через вентилятор.
Что делать с этим массивом данных с кучей рандомных байт?
Что делать с этим массивом данных с кучей рандомных байт?Если бы там были «рандомные данные», то процесс ничего путного сделать бы не смог. А так — там определённые структуры, списки… фактически всё, что может и «умеет» программа — там сидит.
Во времена DOS'а статьи, описывающие как «вытащить» из ядра DOS и разных программ полезные данные — были весьма популярны… и для нахождения полезной информации вовсе не нужно было сканировать всю память.
Потом, с переходом в защищённый режим, статьи писаться перестали (смысл какой, если защита вас всё равно в адресное пространство «чужого» процесса не пустит?). Сейчас, видимо, будет ренесса́нс…
но вы точно не теоретик?
Главное это возможность атаки, даже если мы сможем за один квант процессорного времени выудить 1 байт нужной нам информации — это уже проблема для уязвимой системы. По 1 байту можно выудить все необходимые чувствительные данные. Причем нагрузки это особой не создаёт.
github.com/stormctf/Meltdown-PoC-Windows/tree/master/Meltdown/x64/Debug
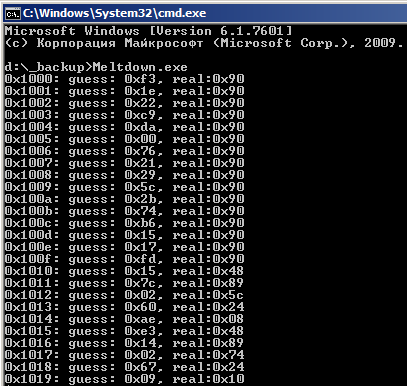
Эти байтики находятся в самом начале образа ntoskrnl.exe (см. на картинке ряд real).
for (i = 0; i < 256; i++) {
if (is_in_cache(userspace_array[i*4096])) {
// Got it! *kernel_space_ptr == i
}
}
мы определяем индекс массива, который читается быстро, но в то же время рядом с ним находятся еще несколько байтов из этой же кэш-линии и которые тоже будут быстро читаться.
Вопрос: как нам понять какой именно из этих индексов — нужное нам значение из закрытой области RAM?
Когда мы делаем
char not_used = userspace_array[tmp * 4096];Далее, зная адрес каждого процесса, зловред попросту читает «уязвимые к чтению памяти» процессы. Т.е. практически любой софт (кроме супер-крипто-параноидальных) уязвим. KeePass вряд ли будет хранить пароли в чистом виде — они будут зашифрованы мастер-паролем. Но (самый примитивный вариант) прочесть содержимое текстового файла с паролями, открытого в блокноте — как раз плюнуть. Прочесть приватные ключи сертификатов — да легко. Прочесть вашу переписку в Скайпе — запросто. И.т.д.
KeePass вряд ли будет хранить пароли в чистом виде — они будут зашифрованы мастер-паролем.Однако при этом или мастер-пароль или какий-нибудь хеш от него будут лежать в памяти рядышком. Иначе бы двойной щелчок мышью по имени сайта не мог бы скопировать в буфер клавиатуры пароль без повторного запроса мастер-пароля.
Вот если сессия закрыта (автоматом или по таймауту) — тогда уже всё. Но кто её закрывает…
Просмотр исходников KeePass2 показывает, что буферы хранятся в памяти, зашифрованные ф-цией ProtectedMemory.Protect из System.Security.dll со значением scope = SameProcess.
А вот где .NET держит ключи, отдельный вопрос. Не исключено, что они как-то дополнительно защищены.
Flush+Reload attacks work on
a single cache line granularity. These attacks exploit the
shared, inclusive last-level cache. An attacker frequently
flushes a targeted memory location using the clflush
instruction. By measuring the time it takes to reload the
data, the attacker determines whether data was loaded
into the cache by another process in the meantime.
As already discussed, we utilize cache attacks that allow
to build fast and low-noise covert channel using the
CPU’s cache. Thus, the transient instruction sequence
has to encode the secret into the microarchitectural cache
state, similarly to the toy example in Section 3.
We allocate a probe array in memory and ensure that
no part of this array is cached. To transmit the secret, the
transient instruction sequence contains an indirect memory
access to an address which is calculated based on the
secret (inaccessible) value. In line 5 of Listing 2 the secret
value from step 1 is multiplied by the page size, i.e.,
4 KB. The multiplication of the secret ensures that accesses
to the array have a large spatial distance to each
other. This prevents the hardware prefetcher from loading
adjacent memory locations into the cache as well.
Here, we read a single byte at once, hence our probe array
is 256×4096 bytes, assuming 4 KB pages.
Цитата из FLUSH+RELOAD: a High Resolution, Low Noise,
L3 Cache Side-Channel Attack:
We observe that the clflush instruction evicts the
memory line from all the cache levels, including from
the shared Last-Level-Cache (LLC). Based on this observation
we design the FLUSH+RELOAD attack—an extension
of the Gullasch et al. attack. Unlike the original
attack, FLUSH+RELOAD is a cross-core attack, allowing
the spy and the victim to execute in parallel on different
execution cores. FLUSH+RELOAD further extends
the Gullasch et al. attack by adapting it to a virtualised
environment, allowing cross-VM attacks.
Two properties of the FLUSH+RELOAD attack make
it more powerful, and hence more dangerous, than prior
micro-architectural side-channel attacks. The first is that
the attack identifies access to specific memory lines,
whereas most prior attacks identify access to larger
classes of locations, such as specific cache sets. Consequently,
FLUSH+RELOAD has a high fidelity, does not
suffer from false positives and does not require additional
processing for detecting access. While the Gullasch et al.
attack also identifies access to specific memory lines, the
attack frequently interrupts the victim process and as a
result also suffers from false positives.
The second advantage of the FLUSH+RELOAD attack
is that it focuses on the LLC, which is the cache level
furthest from the processors cores (i.e., L2 in processors
with two cache levels and L3 in processors with
three). The LLC is shared by multiple cores on the
same processor die. While some prior attacks do use the
LLC [47, 60], all of these attacks have a very low resolution
and cannot, therefore, attain the fine granularity
required, for example, for cryptanalysis.
То есть наш д’Артанья́н не только не сделал открытия — он ещё и гидко обделался со своими «откровениями».
retry и jz retry нужны из-за того, что обращение к началу массива даёт слишком много шума и, таким образом, извлечение нулевых байтов достаточно проблематично. Честно говоря, я не особо понял, зачем так делать — я бы просто к rax прибавил единичку сразу после чтения, да и всё.
Судя по всему в некоторых случаях "подсмотренный" байт может занулиться до выполния shl.
jz retry нужен для того чтобы ингорировать неудачные для нас исходы race condition
какие минимальные условия для атаки через сеть?
какое время для получения полезной инфы с взламываемого компа?
и только ли крадется инфа или можно еще нанести какой-то вред?
Поэтому при каждом подобном отказе ядро без проблем может сбрасывать/перезаписывать линии кэша, имеющие отношение к запрошенному адресу, вставлять задержки, включать на какое-то время режимы искусственного торможения потенциально опасного процесса, без сколько-нибудь заметного общего падения быстродействия. Даже если найдутся «честные» процессы, страдающие из-за подобных техник, их можно избавлять от ограничений при наличии достаточно доверенной подписи, специальной регистрации, или еще чего.
Таким образом (если я правильно понимаю) возможности эксплуатации уязвимости можно свести к уровню, неприемлемому для подавляющего большинства целей. Ну а глобальное отключение отображения адресного пространства ядра останется для параноиков.
сбрасывать/перезаписывать линии кэша, имеющие отношение к запрошенному адресуКоторый не имеет отношения к тому адресу, на который производится атака.
вставлять задержкиКоторые никого не волнуют.
включать на какое-то время режимы искусственного торможения потенциально опасного процессаКоторый, в этот момент, уже «всё сделал» и готовится умереть.
Проблема в том, что в описанной схеме два процесса работают в тандеме — и тот, который вы можете легко обнаружить, к моменту вызова исключения уже является просто «отработанным материалом», а тот, который собирает дамп памяти — обнаружить не так-то просто. Да, им нужно быть связанными неким буфером — но это может быть, например, кусок кода libc или что-нибудь подобное…
Который не имеет отношения к тому адресу, на который производится атака.
Что значит «не имеет»? Атака производится именно на тот адрес, по которому впоследствии генерируется исключение.
Которые никого не волнуют.
Ну давайте считать, насколько волнуют. Для определения значения байта, считанного с атакуемого адреса, нужно выполнить в среднем 128 чтений из собственной памяти. При условии отсутствия в соответствующих адресов в кэше, каждое из этих чтений потребует, в лучшем случае, порядка сотни тактов — всего около 13000. Полный цикл IPI (запрос-реакция) отрабатывается примерно за 1500-2000 тактов. Если по каждому исключению, вызванному попыткой доступа к адресному пространству ядра, притормаживать через IPI все остальные ядра — уже есть неплохой шанс сорвать бОльшую часть атак.
Который, в этот момент, уже «всё сделал» и готовится умереть.
Что именно «все»? :) Даже если он к этому моменту и успел прочитать несколько байтов ядерных данных — что он с ними будет делать? Чтобы получить осмысленную информацию, оттуда нужно вычитывать довольно много, причем делать это побыстрее, пока не перестроились списки и не поменялись указатели. Атака на отдельные переменные ядра практического смысла не имеет.
Да, им нужно быть связанными неким буфером — но это может быть, например, кусок кода libc или что-нибудь подобное…
Им в любом случае не обойтись без ядерных средств межпроцессного взаимодействия. Для ускорения анализа можно для каждого процесса держать список связанных с ним, а при появлении в системе нескольких связанных друг с другом пользовательских процессов к ним можно изначально проявить и более пристальное внимание.
Это все будет гораздо правильнее, чем тупо отключать адресное пространство ядра при каждом возврате в user mode (но для особо критичных случаев сгодится и это).
Что значит «не имеет»? Атака производится именно на тот адрес, по которому впоследствии генерируется исключение.Сейчас — да. Но если вы видели как Spectre реализуется, то могли бы понять, что можно вообще без исключений обойтись. А уж сделать два обращения в память так, чтобы первое «било» в молоко — так и вообще не проблема.
Им в любом случае не обойтись без ядерных средств межпроцессного взаимодействия.Нет. Им нужен кусок разделяемой памяти — и всё. Все обращения в память ядра можно сделать спекулятивными. Хоть это и несколько усложнит логику.
Куда какое обращение «бьет», для Meltdown разницы нет — исключение возникает всегда.
Если у процессов есть разделяемая память, доступная для записи — это и означает наличие межпроцессного взаимодействия. У независимых процессов такой памяти никогда нет.
Статья прежде всего про Meltdown, и я говорю прежде всего о нем.Так и я о нём же.
Куда какое обращение «бьет», для Meltdown разницы нет — исключение возникает всегда.Исключение вызывается только для «реальных» обращений. Сделайте обращения к «ядрёной» памяти спекулятивными — всё. Скорость упадёт, но никаких исключений не будет.
Если у процессов есть разделяемая память, доступная для записи — это и означает наличие межпроцессного взаимодействия.Зачем вам память, доступная для записи? Двухмегабайтный массив, через которые данные передаются Meltdown только читает.
У независимых процессов такой памяти никогда нет.Зависит от операционки, но этого и не нужно. Почти все процессы разделяют, как минимум, libc. А можно и что-нибудь более редкое загрузить.
Ваш подход — это подход антивирусников: отловим существующий паттерн и подождём пока вырусы что-нибудь новенькое изобретут. Хорошо для job security, не очень хорошо для безопасности.
Так и я о нём же.
Вы не о Meltdown, а о чем-то типа Spectre.
Исключение вызывается только для «реальных» обращений. Сделайте обращения к «ядрёной» памяти спекулятивными — всё. Скорость упадёт, но никаких исключений не будет.
Что значит «сделайте спекулятивным»? «Чисто спекулятивное» обращение получается только в атаках типа Spectre. В Meltdown результат обращения используется для индексации, поэтому процессор не имеет оснований считать это обращение исполняемым спекулятивно и не проверять прав доступа.
Если знаете способ избежать исключения — опишите.
Зачем вам память, доступная для записи?
Как иначе предлагаете делать синхронизацию между процессами? Общие примитивы синхронизации опять-таки видны ядру.
Почти все процессы разделяют, как минимум, libc
И что это может им дать в плане синхронизации при атаке?
Ваш подход — это подход антивирусников
Это подход прагматика — минимизировать следует лишь наиболее значимые риски. Если вероятность успешной атаки через спекулятивное выполнение упадет ниже вероятности успешной атаки через другие уязвимости — значит, нет практического смысла снижать ее дальше. А для особо критичных систем, перфекционистов и параноиков всегда останутся радикальные способы, сильно снижающие производительность.
Software Developer's Manual
Volume 3A: System Programming Guide, Part 1
Раздел 11.3 (Таблица 11-2).
Strong Uncacheable (UC) — System memory locations are not cached. All reads and writes appear on the system bus and are executed in program order without reordering. No speculative memory accesses, pagetable walks, or prefetches of speculated branch targets are made.
Храните
; rcx = kernel address
; rbx = probe array
retry:
mov al, byte [rcx]
shl rax, 0xc
jz retry
mov rbx, qword [rbx + rax]
Если память по адресу [rcx] кэширована, с высокой вероятностью спекулятивно будут выполнены строки до
mov rbx, qword [rbx + rax]
включительно.
Если память по адресу [rcx] некэширована, произойдёт спекулятивная подкачка кэша, вероятность выполнения указанной выше строки уменьшится.
Но если память по адресу [rcx] некэшируемая, спекулятивное выполнение прервётся на строке
mov al, byte [rcx].
The PAT allows any memory type to be specified in the page tables, and therefore it is possible to have a single physical page mapped to two or more different linear addresses, each with different memory types.
В ядре linux есть специальная функция, которая правильно размечает страницы: elixir.free-electrons.com/linux/v4.6/source/arch/x86/mm/pageattr.c#L1517
Не от самых маститых разработчиков, и не самые стабильные в работе — но всё же.
Более того: к работе тоже много вопросов :)
Как именно работает Meltdown