
Сравнение программы RAISR с другими передовыми методами повышения разрешения изображений. Больше примеров см. в сопроводительных материалах к научной статье
Повышение разрешения изображений, то есть создание фото высокого разрешения на основе одного фото низкого разрешения — очень хорошо изученная научная проблема. Она важна для многих приложений: зуммирование фото и текста, проекция видео на большой экран и т.д. Даже в фильмах детективы иногда умудряются рассмотреть номер автомобиля на кадре с камеры наблюдения, «приблизив» фотографию до предела. И не только номер автомобиля. Тут всё ограничено фантазией и совестью режиссёра и сценариста. Они могут приблизить фотографию ещё больше — и разглядеть отражение преступника в зеркале заднего вида или даже в отполированной металлической головке болта, которым крепится номерной знак. Зрителям такое нравится.
На практике возможности подобных программ гораздо скромнее. Например, 29 октября 2016 года на GitHub выложили программу Neural Enhance, которая повышает разрешение фотографий с помощью нейросети. Программа сразу вошла в список самых популярных репозиториев за неделю.

Пример работы Neural Enhance

Ещё один пример работы программы Neural Enhance, которая опубликована в открытом доступе на GitHub
Сотрудники Google Research тоже работают в этом направлении — в официальном блоге компании вчера рассказали о методе повышения разрешения, который назвали RAISR (Rapid and Accurate Image Super-Resolution).
Исторически для интерполяции изображений применялись простенькие интерполяторы, которые находят промежуточные значения новых пикселей по известному набору значений пикселей исходного изображения. Там применялись разные методы для вычисления средних значений: интерполяция методом ближайшего соседа, биленейная интерполяция, кубический метод, бикубический метод и т.д. Всё это довольно простые математические формулы. Они широко использовались в разных приложениях в силу своей простоты и неприхотливости. Они совершенно не адаптируются к содержанию изображения, что зачастую приводит к появлению неприятных артефактов — слишком размытых фрагментов, характерных искажений алиасинга.
В последние десятилетия разработаны гораздо более продвинутые программы и методы интерполяции, которые явно учитывают характеристики исходного изображения. Они способны использовать и масштабировать фрагменты исходного изображения, заполнять разреженности, применять гауссовы смеси. Новые методы позволили значительно улучшить качество интерполяции (цифровой реставрации оригиналов) за счёт увеличения сложности вычислений.
Сотрудники Google использовали метод машинного обучения на внешних образцах. Этот метод получил большую популярность в последние годы и описан во многих научных работах. Основной принцип заключается в том, чтобы «предсказывать» содержание изображения в высоком разрешении по его уменьшенной копии. Для такого обучения используется стандартный метод обучения по образцам.
В ходе обучения RAISR применялась база одновременно сгенерированых пар изображений в высоком и низком качестве. Использовались пары маленьких фрагментов изображения для стандартной 2х интерполяции, то есть фрагменты 3×3 и 6×6 пикселей. Алгоритм обучения и работы RAISR показан на схеме.
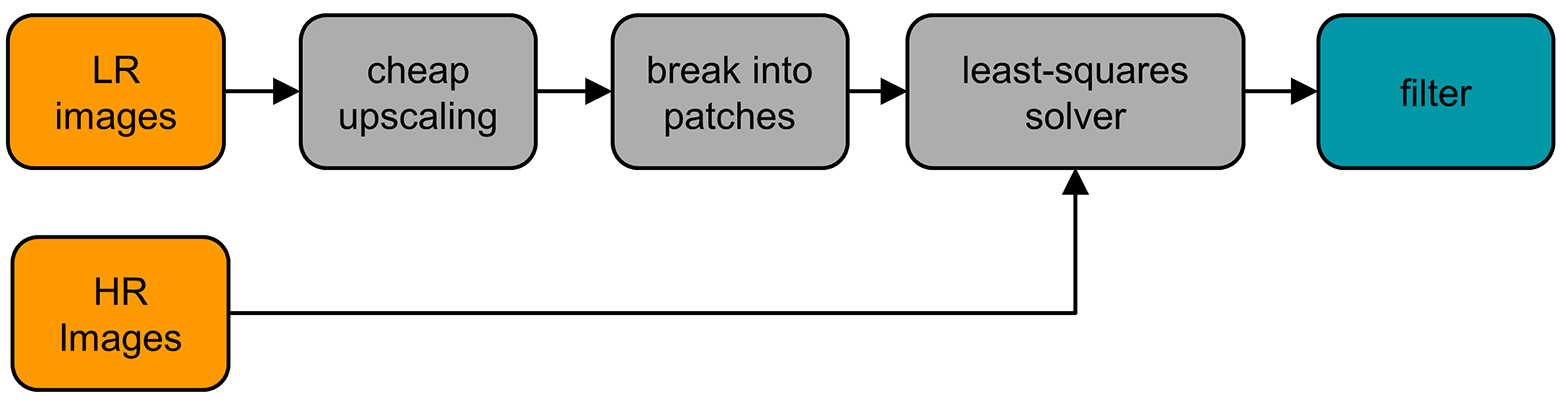

На следующей иллюстрации указаны четыре глобальных фильтра, применение которых допускалось на этапе обучения. Соответственно, программы обучалась применять их наиболее эффективно, в зависимости от содержания этого конкретного фрагмента из нескольких пикселей.

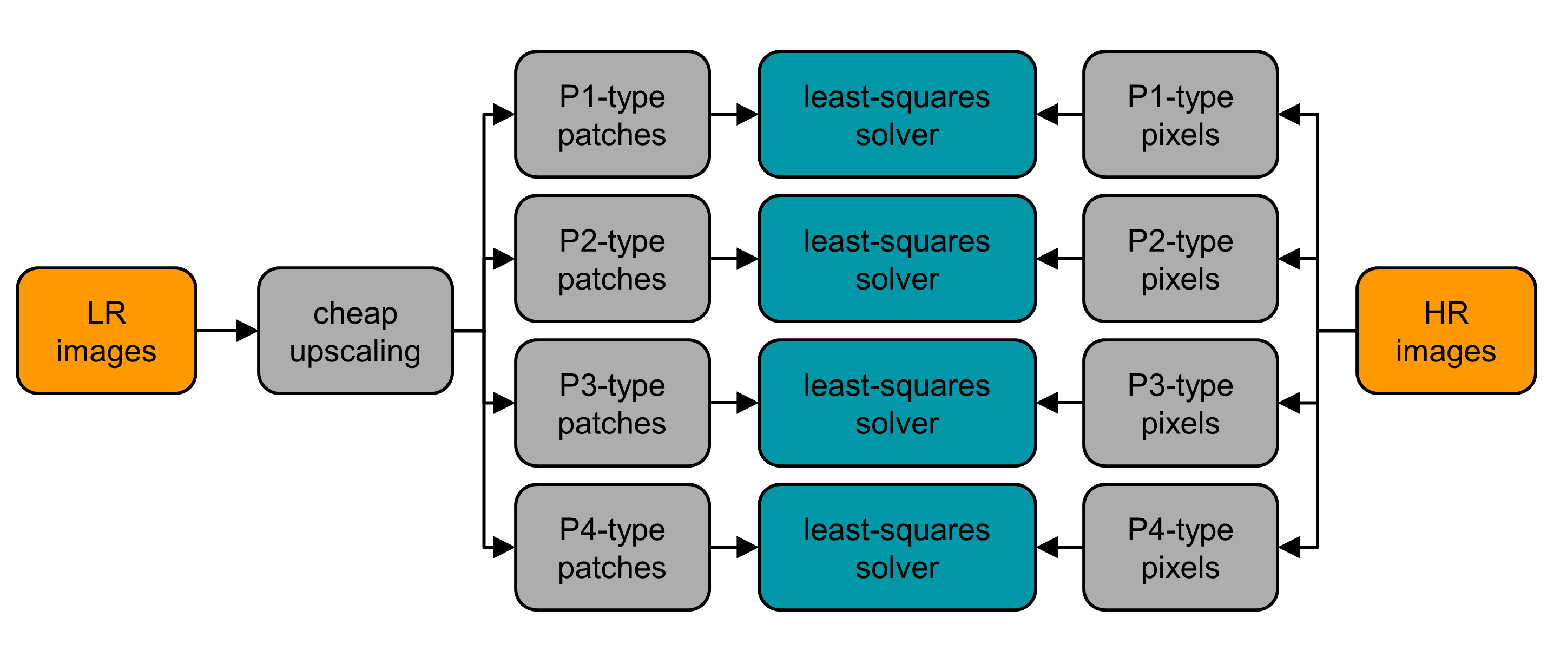
Каждый тип фильтра действует для своего типа пикселей: от Р1 до Р4, в соответствии с типами пикселей, которые используются алгоритмом билинейной интерполяции.

В чём-то метод машинного обучения RAISR похож на обучение нейросетей. Но фактически он представляет собой адаптацию различных фильтров стандартной интерполяции для каждого отдельного маленького фрагмента исходного изображения. То есть это та же старая «линейная интерполяции», но как бы на стероидах — без присущих ей артефактов и с адаптацией к содержанию изображения.
Сравнительное тестирование показало, что такой алгоритм во многих случаях работает даже лучше, чем современные методы продвинутой интерполяции, основанные на нейросетях (SRCNN на иллюстрациях).

К тому же, такой метод на основе хэширования гораздо менее ресурсоёмкий и более приемлем на практике, чем обучение и использование нейросети. Разница в производительности настолько большая (10−100 раз), что эту программу можно спокойно запускать даже на обычных мобильных устройствах, и она будет работать в реальном времени. Ничто не мешает внедрить этот фильтр в современные приложения интерполяции изображений на смартфонах, в том числе в приложение камеры на Android, которое выполняет интерполяцию во время цифрового зуммирования. Вполне возможно, что Google именно это собирается сделать в первую очередь. По крайней мере, это пример наиболее массового повсеместного применения интерполяции на миллионах устройств.

Слева: оригинал низкого разрешения. По центру: результат работы стандартного бикубического интерполятора. Справа: результат работы RAISR
Фотографии станут лучше сразу у всех пользователей Android.
Кстати, ещё одно интересное и важное преимущество RAISR — в процессе обучения эту программу можно обучить устранять характерные артефакты сжатия, в том числе JPEG. Например, на мобильном устройстве фотографии могут храниться в сжатом виде с артефактами, а на экране отображаться без артефактов. Или алгоритм можно применить на фотохостинге Google для автоматического улучшения фотографий пользователей, с устранением артефактов JPEG, которые присутствуют практически повсеместно.

Слева: оригинал низкого разрешения с характерными для JPEG артефактами алиасинга. Справа — выдача RAISR
Научная статья сотрудников Google Research скоро будет опубликована в журнале IEEE Transactions on Computational Imaging. (Примечание: ведущий автор научной работы был стажёром Google Research во время подготовки статьи, но теперь работает в израильском исследовательском технологическом институте Technion).
