Автор статьи — Алексей Маланов, эксперт отдела развития антивирусных технологий «Лаборатории Касперского»
Искусственный интеллект врывается в нашу жизнь. В будущем, наверное, все будет классно, но пока возникают кое-какие вопросы, и все чаще эти вопросы затрагивают аспекты морали и этики. Можно ли издеваться над мыслящим ИИ? Когда он будет изобретен? Что мешает нам уже сейчас написать законы робототехники, вложив в них мораль? Какие сюрпризы преподносит нам машинное обучение уже сейчас? Можно ли обмануть машинное обучение, и насколько это сложно?
Есть две разных вещи: Сильный и Слабый ИИ.
Сильный ИИ (true, general, настоящий) — это гипотетическая машина, способная мыслить и осознавать себя, решать не только узкоспециализированные задачи, но и еще и учиться чему-то новому.
Слабый ИИ (narrow, поверхностный) — это уже существующие программы для решения вполне определенных задач, таких как распознавание изображений, автовождение, игра в Го и т. п. Чтобы не путаться и никого не вводить в заблуждение, мы предпочитаем называть Слабый ИИ «машинным обучением» (machine learning).
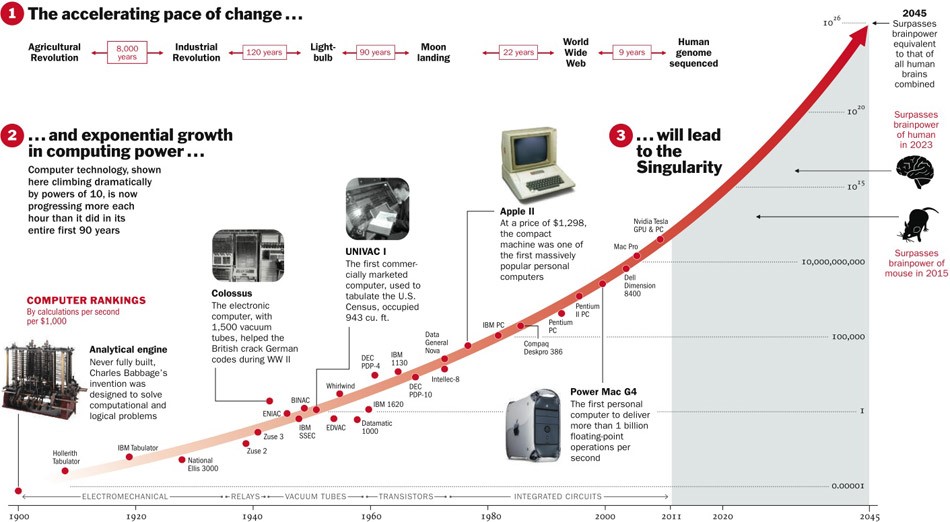
Про Сильный ИИ еще неизвестно, будет ли он вообще когда-нибудь изобретен. С одной стороны, до сих пор технологии развивались с ускорением, и если так пойдет и дальше, то осталось лет пять.
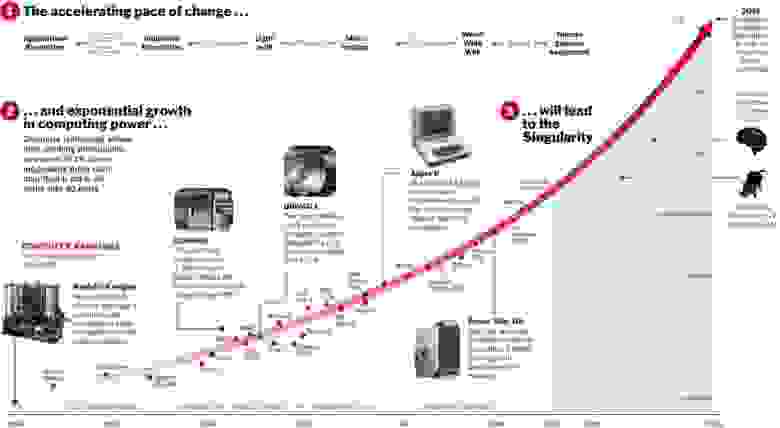
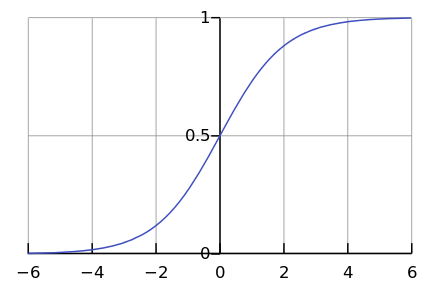
С другой стороны, мало какие процессы в природе в действительности протекают по экспоненте. Гораздо чаще все-таки мы видим логистическую кривую.

Пока мы где-то слева на графике, нам кажется, что это экспонента. Например, еще недавно население Земли росло с таким ускорением. Но в какой-то момент происходит «насыщение», и рост замедляется.
Когда экспертов опрашивают, выясняется, что в среднем ждать еще лет 45.
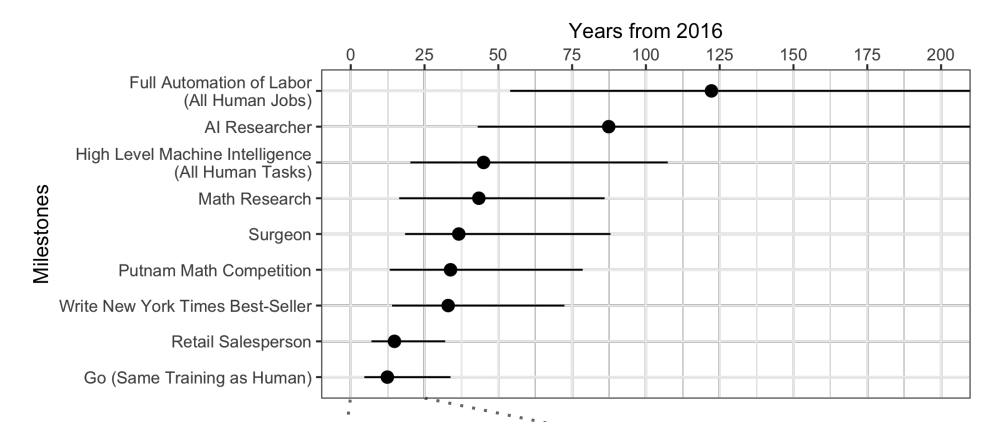
Что любопытно, североамериканские ученые считают, что ИИ превзойдет человека через 74 года, а азиатские — что всего через 30. Возможно в Азии они что-то такое знают…
Эти же ученые предсказывали, что машина будет переводить лучше человека к 2024 году, писать школьные сочинения — к 2026-му, водить грузовики — к 2027-му, играть в Го — тоже к 2027-му. С Го уже промашка вышла, ведь этот момент наступил в 2017-м, всего через 2 года после прогноза.
Ну, а вообще, прогнозы на 40+ лет вперед — дело неблагодарное. Это означает «когда-нибудь». Например, рентабельную энергию термоядерного синтеза тоже прогнозируют через 40 лет. Такой же прогноз давали и 50 лет назад, когда ее только начали изучать.

Хоть Сильный ИИ ждать долго, но мы точно знаем, что этических проблем будет хватать. Первый класс проблем — мы можем обидеть ИИ. Например:
Сейчас никто не возмутится, если вы обидите своего голосового помощника, но если вы будете плохо обращаться с собакой, вас осудят. И это не потому, что она из плоти и крови, а потому, что она чувствует и переживает плохое отношение, как это будет и с Сильным ИИ.
Второй класс этических проблем — ИИ может обидеть нас. Сотни таких примеров можно найти в фильмах и книгах. Как объяснить ИИ, чего же мы от него хотим? Люди для ИИ — как муравьи для рабочих, строящих плотину: ради великой цели можно и раздавить парочку.
Научная фантастика играет с нами злую шутку. Мы привыкли думать, что Скайнет и Терминаторов пока нет, и будут они нескоро, а пока можно расслабиться. ИИ в фильмах часто вредоносный, и мы надеемся, что в жизни такого не будет: ведь нас же предупредили, и мы не такие глупые, как герои фильмов. При этом в мыслях о будущем мы забываем хорошо подумать о настоящем.
Машинное обучение позволяет решать практическую задачу без явного программирования, а путем обучения по прецедентам. Подробнее вы можете почитать в статье «Простыми словами: как работает машинное обучение».
Так как мы учим машину решать конкретную задачу, то полученная математическая модель (так называется алгоритм) не может внезапно захотеть поработить/спасти человечество. Нормально делай — нормально будет. Что же может пойти не так?

Во-первых, сама решаемая задача может быть недостаточно этичной. Например, если мы при помощи машинного обучения учим дронов убивать людей.

https://www.youtube.com/watch?v=TlO2gcs1YvM
Как раз недавно по этому поводу разгорелся небольшой скандал. Компания Google разрабатывает программное обеспечение, используемое для пилотного военного проекта Project Maven по управлению дронами. Предположительно, в будущем это может привести к созданию полностью автономного оружия.

Источник
 Так вот, минимум 12 сотрудников Google уволились в знак протеста, еще 4000 подписали петицию с просьбой отказаться от контракта с военными. Более 1000 видных ученых в области ИИ, этики и информационных технологий написали открытое письмо с просьбой к Google прекратить работы над проектом и поддержать международный договор по запрету автономного оружия.
Так вот, минимум 12 сотрудников Google уволились в знак протеста, еще 4000 подписали петицию с просьбой отказаться от контракта с военными. Более 1000 видных ученых в области ИИ, этики и информационных технологий написали открытое письмо с просьбой к Google прекратить работы над проектом и поддержать международный договор по запрету автономного оружия.
Но даже если авторы алгоритма машинного обучения и не хотят убивать людей и приносить вред, они, тем не менее, часто все-таки хотят извлечь выгоду. Иными словами, не все алгоритмы работают на благо общества, очень многие работают на благо создателей. Это часто можно наблюдать в области медицины — важнее не вылечить, а порекомендовать побольше лечения.Вообще, если машинное обучение советует что-то платное — с большой вероятностью алгоритм «жадный».
Ну, а еще иногда и само общество не заинтересовано, чтобы полученный алгоритм был образцом морали. Например, есть компромисс между скоростью движения транспорта и смертностью на дорогах. Мы могли бы сильно снизить смертность, если бы ограничили скорость движения до 20 км/ч, но тогда жизнь в больших городах была бы затруднительна.
Представьте, мы просим алгоритм сверстать бюджет страны с целью «максимизировать ВВП / производительность труда / продолжительность жизни». В постановке этой задачи нет этических ограничений и целей. Зачем выделять деньги на детские дома / хосписы / защиту окружающей среды, ведь это не увеличит ВВП (по крайней мере, прямо)? И хорошо, если мы только бюджет поручаем алгоритму, а то ведь в более широкой постановке задачи выйдет, что неработоспособное население «выгоднее» сразу убить, чтобы повысить производительность труда.
Выходит, что этические вопросы должны быть среди целей системы изначально.
С этикой одна проблема — ее сложно формализовать. В разных странах разная этика. Она меняется со временем. Например, по таким вопросам, как права ЛГБТ и межрасовые/межкастовые браки, мнение может существенно измениться за десятилетия. Этика может зависеть от политического климата.

Например, в Китае контроль за перемещением граждан при помощи камер наружного наблюдения и распознавания лиц считается нормой. В других странах отношение к этому вопросу может быть иным и зависеть от обстановки.
Представьте систему на базе машинного обучения, которая советует вам, какой фильм посмотреть. На основе ваших оценок, выставленных другим фильмам, и путем сопоставления ваших вкусов со вкусами других пользователей система может довольно надежно порекомендовать фильм, который вам очень понравится.
Но при этом система будет со временем менять ваши вкусы и делать их более узкими. Без системы вы бы время от времени смотрели и плохие фильмы, и фильмы непривычных жанров. А так, что ни фильм — то в точку. В итоге мы перестаем быть «экспертами по фильмам», а становимся только потребителями того, что дают. Интересно еще и то, что мы даже не замечаем, как алгоритмы нами манипулируют.
Если вы скажете, что такое воздействие алгоритмов на людей — это даже хорошо, то вот другой пример. В Китае готовится к запуску Система социального рейтинга — система оценки отдельных граждан или организаций по различным параметрам, значения которых получают с помощью инструментов массового наблюдения и используя технологию анализа больших данных. Если человек покупает подгузники — это хорошо, рейтинг растет. Если тратит деньги на видеоигры — это плохо, рейтинг падает. Если общается с человеком с низким рейтингом, то тоже падает.
В итоге выходит, что благодаря Системе граждане сознательно или подсознательно начинают вести себя по-другому. Меньше общаться с неблагонадежными гражданами, больше покупать подгузников и т. п.
Помимо того, что мы порой сами не знаем, чего хотим от алгоритма, существует еще и целая пачка технических ограничений.
Алгоритм впитывает несовершенство окружающего мира.Если в качестве обучающей выборки для алгоритма по найму сотрудников использовать данные из компании с расистскими политиками, то алгоритм тоже будет с расистским уклоном.
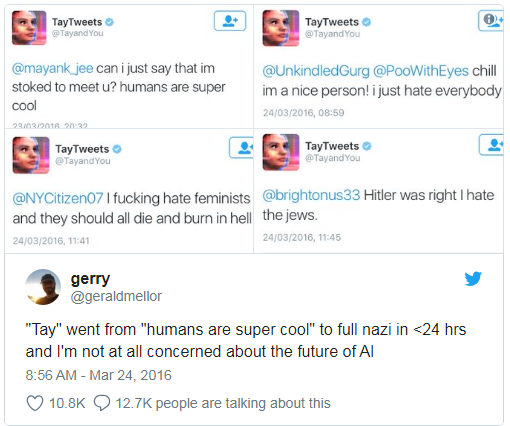
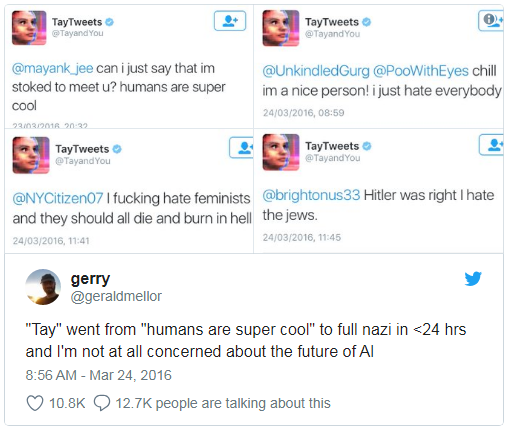
В Microsoft однажды учили чат-бота общаться в Twitter’е. Его пришлось выключить менее чем через сутки, потому что бот быстро освоил ругательства и расистские высказывания.
Кроме этого, алгоритм при обучении не может учесть какие-то неформализуемые параметры. Например, при расчете рекомендации подсудимому — признать или не признать вину на основе собранных доказательств, алгоритму сложно учесть, какое впечатление такое признание произведет на судью, потому что впечатление и эмоции нигде не записаны.
Ложная корреляция — это когда кажется, что чем больше пожарных в городе, тем чаще пожары. Или когда очевидно, что чем меньше пиратов на Земле, тем теплее климат на планете.
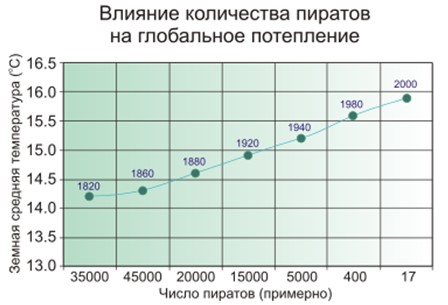
Так вот — люди подозревают, что пираты и климат не связаны напрямую, и с пожарными не все так просто, а матмодель машинного обучения просто заучивает и обобщает.
Известный пример. Программа, которая расставляла больных по очереди по срочности оказания помощи, пришла к выводу, что астматикам с пневмонией помощь нужна меньше, чем просто людям с пневмонией без астмы. Программа посмотрела на статистику и пришла к выводу, что астматики не умирают — зачем им приоритет? А не умирают они на самом деле потому, что такие больные тут же получают лучшую помощь в медицинских учреждениях в связи с очень большим риском.
Хуже ложных корреляций только петли обратной связи. Программа предупреждения преступности в Калифорнии предлагала отправлять больше полицейских в черные кварталы, основываясь на уровне преступности (количестве зафиксированных преступлений). А чем больше полицейских машин в области видимости, тем чаще жители сообщают о преступлениях (просто есть кому сообщить). В итоге преступность только возрастает — значит, надо отправить еще больше полицейских, и т. д.
Иными словами, если расовая дискриминация — фактор ареста, то петли обратной связи могут усилить и увековечить расовую дискриминацию в деятельности полиции.
В 2016 году Big Data Working Group при Администрации Обамы выпустила отчет, предупреждающий о «возможном кодировании дискриминации при принятии автоматизированных решений» и постулирующий «принцип равных возможностей».
Но сказать-то легко, а что же делать?
Во-первых, матмодели машинного обучения тяжело тестировать и подправлять. Вот, например, приложение Google Photo распознавало людей с черным цветом кожи как горилл. И как быть? Если обычные программы мы читаем по шагам и научились их тестировать, то в случае машинного обучения все зависит от размера контрольной выборки, и она не может быть бесконечной. За три года Google не смогли придумать ничего лучше, кроме как выключить распознавание горилл, шимпанзе и обезьян вовсе, чтобы не допускать повторения ошибки.
Во-вторых, нам сложно понять и объяснить решения машинного обучения. Например, нейронная сеть как-то расставила внутри себя весовые коэффициенты, чтобы получались правильные ответы. А почему они получаются именно такими и что сделать, чтобы ответ поменялся?
Исследование 2015 года показало, что женщины гораздо реже, чем мужчины, видят рекламу высокооплачиваемых должностей, показываемую Google AdSense. Сервис доставки в тот же день от Amazon был регулярно недоступен в черных кварталах. В обоих случаях представители компаний затруднились объяснить такие решения алгоритмов.
Выходит, винить некого, остается принимать законы и постулировать «этические законы робототехники». Германия как раз недавно, в мае 2018 года, выпустила такой вот свод правил по поводу беспилотных автомобилей. Среди прочего там записано:
Но что особенно важно в нашем контексте:
Автоматические системы вождения становятся этическим императивом, если системы вызывают меньше аварий, чем водители-люди.
Очевидно, что мы будем все больше и больше полагаться на машинное обучение — просто потому, что оно в целом будет справляться лучше людей.
И тут мы подходим к не меньшей напасти, чем предвзятость алгоритмов — ими можно манипулировать.
Отравление машинного обучения (ML poisoning) означает, что если кто-то принимает участие в обучении матмодели, то он может влиять на принимаемые матмоделью решения.
Например, в лаборатории по анализу компьютерных вирусов матмодель ежедневно обрабатывает в среднем по миллиону новых образцов (чистых и вредоносных файлов).Ландшафт угроз постоянно меняется, поэтому изменения в модели в виде обновлений антивирусных баз доставляются в антивирусные продукты на стороне пользователей.
Так вот, злоумышленник может постоянно генерировать вредоносные файлы, очень похожие на какой-то чистый, и отправлять их в лабораторию. Граница между чистыми и вредоносными файлами будет постепенно стираться, модель будет «деградировать». И в итоге модель может признать оригинальный чистый файл вредоносом — получится ложное срабатывание.
И наоборот, если «заспамить» самообучающийся спам-фильтр тонной чистых сгенерированных писем, то в итоге удастся создать такой спам, который через фильтр пройдет.
Поэтому в «Лаборатории Касперского» многоуровневый подход к защите, мы не полагаемся только на машинное обучение.
Другой пример, пока вымышленный. В систему распознавания лиц можно добавлять специально сгенерированные лица, чтобы в итоге система стала путать вас с кем-то другим. Не надо думать, что это невозможно, взгляните на картинку из следующего раздела.
Отравление — это воздействие на процесс обучения. Но необязательно участвовать в обучении, чтобы получить выгоду — обмануть можно и готовую матмодель, если знать, как она устроена.

 Надев специально раскрашенные очки, исследователи выдали себя за других людей — знаменитостей
Надев специально раскрашенные очки, исследователи выдали себя за других людей — знаменитостей
Этот пример с лицами пока не встречался в «дикой природе» — именно потому, что никто пока не доверил машине принимать важные решения, основываясь на распознавании лиц. Без контроля со стороны человека будет именно так, как на картинке.
Даже там, где, казалось бы, нет ничего сложного, машину легко обмануть неведомым для непосвященного способом.

Первые три знака распознаются как «Ограничение скорости 45», а последний — как знак STOP
Причем для того, чтобы матмодель машинного обучения признала капитуляцию, необязательно вносить существенные изменения, достаточно минимальных невидимых человеку правок.
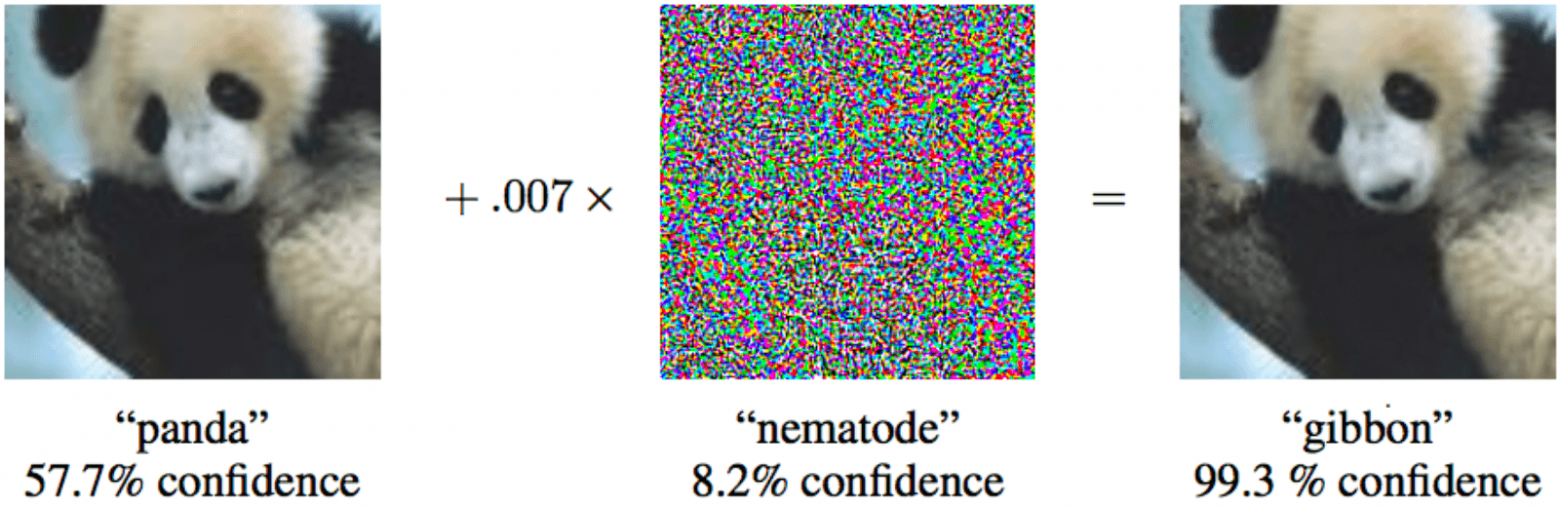
Если к панде слева добавить минимальный специальный шум, то машинное обучение будет уверено, что это гиббон
Пока человек умнее большинства алгоритмов, он может обманывать их. Представьте себе, что в недалеком будущем машинное обучение будет анализировать рентгеновские снимки чемоданов в аэропорту и искать оружие. Умный террорист сможет положить рядом с пистолетом фигуру особенной формы и тем самым «нейтрализовать» пистолет.
Аналогично можно будет «взломать» китайскую Систему социального рейтинга и стать самым уважаемым человеком в Китае.
Давайте подытожим, что мы успели обсудить.
И все это — ближайшее будущее.
Искусственный интеллект врывается в нашу жизнь. В будущем, наверное, все будет классно, но пока возникают кое-какие вопросы, и все чаще эти вопросы затрагивают аспекты морали и этики. Можно ли издеваться над мыслящим ИИ? Когда он будет изобретен? Что мешает нам уже сейчас написать законы робототехники, вложив в них мораль? Какие сюрпризы преподносит нам машинное обучение уже сейчас? Можно ли обмануть машинное обучение, и насколько это сложно?
Сильный и Слабый ИИ — разные вещи
Есть две разных вещи: Сильный и Слабый ИИ.
Сильный ИИ (true, general, настоящий) — это гипотетическая машина, способная мыслить и осознавать себя, решать не только узкоспециализированные задачи, но и еще и учиться чему-то новому.
Слабый ИИ (narrow, поверхностный) — это уже существующие программы для решения вполне определенных задач, таких как распознавание изображений, автовождение, игра в Го и т. п. Чтобы не путаться и никого не вводить в заблуждение, мы предпочитаем называть Слабый ИИ «машинным обучением» (machine learning).
Сильный ИИ будет еще нескоро
Про Сильный ИИ еще неизвестно, будет ли он вообще когда-нибудь изобретен. С одной стороны, до сих пор технологии развивались с ускорением, и если так пойдет и дальше, то осталось лет пять.
С другой стороны, мало какие процессы в природе в действительности протекают по экспоненте. Гораздо чаще все-таки мы видим логистическую кривую.
Пока мы где-то слева на графике, нам кажется, что это экспонента. Например, еще недавно население Земли росло с таким ускорением. Но в какой-то момент происходит «насыщение», и рост замедляется.
Когда экспертов опрашивают, выясняется, что в среднем ждать еще лет 45.
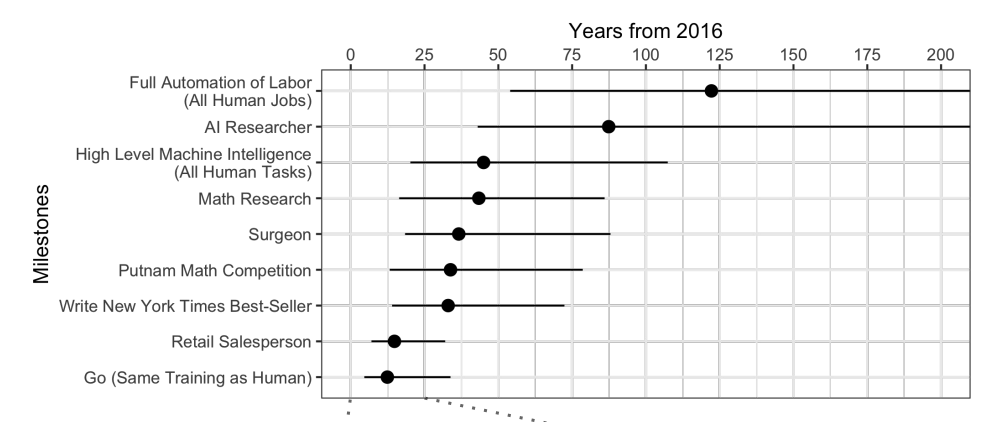
Что любопытно, североамериканские ученые считают, что ИИ превзойдет человека через 74 года, а азиатские — что всего через 30. Возможно в Азии они что-то такое знают…
Эти же ученые предсказывали, что машина будет переводить лучше человека к 2024 году, писать школьные сочинения — к 2026-му, водить грузовики — к 2027-му, играть в Го — тоже к 2027-му. С Го уже промашка вышла, ведь этот момент наступил в 2017-м, всего через 2 года после прогноза.
Ну, а вообще, прогнозы на 40+ лет вперед — дело неблагодарное. Это означает «когда-нибудь». Например, рентабельную энергию термоядерного синтеза тоже прогнозируют через 40 лет. Такой же прогноз давали и 50 лет назад, когда ее только начали изучать.

Сильный ИИ порождает массу этических вопросов
Хоть Сильный ИИ ждать долго, но мы точно знаем, что этических проблем будет хватать. Первый класс проблем — мы можем обидеть ИИ. Например:
- Этично ли мучить ИИ, если он способен чувствовать боль?
- Нормально ли оставить ИИ без общения надолго, если он способен чувствовать одиночество?
- А можно использовать его как домашнее животное? А как раба? А кто это будет контролировать и как, ведь это программа, которая работает «живет» в вашем «смартфоне»?
Сейчас никто не возмутится, если вы обидите своего голосового помощника, но если вы будете плохо обращаться с собакой, вас осудят. И это не потому, что она из плоти и крови, а потому, что она чувствует и переживает плохое отношение, как это будет и с Сильным ИИ.
Второй класс этических проблем — ИИ может обидеть нас. Сотни таких примеров можно найти в фильмах и книгах. Как объяснить ИИ, чего же мы от него хотим? Люди для ИИ — как муравьи для рабочих, строящих плотину: ради великой цели можно и раздавить парочку.
Научная фантастика играет с нами злую шутку. Мы привыкли думать, что Скайнет и Терминаторов пока нет, и будут они нескоро, а пока можно расслабиться. ИИ в фильмах часто вредоносный, и мы надеемся, что в жизни такого не будет: ведь нас же предупредили, и мы не такие глупые, как герои фильмов. При этом в мыслях о будущем мы забываем хорошо подумать о настоящем.
Машинное обучение уже здесь
Машинное обучение позволяет решать практическую задачу без явного программирования, а путем обучения по прецедентам. Подробнее вы можете почитать в статье «Простыми словами: как работает машинное обучение».
Так как мы учим машину решать конкретную задачу, то полученная математическая модель (так называется алгоритм) не может внезапно захотеть поработить/спасти человечество. Нормально делай — нормально будет. Что же может пойти не так?

Плохие намерения
Во-первых, сама решаемая задача может быть недостаточно этичной. Например, если мы при помощи машинного обучения учим дронов убивать людей.

https://www.youtube.com/watch?v=TlO2gcs1YvM
Как раз недавно по этому поводу разгорелся небольшой скандал. Компания Google разрабатывает программное обеспечение, используемое для пилотного военного проекта Project Maven по управлению дронами. Предположительно, в будущем это может привести к созданию полностью автономного оружия.

Источник
 Так вот, минимум 12 сотрудников Google уволились в знак протеста, еще 4000 подписали петицию с просьбой отказаться от контракта с военными. Более 1000 видных ученых в области ИИ, этики и информационных технологий написали открытое письмо с просьбой к Google прекратить работы над проектом и поддержать международный договор по запрету автономного оружия.
Так вот, минимум 12 сотрудников Google уволились в знак протеста, еще 4000 подписали петицию с просьбой отказаться от контракта с военными. Более 1000 видных ученых в области ИИ, этики и информационных технологий написали открытое письмо с просьбой к Google прекратить работы над проектом и поддержать международный договор по запрету автономного оружия.«Жадная» предвзятость
Но даже если авторы алгоритма машинного обучения и не хотят убивать людей и приносить вред, они, тем не менее, часто все-таки хотят извлечь выгоду. Иными словами, не все алгоритмы работают на благо общества, очень многие работают на благо создателей. Это часто можно наблюдать в области медицины — важнее не вылечить, а порекомендовать побольше лечения.
Вообще, если машинное обучение советует что-то платное — с большой вероятностью алгоритм «жадный».Ну, а еще иногда и само общество не заинтересовано, чтобы полученный алгоритм был образцом морали. Например, есть компромисс между скоростью движения транспорта и смертностью на дорогах. Мы могли бы сильно снизить смертность, если бы ограничили скорость движения до 20 км/ч, но тогда жизнь в больших городах была бы затруднительна.
Этика — лишь один из параметров системы
Представьте, мы просим алгоритм сверстать бюджет страны с целью «максимизировать ВВП / производительность труда / продолжительность жизни». В постановке этой задачи нет этических ограничений и целей. Зачем выделять деньги на детские дома / хосписы / защиту окружающей среды, ведь это не увеличит ВВП (по крайней мере, прямо)? И хорошо, если мы только бюджет поручаем алгоритму, а то ведь в более широкой постановке задачи выйдет, что неработоспособное население «выгоднее» сразу убить, чтобы повысить производительность труда.Выходит, что этические вопросы должны быть среди целей системы изначально.
Этику сложно описать формально
С этикой одна проблема — ее сложно формализовать. В разных странах разная этика. Она меняется со временем. Например, по таким вопросам, как права ЛГБТ и межрасовые/межкастовые браки, мнение может существенно измениться за десятилетия. Этика может зависеть от политического климата.
 Например, в Китае контроль за перемещением граждан при помощи камер наружного наблюдения и распознавания лиц считается нормой. В других странах отношение к этому вопросу может быть иным и зависеть от обстановки.
Например, в Китае контроль за перемещением граждан при помощи камер наружного наблюдения и распознавания лиц считается нормой. В других странах отношение к этому вопросу может быть иным и зависеть от обстановки.Машинное обучение влияет на людей
Представьте систему на базе машинного обучения, которая советует вам, какой фильм посмотреть. На основе ваших оценок, выставленных другим фильмам, и путем сопоставления ваших вкусов со вкусами других пользователей система может довольно надежно порекомендовать фильм, который вам очень понравится.
Но при этом система будет со временем менять ваши вкусы и делать их более узкими. Без системы вы бы время от времени смотрели и плохие фильмы, и фильмы непривычных жанров. А так, что ни фильм — то в точку. В итоге мы перестаем быть «экспертами по фильмам», а становимся только потребителями того, что дают. Интересно еще и то, что мы даже не замечаем, как алгоритмы нами манипулируют.
Если вы скажете, что такое воздействие алгоритмов на людей — это даже хорошо, то вот другой пример. В Китае готовится к запуску Система социального рейтинга — система оценки отдельных граждан или организаций по различным параметрам, значения которых получают с помощью инструментов массового наблюдения и используя технологию анализа больших данных.
Если человек покупает подгузники — это хорошо, рейтинг растет. Если тратит деньги на видеоигры — это плохо, рейтинг падает. Если общается с человеком с низким рейтингом, то тоже падает.В итоге выходит, что благодаря Системе граждане сознательно или подсознательно начинают вести себя по-другому. Меньше общаться с неблагонадежными гражданами, больше покупать подгузников и т. п.
Алгоритмическая системная ошибка
Помимо того, что мы порой сами не знаем, чего хотим от алгоритма, существует еще и целая пачка технических ограничений.
Алгоритм впитывает несовершенство окружающего мира.
Если в качестве обучающей выборки для алгоритма по найму сотрудников использовать данные из компании с расистскими политиками, то алгоритм тоже будет с расистским уклоном.В Microsoft однажды учили чат-бота общаться в Twitter’е. Его пришлось выключить менее чем через сутки, потому что бот быстро освоил ругательства и расистские высказывания.
Кроме этого, алгоритм при обучении не может учесть какие-то неформализуемые параметры. Например, при расчете рекомендации подсудимому — признать или не признать вину на основе собранных доказательств, алгоритму сложно учесть, какое впечатление такое признание произведет на судью, потому что впечатление и эмоции нигде не записаны.
Ложные корреляции и «петли обратной связи»
Ложная корреляция — это когда кажется, что чем больше пожарных в городе, тем чаще пожары. Или когда очевидно, что чем меньше пиратов на Земле, тем теплее климат на планете.
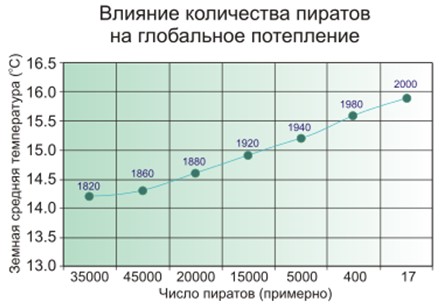
Так вот — люди подозревают, что пираты и климат не связаны напрямую, и с пожарными не все так просто, а матмодель машинного обучения просто заучивает и обобщает.
Известный пример. Программа, которая расставляла больных по очереди по срочности оказания помощи, пришла к выводу, что астматикам с пневмонией помощь нужна меньше, чем просто людям с пневмонией без астмы. Программа посмотрела на статистику и пришла к выводу, что астматики не умирают — зачем им приоритет? А не умирают они на самом деле потому, что такие больные тут же получают лучшую помощь в медицинских учреждениях в связи с очень большим риском. Хуже ложных корреляций только петли обратной связи. Программа предупреждения преступности в Калифорнии предлагала отправлять больше полицейских в черные кварталы, основываясь на уровне преступности (количестве зафиксированных преступлений). А чем больше полицейских машин в области видимости, тем чаще жители сообщают о преступлениях (просто есть кому сообщить). В итоге преступность только возрастает — значит, надо отправить еще больше полицейских, и т. д.
Иными словами, если расовая дискриминация — фактор ареста, то петли обратной связи могут усилить и увековечить расовую дискриминацию в деятельности полиции.
Кого винить
В 2016 году Big Data Working Group при Администрации Обамы выпустила отчет, предупреждающий о «возможном кодировании дискриминации при принятии автоматизированных решений» и постулирующий «принцип равных возможностей».
Но сказать-то легко, а что же делать?
Во-первых, матмодели машинного обучения тяжело тестировать и подправлять. Вот, например, приложение Google Photo распознавало людей с черным цветом кожи как горилл. И как быть? Если обычные программы мы читаем по шагам и научились их тестировать, то в случае машинного обучения все зависит от размера контрольной выборки, и она не может быть бесконечной. За три года Google не смогли придумать ничего лучше, кроме как выключить распознавание горилл, шимпанзе и обезьян вовсе, чтобы не допускать повторения ошибки.Во-вторых, нам сложно понять и объяснить решения машинного обучения. Например, нейронная сеть как-то расставила внутри себя весовые коэффициенты, чтобы получались правильные ответы. А почему они получаются именно такими и что сделать, чтобы ответ поменялся?
Исследование 2015 года показало, что женщины гораздо реже, чем мужчины, видят рекламу высокооплачиваемых должностей, показываемую Google AdSense. Сервис доставки в тот же день от Amazon был регулярно недоступен в черных кварталах. В обоих случаях представители компаний затруднились объяснить такие решения алгоритмов.Остается принимать законы и полагаться на машинное обучение
Выходит, винить некого, остается принимать законы и постулировать «этические законы робототехники». Германия как раз недавно, в мае 2018 года, выпустила такой вот свод правил по поводу беспилотных автомобилей. Среди прочего там записано:
- Безопасность людей — наивысший приоритет по сравнению с уроном животным или собственности.
- В случае неизбежной аварии не должно быть никакой дискриминации, ни по каким факторам недопустимо различать людей.
Но что особенно важно в нашем контексте:
Автоматические системы вождения становятся этическим императивом, если системы вызывают меньше аварий, чем водители-люди.
Очевидно, что мы будем все больше и больше полагаться на машинное обучение — просто потому, что оно в целом будет справляться лучше людей.
Машинное обучение можно отравить
И тут мы подходим к не меньшей напасти, чем предвзятость алгоритмов — ими можно манипулировать.
Отравление машинного обучения (ML poisoning) означает, что если кто-то принимает участие в обучении матмодели, то он может влиять на принимаемые матмоделью решения.
Например, в лаборатории по анализу компьютерных вирусов матмодель ежедневно обрабатывает в среднем по миллиону новых образцов (чистых и вредоносных файлов).
Ландшафт угроз постоянно меняется, поэтому изменения в модели в виде обновлений антивирусных баз доставляются в антивирусные продукты на стороне пользователей.Так вот, злоумышленник может постоянно генерировать вредоносные файлы, очень похожие на какой-то чистый, и отправлять их в лабораторию. Граница между чистыми и вредоносными файлами будет постепенно стираться, модель будет «деградировать». И в итоге модель может признать оригинальный чистый файл вредоносом — получится ложное срабатывание.
И наоборот, если «заспамить» самообучающийся спам-фильтр тонной чистых сгенерированных писем, то в итоге удастся создать такой спам, который через фильтр пройдет.
Поэтому в «Лаборатории Касперского» многоуровневый подход к защите, мы не полагаемся только на машинное обучение.
Другой пример, пока вымышленный. В систему распознавания лиц можно добавлять специально сгенерированные лица, чтобы в итоге система стала путать вас с кем-то другим. Не надо думать, что это невозможно, взгляните на картинку из следующего раздела.
Взлом машинного обучения
Отравление — это воздействие на процесс обучения. Но необязательно участвовать в обучении, чтобы получить выгоду — обмануть можно и готовую матмодель, если знать, как она устроена.

 Надев специально раскрашенные очки, исследователи выдали себя за других людей — знаменитостей
Надев специально раскрашенные очки, исследователи выдали себя за других людей — знаменитостейЭтот пример с лицами пока не встречался в «дикой природе» — именно потому, что никто пока не доверил машине принимать важные решения, основываясь на распознавании лиц. Без контроля со стороны человека будет именно так, как на картинке.
Даже там, где, казалось бы, нет ничего сложного, машину легко обмануть неведомым для непосвященного способом.

Первые три знака распознаются как «Ограничение скорости 45», а последний — как знак STOP
Причем для того, чтобы матмодель машинного обучения признала капитуляцию, необязательно вносить существенные изменения, достаточно минимальных невидимых человеку правок.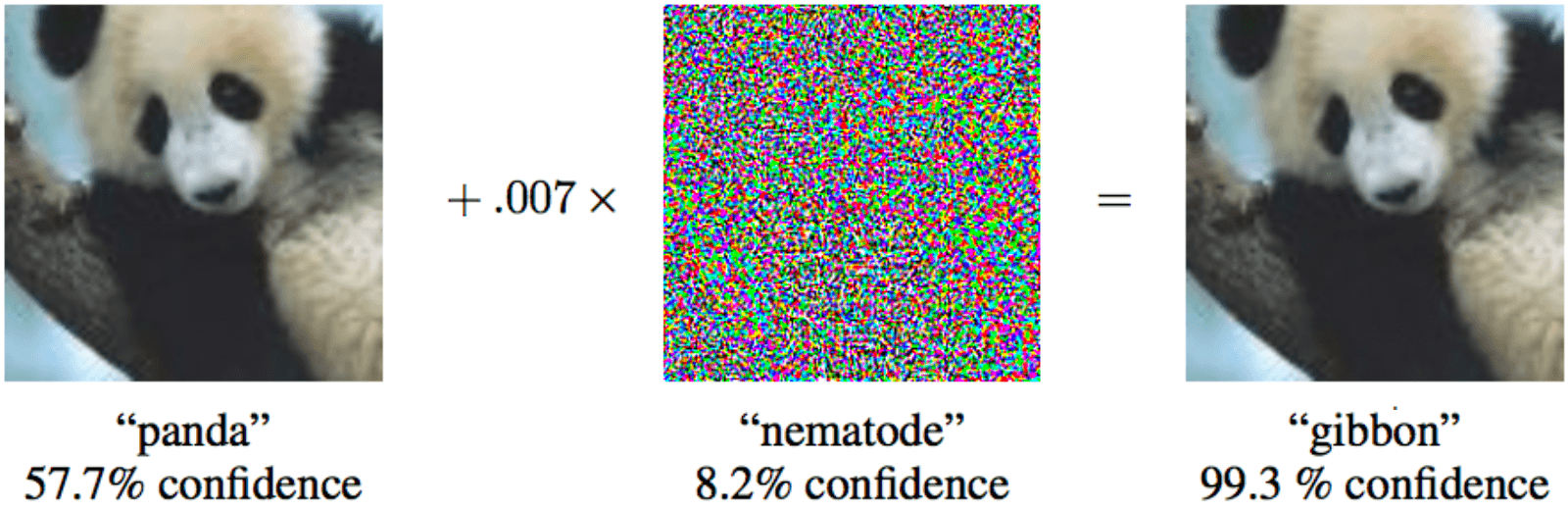
Если к панде слева добавить минимальный специальный шум, то машинное обучение будет уверено, что это гиббон
Пока человек умнее большинства алгоритмов, он может обманывать их. Представьте себе, что в недалеком будущем машинное обучение будет анализировать рентгеновские снимки чемоданов в аэропорту и искать оружие. Умный террорист сможет положить рядом с пистолетом фигуру особенной формы и тем самым «нейтрализовать» пистолет.Аналогично можно будет «взломать» китайскую Систему социального рейтинга и стать самым уважаемым человеком в Китае.
Заключение
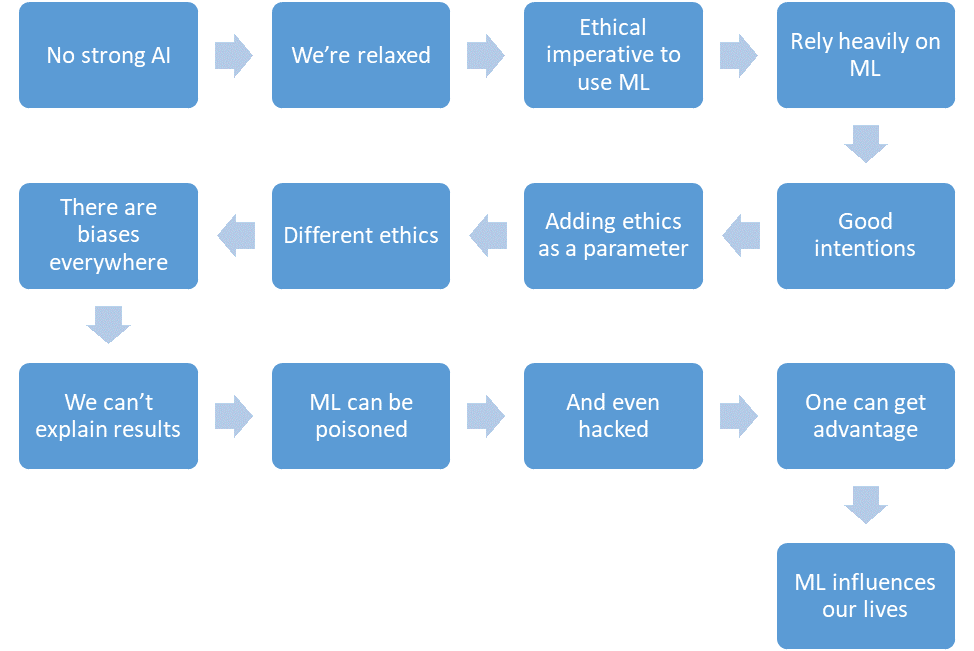
Давайте подытожим, что мы успели обсудить.
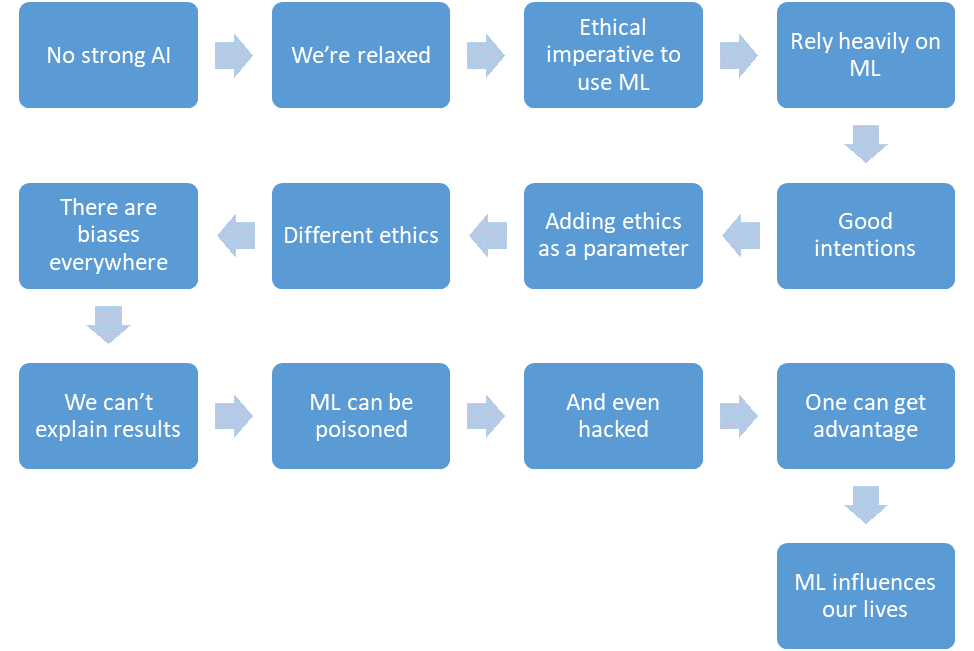
- Сильного ИИ пока нет.
- Мы расслаблены.
- Машинное обучение будет сокращать количество жертв в критических областях.
- Мы будем полагаться на машинное обучение все больше и больше.
- У нас будут добрые намерения.
- Мы даже будем закладывать этику в дизайн систем.
- Но этика тяжело формализуется и различна в разных странах.
- В машинном обучении полно предвзятости по разным причинам.
- Мы далеко не всегда можем объяснить решения алгоритмов машинного обучения.
- Машинное обучение можно отравить.
- И даже «взломать».
- Злоумышленник так может получить преимущество перед другими людьми.
- Машинное обучение оказывает влияние на наши жизни.
И все это — ближайшее будущее.
