Софту мы не доверяем уже давно, и поэтому осуществляем его аудит, проводим обратную инженерию, прогоняем в пошаговом режиме, запускаем в песочнице. Что же насчёт процессора, на котором выполняется наш софт? – Мы слепо и беззаветно доверяем этому маленькому кусочку кремния. Однако современное железо имеет те же самые проблемы, что и софт: секретную недокументированную функциональность, ошибки, уязвимости, малварь, трояны, руткиты, бэкдоры.

ISA (Instruction Set Architecture) x86 – одна из самых долгих непрерывно изменяющихся «архитектур набора команд» в истории. Начиная с дизайна 8086, разработанного в 1976 году, ISA претерпевает постоянные изменения и обновления; сохраняя при этом обратную совместимость и поддержку исходной спецификации. За 40 лет своего взросления, архитектура ISA обросла и продолжает обрастать множеством новых режимов и наборов инструкций, каждый из которых добавляет к предшествующему дизайну, и без того перегруженному, новый слой. Из-за политики полной обратной совместимости, в современных процессорах x86 присутствуют даже те инструкции и режимы, которые на сегодняшний день уже преданы полному забвению. В результате мы имеем архитектуру процессора, которая представляет собой сложно переплетающийся лабиринт новых и антикварных технологий. Такая чрезвычайно сложная среда – порождает множество проблем с кибербезопасностью процессора. Поэтому процессоры x86 не могут претендовать на роль доверенного корня критической киберинфраструктуры.
Вы всё ещё доверяете своему процессору?
Безопасность программ и операционной системы – зиждется на безопасности железа, на котором они развёрнуты. Как правило разработчики софта не учитывают того факта, что железо, на котором разворачивается их софт – может быть недоверенным, вредоносным. Когда железо ведёт себя ошибочно (независимо оттого, преднамеренно или нет), программные механизмы безопасности – полностью обесцениваются. Уже много лет предлагаются различные модели защищённых процессоров: Intel SGX, AMD Pacifica и др. Тем не менее, завидная регулярность, с которой публикуется информация о критических сбоях (из недавних, например Meltdown и Spectre) и обнаруженных недокументированных «отладочных» функциях – наводит на мысль, что наше беззаветное доверие к процессорам беспочвенно.
Современные процессоры x86 представляют собой очень громоздкое и запутанное переплетение новейших и антикварных технологий. У 8086 было 29 тыс. транзисторов, у Pentium – 3 млн., у Broadwell – 3,2 млрд, у Cannonlake – больше 10 млрд.

При таком количестве транзисторов неудивительно, что современные процессоры x86 испещрены недокументированными инструкциями и аппаратными уязвимостями. Среди недокументированных, – обнаруженных почти случайно, – инструкций: ICEBP (0xF1), LOADALL (0x0F07), apicall (0x0FFFF0) [1], которые позволяют разблокировать процессор для несанкционированного доступа к защищённым областям памяти.
Что же касается многочисленных аппаратных уязвимостей процессоров (см. два рисунка ниже), то они позволяют киберзлоумышленнику осуществлять эскалацию привилегий [3], извлекать криптографические ключи [4], создавать новые ассемблерные инструкции [2], менять функциональность уже существующих ассемблерных инструкций [2], устанавливать хуки на ассемблерные инструкции [2], брать под контроль «аппаратно ускоренную виртуализацию» [7], вмешиваться в «атомарные криптографические вычисления» [7] и, – сладкое напоследок, – входить в «режим бога»: подчинять себе легальный аппаратный бэкдор Intel ME (который позволяет получать удалённый доступ даже к выключенному компьютеру) [8]. И всё это – не оставляя каких-либо цифровых следов.
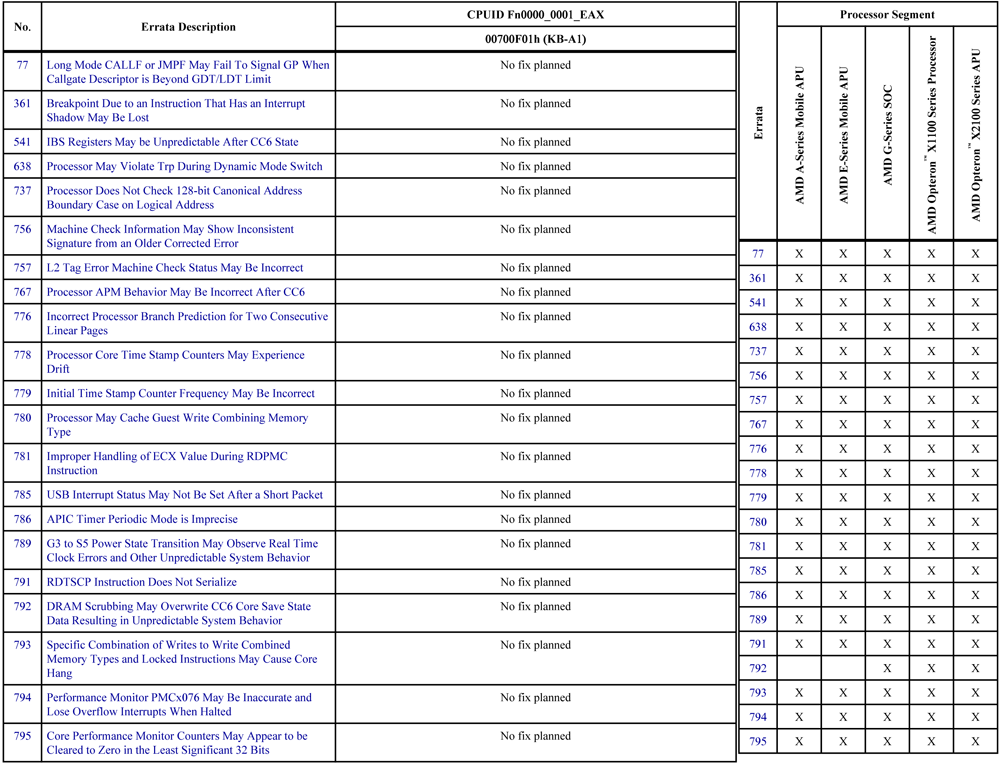
Современные процессоры – это больше софт, чем железо
Строго говоря, современные процессоры даже нельзя назвать «железом» в полном смысле этого слова. Потому что наиболее критичная их функциональность (в том числе, ISA) – обеспечивается перепрошиваемым микрокодом. Изначально микрокод отвечал в основном за то, чтобы управлять декодированием и выполнением сложных ассемблерных инструкций: операции с плавающей точкой, MMX-примитивы, обработчики строк с префиксом REP и т.п. Однако с течением времени на микрокод возлагается всё больше и больше ответственности за обработку операций внутри процессора. Так например, современные расширения процессоров Intel, такие как AVX (Advanced Vector Extensions) и VT-d (аппаратная виртуализация) – реализованы на микрокоде.
Кроме того, сегодня микрокод отвечает, в числе прочего, за сохранение состояния процессора, за управление кэшем и также за управление энергосбережением. Для энергосбережения, на микрокоде реализован механизм прерываний, обрабатывающий состояния электропитания: С-состояния (степень энергосберегающего сна: от активного состояния до глубокого сна) и P-состояния (разные комбинации вольтажа и частоты). Так например, за обнуление L2-кэша при входе в состояние C4, а также при выходе из него – отвечает именно микрокод.
Зачем производители процессоров пользуются микрокодом?
Производители процессоров x86 используют микрокод для разложения сложных ассемблерных инструкций (длина которых может достигать 15 байт) в цепочку простых микроинструкций, – в целях упрощения аппаратной архитектуры и облегчения диагностики. По сути, микрокод это интерпретатор между внешней (видимой для пользователя) CISC-архитектурой и внутренней (аппаратной) RISC-архитектурой.
При обнаружении ошибок в CISC-архитектуре (в ISA, прежде всего), производители публикуют обновление микрокода, которое можно закачать в процессор через BIOS/UEFI материнской платы или через операционную систему (во время процесса загрузки). Благодаря такой системе обновлений, основанной на микрокодах, производители процессоров обеспечивают себе гибкость и снижение затрат – при исправлении ошибок в своём оборудовании. Нашумевшая ошибка с fdiv, которая сильно подкосила процессоры Intel Pentium в 1994 году – сделала ещё более очевидным тот факт, что высокотехнологичное железо подвержено ошибкам точно также, как и софт. Данный инцидент породил у производителей ещё больше интереса к архитектуре процессоров на основе микрокода. Поэтому Intel и AMD стали строить свои процессоры с применением технологии микрокодов. Intel – начиная с Pentium Pro (P6), выпущенного в 1995 году. AMD – начиная с K7, выпущенного в 1999 году.
Всё тайное становится явным
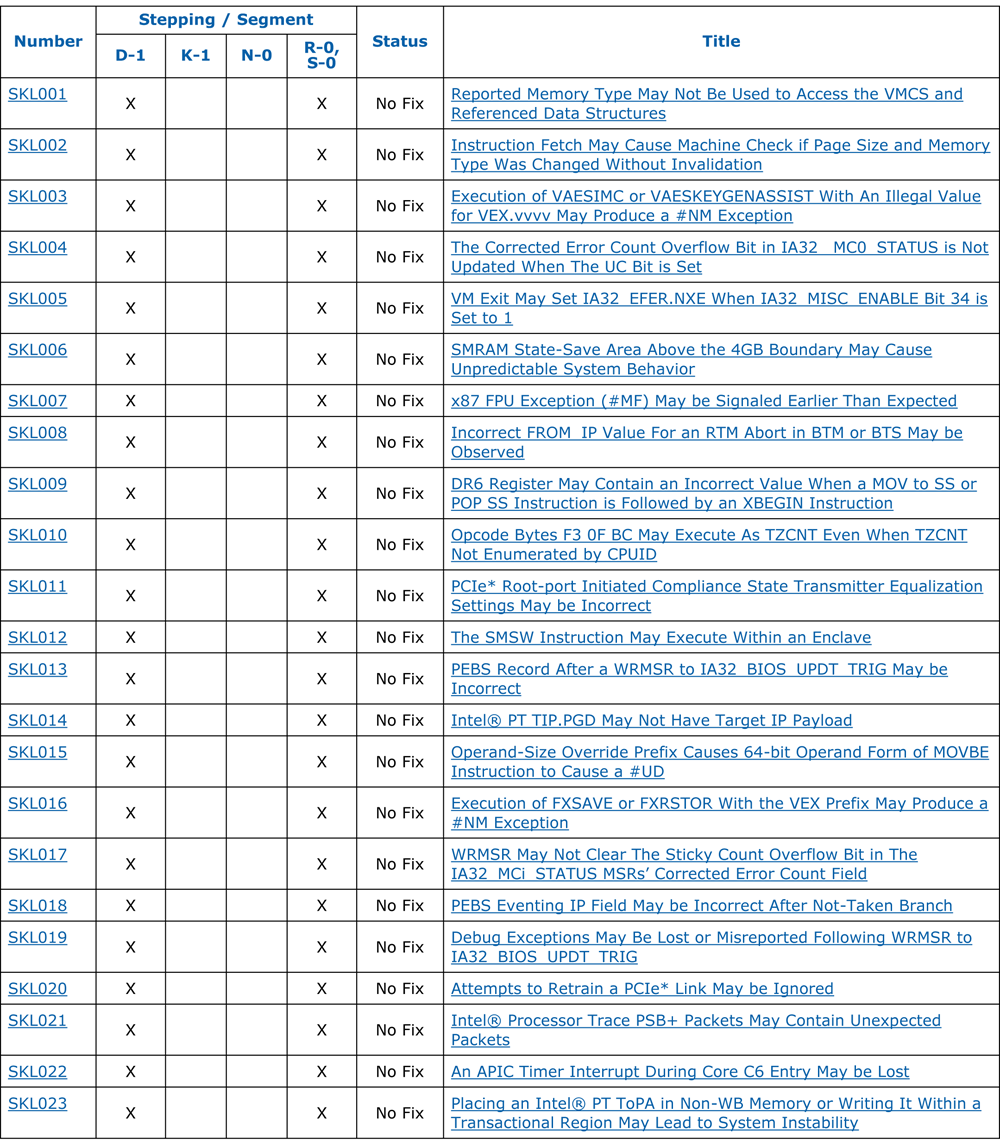
Несмотря на то, что производители процессоров стараются держать архитектуру микрокодов и механизм их обновления в строжайшем секрете, – враг не дремлет. Крупицы разрозненной информации (в основном из патентов, вроде AMD RISC86 [5]) и вдумчивый реверсинг официальных обновлений для BIOS (как это было с K8 [6]), – постепенно проливают свет на тайну микрокода (см. например, на рисунке ниже «механизм обновления микрокода процессоров AMD»). А благодаря постоянной эволюции инструментария для реверсинга (как программного, так и аппаратного) [2], перспективным методикам фаззинга [1] и появлению таких OpenSource-инструментов как Microparse [9] и Sandsifter [10] – киберзлоумышленник может узнать о микрокоде всё необходимое для того, чтобы писать на нём микрокодовую малварь.
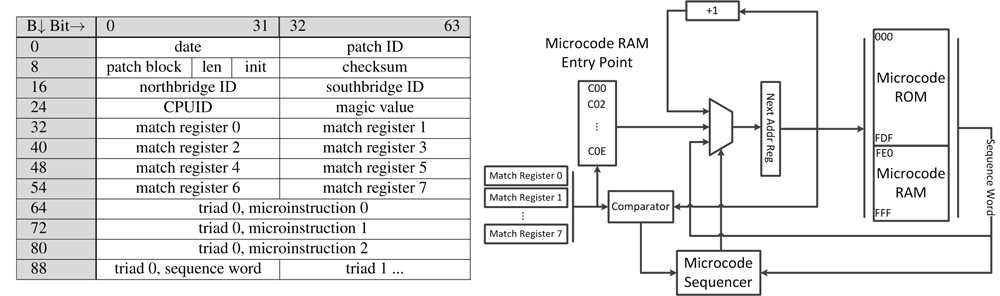
Так например, в [2] на правах «Hello world!» (первый шаг к троянизации микрокода) разработан «микрохук» (микрокодовая программа, перехватывающая ассемблерную инструкцию), который подсчитывает, сколько раз процессор обращался к команде div. Этот микрохук представляет собой инъекцию в обработчик ассемблерной инструкции div.

Там же [2] представлен более продвинутый микрохук, – который спокойно себе сидит в ассемблерной инструкции div ebx, ничем не выдавая своего присутствия, и активируется только когда при обращении к div ebx выполняются конкретные условия: в регистре ebx содержится значение B, а в регистре eax содержится значение A. Активируясь, этот микрохук увеличивает значение регистра eip (указатель текущей инструкции) на единицу. В результате выполнение программы (которая имела смелость обратиться к инструкции div ebx) продолжается со смещением: ни с первого байта следующей за div ebx команды, а с её второго байта. Если же в регистрах eax и ebx заданы другие значения, то div ebx работает в обычном режиме. Какая в этом практическая ценность? Например, чтобы незаметно активировать скрытую цепочку ассемблерных инструкций, при использовании обфускационной техники с «перекрываемыми инструкциями» [11].
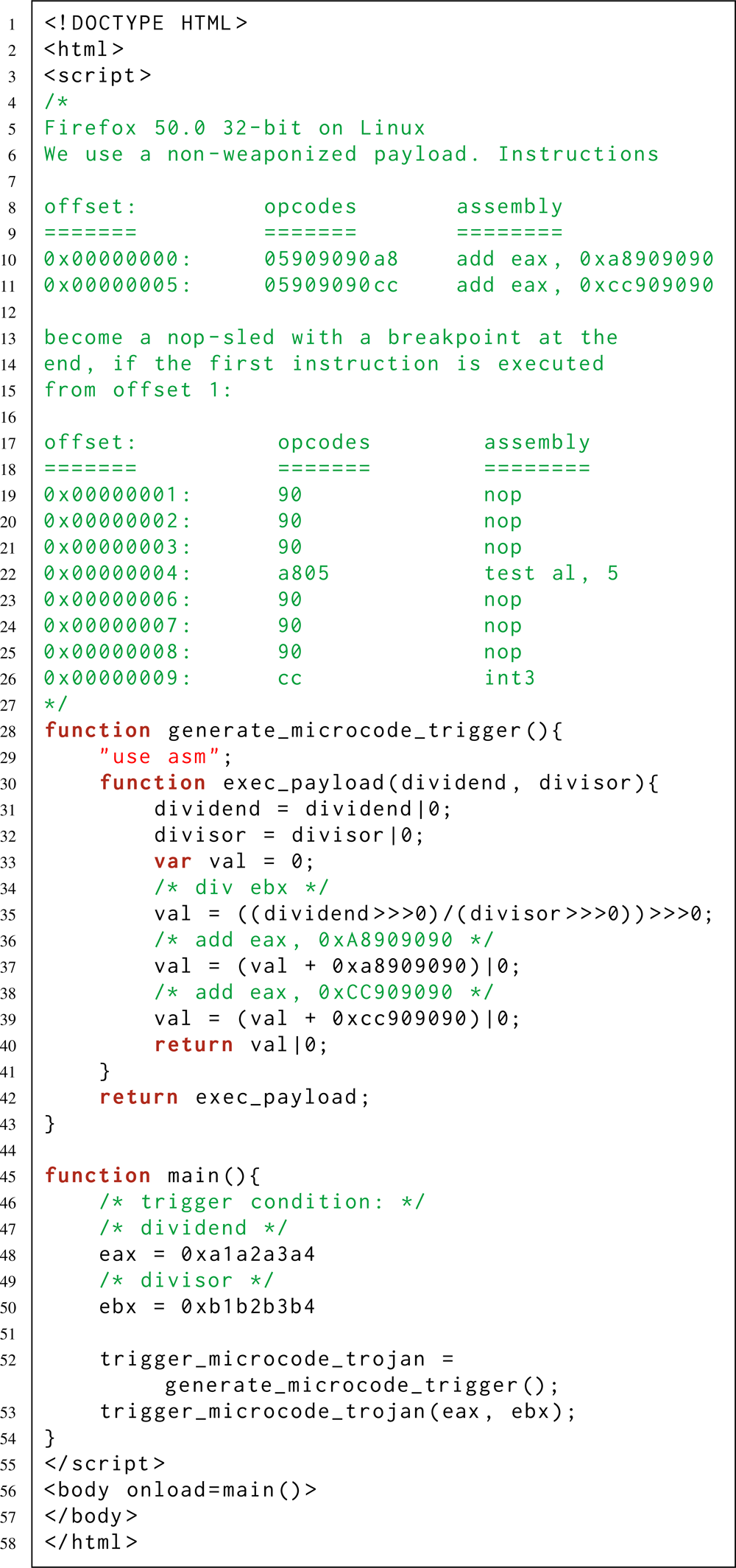
Эти два примера демонстрируют, как законные ассемблерные инструкции можно использовать для сокрытия в них произвольного троянского кода.
При этом, киберзлоумышленник может активировать свою вредоносную полезную нагрузку – в том числе и удалённо. Например, когда необходимое для активации условие выполняется на веб-странице, контролируемой злоумышленником. Это возможно благодаря компиляторам Just-in-Time (JIT) и Ahead-of-Time (AOT), встроенным в современные веб-браузеры. Эти компиляторы позволяют испускать предопределённый поток ассемблерных инструкций машинного кода – даже если вы пишете программу исключительно на высокоуровневом JavaScript (см. последний листинг – чуть выше).
- Christopher Domas. Breaking the x86 ISA // DEFCON 25. 2017.
- Philipp Koppe. Reverse Engineering x86 Processor Microcode // Proceedings of the 26th USENIX Security Symposium. 2017. pp. 1163-1180.
- Matthew Hicks. SPECS: A Lightweight Runtime Mechanism for Protecting Software from Security-Critical Processor Bugs // Proceedings of the 28th International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS). 2015. pp. 517–529.
- Adi Shamir. Bug Attacks // Proceedings of the 28th Annual conference on Cryptography: Advances in Cryptology. 2008. pp. 221–240.
- John Favor. RISC86 Instruction Set // US Patent 6336178. 2002.
- Opteron Exposed: Reverse Engineering AMD K8 Microcode Updates. 2004.
- Saming Chen. Security Analysis of x86 Processor Microcode.2014.
- Catalin Cimpanu. Malware Uses Obscure Intel CPU Feature to Steal Data and Avoid Firewalls. 2017.
- Daming Chen. Microparse: Microcode parser for AMD, Intel, and VIA processors // GitHub. 2014.
- Sandsifter: The x86 processor fuzzer // GitHib. 2017.
- Карев В.М. Как написать на ассемблере программу с перекрываемыми инструкциями (ещё одна техника обфускации байт-кода) // Хабрахабр. 2018. URL: (дата обращения: 25 октября 2018).
