Comments 87
- Выкинуть весь вышеописанный переусложнённый многословный бесполезный код
- Оставить из него одну строчку, которая реально что-то делает
(addr ) ^= (1 << bit) - Впредь никогда не тащить лишние абстракции в программирование микроконтроллеров
Суть заключается в том, что бизнес логика будет очень простая, переносимая из проекта в проект и можно будет легко реализовывать алгоритмы… В случае же с
(addr ) ^= (1 << bit)int main() {
BlinkTimer & blinker = Singleton<BlinkTimer>::GetInstance() ;
//подписываем Led1, находящийся в ROM, на событие от Таймера моргания
blinker.Subscribe(Singleton<Led1>::GetInstance()) ;
blinker.Start() ;
delay(10000_ms); //сделал так для простоты
blinker.Subscribe(Singleton<Led2>::GetInstance()) ; //подписываем другой светодиод
}Да много плюсов, вам не надо менять обработчик прерывания таймера, вы можете подписать другого подписчика, который что-то делает на событие по таймеру, при этом вам не надо менять сам обработчик и так далее… но это об абстракциях.
А статья больше я про то, что порождающий шаблон Синглтон точно создает вам объект в ROM, а если не сможет его создать, то значит вы что-то сделали не так, и должны поправить. Если скомпилилось, то вы точно уверены, что объект в ROM, ну при условии, что линкер правильно настроен.
1. Компилятор не может ничего в ROM положить, потому что он может раскидать только по секциям. Секции по адресам раскидывает линкер, поэтому, если вы в настройках линкера сказали, что секция помеченная атрибутом
.readonly должна лежать в ROM, все ваши readonly переменные будут лежать в ROM. Как бы предполагается, что в микроконтроллере с flash как раз так линкер и настроен. Конечно никто вам не запрещает специально настроить линкер, на то, чтобы все было RAM, даже код…2. сonstexpr выражение, а в нашем случае
constexpr static T instance{T()}, ни что иное, как сonstexpr выражение, может быть таким, пока не встретит там кучу всего перечислено в стандарте, но я приведу часть:this (8.1.2), except in a constexpr function or a constexpr constructor that is being evaluated as part of e;
(2.2) — an invocation of a function other than a constexpr constructor for a literal class, a constexpr function,or an implicit invocation of a trivial destructor (15.4) [ Note: Overload resolution (16.3) is applied as usual — end note ];
(2.3) — an invocation of an undefined constexpr function or an undefined constexpr constructor;
(2.4) — an invocation of an instantiated constexpr function or constexpr constructor that fails to satisfy the requirements for a constexpr function or constexpr constructor (10.1.5);
(2.6) — an operation that would have undefined behavior as specified in Clauses 4 through 19 of this International Standard [ Note: including, for example, signed integer overflow (Clause 8), certain pointer arithmetic (8.7), division by zero (8.6), or certain shift operations (8.8) — end note ];
[Example:
int x; // not constant struct A { constexpr A(bool b) : m(b?42:x) { } int m; }; constexpr int v = A(true).m; // OK: constructor call initializes m with the value 42 constexpr int w = A(false).m; // ERROR: initializer for m is x, which is non-constant constexpr int f1(int k) { constexpr int x = k; // ERROR: x is not initialized by a constant expression // because lifetime of k began outside the initializer of x return x;
}
Т.е. как только встречается одно из этих условий, компилятор должен выдать ошибку, что ваше выражение не может быть constexpr
3. Для constexpr функций и конструктор есть отдельный раздел в стандарте и действительно нельзя определить является ли функция или конструктор constexpr или нет. Про это и был разговор со знающим человеком
4. Знающий человек Valdaros, правильно указал, на то, что объявленный constexpr конструктор может таковым не считаться, по причине того, что можно изменить const-qualified объект, и я привел пример с конструктором в конце прошлой статьи.
5. Но как только мы объявили
constexpr static T instance{T()} и при этом у объекта T конструктор не соответствует пункту (2.4), наше выражение не может считаться constexpr и поэтому компилятор выдает ошибку. Это и есть 100% гарантия того, что объект попадает в секцию помеченную .readonly, а если она в настройках линкера настроена на ROM, то и в ROM.
И это не «рекомендация» — это гарантировано стандартом.
Еще раз constexpr конструктор не гарантирует статическую инициализацию, что и было указано знающим человеком. А вот constexpr выражение написанное вами, не могущее на самом деле им быть, должно восприниматься компилятором как ошибка, он вам должен про об сообщить, что в данном методе и обыгрывается.
Интересно, как часто есть необходимость добиваться идеальной кроссплатформенности и соответствия стандартам для встраиваемых проектов? По моему они пишутся под конкретный процессор и компилятор, если только это не универсальные библиотеки. А для конкретного компилятора достаточно простейшего С-кода с прагмами, чтобы расподожить объект где нужно и получить оптимальный код инициализации. В своих проектах предпочитаю обходиться без этих сложных объектных заморочек — уж простите, но глупо столько сил тратить на простейшую задачу, особенно в сложном проекте.
C.2.10 Использование доверительных/проверенных элементов программного обеспечения
Примечани е — Ссылка наданный метод/средство приведена в МЭК 61508-3 (таблицы А.2, С.2, А.4иС.4).
Цель. Исключение такого проектирования программных модулей и элементов, которое вызывало бы необходимость их интенсивных повторных проверок или перепроектирования для каждого нового применения. Использование преимущества проектов, которые не были формально или строго проверены, но для которых имеется продолжительный опыт эксплуатации. Использовать преимущества уже существующих программных элементов, которые были проверены для различных применений и для которых существует совокупность доказательств подтверждения соответствия.
Описание. Данный метод проверяет наличие в программных элементах систематических ошибок проектирования и/или эксплуатационных отказов.
Строить сложную систему, используя элементарные компоненты, нецелесообразно. Как правило, используют основные узлы («элементы», см. МЭК 61508-4, пункты 3.2.8 и 3.4.5), которые были разработаны ранее для обеспечения некоторых полезных функций и которые могут быть использованы для реализации некоторой части новой системы.
Грамотно спроектированные и структурированные ПЭ системы состоят из ряда программных элементов, которые различаются между собой четким образом и взаимодействуют друг с другом вполне определенными способами. Формирование библиотеки таких общеприменимых программных элементов, которые можно повторно использовать в нескольких применениях, позволяет большую часть ресурсов, необходимых для подтверждения соответствия проектов, распределять по нескольким применениям.
Кроме того в любом устройстве приходит момент, когда появляется новая платформа и надо все на нее переносить, и код надо переиспользовать по полной. А учитывая, что с ним сразу и юнит тесты и документация есть и он уже проверку проходил от сертификатчиков, это экономит кучу денег и времени.
Кроме того в любом устройстве приходит момент, когда появляется новая платформа и надо все на нее переносить, и код надо переиспользовать по полной. А учитывая, что с ним сразу и юнит тесты и документация есть и он уже проверку проходил от сертификатчиков, это экономит кучу денег и времени.
То есть у вас есть опыт поддрежки и переноса на новые платформы больших проектов на C и проектов на C++ с метапрограммированием и Вы можете реальными цифрами подтвердить экономию?
Или это Вы так думаете…
Забавно отвечать на коммент спустя 3 года. Был коммерческий проект, работал на архитектуре cortex-m3, пришёл ковид, чипы пропали, запас стал подходить к концу, схватили первое, что выпало в продажу и точно покрывало хардварную часть - cortex-m4. Портируем проект. Сейчас вообще хз будут ли чипы, а если будут то какие, предполагаю, что ещё один порт не за горами.
Чтобы понять, что за ножка, потребовалось внимательно пересмотреть контекст.
(восстановил комментарий)
Как может быть бизнес-логика в эмбеде?
Любой маломальский датчик имеет встроенный софт, где 80% бизнес логики. Настроили АЦП, порты (это 20%, а то и меньше, и то, надо просто прочитать датащит и настроить все в соответствии с ним (особо изобретать ничего не надо)), а дальше пошла математика, она тоже является бизнеслогикой, расчеты, обработка ошибок, вывод на индикатор, передача данных по протоколам, настройка, логирование информации.
В нормально спроектированном ембед софте Абстрактное Железо и уровень бизнеслогики разведены, так чтобы при смене платформы, бизнеслогика могла хорошо переносится без изменения. А уж на чем он написан, вообще не важно, Си, С++ или даже Rust.
Кстати, если уж совсем про языки заговорили, то для встроенного софта удовлетворяющим требованиям надежности, то ни Си ни С++ не рекомендованы, без специально описанных стандартов программирования и так далее. А рекомендован — Ada, Modula2, например, потому что они строго типизированы.
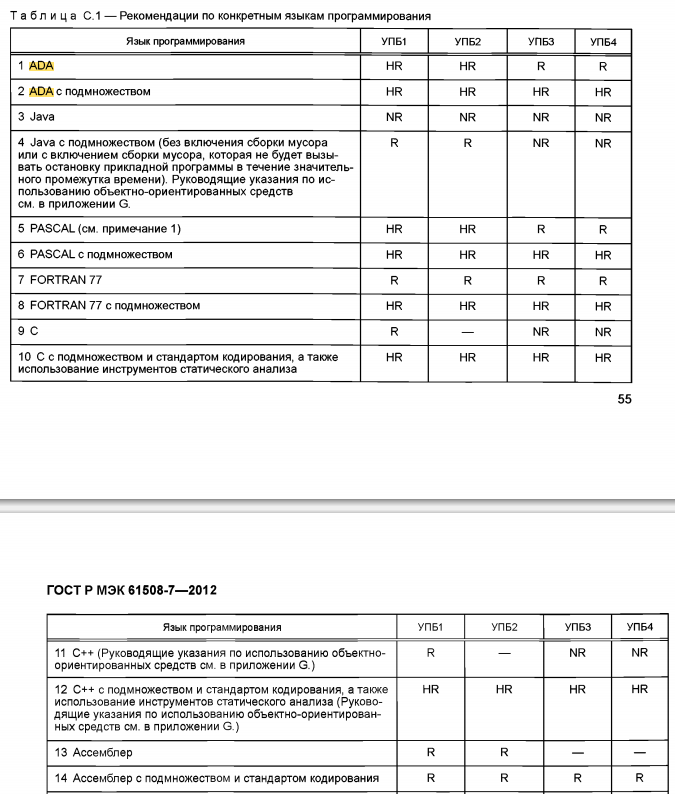
NR — Not recommended… R — recommended (на самом деле, считайте что тут будут к вам придираться), HR — High recommended (это то за что вы получите бал).
Я надеюсь это то не новость для вас…
Таблица из МЭК 61508-7. Как вы видите из таблицы С++ и Си не рекомендованы к использованию без специальных средств проверки. А рекомендован Ada.
Я и не рассматривал Linux, потому что вообще считаю, что Linux это уже никакой не embedded. Я рассматриваю что-то типа максимум, софт использующий РТОС, типа FreeRTOS.
Линукс писался на Си, потому что в то время, действительно С++ не был столь эффективен и самое эффективное можно было писать только на Си, ну не считая ассемблера.
Архитектура ПО везде одинаковая, многослойная… и то, что я вам сказал, является ни чем иным, как бизнес логикой.
Как это не удивительно для вас, но во встроенном ПО тоже рисуют архитектуру, потому что без неё вы не получите ни одного сертификата надежности.
И да я имею ввиду только
тот же контроллер Cortex-M3, или подобный, который есть в каждом мобильном устройстве и который управляет всей системой питания и тактирования девайсаИ совершенно верно вы сказали, про цену ошибки. Поэтому чтобы этого не допустить и делают
Примечани е — Ссылка наданный метод/средство приведена в МЭК 61508-3 (таблицы А.2, С.2, А.4иС.4).
Цель. Исключение такого проектирования программных модулей и элементов, которое вызывало бы необходимость их интенсивных повторных проверок или перепроектирования для каждого нового применения. Использование преимущества проектов, которые не были формально или строго проверены, но для которых имеется продолжительный опыт эксплуатации. Использовать преимущества уже существующих программных элементов, которые были проверены для различных применений и для которых существует совокупность доказательств подтверждения соответствия.
Описание. Данный метод проверяет наличие в программных элементах систематических ошибок проектирования и/или эксплуатационных отказов.
Строить сложную систему, используя элементарные компоненты, нецелесообразно. Как правило, используют основные узлы («элементы», см. МЭК 61508-4, пункты 3.2.8 и 3.4.5), которые были разработаны ранее для обеспечения некоторых полезных функций и которые могут быть использованы для реализации некоторой части новой системы.
Грамотно спроектированные и структурированные ПЭ системы состоят из ряда программных элементов, которые различаются между собой четким образом и взаимодействуют друг с другом вполне определенными способами. Формирование библиотеки таких общеприменимых программных элементов, которые можно повторно использовать в нескольких применениях, позволяет большую часть ресурсов, необходимых для подтверждения соответствия проектов, распределять по нескольким применениям.
А также добиваются отсутствия ошибок с помощью процесса разработки, Требования-архитектура-код-статический анализатор-юни тесты-смок тесты-системные тесты.
Часть отвечающая за аппаратуру вообще в таком процессу описывается в специальном документе (как настроить порты, регистры периферии, микросхемы АЦП, модема и так далле), документ делают программисты вместе с электронщиками и это делается до разработки ПО, это входит в спецификацию, все что нужно дальше сделать это настроить все в соответствии с документом, что там такого заумного и сверхъестественного, что надо знать только ембедд программисту, я не понимаю… мало того, я могу вас уверить, что в большинстве случаев, после настройки в соответствии с этим документов, даже отладка не нужна. Проблемы бывают, если например, программист плохо прочитал все ерраты, и не учёл важные моменты, но в большинстве случаев все работает с первого раза. (У нас был момент связанный с AVR, когда, мы использовали, как было написано в errate не задействованный бит регистра, ну т.е его настройка ни на что не влияла, а Атмел взял и выпустили новую ревизию микроконтроллера и он стал отвечать за перевод АЦП на пониженное потребление на низкой частоте). Т.е. у нас наши прототипы на предыдущей ревизии работали хорошо, потому что настройка этого бита ничего не давала, а как только пришла новая ревизия, показания АЦП стали неверными, и мы понять ничего не могли. Вот тут и пришлось делать отладку… Но это чистый косяк программистов, которые еррату сквозь пальцы читали и потом еще на peer review проглядели этот момент.
А классы и шаблоны позволяют лучше понять код, и проследить связь архитектуры с кодом, потому что она линейная. Вы можете в принципе из UML сгенерить заготовку класса, а уж обратно и подавно. А вот как описать идею Сишного callback передающегося в функцию простым рисунком?
Мы и занимается как раз разработкой надежного ПО, чтобы не было
ошибок потенциально приводящих к зависанию и перезагрузке, или просто крэшит проток выполнения и опять перезагрузка ватчдогом
Советую этот МЭК прочитать, там описаны методики обнаружения всех этих ошибок и практики программирования для того, чтобы этих ошибок не допускать.
И это в первую очередь касается встроенного ПО
Я вас уверяю, плюсы сейчас можно использовать эффективнее Си (как по размеру кода, так и по скорости и качеству разработки), при грамотном подходе.
Угу, однако Си с подмножеством и линтером таки побеждаэ, ибо уже HR, но меньше вопросов от некомпетентных аудиторов и проще найти более-менее вменяемых разработчиков.
Но это так, к слову, я в вашу дискуссию не лезу. Уже говорил ранее, что рано или поздно плюсы придут в эмбед плотно, но это потребует сильного пересмотра стратегий разработки.
К слову — это в каком же университете, на какой специальности и в каком курсе вы так смело подложили плюсовую бомбу под «C supremacy»? :)
Блин, ну ведь выше уже был упомянут 61508, сложно потратить час на чтение по диагонали?
мне тоже приходятся байтики ворочать, просто их обычно в районе 10-100 миллиардов, и они все в памяти, и мне надо уметь быстро по ним отвечать на запросы, или что-то матрично-машинно-обучательное воротить.
При этом количество памяти измеряется сотнями гигабайт, частоты процессоров — гигагерцами, а их количество — сотнями? Тогда ваша позиция неудивительна.
Поймите меня верно, я совершенно не подвергаю сомнению ваш опыт в обработке больших массивов данных, но, поверьте, контроллер микроволновки программируется совсем по-другому, и тут навыки в описываемой области так же бесполезны, как и мои навыки в программировании контроллеров бесполезны применительно к big data.
А, потому что не знает C++ и знать не хочет. Ну ок.
Вполне себе аргумент, между прочим. Тем более что знание плюсов — понятие растяжимое, и из этой когорты люди выпадают каждые три года, с каждым новым стандартом (а я очевидно выпал уже очень давно, даже несмотря на мое раздутое самомнение).
— Плюсы лучше, учите плюсы!
— Да нам и так хорошо.
— Вам плохо, смотрите как вам плохо, просто вы не знали!
— Что-то у вас язык сложный, если плохо его знать — еще больше накосячишь. Мы лучше по-старинке.
— Это все отмазки, вы не программисты, а программасты, вон из профессии, ленивые уроды!
— Окау.
А вот реплики — ну это смотря к какой ветке обсуждения. Например в этой ветке стартовый комментарий в общем-то ничего не говорит ни про один из языков, там сугубо какие-то злобные обвинения в адрес автора, и языки возникли уже в комментариях к комментарию. А вот в ветке ниже — там да, сразу пошли в атаку.
В то же время, ООП достаточно неплохо эмулируется на plain C, взять хотя бы эту ссылку: stackoverflow.com/questions/840501/how-do-function-pointers-in-c-work, в частности, раздел «Function pointers in C can be used to perform object-oriented programming in C».
Вот там видно, что у людей теория и практика шагают в долю.
Если, что там весь код на этапе компиляции все делает и на выходе только, то, что надо…
Да нет, там общая психологическая фиксация. Конечно в самом ООП, если его использовать маленько, никаких минусов, а одни плюсы. Но ведь… Ведь конструкторы копирования все эти сраные… Какая-то прочая мутота… Какое-то SRP, шаблоны (их и я лично ненавижу, как вы уже заметили — прим. авт.), какие-то ацкие контейнеры и итераторы, умные указатели, аааа, кровь из глаз… Так рассуждают многие, и их можно понять — напиши что-нибудь на плюсах немного не по мэйнстриму, покажи потом такой код на Хабре (условно), тебя же обосрут с ног до головы — где, дескать, паттерны!!! Проще сказать, что плюсы не для эмбеда, надо только в Си, вы ничего не понимаете и только ногами дрыгали.
Вот я готов сделать честный каминг-аут — писал на плюсах под МК, но это было в чистом виде "Си с классами". И, внимание, с собственной реализацией ассоциативного массива! Так что ненависть других эмбедеров к плюсам не разделяю — просто у меня свои плюсы. Берегите нервы, товарищи. :)
Я действительно пробовал ООП на МК и было это много лет назад, с тех пор ARM GCC стал менее глючным (2018q4 все равно нельзя использовать, таращит его).
Если подходить шаблон как к скриптовому языку, который может на этапе компиляции, что-то сделать с вашим кодом, и преобразовать его в что-то немного другое, удобное для использование. Сичтайте, что вам надо скрипт на Phyton написали, для того, чтобы из данных генерить заголовочники. А зачем вам Phyton, если это можно сделать с помощью самого языка и компилятора?
Умные указателя, итераторы — все сделано для того, чтобы в коде не допустить ошибку, они за вас думают, делают так, чтобы если вы создали объект, он не забыл очистить память при очистке… Т.е. по сути это в помощь вам… вам меньше надо париться и меньше деталей в голове держать, сконцентрироваться на самой задаче, а не на том, как не допустить ошибку.
Можно прямо ООП с виртуальным наследование не использовать
А зачем отказываться? Тем более что позднее связывание — едва ли не простейшая для понимания вещь.
Конструкторы копирования обычно не используются, для микроконтроллера точно
Конструктор копирования обязан быть, иначе вы проклятый глупец и вон из С++.
В синглтоне только, разве что
Внезапно. :)
Из «правила трех» это проистекает, хотя его можно и игнорировать.
другой стороны, конструктор это просто обычный метод, который вызывается сам в момент создания объекта для его инициализации.… Соответственно конструктор копирования вызывается в момент копирования объекта
Да я не спорю же, конечно все очень просто ))
Умные указателя, итераторы — все сделано для того, чтобы в коде не допустить ошибку, они за вас думают, делают так, чтобы если вы создали объект, он не забыл очистить память при очистке
Да понятно это все, но… Если бы это было сделано по-другому и выглядело по-человечески. Уж никак не из-за блестящей реализации, которой все завидуют, плюсы все никак не победят Си в эмбеде.
Конструктор копирования обязан быть, иначе вы проклятый глупец и вон из С++
Я видимо неправильно выразился, имел ввиду, что вы его не определяете, ставите его либо deafult, либо, чтобы класс не забивать вообще ничего не пишите и для вас как-будто его нет, хотя конечно он есть :) по умолчанию
Из «правила трех» это проистекает, хотя его можно и игнорировать.Сейчас уже правило 6, потому что еще move конструктор и оператор присваивания добавились :) и деструктор.
Но это обычно ко встроенному ПО отношения не имеет. Поэтому я не вижу ничего страшного, чтобы их просто не определять в таком случае, чтобы код не загромождать.
Я видимо неправильно выразился, имел ввиду, что вы его не определяете, ставите его либо deafult, либо, чтобы класс не забивать вообще ничего не пишите и для вас как-будто его нет, хотя конечно он есть :) по умолчанию
Нет нет, я вас прекрасно понял. Естественно его не может не быть в любом случае, однако же суть в том, что если ты его не определяешь, то… Вот вы например знаете, что не все программисты на С++ в курсе про конструктор копирования? В это и проблема обсуждаемого языка — до определенного момента можно жить припеваючи.
Сейчас уже правило 6
Вроде «правило пяти» сейчас уже, но не важно.
Но это обычно ко встроенному ПО отношения не имеет. Поэтому я не вижу ничего страшного, чтобы их просто не определять в таком случае, чтобы код не загромождать.
Ой ой ой, как интересно… Так может тогда и вместо new использовать malloc? Удобнее же. И кастоваться можно в стиле Си, гораздо менее загромождает код. И шаблонами не пользоваться — в большинстве случаев они кажется вставляются только для того, чтобы поразить общественность. И никаких умных указателей — в большинстве случаев от них никакого толка. В каком месте можно остановиться? Принцип «не используй то, что тебе не нужно» может завести очень далеко.
С другой стороны, конструктор это просто обычный метод, который вызывается сам в момент создания объекта для его инициализации.
Вы серьезно уверены, что конструктор — обычный метод? Стандарт говорит об этом иначе…
Скажем, так. Я действительно думаю, что это функция без имени использующаяся для инициализации класса.
Во-вторых, вызвать конструктор нельзя, это может сделать только компилятор, причем это часто даже вызовом не назвать, столько там может быть неявных действий, особенно, если используется вся мощь ООП с наследованием и т.д.
Конструктор это как бы указание для компилятора: помимо той магии, которую ты нагенеришь для создания объекта в том или ином контексте, вот это вот не забудь выполнить.
А вот деструктор, это да, функция с типом возврата void. Но там тоже не все так просто.

Может вы спутали с конструктором по умолчанию, да и то там проблема, не в самом конструторе, а в том, что компилятор не может это вызов распарсить по нормальному, называется
Most Vexing Parse. В общем, тут вы не правы.
Решил освежить в памяти стандарт, да действительно называется special member function. Но суть от этого не поменялась. Это все еще функция, без имени и использумая для инициализации.
Говорить, что конструктор обычный метод, вызываемый для инициализации — это даже не упрощение. Вы студентов тоже этому учите?!
Декларация конструктора такая же как и функции. Если выглядит как утка, крякает как утка, плавает как утка, то скорее всего это утка и есть.
И даже в ассемблере это BL… Ну что вы в самом деле, так можно сказать что и метод это не функция…
Если я слово обычный заменю на специальный… Будет понятнее?
И да… Студентам я говорю, что это метод без имени, использумый для инициализации. Как написано во всех учебниках. И что вызвать его можно тоже говорю.
A declaration of a constructor uses a function declarator form.— конструктор выглядит как функция. Но, например, в нем может быть список инициализации, которого не может быть в обычной функции.
Конструктор влияет на инициализацию объекта, но код создающий объект генерируется компилятором.
Конструктор базового класса Вы не вызываете, Вы можете только указать, какой из конструкторов базового класса применить.
Пролог и эпилог конструктора обычно отличается от обычных функций, иногда значительно.
В ходе конструирования объекта совершаются нетривиальные действия (например, смена значения указателя на таблицу виртуальных функций).
Ни одна друга утка не крякает даже близко. Не путайте конструктор со статической фабрикой вроде std::make_shared.
А по-поводу ассемблерного кода, то там не call/bl может быть, а jump или вообще все встроится. И что?
Слово для инициализации подразумевает под собой, все связанное с инициалищацией, в том числе и список инициализации.
Что вы подразумеваете под словом, код создающий обьект? И причем тут конструктор? Насколько я помню, под обьект просто компилятор должен выделить память, а потом вызвать конструктор для инициализации и вызов это выглядит как вызов функции, включая все то, что находится в списке инициализации.
Конечно много чего происходит на заднем плане, но тогда и виртуальный метод тоже не метод в вашем понимании, потому что там много чего происходит тоже на задворках, в том числе и вытаскивание адреса функции через указатель таблицы виртуальных функций. А статическая локальная переменная не переменная, потому что там вообще инициализация не тривиальная.
Я согласен, что в таком контексте
правильнее будет сказать специальная функция, не имеющая имени, использующаяся для инициализации.
Но то, что я имел ввиду сказать в оригинальном тексте, это, факт того, что по большому счету выглядит это как функция, вызываемая при создании… Что собственно в общем то так и есть.
Object obj = Object(10);
Или так
Object obj(10);
Что это если не инициализация, используя вызов конструктора класса Object с параметром int на входе?
Или я чего то недопонимаю?
Что то вы меня вообще в тупик поставили своим вопросом :), я еще раз прочитал первоисточник и все теперь все встало на свои места. С терминологией видимо несостыковка.
Т. Е. формально похоже вы правы, явно конструктор не вызывается, поскольку у него нет имени компилятор не может найти его чере поиск имен, но применение явного преобразование типа инициирует вызов конструктора для инициализации обьекта.
Это выглядит как вызов безымянной функции, и поэтому все просто назыаают это вызовом конструктора.
А вызов конструктора базового класса и своего конструктора, правильнее назвать делегированием.
Получается терминология вызов в данном контексте не совсем верная, но по другому я никогда это и не называл.
Что мы видим? Компаратор во втором случае передается как указатель на функцию, то есть мы _всегда_ обязаны вызывать эту функцию, пихать значения в регистры, делать джамп, вот это всё. В первом случае компилятор может взять и заинлайнить компаратор (если там что-то тривиальное, типа сравнения Точек).
Во втором случае тело функции находится в библиотеке, что, опять же, заставляет компилятор делать явный вызов. В первом случае всё также может заинлайнится.
Итак, как N+1 гарантированных вызовов функций могут быть быстрее 1 или 0 вызовов функций?
Ну вот и получается, что C++ многие начинают считать «языков не для всех» и не для всего.
А чего компилятор это не ловит в 2019-м-то году?
Потому что может быть случай, когда человек хотел сделать именно так. Может это какой-то хитрый регистр, обращение к которому по такому правилу вызывает определенный эффект?
Скажем, в STM32F0 модуль SPI устроен так, что обращения
SPIx->DR = byte;
и
*((uint8_t *)(&(SPIx->DR))) = byte;
вызывают разный аппаратный эффект. Внезапно, да?
Вообще, корректно работать с указателями на уровне рефлекса — первое, чему должен научиться разработчик встроенных систем.
SPIx->DR = byte;
и
*((uint8_t *)(&(SPIx->DR))) = byte;
вызывают разный аппаратный эффект. Внезапно, да?
Вас правда удивляет, что запись по хранящемуся в поле структуры адресу вызывает не тот же эффект, что запись по адресу поля структуры, Мне кажется, что это не зависит от архитектуры и т.д.
А теперь внимательно-внимательно посмотрите, что делает каждая запись.
Эти записи пишут в одно и то же место. Только одна использует инструкцию записи слова, а другая — байта.
Во второй записи происходит следующее: мы берем адрес регистра (потому что структура отображается непосредственно на область памяти, которую занимает модуль SPI), приводим его к типу указателя на uint8_t и разыменовываем обратно.
В первом случае мы пишем просто в регистр, который в структуре объявлен как uint16_t.
модуль SPI устроен
через ж. он устроен.
Никто им не мешал сделать отдельный регистр SPIx->DR_WORD. Никто не мешал накрутить union'ы в заголовке, чтобы не плодить приведения типов на ровном месте.
Но нет! Программист STM32 должен страдать!
Смотришь на периферию любого другого контроллера — насколько же гибко и мощно можно сделать периферию, а тут…
Наболело, извините.
Внезапно, да?
Внезапно, да. Про такие особенности надо писать БОЛЬШИМИ БУКВАМИ в описании регистров. То, что оно упоминается только в описании модуля (как фишка «у нас есть data packing») — однозначно минус.
stm32 = кортекс
Да, капитан!
описан в библиотеке ARM CMSIS, как и МК других производителей.
А вот тут — нет. ARM описывает ядро и «ядерную» периферию (NVIC, SysTick, SCB). Плюс они придумали (?) формат SVD — суть единообразное описание регистров периферии, который конвертируется в хидер спец-конвертером ( github.com/ARM-software/CMSIS_5/tree/develop/CMSIS/Utilities ).
А вот остальные периферийные модули, как и описание к ним, делают производители чипа (и, собственно, периферийные модули и являются конкурентным преимуществом — ядро-то у всех одинаковое!).
у всех ARM точно так же
Точно так же что? Модуль SPI одинаковый? Мне лень нарезать картинки с блок-схемами, просто поверьте на слово — у каждого производителя он свой. Пруфы — в user manual, reference manual, product specification.
Я брал свежий CMSIS с сайта ARM, а не ST.
Ссылка developer.arm.com/tools-and-software/embedded/cmsis
ведёт на github.com/ARM-software/CMSIS_5/releases/tag/5.5.1
Вас ведь не затруднит найти хоть одно упоминание ST'шного модуля SPI в любом из трёх представленных там файлов?
Остальные тезисы предлагаю обсудить после этого вопроса.
Там уже есть кучу SVD от производителя github.com/posborne/cmsis-svd/tree/master/data
Я инлайну уделил время, т.к. на коротких функциях он дает 30-40% прироста производительности.
Угу, давайте возьмем какой-нибудь std::sort и сравним с qsortПрограммирование МК с использованием C++ это тоже искусство. Понятно, что прямой перенос паттернов с десктопа в МК приводит к плачевным результатам. Поэтому применение плюсов отнюдь не избавляет от необходимости глубокого понимания того, что во что и как компилируется. Причем в случае C++, минимальный объем таких знаний гораздо больше чем для C.
Используйте «паттерн Синглтон»! В эмбедеде его только и используют, уже лет 40!
Ждем на Хабре публикаций вроде «используйте целочисленную арифметику», или «не используйте printf»!
Синглтон, размещающий объекты в ROM и статические переменные(С++ на примере микроконтроллера Cortex M4)