Comments 69
Проблема в том, что UML — это та же спецификация, только описанная графически, а не текстом.
И поэтому ее будет преследовать тот же бич всех спецификаций — по мере имплементации реальный код будет все больше и больше удаляться от спецификации, если постоянно их не синхронизировать. А так как на синхронизацию очень многие забивают, то получается, что UML для многих — это просто трата времени, так как в итоге все равно надо смотреть на код.
Решить эту проблему пытаются с помощью автоматической генерации кода из UML, но я пока не видел тех, кто это успешно реализовал в производственной деятельности.
Автоматическая генерация кода по спецификации никогда не работает.
Код всегда сложнее спецификации, в нем больше деталей. А потому либо сгенерированный код придется править вручную, что сведет на нет всю идею, либо же в спецификацию начнут пробираться детали реализации. Во втором случае все сведется к тому, что программа будет писаться на языке, который для программирования не предназначен.
А по теме — UML ничем не лучше рисунтов на салфетках. Да, это некий стандарт. Да, его все понимают. Да, его иногда даже используют (sequence diagrams — программисты, data flow — архитекторы). Но как сказано было выше любая спецификация устаревает в тот момент, когда ее начинает читать программист. Поддерживать документацию? Ну если только вообще нечего больше делать :)
RUP общего с Rational Rose имеет только слово Rational.
Rose не умела генерировать алгоритмы.
Data flow нет в UML.
Алгоритмы целиком она конечно не генерировала, но ниже классов и даже методов спускалась. Для того весь код был размечен коментириями страшного вида. Этим достизалась синхронизация диаграмм -> кода и обратно.
Data flow диаграмм нет, но activity diagram есть.
К примеру, с этим вам может помочь IDE от JetBrains, там можно генерировать диаграммы. Ссылка
Автоматическая генерация кода по спецификации никогда не работает.
Ну почему не работает? Работает. Например для генерации кода в системах управления реального времени — автомобильных, авиационных, космических системах. И в системах цифровой обработки сигналов.
Там логика контроллера или преобразователя сигналов полностью описывается графически диаграммами состояний и сигналами и блоками, моделируется и проверяется вместе с объектом управления или генераторами сигналов и из нее генерируется Си или HDL код.
Модель — это и есть функциональная спецификация, а сам подход называется Model-Based-Design. Только UML там нет...
Там логика контроллера или преобразователя сигналов полностью описывается графически диаграммами состояний и сигналами и блоками
Тогда это графический язык программирования, а не спецификация
Только UML там нет...
И это не случайность.
Тогда это графический язык программирования, а не спецификация
Это именно функциональная спецификация. Она описывает, что должен делать контроллер словами системного дизайнера. О программировании он при этом не знает.
Сравните вот эту диаграмму состояний в Stateflow

С диаграммой состояний UML
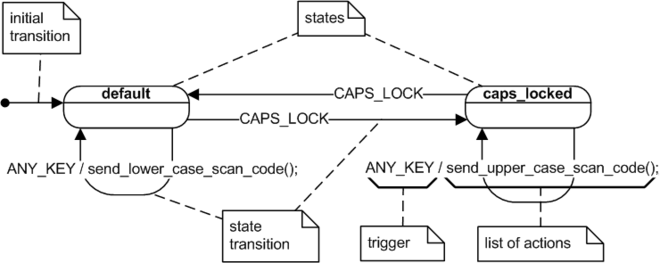
Не видите знакомые элементы?
А вот вам диаграма состояний нагревателя в Stateflow.
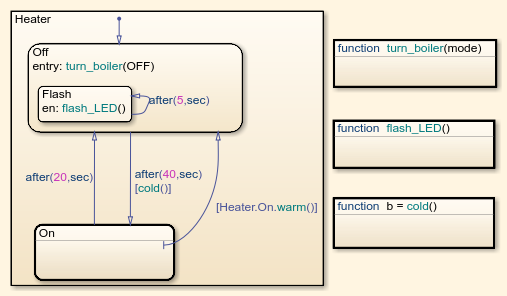
Чем вам не UML? Разве не читается? А ведь из нее можно сгенерить вполне рабочий код.
Вот эти after(5, sec) и превращают схему в графическую программу. Тут нельзя написать after 5 sec или там since(sec, 5) — автор схемы должен разбираться в доступных ему командах.
О программировании он при этом не знает.
Это он так думает...
Вот эти after(5, sec) и превращают схему в графическую программу. Тут нельзя написать after 5 sec или там since(sec, 5) — автор схемы должен разбираться в доступных ему командах.
Это необходимый синтаксис для того, чтобы система правильно моделировала поведение диаграммы. Вы же хотите посмотреть как оно будет работать до того, как начнете программировать? Иначе, как я уже говорил, вообще смысл моделирования теряется — что толку от такой диаграммы, если ее нельзя прогнать через моделирование?
Только UML там нет...
Вообще-то есть. Называется Action Semantics for UML.
Ужасная штука.
Проходили. Знаю.
Код получается громоздкий и плохо читаемый, любое внесение изменений в него (а без этого не обойтись) приводит к тому, что обратно из UML новую версию не сгенерить.
Мертворожденная идея фирмы Rational Rose.
Могла бы работает только в идеальном мире, в котором:
- ТЗ проекта отлита в бериллиевой бронзе.
- Структура классов и архитектура ПО так же отлита в бериллиевой бронзе.
В жизни — не работает.
Первично все таки UML, а потом код, а не наоборот. Т.е. не надо генерить UML из кода, это неправильно, а вот из UML в код можно. Но лучше, просто вначале делать изменения в UML, а потом переносить их в код… и встроить это в процесс.
Моделирование — это не всегда работы типы проектирования. Моделирование как документирование, описание того что уже имеется или сделано без лишних деталей, тоже используется. Банальный школьный глобус — модель земного шара, модель как описание, а не как проект :)
Предварительное проектирование никак от очень очень много итераций не спасает в условиях меняющихся требований. В какой-то момент времени проектные модели начинают отставать от кода, вернее код ответвляется от проектной модели, так её полностью и не имплементировав. А возможность генерировать UML означает возможность получить актуальную техническую документацию в любой момент.
Какая разница кидаться менять код сразу и методом проб и ошибок искать правильный вариант, или кинуться поменять модель, а потом по ней тупо сделать код… В код не все сразу смогут въехать, что там вообще происходит, а модель она проще, её понять могут многие, и если что могут дать дельные советы… и на этапе моделирования еще успеть серьезные огрехи в архитектуре поправить. А код по архитектуре можно написать быстро. Даже замеряли мы на примерно похожих проектах с разными подходами, если код писать без моделирования то очень быстрое начало, в пропорциях примерно так, через месяц уже можно отрапортовать, что все (а точнее код) готово на 90%, а потом 11 месяцев еще доводить до ума эти 10%. А с моделированием, через 2 месяц можно сказать, что модель на 90% готова (при этом, ни строчки кода ни написав), потом 2-3 месяца на реализацию модели и детальное моделирование и 2-3 месяца доводку модели с кодом, т.е примерно в 2 раза быстрее, а про качество вообще молчу.
Вы так говорите, как будто архитектуру нельзя описать кодом, а в графическую модель все сразу могут въехать. Кроме очень большой трудоемкости рисования диаграмм, самый большой их недостаток по опыту: мало кто их понимает хоть как-то (я — хоть как-то, без чтения спек UML не возьмусь реализовывать ни одну схему в статье, даже схему работы часов я не понимаю), а чаще бизнес даже не пытается их смотреть, принимая их за техническую документацию, которую непонятно зачем ему на утверждение приносят. Вот с BPMN они любят возиться, по своей инициативе их даже рисуют, а UML им просто неинтересна. Выходит UML нужен только автору, как инструмент фиксации своих идей, если графическую фиксацию он воспринимает лучше других. Мне вот текстовая ближе и субъективно, и по результатам многочисленных психологических тестов.
Может быть UML имеет смысл в организациях, где над проектом сначала работает архитектор, рисует схемы, отдаёт их программистам и с проекта уходит. А вот для себя, в качестве инструмента общения с бизнесом (что бизнесу показывать в конце спринта первые два месяца?) или в качестве рабочего инструмента команды, он, по-моему, избыточен
И на практике слабо понимаю как можно 2 месяца что-то моделировать, не имея возможности проверить как оно соответствует бизнес-требованиям.
Выходит UML нужен только автору, как инструмент фиксации своих идей, если графическую фиксацию он воспринимает лучше других. Мне вот текстовая ближе и субъективно, и по результатам многочисленных психологических тестов.
Не соглашусь с этим: если код писали НЕ Вы — перечитывать кучу хитросплетений модулей и имен и зачем это все сделано и как работает — это явно не быстро. Зачастую ВЫСОКИЙ УРОВЕНЬ в виде документации UML или текстового описания коллегой в чате (что одно и тоже — ВЫСОКИЙ уровень ключевое) — будет эффективней для понимания хоть всей системы, хоть конкретного алгоритма (если по нему вам описали).
Для понимания нюансов — вроде как производительно у нас тут работает (где оптимизить, где итак ок), или какие модули с чем связаны вплоть до параметров методов и иерархий классов — разумеется будет накладно описывать в виде UML просто потому что это другой УРОВЕНЬ детализации, его конечно лучше в коде читать.
Только вот про моделирование в статье аж всего два слова. Как и во всех описаниях работы с UML тоже. Для меня модель системы — это когда ты на вход подаешь информацию — а на выходе получаешь ее реакцию.
Например вот есть в UML диаграма состояний. ОК, как ее промоделировать? Как проверить, что все состояния правильные и переходы правильно отрабатываются? А иначе, я так тоже могу самолет от руки нарисовать и сказать, что это мое представление о нем в UML. А как это проверить?
Чисто логически, поэтому и называется, полуформальный. Т. Е., ты смотришь на модель, например диаграмму последовательности, преполагаешь, а что если другой поток будет обращаться… Ага надо добавить вызов лока… И так далее. Ее может посмотреть другой программист, проанализировать и сказать, что да работать будет… реализовывай…
Зато потом из UML прекрасно пишется и дополняется документация.
Ну и отдельные косяки сразу бросаются в глаза.
Допустим надо реализовать некое сложное, асинхронное взаимодействие.
1. Рисуем диаграмму последовательностей, основываясь на своих предположениях.
2. Реализовываем ее в лоб — последовательно сверху вниз
3. В процессе реализации понимаем, что вот этот этап надо бы совсем по другому реализовать, возможно даже с переделкой нескольких предыдущих
4. Возвращаемся к схеме(!) и дорабатываем необходимые места
5. Продолжаем разработку с самого «верхнего» измененного места
6. goto 3
Тут главное перебороть в себе укоренившееся представление, что «код первичен, а схемы вторичны» и сами с удивлением поймете, насколько проще и понятнее становится разработка.
Я признаю полезность UML, но единственный удобный инструмент для создания диаграмм классов, работающий под Linux, который я нашёл за разумные деньги это IDE от JetBrains. Пишешь код классов (скелет) и генерируешь диаграмму, если она требуется. Только мышкой потом перетащить остаётся, чтоб понятней было, и то стрелки кривые выходят.
Для остальных диаграмм и того нет. Поэтому диаграммы создаю в качестве отчёта, если єто входит в DoD задачи. Даже для задачи разработки архитектуры, когда написание кода не подразумевается, я его всё равно пишу. И если требуется не только диаграмма классов, то рисование остальных в более-менее презентабельном виде занимает обычно больше времени, чем собственно разработка. Иногда на порядки больше. Если заниматься этим чаще, то может быть чуть-чуть время уменьшится из-за того, что на каждый чих в спецификации лезть не надо будет. Но само рисование "мышкой и клавиатурой" никуда не денется.
Есть бесплатные или недорогие Linux или веб инструменты создания остальных диаграмм из текстового описания на каком-то языке (в идеале DSL, но yaml тоже пойдёт — что по коду их генерировать можно я не верю), без указания размеров и координат, с последующим ручным выравниванием для презентационніх целей?
Я сразу написл, что не ищу инструментов которые из текста сделают готовое для презентации описание. Не верю в их существование, пока не создан ИИ, понимающий что такое удобно, красиво и как найти между ними баланс.
За наводку на http://plantuml.com/ огромное спасибо!
Для Draw.io можно сделать описание диаграммы на html. Сначала вставляете ручками элемент, потом смотрите каким кодом он описывается (Дополнительно -> Редактировать диаграмму). Далее пишете свой парсер, который из вашего формата сделает описание на нужном html.
Мне помогает делать удобные и красивые схемы баз данных
Вам тут чуть выше про draw.io написали, от тех же разработчиков есть mermaid.js
Пример реализации: GenieLamp
Есть также инструменты two-way, например ModelMaker: интегрирован в IDE, UML постоянно синхронизирован с кодом, менять программу можно с обоих сторон.
Основная проблема UML — расположение взаимосвязанных структур на плоскости.
С одной стороны, трудно охватить взглядом, с другой стороны связи накладываются друг на друга и перепутываются.
Судя по детективным фильмам, наиболее всего они помогают при анализе криминальных ситуаций.
PS Я не противник UML, но все же код писать и читать легче
Диаграммы классов, в основном, бесполезны. Дело в том, что во многих языках программирования есть свои особенности, которые в UML не предусмотрены, и свои традиции реализации тех или иных паттернов. И при составлении диаграммы классов для них приходится сначала декомпозировать специфичные для языка вещи на элементарные сущности UML — а потом, при чтении диаграммы, мысленно собирать их обратно.
Скажем, в тех же C++ или Rust широко используется статический полиморфизм — а значит, вместо интерфейсов или базовый классов надо как-то показывать на диаграмме концепты и протоколы. Их еще и в языке нет — но в спецификации они должны уже быть...
Или взять в том же C++ лямбды. Формально это аж целый класс с одним методом, к тому же наследующий std::function<...>. Но в коде лямбда — всего лишь функция с квадратными скобками вместо имени...
То же самое касается и диаграмм деятельности: в коде у нас есть циклы, а на диаграммах деятельности приходится делать их через аналог goto.
Хотя если добавить на диаграмму деятельности "дорожки" — то это уже получается довольно полезная диаграмма, поскольку на ней можно увидеть алгоритм работы распределенной системы целиком.
А диаграмма деятельности с «дорожками» и «циклами» — это диаграмма последовательности. Посмотрите в конец статьи planerka.info/item/diagrammy-posledovatelnosti
Нее, это разные вещи. Диаграмма последовательности показывает лишь один из вариантов развития событий, а диаграмма деятельности — сам алгоритм.
На диаграмме последовательности не бывает ветвлений, зато на ней хорошо видны фоновые задачи.
В диаграмме последовательности, посмотрите оператор «alt».
И диаграмма деятельности тоже поддерживает параллельные процессы.
По вашей ссылке:
Общая проблема диаграмм последовательности заключается в том, как отображать циклы и условные конструкции.
Прежде всего надо усвоить, что диаграмма последовательности для этого не предназначе на. Подобные управляющие структуры лучше показывать с помощью диаграммы деятельности или собственно кода.
Что же до поддержки диаграммами деятельности параллельных процессов — то там не видна их относительная продолжительность.
Просто конкретная диаграмма, как уже высказались, имеет смысл для того, чтобы показать то или иное — общий алгоритм (одной подсистемы, или высокоуровневой системы — разные случаи) или может состояние системы в нужный момент (со всеми объектами, или срез из нужного множества объектов)
Каким образом сказанное вами опровергает возможность добавить "дорожки" на диаграмму деятельности и НЕ получить при этом диаграмму последовательности?
Если вам нужен алгоритм, во всех его проявлениях, т.е не один тест вариант, нужно юзать Диаграмму деятельности.
Есть помоему комбинированная, где есть и дорожки, и полный алгоритм, но это 3я (точно не 1я и не 2я).
p.s. извиняюсь если это выглядело как опровержение, или если тут так принято, писать коменты только ради опровержений. Я просто уточняю — что имею в своем опыте.
И в моей практике «Зачастую на практике важны имено конкретные варианты развития» это значит что «зачастую», а другую диаграмму в принципе и не юзал почти никогда, за не надобностью, но смысл в ней есть конечно, просто обычно — нужны конкретные варианты, и уже их них можно составить прямо сразу Код, минуя диаграмму деятельности, потому что каждый из тест вариантов — можно проверять прям по нужной диаграмме Последовательности.
И при составлении диаграммы классов для них приходится сначала декомпозировать специфичные для языка вещи на элементарные сущности UML — а потом, при чтении диаграммы, мысленно собирать их обратно.
То что вы конвертируете какието сущности из UML напрямую в язык-прогр, или наоборот из языка-прогр в UML — только подтверждает то, что вы используете ОДИНАКОВЫЙ УРОВЕНЬ и для UML и для языка-прогр, что не имеет никакого смысла на практике. Имеет смысл РАЗНЫЙ УРОВЕНЬ, например это planerka.info/item/diagrammy-posledovatelnosti написанное человеческим языком и там видно на прилично-высоком-уровне что делается каждый из модулей (или даже людей).
Осталось понять, как подобный разный уровень применим к диаграммам классов...
Т.е использовать диаграммы: Последовательности, Прецедентов, state-machine — самые распространенные, и с их помощью можно именно высокий уровень задачи описать, и иногда детали реализации (но не скатиться в очень детальность).
Хотя та же state-machine (состояний) может быть применена как для высокого уровня, например юзер в состоянии = меню, кликает «в бой» и условно если есть соперники — сервер его помещает в бой сразу, или если нет соперников — ставит в очередь ожидания, и потом когда начнется состояние = бой, он может проиграть или выиграть или ливнуть из игры.
Но может быть и низкий уровень вроде описания работы TCP с его syn\ack и состояниями — что обычно редко когда нужно, но всетаки если и нужно — это низкий или средний уровень, думайте сами — нужны ли они вам, мне — обычно нет.
Т.е разница ключевая тут — сколько еще уровней-ПОД находится, и сколько кода надо написать… если много кода еще предстоит написать (т.е скрыто, за пределами диаграммы) — имхо нормальная диаграмма, и предназначенная для overview\обучения\обсуждения, а вот если кучу подробностей — так это почти уровень кода, и дублирование работы.
Если комментировать ваш первый тезис
Диаграммы классов, в основном, бесполезны.
Тогда я согласен по большей части
Проблема с UML в том, что надо, чтобы его понимал еще кто-то, кроме меня. :)
На практике получается так: BDD, DDD и современные IDE вполне решают проблему "разобраться с архитектурой", а при обсуждении — псевдокод и квадратики со стрелочками в свободной форме, отдаленно напоминающие UML.
Если задача — обсудить какието сложные вещи — которые вы не можете быстро сами додумать (потому что не спец, потому что не вы ответственный, потому что надо доказать другим что оно будет или не будет работать) — конечно любой способ донесения информации хорош, но если это происходит часто — все просто научатся UML пользоваться в вашей среде, и далее будет понятно.
А если это на один раз — доносите человеческим языком, задавайте вопросы, обсуждайте — как угодно, но это не смысл и не use-case для UML, и это не его минус.
Те же слова, написанные русскими буквами, зачастую не понятны людям, они задают уточняющие вопросы, чтото переспрашивают… это же не минус русского языка правда?
1. Способ графического отображения идей для принятия решений.
2. Способ графической примитивной фиксации решений, которая устаревает.
— кому это нужно
— и что он с этим делает
Вот скажем, строительная документация нужна на всех этапах строительства и эксплуатации здания самым разным службам. Кто не хочет сложностей, поддерживает ее в актуальном состоянии.
Аналогично с документация для ИТ-систем. Если ею пользуются несколько команд на регулярной основе, то поддерживать в актуальном состоянии ее становится выгодно. UML — всего лишь способ описания, который понятен большинству. И команда с удовольствием обновляет документацию, потому что для нее очевидна выгода актуальной документации.
Например: сначала архитектор создает скелет — условно диаграмму последовательностей из клиента-сервера-юзера и там отображаются кто кому какие ВЫСОКО-УРОВНЕВЫЕ команды посылает, в этом и смысл, не нужно все детали отображать. А если нет деталей — не возможна кодо-генерация, ну можно условно шаблон сгенерировать из классов и пары методов, а потом всеравно начинку (код кучи if-ов и методов и параметров).
Другой пример: рисуется диаграмма state-machine — она СРЕДНЕ-УРОВНЕВАЯ — и предназначена для решения конкретной задачи, условно там есть Init (где начало) и переходу при кликах юзера в UI, в зависимости от условия (if просто другим языком) делается переход в состояние, в котором и UI будет другой и команды перехода из-в будут другими, т.е конкретный алгоритм можно сказать. Но это все еще НЕ-КОД, т.е конкретные детали всеравно придется кодить (вызывать конкретные методы\функции, передавать нужные параметры, рисовать чтото в UI, отслеживать события из UI от юзера и т.п).
Смысл этих уровней — есть. Но он должен быть осмысленным.
Т.е не так что «сделаем диаграммы на все что у нас в проекте будет — а код сгенерируем» — не сработает т.к. вы диаграммами высокого уровня хотите сгенерить код низкого уровня? это же не верно… просто потому что вам в момент проектирования ВЫСОКОГО-уровня неважно(!) что на низком будет, пусть там хоть Set\List\Dict будет, хоть цикл с полным перебором, и какой там UI и какие события — не важно.
В обратную сторону «напишем код — тулза нам сгенерит документацию на UML» частично может работать, но это для ОБУЧЕНИЯ, т.е входа новых лбюдей в этот проект, или написания книжек по паттернам проектирования (это тоже важно).
Зачастую нужен баланс и понимание того что мы сделаем ВЫСОКИЙ уровень системы клиент-серв (например, если у нас эта задача), сделаем СРЕДНИЙ уровень для ПОДСИСТЕМЫ UI с диаграммой состояний, сделаем еще СРЕДНИЙ уровень для ПОДСИСТЕМЫ рендернга 3D графиик на клиенте, и потом еще напишем кучу НИЗКО-уровневой реализации во многих подсистемах (кучу if, имен методов и параметров, их типов, кучу enum и т.п — все это описывать в ВЫСОКО-уровеном UML\диаграмме зачастую нет смысла, если только они не ключевые в понимании системы).
Где-то (уже не помню) читал о том что мышление наше МНОГО-УРОВНЕВОЕ, но вот тулз для поддержки этого мышления в программировании — пока нет, полноценных по крайней мере, т.е то что есть в виде отдельных кодо-генераторов — уже описал — слабо помогает.
Идеально это если бы были и work-flow (как мы делаем, инструкции для программистов по проектированию) и чем — какими тулзами \ генераторами \ IDE, и как все это в общую систему свести.
Были такие попытки в духе RUP… на сколко знаю — не идеально.
ДУМАТЬ УРОВНЯМИ вам никто не мешает. Так и нужно думать. Т.е. создавать (хоть в голове и потом забыть \ хоть текстом и потом выкинуть, ну можно и задокументировать) какойто один высокий уровень, проектировать постепенно и волзвратно средние уровни, и чтобы все это не устаревало — всеравно как-то нужно поддерживать ЗНАНИЯ. Т.е ключевое тут — НЕ-КОД, НЕ-UML, а ЗНАНИЯ! Т.е программист, когда он решает даже потом вернуться к задаче — не код должен дублировать в виде документации, или документацию пере-генерировать в код и потом фиксить это, ему ЛЮБЫМ СПОСОБОМ надо поддерживать РАЗНЫЕ УРОВНИ ЗНАНИЙ. Пока способов поддержки УРОВНЕЙ — мало, и все не очень… т.е ктото будет лениться писать документацию (даже комменты в коде — помогают, если они на ДРУГОМ УРОВНЕ), потом лениться ее править, и они хотят чтобы чтото за них это сделало… нет такой тулзы, чтобы вам сделать много УРОВНЕЙ — по вашему желанию. Поэтому зачастую программисты поддерживают ТОЛЬКО КОД. Ну чтобы единый источник был. Они думают что это ИДЕАЛ, чтоб не дублировать документацию. Но смысл всеравно остается — эти УРОВНИ они должны гдето брать — когда надо пофиксить чтото, добавить функционал, обучить когото — вспомнинать приходиться из головы, или придумывать\ проектировать заного.
Когда проектируешь архитектуру своего приложения, а не просто по приколу кодишь, то без диаграмм никуда.
А лучше UML я пока ничего не видел.
Зачем нам UML? Или как сохранить себе нервы и время