
This post is a small abstract of full-scaled research focused on keyword recognition. Technique of semantics extraction was initially applied in field of social media research of depressive patterns. Here I focus on NLP and math aspects without psychological interpretation. It is clear that analysis of single word frequencies is not enough. Multiple random mixing of collection does not affect the relative frequency but destroys information totally — bag of words effect. We need more accurate approach for the mining of semantics attractors.
According to Relational Frame Theory (RFT) bidirectional links of entities are basic cognitive elements. The hypothesis of bigram dictionary has been tested. We explored top Russian speaking Wall Of Help. 150,000 visits per day. Response/request collections have been parsed: 25,000 of records in 2018.
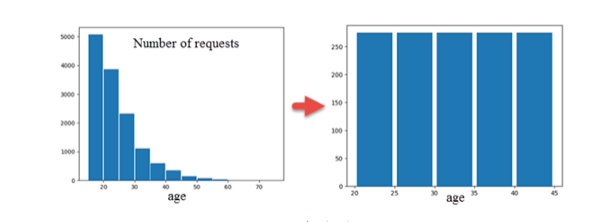
Text cleaning included age/sex/text and message length standardizations. Sex standardization was reached by [name — sex] recognition. Morphological cleaning and tokenization allowed getting nouns in standard form. Vocabulary of bigrams with corresponding frequences was mined. Bigram sets are ordered by frequency and normalized to equal volume in both groups by cutoff criteria. Each group, Request/Responce is characterized by unique bigram matrix. Increase of information as inverse to Shannon entropy is shown: 30% of increment. I(3)-I(2)=6% for the 3-grams, [H(4)-H(3)]=2% and less than 1% for N>4.
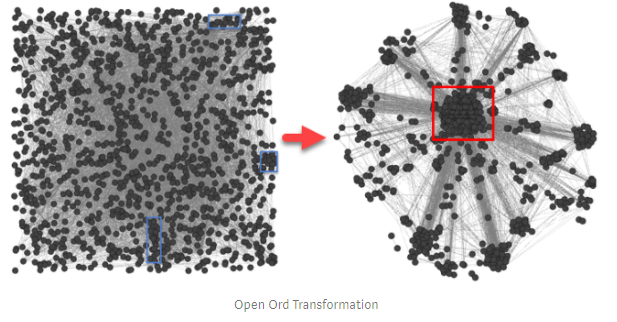
Bigram matrix was used as a generator of weighted undirected 3D graph. Сonversion was implemented by Open Ord force-directed layout algorithm. It makes transformation from 2D matrix to the tree based topology. Weight of each node corresponds to the single word frequency (not shown) while edge length is the inverse function of bigram frequency. I considered betweennes centrality (BC) and modified closest neighbours. Entities with extra high BC may be considered as information hubs, which influence the semantics: removal of these entities affects information mostly. Closest neighbours are based on co-occurrence frequency analysis. I considered modified neighbour ordering. BC of neighbour inverse to co-occurrence distance (CD) was used as weighting function: BC/CD.

We investigated closest neighbors in the vicinity of selected BC Root: #Life. #Man (№1) value is almost fused with #Life attractor. #Procreation (№2), #Family (№3) are next closest entities with lower BC/CD grade. Responce values are represented in the following order: #Man №1, #Job №2, #Procreation №3. It should be noticed that topic bias is obviously present in responce group. However separation of personal and group values (#Man vice #Life) is remarkable inspite of topic noise. Graph was based on 10,000 most frequent bigrams: 44% of data. However the top 5 entities ranked by BC/CD do not change after rescaling to 50% and 88% of bigram dictionary.
The considered results correlate with empirical observations in psychology. Consequently they preliminarily confirm selected algorithm of BC/CD ranging for recognition of semantics attractors. It is convinient if you deal with Big Noisy Text/Speech Data. It may be used for mining of keywords in relation to selected entity or in absolute terms. You may read more here. The instrument may have applications in HR evaluation as well. Authors conduct relevant research in English speaking segment and look for collaboration. The full version of research is pending in the peer reviewed journal. However you may ask draft upon the personal request. Thank you.
I would like to thank Dmitry Vodyanov for the fruitful discussion.
