Have you thought about the influence of the nearest metro to the price of your flat?
What about several kindergartens around your apartment? Are you ready to plunge in the world of geo-spatial data?
What is all about?
In the previous part, we had some data and tried to find a good enough offer on a real estate market in Yekaterinburg.
We had arrived at a point when we had an accuracy on cross-validation near 73%. However, every coin has 2 sides. And 73% accuracy it is 27% of error. How could we make that less? What is the next step?
Spatial data is coming to help
What about getting more data from the environment? We can use geo-context and some spatial data.
Rarely people spend their entire life at home. Sometimes they go to shops, take kids from daycare. Their children grow up and go to school, university, etc.
Or… sometimes they need medical help and they are looking for a hospital. And a very important thing is public transport, metro at least. In other words, there are many things near there, that have an impact on pricing.
Let me show you a list of them:
- Public transport stops
- Shops
- Kindergartens
- Hospitals/medical institutions
- Educational institutions
- Metro
Visualization for new data
After getting that information from different sources, I made a visualisation.
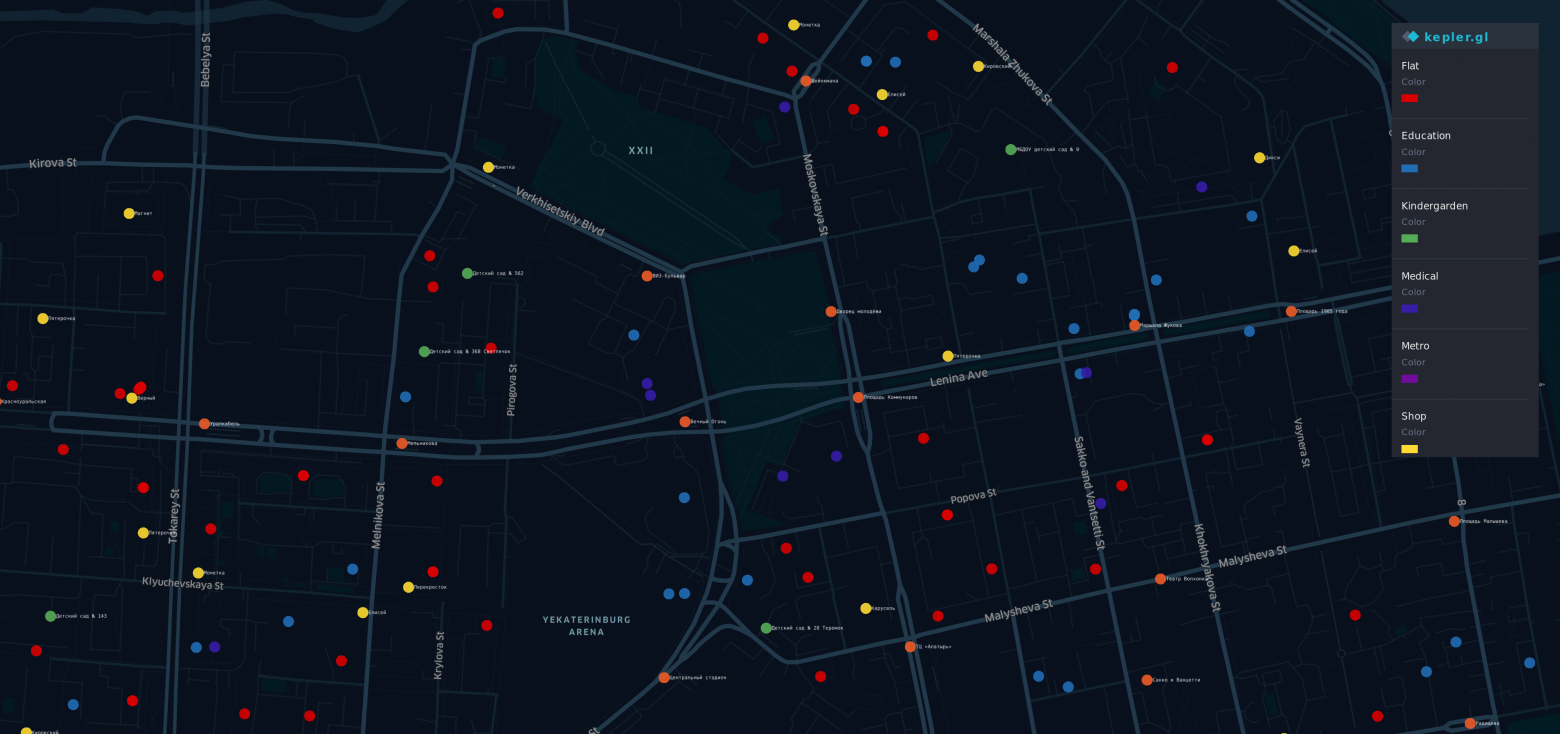
There are some points on the map the most prestigious (and expensive) district of Yekaterinburg.
- Red points - flats
- Orange - stops
- Yellow - shops
- Green - kindergartens
- Blue - education
- Indigo - medical
- Violet - Metro
Yes, a rainbow is here.
Overview
Now we have a dataset which is bounded with geodata and has some new information
df.head(10)
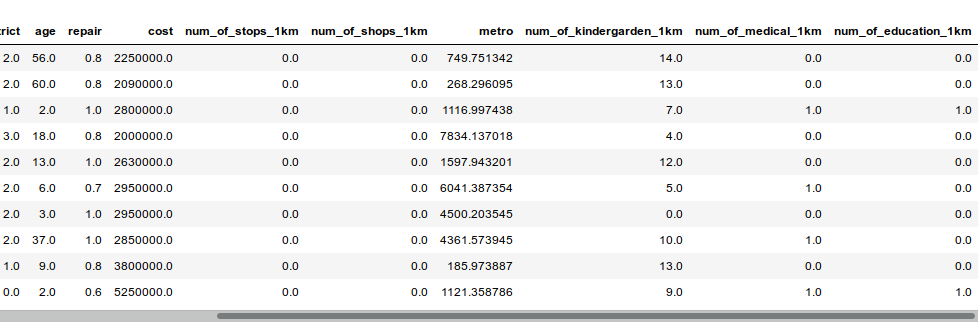
df.describe()

A good old model
Try the same way as before
y = df.cost X = df.drop(columns=['cost']) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2,random_state=42)
Then we train our model again, cross our fingers and try to predict the price of flat again.
from sklearn.linear_model import LinearRegression regressor = LinearRegression() model = regressor.fit(X_train, y_train) do_cross_validation(X_test, y_test, model)

Hmm… it looks better than the previous result with 73% of accuracy.
What about trying of interpretation? Our previous model had a good enough ability to explain the flat price.
estimate_model(regressor)
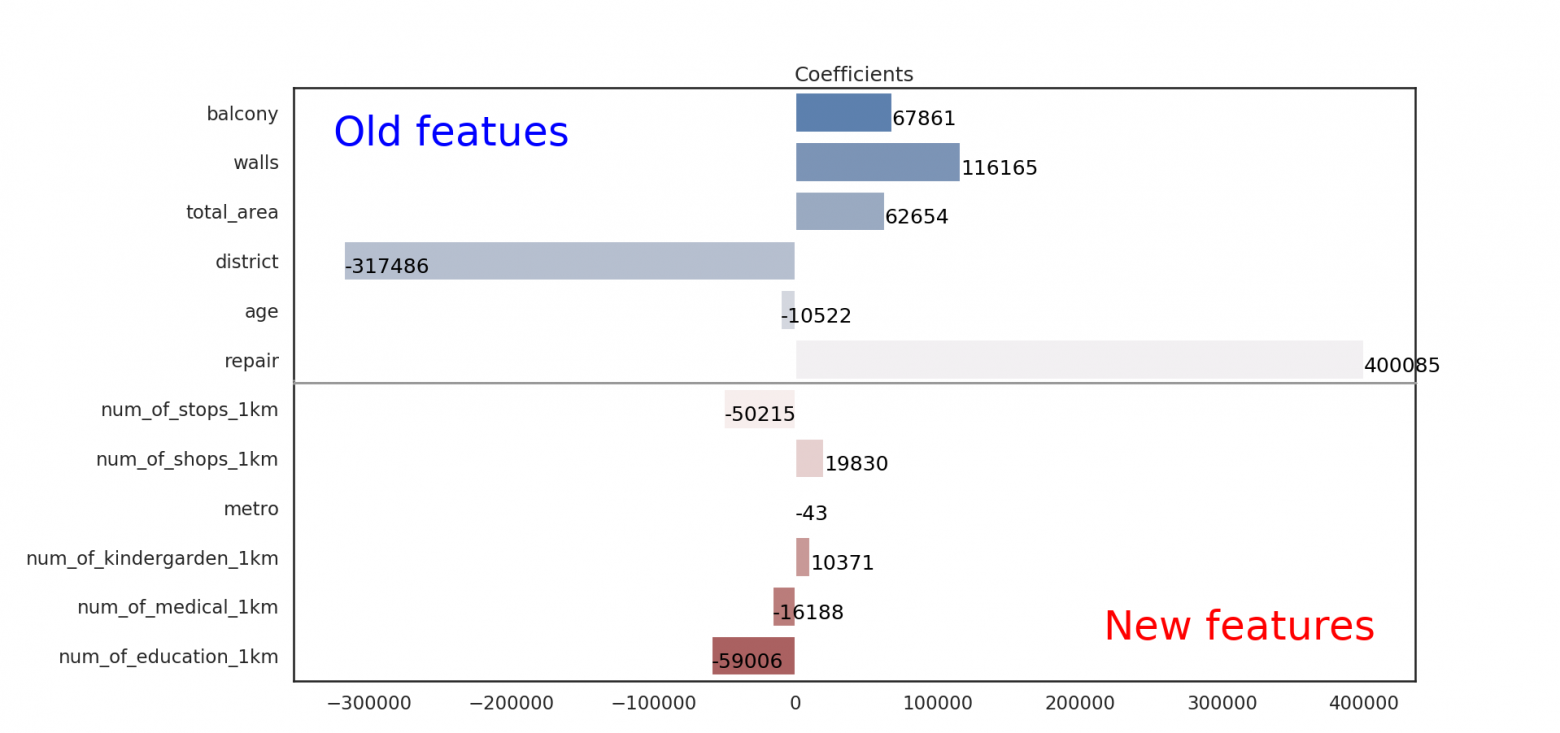
Oops… Our new model works well with old features, but the behaviour with new ones seems odd.
For example, the bigger number of educational or medical institutions leads to a decrease in the price of flat. Accordingly, the number of stops nearby flat is an identical situation and it should gain an additional contribution to the flat price.
The new model is more accurate, but it does not fit with real life.
Something is broken
Let consider what happened.
First of all — I want to remind you that key feature of our linear regression is… erm… linearity. Yes, Captain Obvious is here.
If your data is compatible with an idea "The bigger/lease is X the bigger/lease will Y" - linear regression will be a good tool. But geodata is more complex than we expected.
For instance:
- When near your flat is a bus stop it is good, but if the amount of them is around 5, it leads to a noisy street and people would like to avoid to buy a flat nearby.
- If there is a university, it should have a good influence on price,
at the same time a crowd of students near your home is not so pleased if you are not a very sociable person. - Metro near your home is good, but if you live in one hour by foot
from the nearest metro - it should not make sense.
As you see - it depends on many factors and points of view. And the nature of our geodata is not linear, we can not extrapolate the impact of them.
At the same time, why does model with bizarre coefficients work better than the previous one?
plot.figure(figsize=(10,10)) corr = df.corr()*100.0 sns.heatmap(corr[['cost']], cmap= sns.diverging_palette(220, 10), center=0, linewidths=1, cbar_kws={"shrink": .7}, annot=True, fmt=".2f")
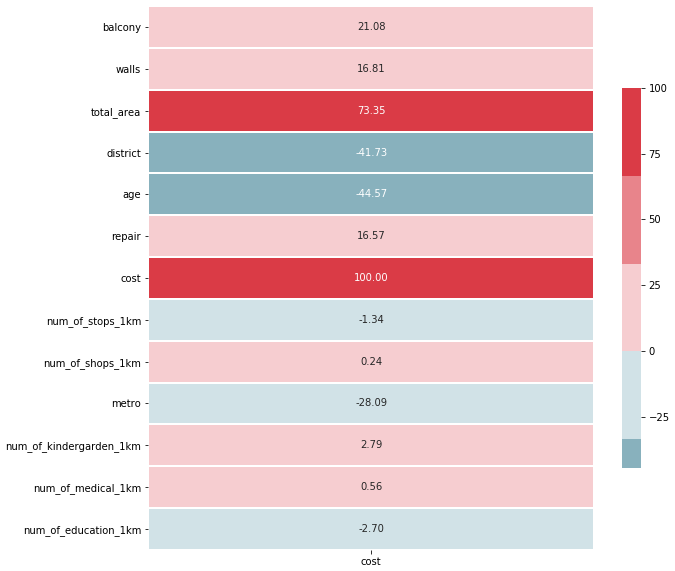
It looks interesting. We have seen the similar picture in the previous part.
There is a negative correlation between distance to the nearest metro and price. And this factor has an impact on accuracy more than some older ones.
Meanwhile, our model work messy and don not see dependencies between aggregated data and target variable. The simplicity of linear regression has its own limits.
The king is dead, long live the king!
And if a linear regression is not suitable for our case, what can be better? If only our model could be "smarter"…
Fortunately, we have an approach which should better because of it more… flexible and has a built-in mechanism "do if that do this else do that".
Decision Tree appears on the scene.
from sklearn.tree import DecisionTreeRegressor A decision tree can have a different depth, usually, it works well when depth is 3 and bigger. And the parameter of max depth has the biggest influence on the result. Let's do some code for checking depth from 3 to 32 data = [] for x in range(3,32): regressor = DecisionTreeRegressor(max_depth=x,random_state=42) model = regressor.fit(X_train, y_train) accuracy = do_cross_validation(X, y, model) data.append({'max_depth':x,'accuracy':accuracy}) data = pd.DataFrame(data) ax = sns.lineplot(x="max_depth", y="accuracy", data=data) max_result = data.loc[data['accuracy'].idxmax()] ax.set_title(f'Max accuracy-{max_result.accuracy}\nDepth {max_result.max_depth} ')
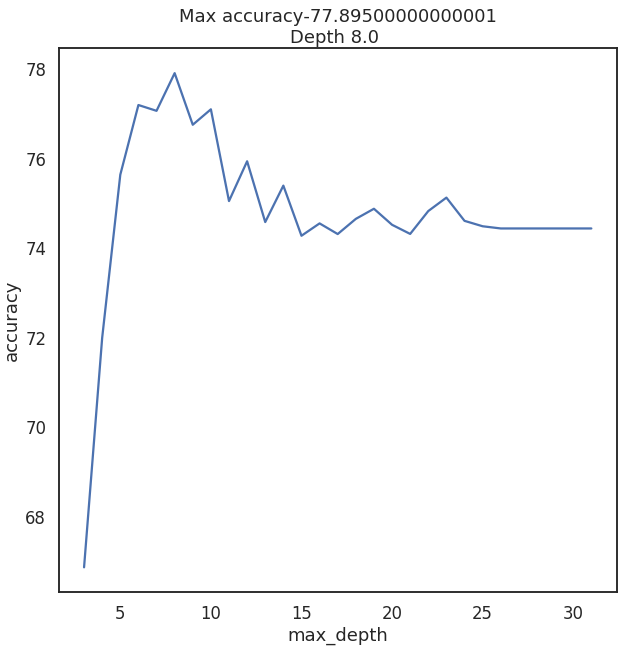
Well… for a situation when the max_depth of a tree is equal 8 the accuracy is above 77.
And it would be a good achievement if we did not think about the limits of that approach. Let have a look at how it will work with max_depht=2
from IPython.core.display import Image, SVG from sklearn.tree import export_graphviz from graphviz import Source 2_level_regressor = DecisionTreeRegressor(max_depth=2, random_state=42) model = 2_level_regressor.fit(X_train, y_train) graph = Source(export_graphviz(model, out_file=None , feature_names=X.columns , filled = True)) SVG(graph.pipe(format='svg'))
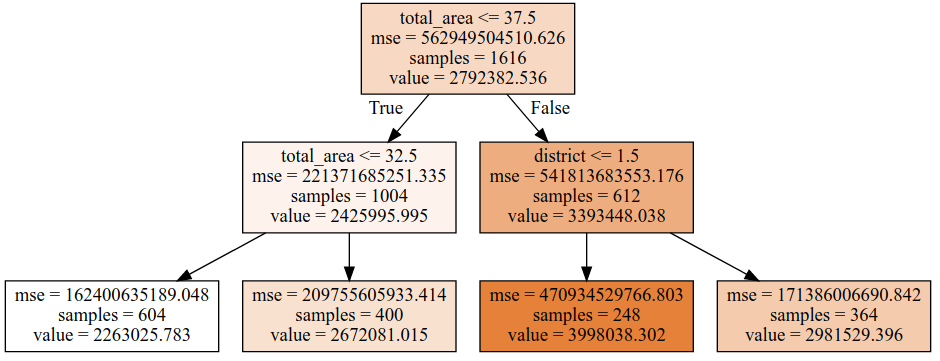
On this picture, we can see that there are only 4 variants of prediction. When you use DecisionTreeRegressor, it works differently than Linear Regression. Just differently. It does not use a contribution of factors (coefficients), instead of that DecisionTreeRegressor uses "likelihood". And the price of a flat will be the same as has the flat most similar on predicted.
We can show it by predicting our price with that tree.
y = two_level_regressor.predict(X_test) errors = pd.DataFrame(data=y,columns=['errors']) f, ax = plot.subplots(figsize=(12, 12)) sns.countplot(x="errors", data=errors)
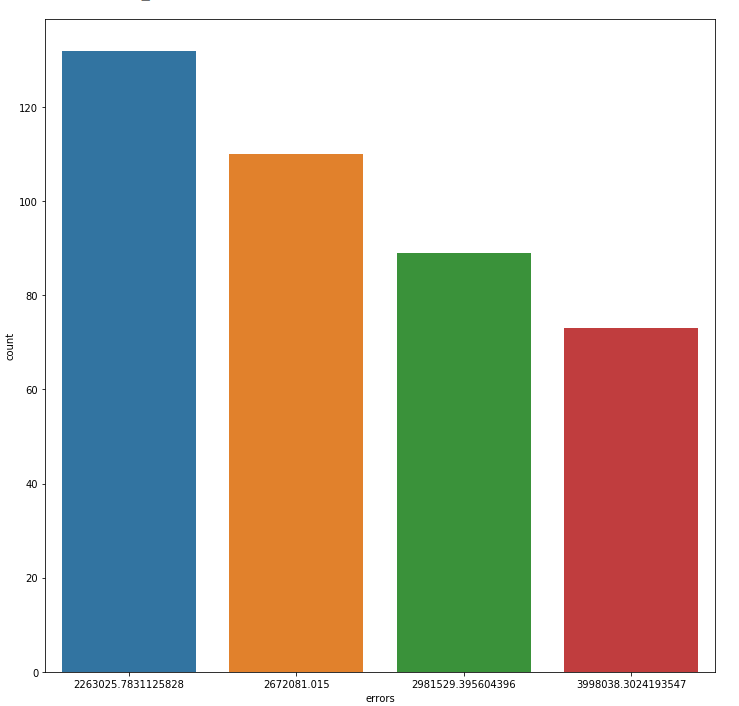
And every your prediction will match with one of these values. And when we are using max_depth=8 we can expect no more than 256 different variants for over than 2000 flats. Maybe it is good for classification's issues, but it is not flexible enough for our case.
Wisdom of crowd
If you try to predict the score on the final of World Cup - there is a big probability you will be mistaken. At the same time, if you ask for opinion all judges on Championship - you will have better chances to guess. If you ask independent experts, trainers, judges and then do some magic with answers - your chances will increase significantly. Looks like an election of a president.
An ensemble of several "primitive" trees can give more than each of them. And RandomForestRegressor is a tool which we will use
First of all, let's consider basic params - max_depth, max_features and a number of trees in the model.
Number of trees
In accordance with "How Many Trees in a Random Forest?" the best choice will be 128 trees. Further increasing of the number of trees does not lead to significant improvement in accuracy, but increase time for training.
Maximal number of features
Right now our model has 12 features. Half of them is old ones which are related to with features of flat, other related to geo-context. So I decided to give a chance for each of them. Let it be 6 features for a tree.
Maximal depth of a tree
For that parameter, we can analyse a learning curve.
from sklearn.ensemble import RandomForestRegressor data = [] for x in range(1,32): regressor = RandomForestRegressor(random_state=42, max_depth=x, n_estimators=128,max_features=6) model = regressor.fit(X_train, y_train) accuracy = do_cross_validation(X, y, model) data.append({'max_depth':x,'accuracy':accuracy}) data = pd.DataFrame(data) f, ax = plot.subplots(figsize=(10, 10)) sns.lineplot(x="max_depth", y="accuracy", data=data) max_result = data.loc[data['accuracy'].idxmax()] ax.set_title(f'Max accuracy-{max_result.accuracy}\nDepth {max_result.max_depth} ')
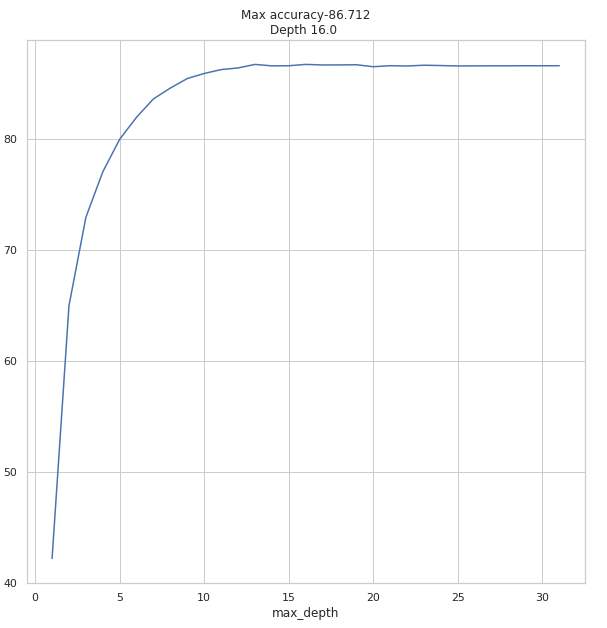
Whoa… over 86% accuracy on max_depth=16 against 77% on one design tree. It looks amazing, is not it?
Conclusion
Well… now we have a better result in prediction than previous ones, 86% is near the finish line. The last step for checking - let look at feature importance. Did geodata give any benefit to our model?
feat_importances = model.feature_importances_ feat_importances = pd.Series(feat_importances, index=X.columns) feat_importances.nlargest(5).plot(kind='barh')
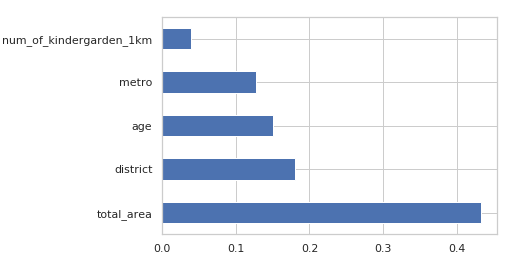
Some old features still have affected on the result. At the same time distance to the nearest metro and kindergartens also has affected. And it sounds logical.
Without a doubt, geodata helped us to improve our model.
Thanks for reading!
P.S.
Our journey is not finished yet. 86% accuracy is a tremendous result for real data. Meanwhile, here is a small gap between 14% and 10% of mean error, which we expect. In the next chapter of our story, we will try to overcome this barrier or at least to decrease this error.
There is the IPython-notebook
