Экспериментировать с библиотекой Trax и архитектурой трансформер оказалось крайне увлекательно. Предыдущая статья была про саммаризатор. В этой хочу рассказать о том, как я учил трансформер общаться на русском языке.
Сравнительно простого чат-бота можно построить на базе языковой модели, которая умеет прогнозировать следующее слово по предыдущим, и которую несложно сделать, используя Трансформер-декодер по аналогии с GPT. В этом случае диалог формируется как связный неструктурированный текст. Чтобы превратить этот текст в чат, нужно вмешиваться в процесс генерации, добавляя реплики пользователя. Но обо всём по порядку.
В качестве фреймворка я использовал библиотеку Trax.
Trax — библиотека глубокого обучения с фокусом на понятный код и быстрые вычисления. Библиотека активно развивается и поддерживается командой Google Brain. Trax использует tensorflow и является одной из библиотек в его экосистеме, работает на CPU, GPU и TPU. На Google Colab TPU проверил. Нужно следить, чтобы количество текстов в пакете при обучении было кратно восьми.
Для модели чат-бота я решил попробовать новую архитектуру — Reformer. Это трансформер, который может работать с длинными текстами размером с хорошую книгу буквально на одном ускорителе. Reformer кардинально снижает используемый объем памяти. Это достигается за счет двух вещей. Во-первых, у Reformer более эффективный в смысле памяти механизм внимания. Во-вторых, реверсивная схема вычислений, позволяющая отказаться от хранения значений активации для расчета градиента. Детали здесь на английском, а здесь перевод заметки из Google AI Blog.
Мотивация: не то что бы у меня были какие-то гигантские диалоги, но очень хотелось посмотреть как Reformer ведет себя на Google Colab и как учится в сравнении с Transformer.
Оказалось, не зря.
"Танцы с бубном" вокруг Reformer
В Trax версии 1.3.7 (устанавливается через pip) в Reformer не удается загрузить веса предобученной модели. Это ошибка была исправлена в версии 1.3.4 и снова проявилась в 1.3.7. На форуме предложили пока использовать версию 1.3.6. Так и сделал, тут же возникла проблема с библиотекой T5, части которой Trax использует для работы с данными. Откатив и T5 к предыдущей версии, я «потерял» trax.data.tokenize, который отказался работать с последней версией sentencepiece. Тут я бросил путешествовать в историю пакетов и просто сегментировал всё заранее при помощи SentencePieceProcessor.
Данные
Нужный набор данных я скачал на Яндекс.Толока. Он называется «Toloka Persona Chat Rus» и его можно использовать в некоммерческих целях с упоминанием источника. Упоминаю: Ребята из Яндекс.Толока — вы большие молодцы!
Набор содержит 10000 русскоязычных диалогов на общие темы с возможностью фильтрации по профилю пользователя. Можно было бы например отфильтровать диалоги, где один из пользователей женщина, но я посчитал, что их и так не очень много. Диалоги представлены в виде HTML-текста, пришлось потратить некоторое время на чистку.
Примеры текста в процессе
В наборе данных:
<span class=participant_2>Пользователь 2: Привет) расскажи о себе</span><br /><span class=participant_1>Пользователь 1: Привет) под вкусный кофеек настроение поболтать появилось<br />)</span><br /><span class=participant_2>Пользователь 2: Что читаешь? Мне нравится классика</span><br /><span class=participant_2>Пользователь 2: Я тоже люблю пообщаться</span><br /><span class=participant_1>Пользователь 1: Люблю животных, просто обожаю, как и свою работу)</span><br /><span class=participant_1>Пользователь 1: Я фантастику люблю</span><br /><span class=participant_2>Пользователь 2: А я выращиваю фиалки</span><br />...
После очистки:
2: Привет) расскажи о себе
1: Привет) под вкусный кофеек настроение поболтать появилось )
2: Что читаешь? Мне нравится классика
2: Я тоже люблю пообщаться
1: Люблю животных, просто обожаю, как и свою работу)
1: Я фантастику люблю
2: А я выращиваю фиалки...
2: И веду здоровый и активный образ жизни!
После склейки реплик:
2: Привет) расскажи о себе
1: Привет) под вкусный кофеек настроение поболтать появилось )
2: Что читаешь? Мне нравится классика Я тоже люблю пообщаться
1: Люблю животных, просто обожаю, как и свою работу) Я фантастику люблю
2: А я выращиваю фиалки И веду здоровый и активный образ жизни!
Некоторые диалоги начинаются со второго пользователя, там нужна замена идентификаторов:
1: Привет) расскажи о себе
2: Привет) под вкусный кофеек настроение поболтать появилось )
1: Что читаешь? Мне нравится классика Я тоже люблю пообщаться
2: Люблю животных, просто обожаю, как и свою работу) Я фантастику люблю
1: А я выращиваю фиалки И веду здоровый и активный образ жизни!
Для обучения модели требуется неструктурированный текст, примерно такой:
'1: Привет) расскажи о себе 2: Привет) под вкусный кофеек настроение поболтать появилось ) 1: Что читаешь? Мне нравится классика Я тоже люблю пообщаться 2: Люблю животных, просто обожаю, как и свою работу) Я фантастику люблю 1: А я выращиваю фиалки И веду здоровый и активный образ жизни! 2: Ух ты, интересно. 1: Ты случайно не принц на белом коне? Я его очень жду.. 2: А у меня из хобби каждую неделю тусить с моим лучшим другом) STOP'
Два момента:
Идентификаторы «Пользователь 1:» и «Пользователь 2:» в исходном тексте пришлось сократить до «1:» и «2:», чтобы они не разбивались на два токена.
В конец каждого диалога я добавил слово STOP, которое кодируется одним токеном. Это нужно для остановки декодера при генерации диалога.
Справедливо решив, что для модели с несколькими десятками миллионов параметров десяти тысяч диалогов будет маловато, я сделал еще 36 тысяч, просто «откусывая» от начала диалогов по четному количеству реплик так, чтобы оставалось не меньше восьми. В общем, и этого не очень-то много, в связи с этим вопрос: где взять еще диалогов на русском?
Процесс подготовки данных представлен на схеме:

В качестве модели для сегментации текста, как и в эксперименте с саммаризатором, я использовал Byte Pair Encoding (BPE) из библиотеки sentencepiece. Размер словаря 10k токенов.
Пример текста после сегментации
['▁1:', '▁Привет', ')', '▁расскажи', '▁о', '▁себе', '▁2:', '▁Привет', ')', '▁под', '▁вкусный', '▁кофе', 'ек', '▁настроение', '▁поболтать', '▁появи', 'лось', '▁)', '▁1:', '▁Что', '▁читаешь', '?', '▁Мне', '▁нравится', '▁класси', 'ка'...
... '▁Ты', '▁случайно', '▁не', '▁прин', 'ц', '▁на', '▁б', 'елом', '▁ко', 'не', '?', '▁Я', '▁его', '▁очень', '▁жду', '..', '▁2:', '▁А', '▁у', '▁меня', '▁из', '▁хобби', '▁каж', 'дую', '▁неделю', '▁ту', 'сить', '▁с', '▁моим', '▁луч', 'шим', '▁другом', ')', '▁STOP']
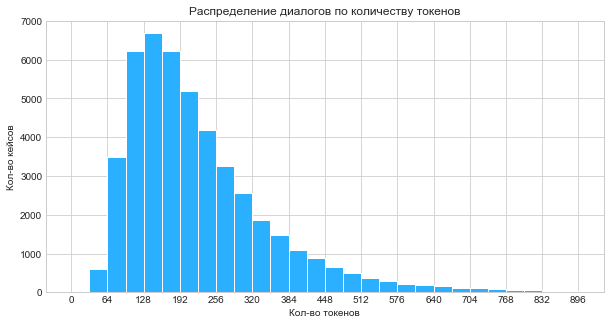
Размеры корзин для формирования пакетов фиксированной длинны выбирал по гистограмме. Решил отказаться от текстов короче шестидесяти четырех токенов.
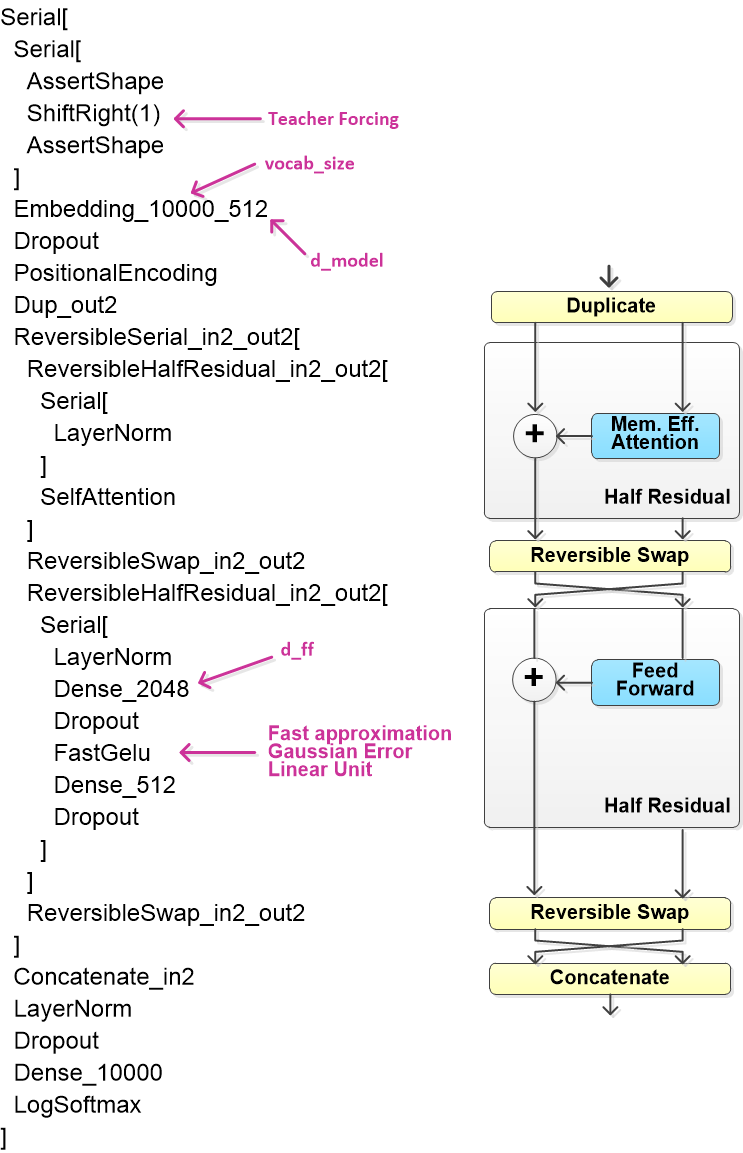
Модель
Модель Reformer создается несколькими строчками кода:
def ReformerLM(vocab_size=vocab_size, n_layers=6, mode='train',
attention_type=tl.SelfAttention):
model = trax.models.ReformerLM(
vocab_size=vocab_size,
n_layers=n_layers,
mode = mode,
attention_type=attention_type
)
return model
ChatModel = ReformerLM()У Reformer есть два собственных варианта реализации механизма внимания: Self Attention и LSH Attention. Первый экономит память, рассчитывая только отдельные сегменты матрицы весов внимания, хотя это по прежнему dot-product attention. Второй оценивает сходство векторов через локально-чувствительное хеширование (locality-sensitive hashing). LSH я еще не испытал, по идее должно работать быстрее, но нужно подбирать параметры хеширования.
За исключением размера словаря параметры модели взяты по умолчанию:
Шесть декодеров, в каждом восемь головок
Размер словаря: 10000
Размер векторного пространства: 512
Размер слоя прямого распространения: 2048
Вероятность выключения нейронов из обучения (dropout): 0.1
Схему модели можно вывести командой print(model).
Картинка в стиле «длиннокот» для одного декодер-блока
Обучение
В моей модели 35 млн. параметров, обучал сериями по 20 тысяч шагов. Каждая серия чуть больше двух часов. Всего восемь серий или 160 тысяч итераций. Загрузка весов для модели после очередной серии является стрессом, качество в этот момент нестабильно. Заметил это только когда «прикрутил» TensorBoard. Оказалось совсем несложно, формат логов стандартный.
TensorBoard в colab-ноутбуке:
%load_ext tensorboard
%tensorboard --logdir ../root/model/ # folder where train and eval logs...Кривые обучения для третьей и четвертой серии. Виден «стресс» на 40k.
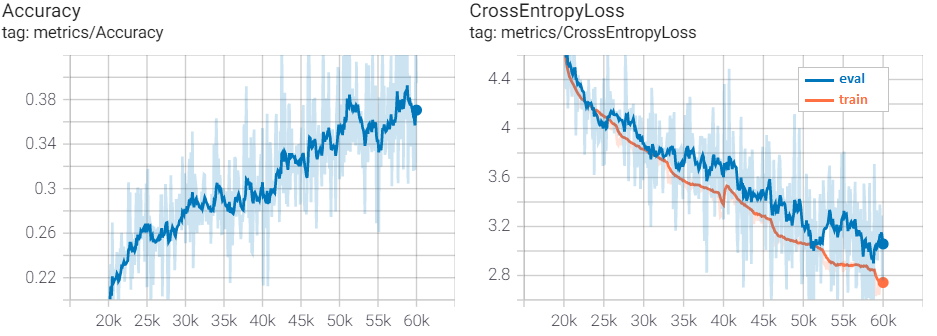
До 100k с шагом обучения 2e-4 модель учится сравнительно ровно. Потом проявляются переобучение и зависания в локальных минимумах. Нужно снижать шаг обучения и увеличивать dropout. Не рекомендую dropout больше 0.2. Обучение сильно замедляется, а качество откатывается на пару серий назад. Кривые для шестой и седьмой серии:
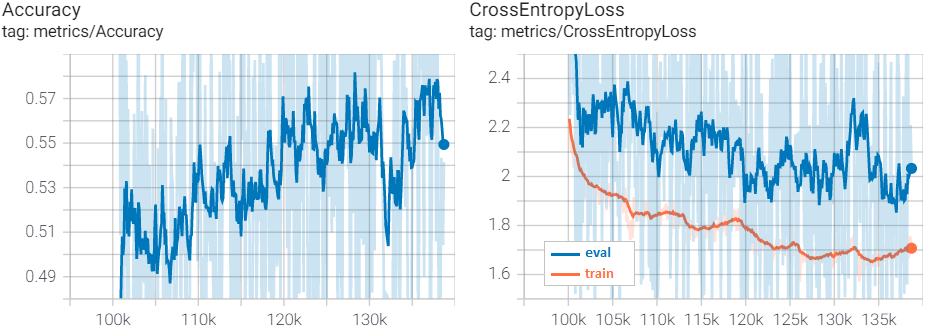
За восемь серий кросс-энтропийная ошибка (cross entropy loss) упала с 10 до 1.6-1.8, доля правильных ответов (accuracy) выросла в среднем до 60%.
Чат-бот
Для чат-бота нужен интерактивный декодер (не путать с декодер-блоком Reformer). Он должен принимать реплики пользователя и добавлять их в конец последовательности, на основе которой модель определяет следующий токен. В основе декодера — авторегрессионный генератор из библиотеки trax. Авторегрессионный означает, что следующий токен генерируется на основе текущего и всей предыдущей истории, а затем сам становится текущим. Чтобы очистить историю нужно установить исходное состояние модели, которое можно считать в переменную после инициализации и загрузки весов. Делается это простой инструкцией: STARTING_STATE = model.state и также потом устанавливается: model.state = STARTING_STATE.
Детали декодера
Декодер использует генератор в виде следующей конструкции, где start_sequence массив (id) токенов, с которого начинается генерация:
def output_gen(model, start_sequence, temperature, accelerate):
# Add batch dimension to array
input_batch = np.expand_dims(start_sequence, axis=0)
gen = trax.supervised.decoding.autoregressive_sample_stream(
model,
inputs=input_batch,
temperature=temperature,
accelerate=accelerate
)
return genПро температуру: temperature (float) — параметр, определяющий выбор следующего токена. Если 0, работает как argmax, выбирается наиболее вероятный токен (жадный декодер). Если больше нуля (до 1.) — семплирует из распределения вероятностей. Чем выше температура, тем более случайным будет выбор.
Про акселерацию: в Trax есть акселератор уровней. Он умеет обрабатывать пакетный ввод на нескольких устройствах ускорителя, если их больше одного. Если же устройство одно, использует JIT-компиляцию.
Упрощенно алгоритм декодера выглядит так (бот начинает первым):
Вход: модель, исходное состояние модели, параметры температуры и акселерации.
Выход: нет
....Инициировать start_sequence токенами приветствия (например, '1: Привет 2:')
....Инициировать реплику пустым списком
....Присвоить значения переменным:
....P1 ← токен первого пользователя ('1:')
....P2 ← токен второго пользователя ('2:')
....STOP ← токен останова
....Выполнять пока в start_sequence отсутствует токен STOP:
........Установить исходное состояние модели
........Если start_sequence заканчивается на Р2:
............Печатать реплику между последними P1 и P2 в start_sequence
............Принять и напечатать ввод от пользователя
............Добавить ввод пользователя к start_sequence
............Добавить P1 к start_sequence
........Конец Если
........Выполнять пока в реплике не появится токен P2:
............Итерировать авторегрессионный генератор с параметрами темп. и акселерации
............Добавить новый токен в реплику
........Конец цикла
........Добавить реплику к start_sequence
........Очистить реплику
....Конец цикла
Я сделал два декодера, бот — первый, пользователь — второй, и наоборот. Во всех примерах жадный декодер (температура = 0, см. спойлер "Детали декодера"). Если температура нулевая и вы пишите одни и те же реплики, диалог будет одним и тем же.
Пример почти идеального диалога:
(бот — первый, реплики выделены):
1: Привет
2: Привет
1: Как дела?
2: Отлично. А у вас?
1: Тоже хорошо Чем занимаешься?
2: Я фрилансер
1: Я учитель младших классов
2: Ух ты. Вам нравятся дети?
1: Да, у меня трое детей
2: Наверное нелегко с ними?
1: Да, мы с ними часто ходим в походы
2: Ого. Вы любите путешествовать?
1: Да, люблю
2: А я хочу в Японию. Это моя мечта
1: Что ты любишь?
2: Музыку и красное вино. А вы?
1: Мне нравится
2: Ладно. Мне пора бежать.
Менее удачные диалоги
(бот — второй)
1: Добрый день
2: Привет
1: Как ваши дела?
2: Хорошо, а у вас?
1: Отлично. Чем занимаетесь?
2: Я работаю в школе, а вы?
1: Я архитектор
2: Чем занимаетесь? (архитекторы модели видимо не знакомы)
1: Я программист
2: Это очень интересно
1: Как вас зовут?
2: Елена, а вас?
1: Я Игорь. Вам нравятся дети?
2: Нет, детей у меня нет
1: Любите читать? Или готовить?
2: Я люблю читать книги
1: Что вам нравится читать?
2: Я люблю психологию
1: О, интересно. А какая ваша любимая книга?
2: Я люблю русскую литературу, а вам?
1: Мне нравится фантастика
2: Я читала про любовь, мне немного нравится, спасибо за общение, но мне пора
1: Пока
Тут я немного поиздевался
(бот — второй)
1: Приветище!!!
2: Привет, как дела?
1: Нормально. Чем занимаешься?
2: Я работаю в школе, а ты?
1: А как тебя зовут?
2: Я люблю детей, поэтому я учитель младших классов, а ты?
1: Я Игорь. А тебя как зовут?
2: Я Ксюша, а ты?
1: Чем занимаешься, Ксюша?
2: Я люблю читать книги, а ты?
1: Я тоже. Какая твоя любимая?
2: Граф Монте Кристогова (из каких двух слов модель это склеила?)
1: Интересно. А кто твой любимый актер?
2: Да, я люблю детей, а ты?
1: У меня есть дочь
2: У меня есть дети, мальчики, мальчики
1: А коты? Ты любишь котов?
2: Да, очень, а ты?
1: Нравятся. А дельфинов?
2: Да, но я их люблю, а ты?
1: Мне нравятся кошки, дельфины и лошади
2: У тебя есть домашние животные?
1: Был старый кот
2: У меня кот
1: Ясно. Мне пора работать.
2: Пока
1: Пока
Скринкаст. Ускорил в два раза.
В коде есть еще full text decoder. это генератор текста без пользователя. Он нужен, чтобы быстро оценить качество этапа.
Для декодеров использовал фрагменты кода из неоцениваемой части задания на курсе "Natural Language Processing with Attention Models". Курс великолепен. Рекомендую!
Ссылки
Мой репозитарий с кодом эксперимента.
Репозитарий trax
Статья на arxiv: "Reformer: The Efficient Transformer", вышла в начале 2020 года .
