Представлюсь
Всем привет! Меня зовут Влад Виноградов, я руководитель отдела компьютерного зрения в компании EORA.AI. Мы занимаемся глубоким обучением уже более трех лет и за это время реализовали множество проектов для российских и международных клиентов в которые входила исследовательская часть и обучение моделей. В последнее время мы фокусируемся на решении задач поиска похожих изображений и на текущий момент создали системы поиска по логотипам, чертежам, мебели, одежде и другим товарам.
Эта публикация предназначена для Machine Learning инженеров и написана по мотивам моего выступления Поиск похожих изображений - справочник от А до Я, который был опубликован сообществом Open Data Science на Data Fest Online 2020.
Данная статья содержит справочную информацию по зарекомендованным методам, применяемым в задаче Image Retireval. Прочитав статью, вы сможете построить систему поиска похожих изображений под вашу задачу с нуля (не включая процесс разработки production решения).
О задаче
Поиск похожих изображений (по-другому, Content-Based Image Retrieval или CBIR) - это любой поиск, в котором участвуют изображения.
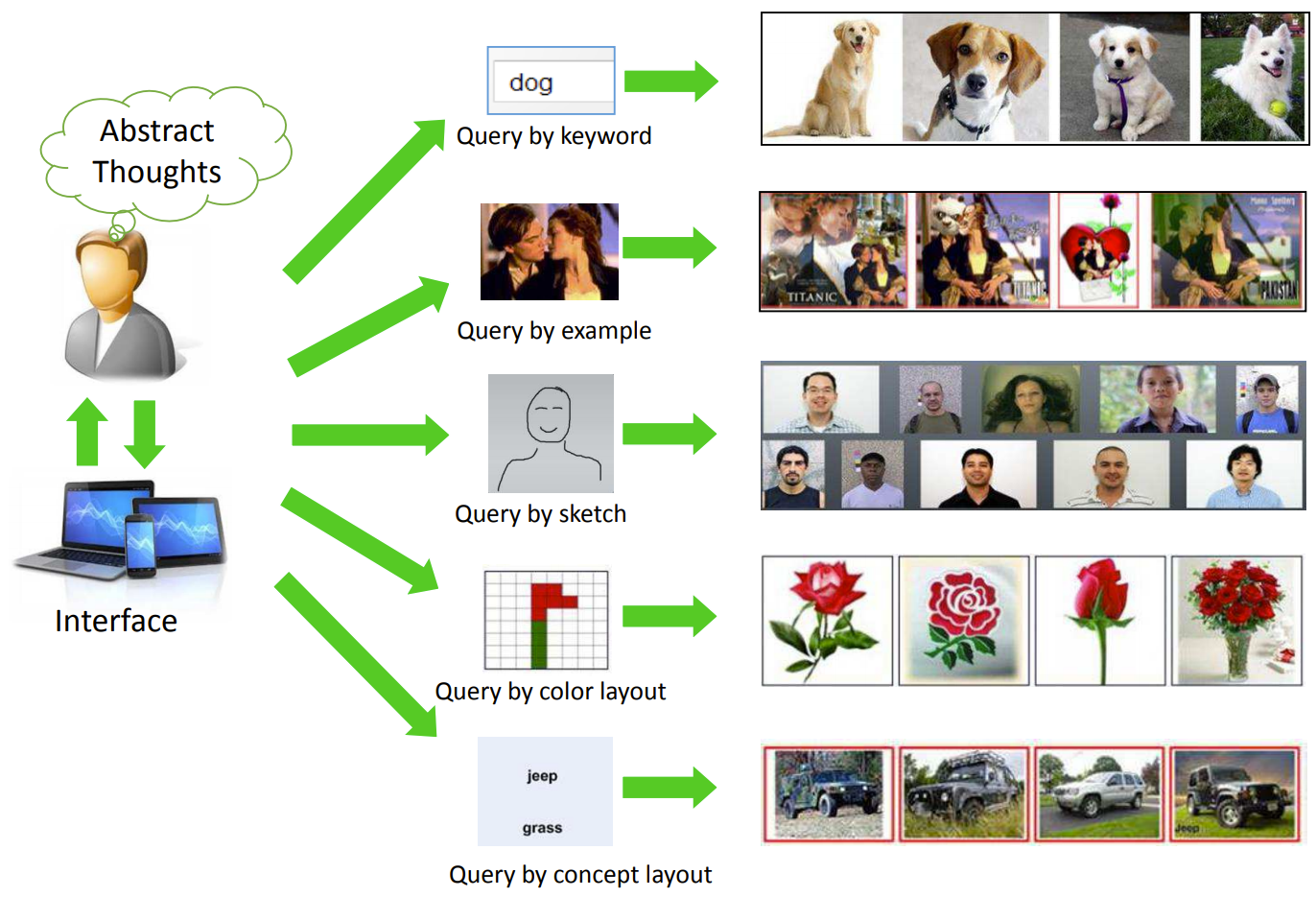
Проще всего о задаче расскажет картинка сверху из статьи Recent Advance in Content-based Image Retrieval: A Literature Survey (2017).
Сейчас все активнее применяется подход "Поиск по фото", в частности, в e-commerce сервисах (AliExpress, Wildberries и др.). "Поиск по ключевому слову" (с пониманием контента изображений) уже давно осел в поисковых движках Google, Яндекс и пр., но вот до маркетплейсов и прочих частных поисковых систем еще не дошел. Думаю, с момента появления нашумевшего в кругах компьютерного зрения CLIP: Connecting Text and Images ускорится глобализация и этого подхода.
Поскольку наша команда специализируется на нейронных сетях в компьютерном зрении, в этой статье я сосредоточусь только на подходе "Поиск по фото".
Базовые компоненты сервиса
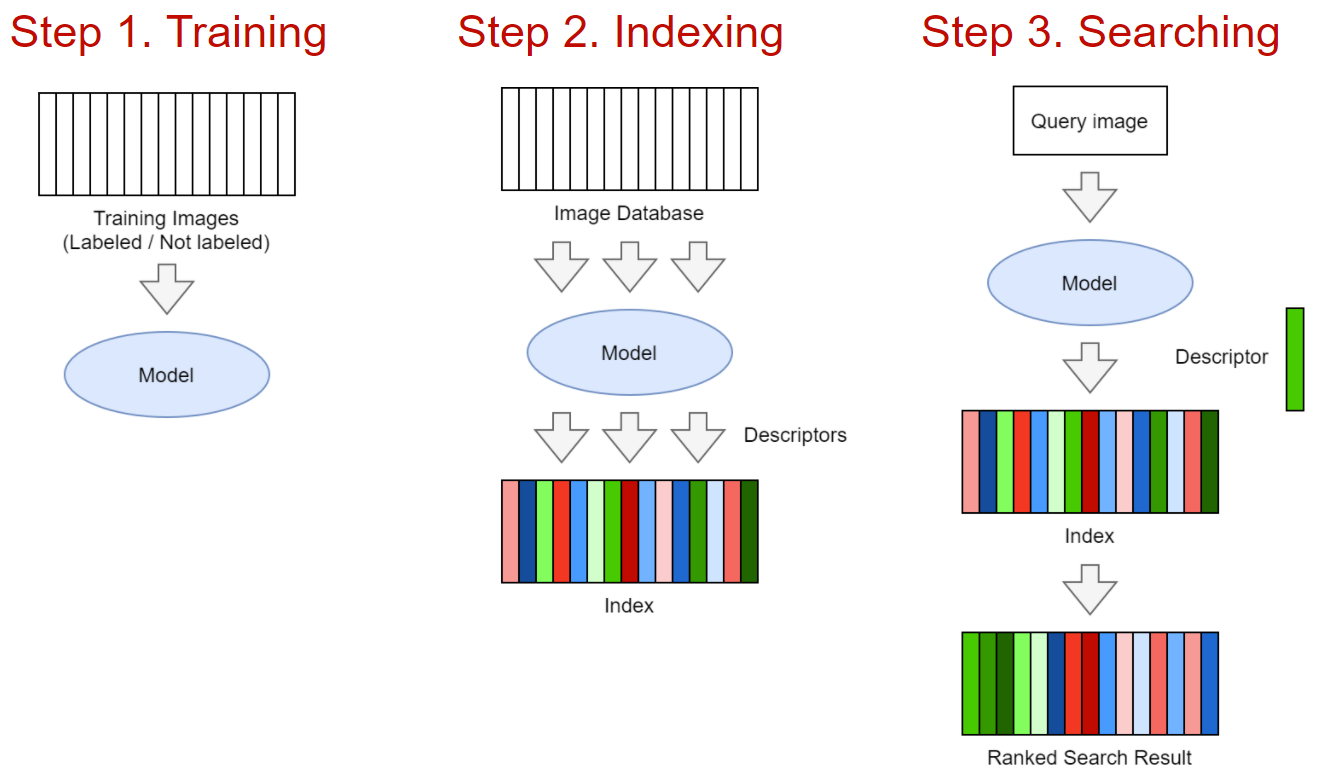
Шаг 1. Обучение модели. Модель может быть сделана на классике CV или на базе нейронной сети. На вход модели - изображение, на выход - D-мерный дескриптор/эмбеддинг. В случае с классикой это может быть комбинация SIFT-дескриптора + Bag of Visual Words. В случае с нейронной сетью - стандартный бэкбон по типу ResNet, EfficientNet и пр. + замысловатые пулинг слои + хитрые техники обучения, о которых мы далее поговорим. Могу сказать, что при наличии достаточного объема данных или хорошего претрена нейронные сети сильно выиграют почти всегда (мы проверяли), поэтому сосредоточимся на них.
Шаг 2. Индексирование базы изображений. Индексирование представляет из себя прогон обученной модели на всех изображениях и запись эмбеддингов в специальный индекс для быстрого поиска.
Шаг 3. Поиск. По загруженному пользователем изображению делается прогон модели, получение эмбеддинга и сравнение данного эмбеддинга с остальными в базе. Результатом поиска является отсортированная по релевантности выдача.
Нейросети и Metric Learning
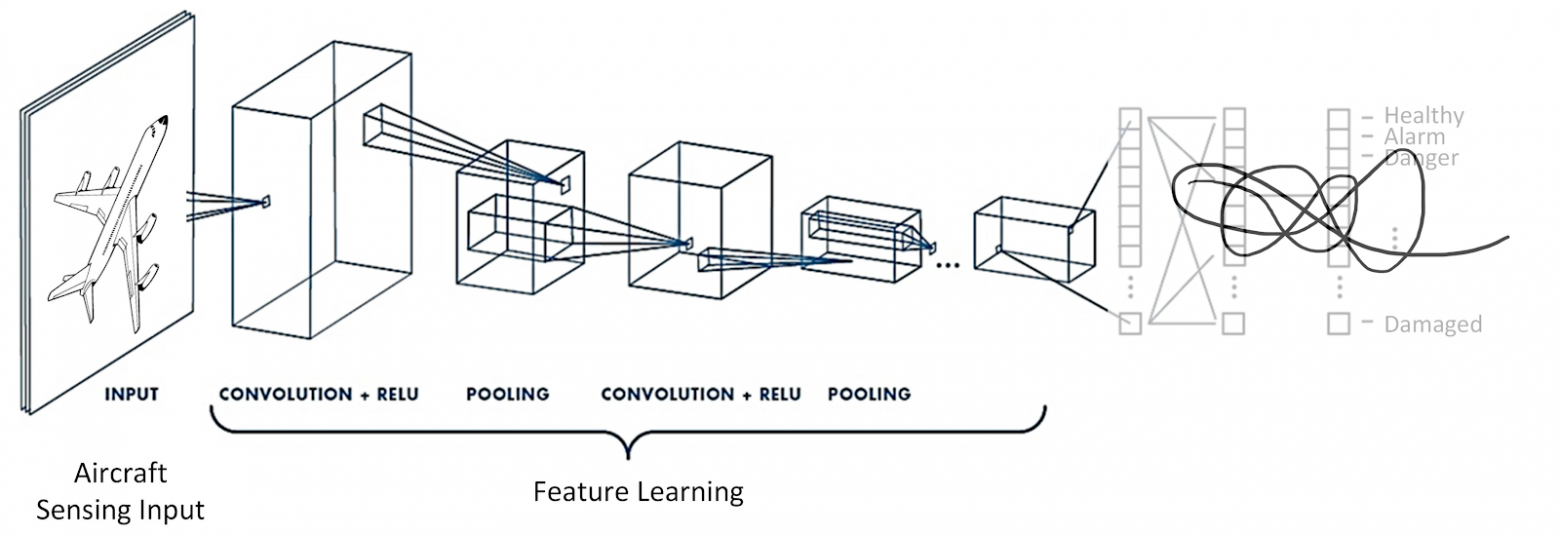
Нейронная сеть в задаче поиска похожих используется как feature extractor (бэкбон). Выбор бэкбона зависит от объема и сложности данных - рассмотреть можно все от ResNet18 до Visual Transformer.
Первая особенность моделей в Image Retrieval - это магия в голове нейросети. На лидерборде по Image Retrieval борются за построение лучших дескрипторов - тут есть и Combined Global Descriptors с параллельными пулингами и Batch Drop Block для более равномерного распределения активации по выходной карте признаков.
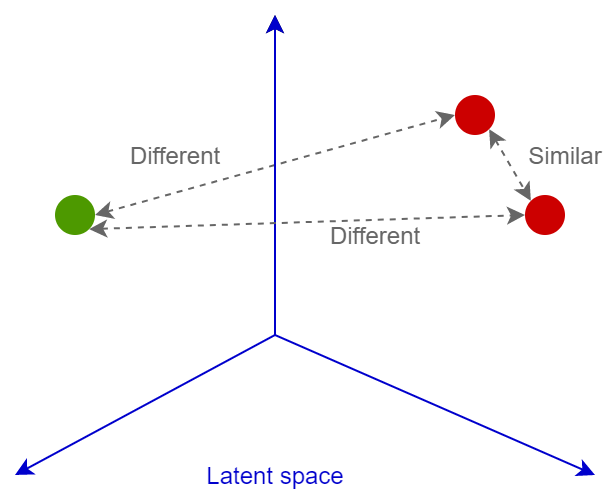
Второй главной фишкой являются функции ошибок. Их очень много. Только в Deep Image Retrieval: A Survey представлено больше десятка зарекомендованных парных лоссов. Еще столько же есть классификационных. Главная суть всех этих лоссов - обучить нейросеть трансформировать изображение в вектор линейно разделимого пространства, так чтобы далее можно было сравнивать эти вектора по косинусному или евклидову расстоянию: похожие изображения будут иметь близкие эмбеддинги, непохожие - далекие. Рассмотрим подробнее.
Функции ошибок
Contrastive Loss
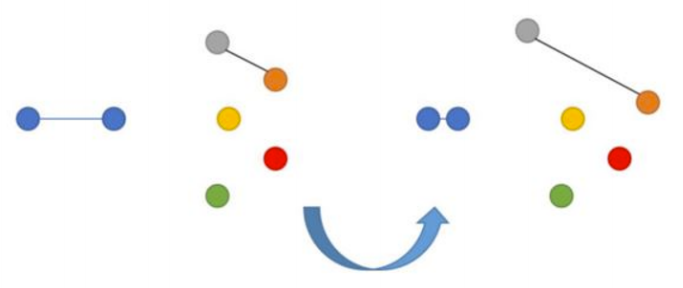
Самая простая для понимания функция ошибки - Contrastive Loss. Это парный лосс, т.е. объекты сравниваются по расстоянию между друг другом.
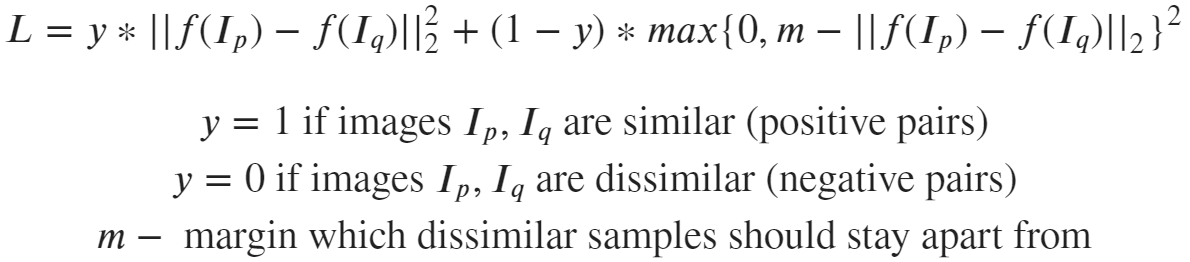
Нейросеть штрафуется за отдаленность друг от друга эмбеддингов изображений p и q, если эти изображения на самом деле похожи. Аналогично, возникает штраф за близость эмбеддингов, изображения которых на самом деле непохожи друг на друга. При этом в последнем случае мы ставим границу m (например, 0.5), преодолев которую, мы считаем, что нейросеть справилась с задачей "разъединения" непохожих изображений.
Triplet Loss
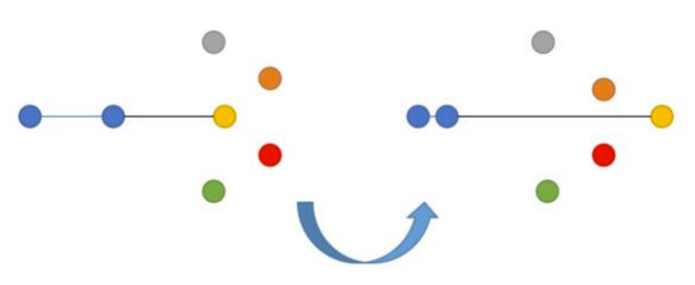
Triplet Loss берет во внимание три объекта - якорь, позитив (похожий на якорь) и негатив (отличный от якоря). Это также парный лосс.

Здесь мы нацелены на минимизацию расстояния от якоря до позитива и максимизацию расстояния от якоря до негатива. Впервые Triplet Loss был представлен в статье FaceNet от Google по распознаванию лиц и долгое время был state-of-the-art решением.
N-tupled Loss
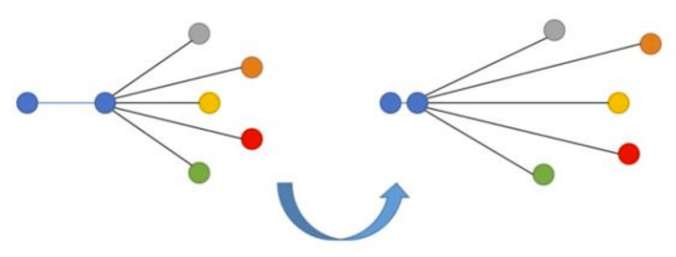
N-tupled Loss - развитие Triplet Loss, в котором также берется якорь и позитив, но вместо одного негатива используется несколько негативов.

Angular Additive Margin (ArcFace)
Проблема парных лоссов заключается в выборе комбинаций позитивов, негативов и якорей - если их просто брать равномерно случайными из датасета, то возникнет проблема "легких пар". Это такие простые пары изображений, для которых лосс будет 0. Оказывается, сеть достаточно быстро сходится к состоянию, в котором большинство элементов в батче будут для нее "легкими", и лосс для них окажется нулевым - сеть перестанет учиться. Чтобы избежать этой проблемы, стали придумывать изощренные техники майнинга пар - hard negative и hard positive mining. Подробнее о проблеме можно почитать в этой статье. Существует также библиотека PML, в которой реализовано множество методов майнинга, да и вообще в библиотеке представлено много полезного по задаче Metric Learning на PyTorch.
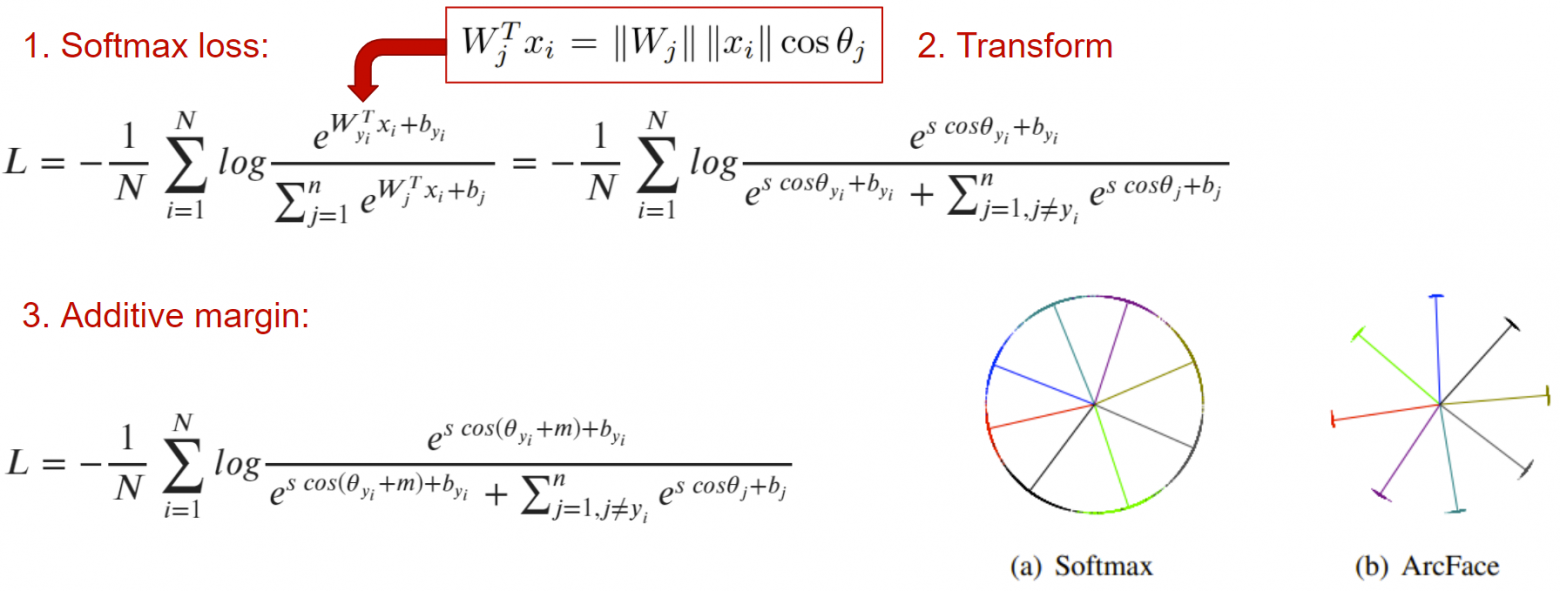
Еще одним решением проблемы являются классификационные лоссы. Рассмотрим одну популярную функцию ошибки, которая привела к state-of-the-art в распознавании лиц три года назад - ArcFace.
Основная мысль в том, чтобы добавить в обычную кросс-энтропию отступ m, который распределяет эмбеддинги изображений одного класса в районе центроиды этого класса так, чтобы все они были отделены от кластеров эмбеддингов других классов хотя бы на угол m.
Кажется, что это идеальная функция ошибки, особенно, когда посмотришь на бэнчмарк MegaFace. Но нужно иметь в виду, что она будет работать только при наличии классификационной разметки. Если у вас такой нет, придется работать с парными лоссами.
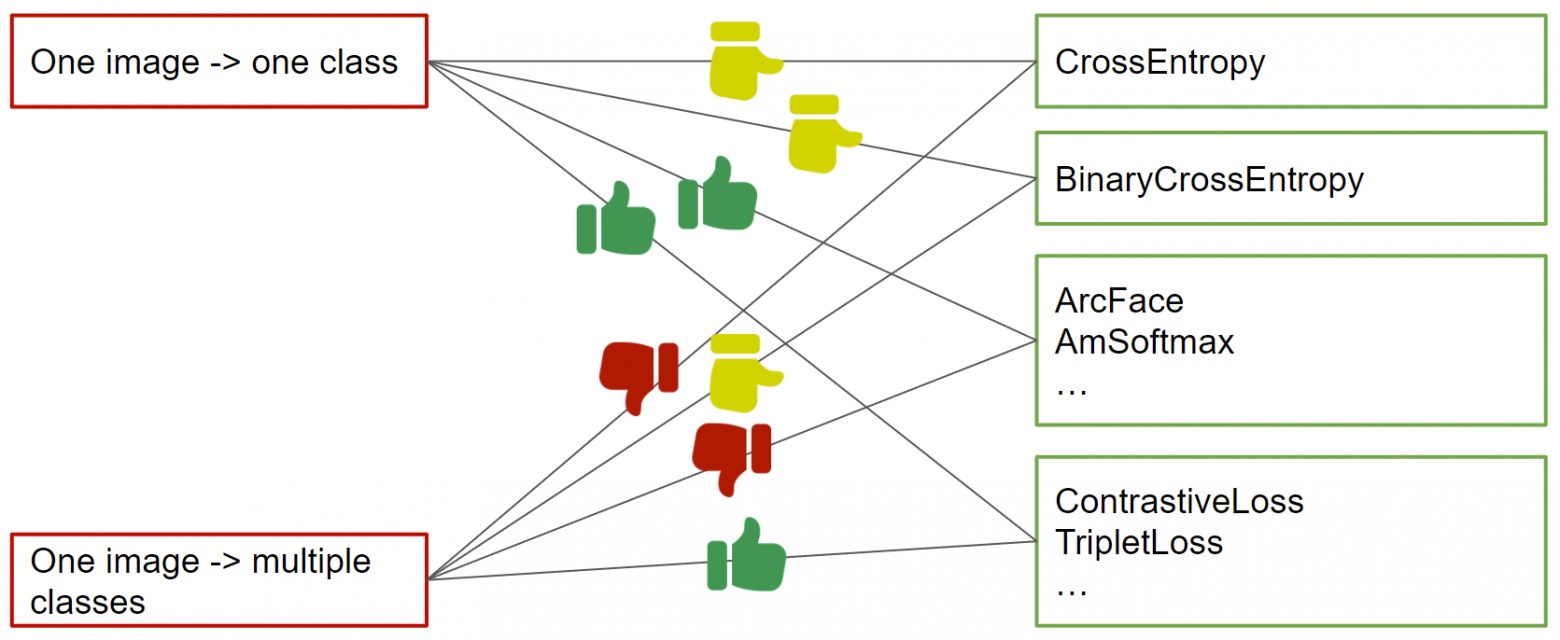
Здесь я визуально показываю, какие функции ошибок лучше всего применять при наличии одноклассовой и многоклассовой разметки (из последней можно вывести парную разметку путем подсчета доли пересечения между multilabel векторами примеров).
Пулинги
Вернемся к архитектуре нейросети и рассмотрим парочку pooling слоев, применяемых в задачах Image Retrieval
R-MAC
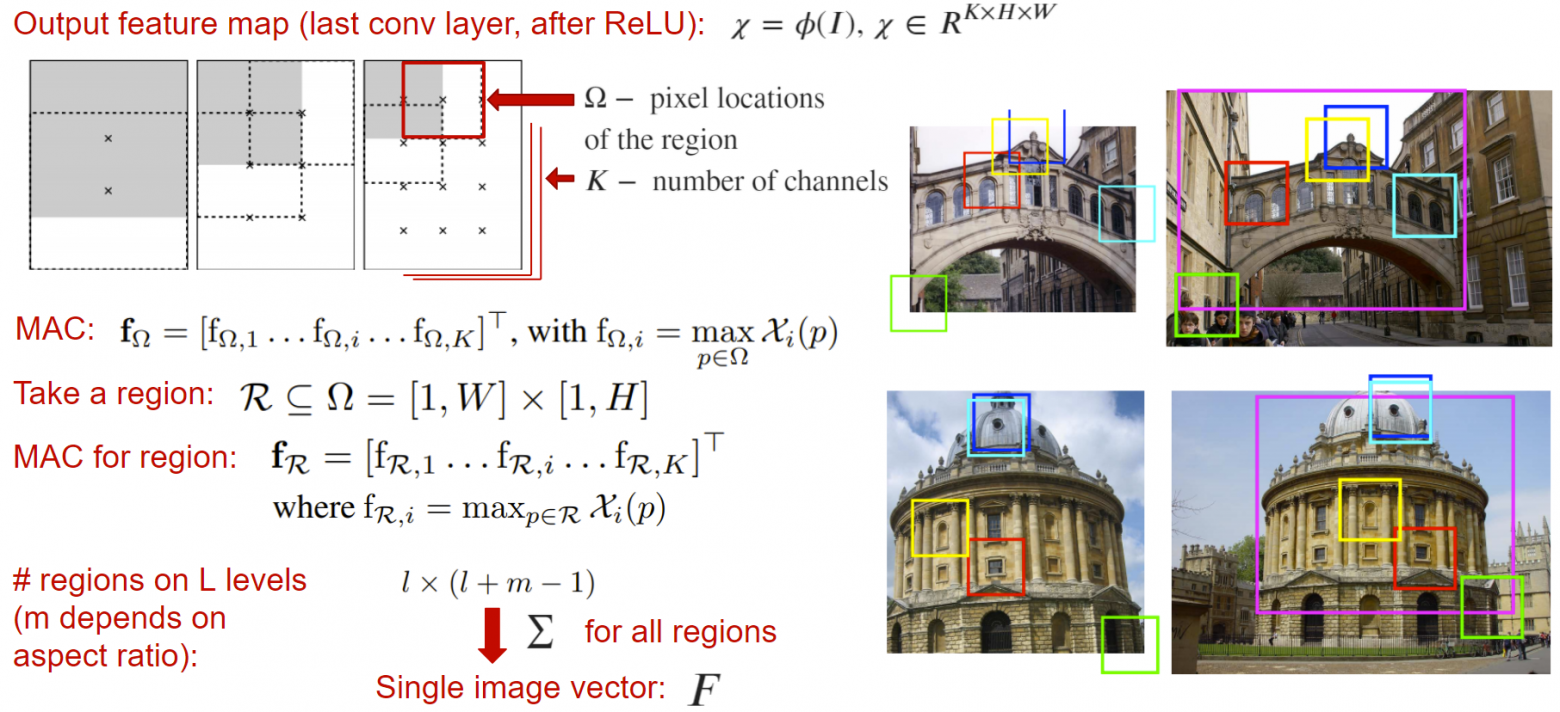
Regional Maximum Activation of Convolutions (R-MAC) - пулинг слой, принимающий выходную карту нейронной сети (до глобального пулинга или слоев классификации) и возвращающий вектор-дескриптор, посчитанный как сумма активаций в различных окнах выходной карты. Здесь активацией окна является взятие максимума по этому окну для каждого канала независимо.
Итоговый дескриптор учитывает локальные особенности изображения при различных масштабах, тем самым создающий богатое признаковое описание. Этот дескриптор сам может являться эмбеддингом, поэтому его можно сразу отправить в функцию ошибки.
GeM
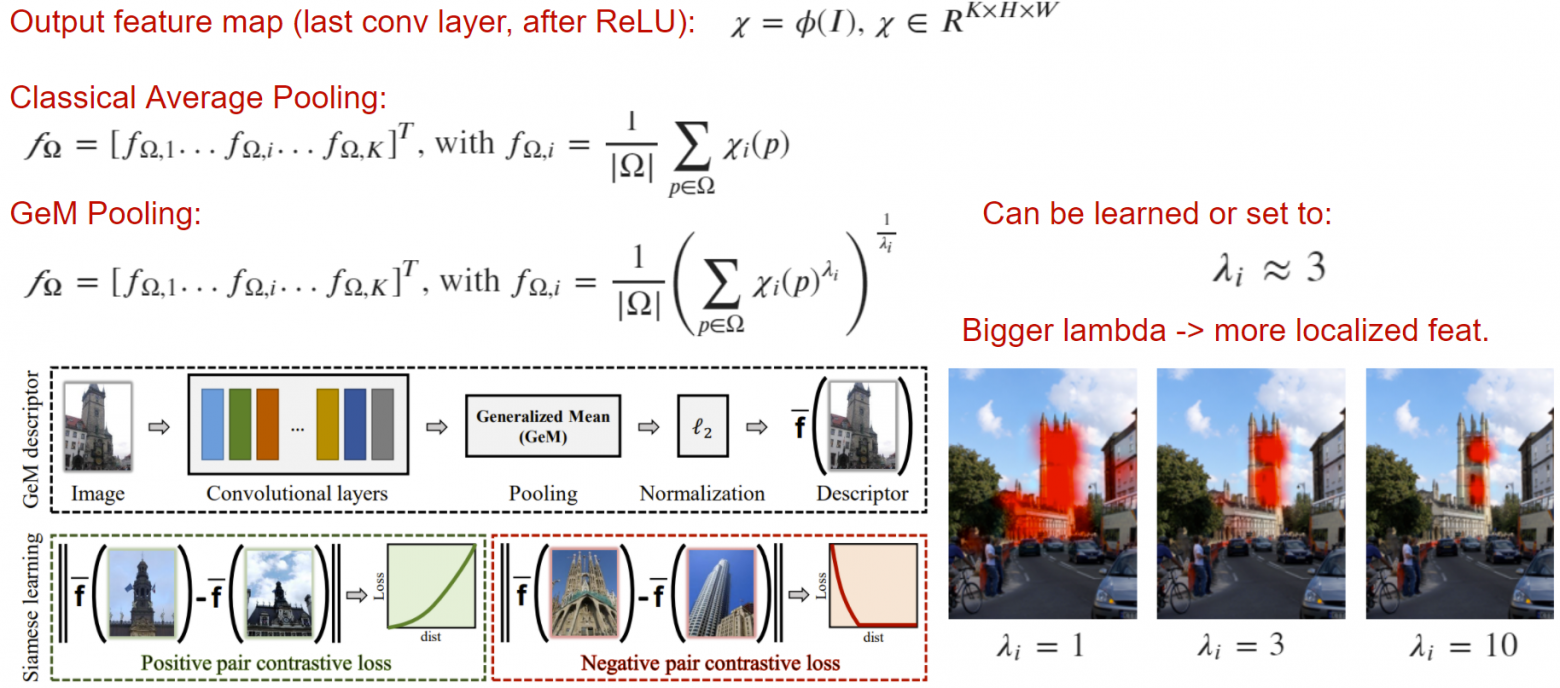
Generalized Mean (GeM) - простой пулинг, который может улучшить качество выходного дескриптора. Суть в том, что классический average pooling можно обобщить на lambda-норму. При увеличении lambda мы заставляем сеть фокусироваться на значимых частях изображения, что в определенных задачах может быть важно.
Ранжирование
Индексы
Залог качественного поиска похожих изображений - ранжирование, т.е. отображение наиболее релевантных примеров для данного запроса. Оно характеризуется скоростью построения индекса дескрипторов, скоростью поиска и потребляемой памятью.
Самое простое - сохранить "в лоб" эмбеддинги и делать brute-force поиск по ним, например, с помощью косинусного расстояния. Проблемы появляются тогда, когда эмбеддингов становится много - миллионы, десятки миллионов или еще больше. Скорость поиска значительно снижается, объем занимаемой динамической памяти увеличивается. Одна позитивная вещь остается - это качество поиска, оно идеально при имеющихся эмбеддингах.

Указанные проблемы можно решить в ущерб качеству - хранить эмбеддинги не в исходном виде, а сжатом (квантизованном). А также изменить стратегию поиска - искать не brute-force, а стараться за минимальное число сравнений найти нужное число ближайших к данному запросу. Существует большое число эффективных фреймворков приближенного поиска ближайших. Для них создан специальный бэнчмарк, где можно посмотреть, как ведет себя каждая библиотека на различных датасетах.
Самые популярные: отечественная NMSLIB, Spotify Annoy, Facebook Faiss, Google Scann. Также, если хочется взять индексирование с REST API "из коробки", можно рассмотреть приложение Jina.
Переранжирование
Исследователи в области Information Retrieval давно поняли, что упорядоченная поисковая выдача может быть улучшена неким способом переупорядочивания элементов после получения исходной выдачи.
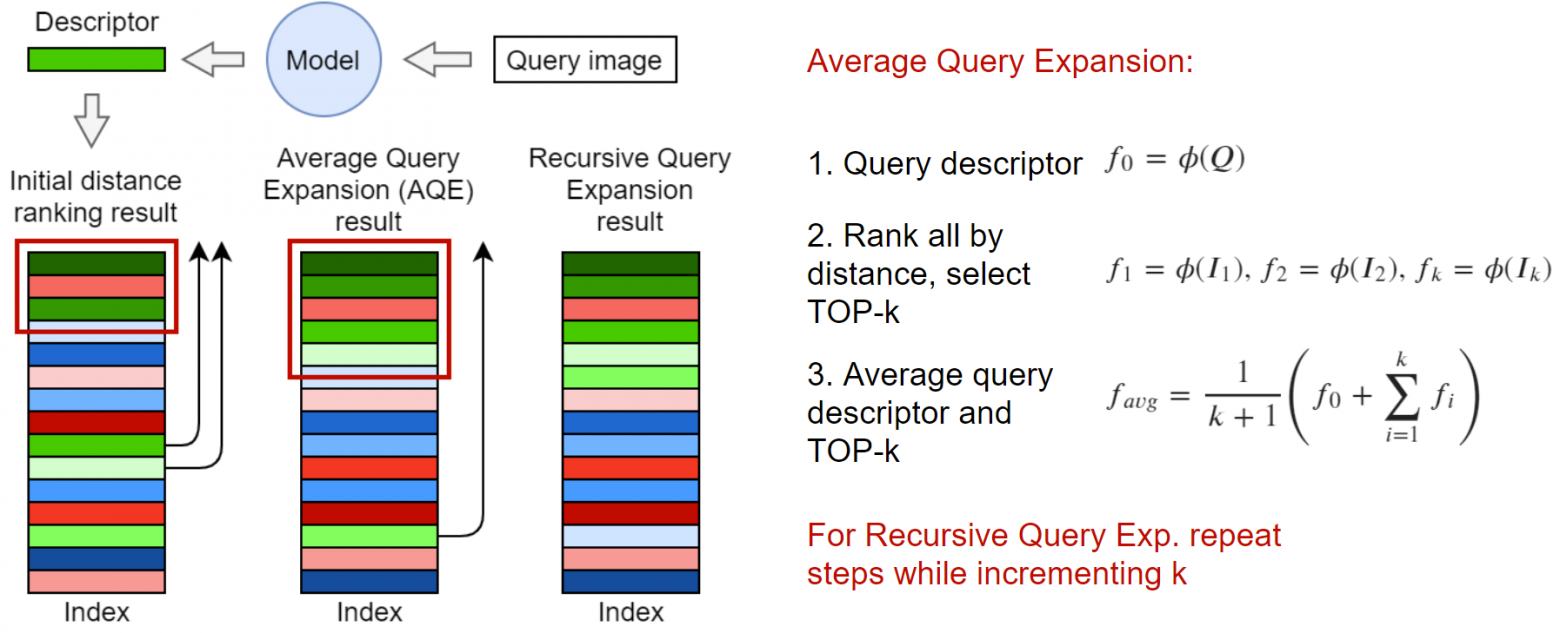
Одним из таких методов является Query Expansion. Идея состоит в том, чтобы использовать top-k ближайших элементов для генерации нового эмбеддинга. В самом простом случае можно взять усредненный вектор, как показано на картинке выше. Также можно взвесить эмбеддинги, например, по отдаленности в выдаче или косинусному расстоянию от запроса. Подобные улучшения описаны в едином фреймворке в статье Attention-Based Query Expansion Learning. По желанию можно применить Query Expansion рекурсивно.
k-reciprocal

k-reciprocal - множество элементов из top-k, в числе k ближайших которых присутствует сам запрос. На базе этого множества строят процесс переранжирования выдачи, один из которых описан в статье Re-ranking Person Re-identification with k-reciprocal Encoding. По определению, k-reciprocal ближе к запросу, чем k-nearest neighbors. Соответственно, можно грубо считать элементы, попавшие в множество k-reciprocal заведомо позитивными и изменять правило взвешивания, например, для Query Expansion. В данной статье разработан механизм пересчета дистанций с использований k-reciprocal множеств самих элементов в top-k. В статье много выкладок, это выходит за рамки данного поста, поэтому предлагаю читателю ознакомиться самостоятельно.
Валидация
Мы подошли к части проверки качества поиска похожих. В этой задаче есть много тонкостей, которые новичками могут быть не замечены в первое время работы над Image Retrieval проектом.
Метрики
В первую очередь - метрики. Рассмотрим такие популярные метрики в задаче Image Retrieval: precision@k, recall@k, R-precision, mAP и nDCG.
precision@k

Показывает долю релевантных среди top-k ответов.
Плюсы:
показывает, насколько система избирательна в построении top-k
Минусы:
очень чувствительна к числу релевантных для данного запроса, что не позволяет объективно оценить качество поиска, где для разных запросов имеется разное число релевантных примеров
достичь значение 1 возможно только, если число релевантных >= k для всех запросов
R-precision

То же самое, что precision@k, где k устанавливается равным числу релевантных к данному запросу
Плюсы:
исчезает чувствительность к числу k в precision@k, метрика становится стабильной
Минусы:
приходится знать общее число релевантных к запросу (может быть проблемой, если не все релевантные размечены)
recall@k

Показывает, какая доля релевантных была найдена в top-k
Плюсы:
отвечает на вопрос, найдены ли релевантные в принципе среди top-k
стабильна и хорошо усредняется по запросам
mAP (mean Average Precision)
Показывает насколько плотно мы заполняем топ выдачи релевантными примерами. Можно на это посмотреть как на объем информации, полученной пользователем поискового движка, который прочитал наименьшее число страниц. Соответственно, чем больше объем информации к числу прочитанных страниц, тем выше метрика.
Плюсы:
объективная стабильная оценка качества поиска
является одно-численным представлением precision-recall кривой, которая сама по себе богата информацией для анализа
Минусы
приходится знать общее число релевантных к запросу (может быть проблемой, если не все релевантные размечены)
Подробнее про метрики в Information Retrieval, в том числе посмотреть вывод mAP, можно почитать здесь.
nDCG (Normalized Discounted Gain)

Данная метрика показывает, насколько корректно упорядочены элементы в top-k между собой. Плюсы и минусы этой метрики не будем рассматривать, поскольку в нашем списке это единственная метрика, учитывающая порядок элементов. Тем не менее, есть исследования, показывающие, что при необходимости учитывать порядок данная метрика является достаточно стабильной и может подойти в большинстве случаев.
Усреднение
Также важно отметить варианты усреднения метрик по запросам. Рассмотрим два варианта:
macro: для каждого запроса считается метрика, усредняем по всем запросам
+: нет значительных колебаний при разном числе релевантных к данному запросу
-: все запросы рассматриваются как равноправные, даже если на какие-то больше релевантных, чем на другие
micro: число размеченных релевантных и отдельно успешно найденных релевантных суммируется по всем запросам, затем участвует в дроби соответствующей метрики
+: запросы оцениваются с учетом числа размеченных релевантных для каждого из них
-: метрика может стать сильно низкой / сильно высокой, если для какого-то запроса было очень много размеченных релевантных и система неуспешно / успешно вывела их в топ
Схемы валидации
Предлагаю рассмотреть два варианта валидации.
Валидация на множестве запросов и выбранных к ним релевантных
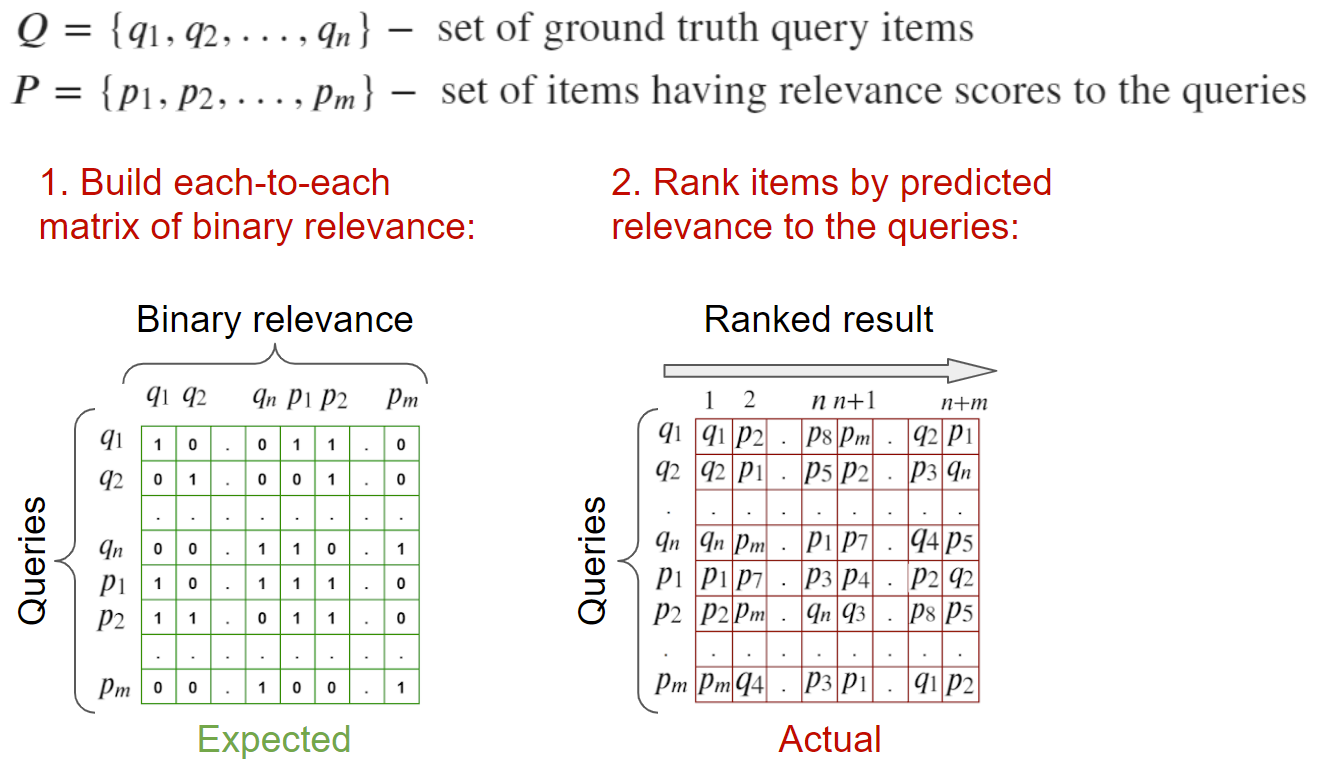
На вход: изображения-запросы и изображения, релевантные к ним. Имеется разметка в виде списка релевантных для данного запроса.
Для подсчета метрик можно посчитать матрицу релевантности каждый с каждым и, на основе бинарной информации о релевантности элементов посчитать метрики.
Валидация на полной базе
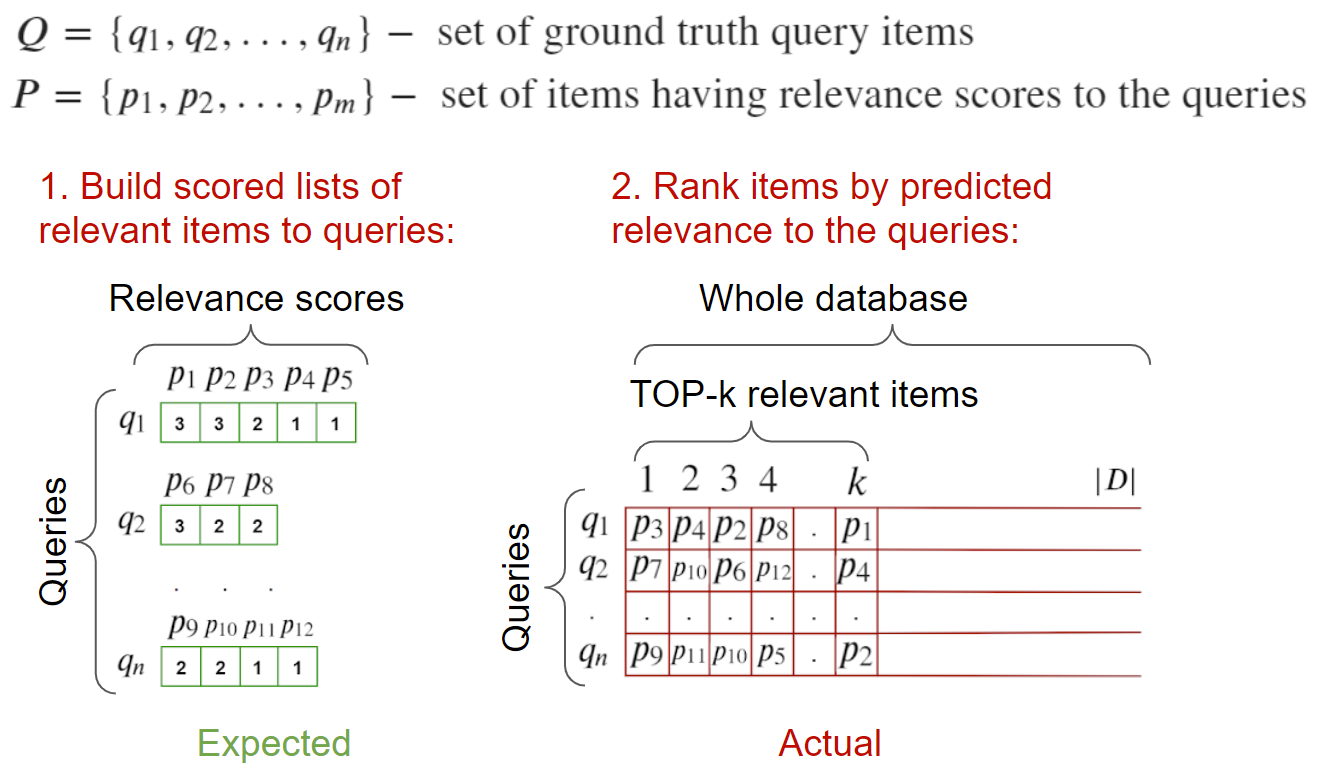
На вход: изображения-запросы, и изображения, релевантные к ним. Также должна быть валидационная база изображений, в которой в идеале отмечены все релевантные к данным запросам. А также в ней не должно присутствовать изображений-запросов, иначе придется их чистить на этапе поиска, чтобы они не засоряли top-1. Валидационная база участвует как база негативов - наша задача вытянуть релевантные по отношению к ней.
Для подсчета метрик можно пройтись по всем запросам, посчитать дистанции до всех элементов, включая релевантные и отправить в функцию вычисления метрики.
Пример реализованного проекта

Некоторые компании спорят с другими компаниями, чтобы вторые не использовали изобразительные элементы бренда первых. В таких случаях более слабый производитель пытается паразитировать на успехе крупного бренда, выдавая свои продукты и услуги под похожей символикой. От этого страдают и пользователи - вы можете по ошибке купить сыр не того производителя, которому вы уже доверяете, а взять подделанный товар, не прочитав внимательно этикетку. Пример из недавнего: Apple Is Attempting to Block a Pear Logo Trademark.
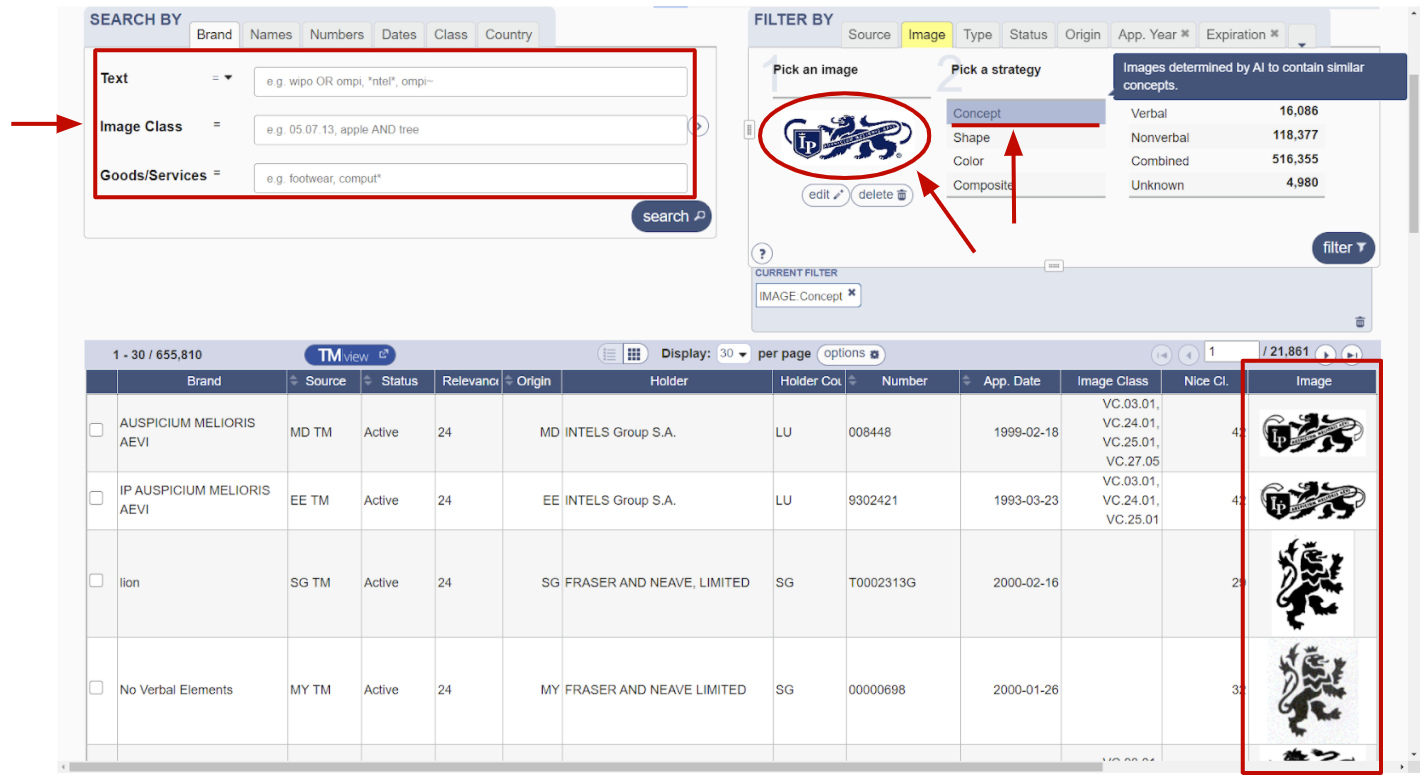
Для борьбы с нелегалами существуют специальные компании, государственные и частные. У них имеется реестр зарегистрированных товарных знаков, по которому они могут сравнивать новые приходящие знаки и разрешать/отклонять заявку на регистрацию товарного знака. Выше пример интерфейса зарубежной системы WIPO. В таких системах хорошим помощником будет поиск похожих изображений - эксперт быстрее сможет найти аналоги.
Примеры работы нашей системы
Объем индексируемой базы изображений: несколько миллионов товарных знаков. Здесь первое изображение - запрос, на следующей строке - список ожидаемых релевантных, остальные строки - то, что выдает поисковая система в порядке снижения релевантности.


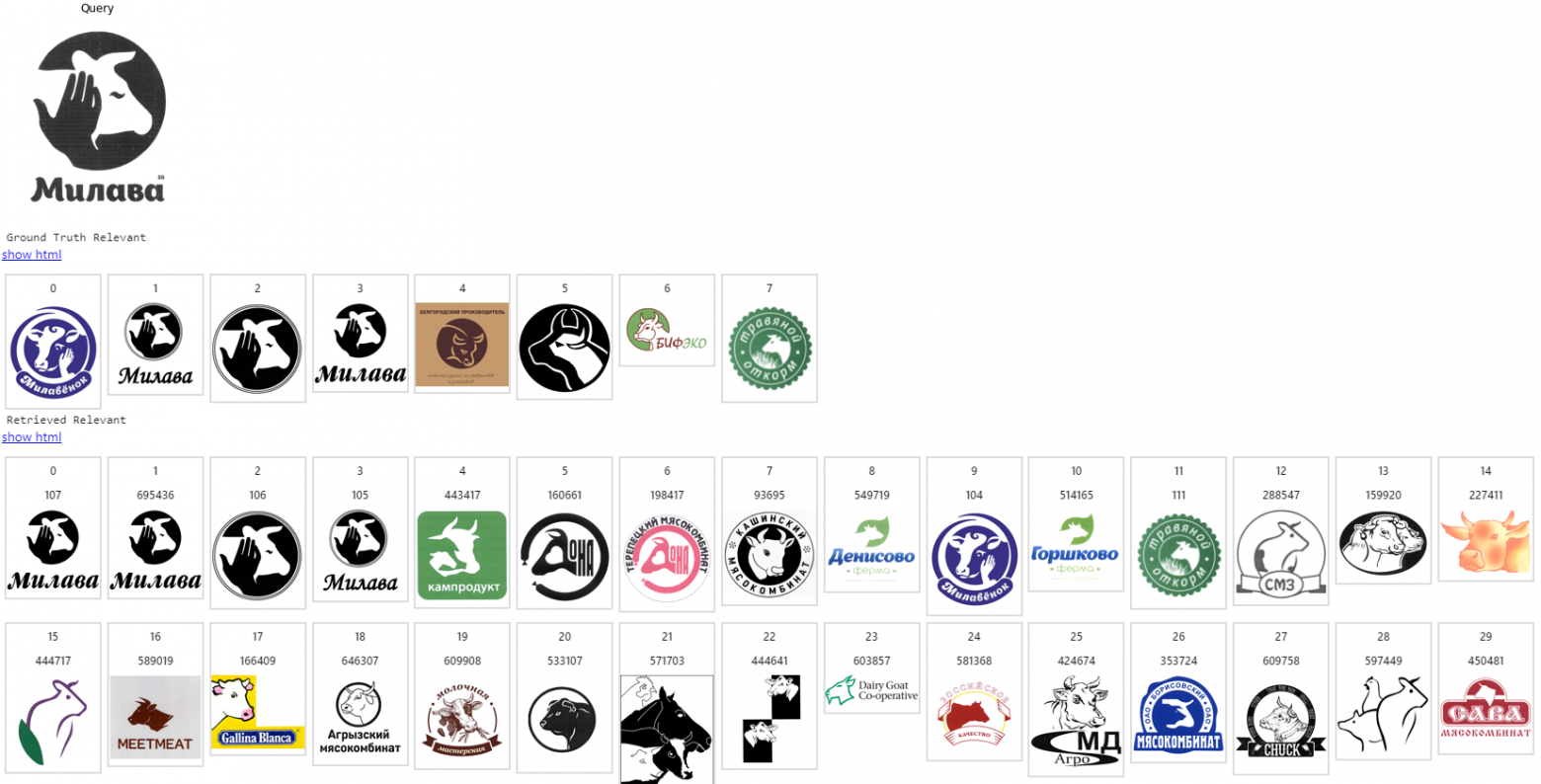

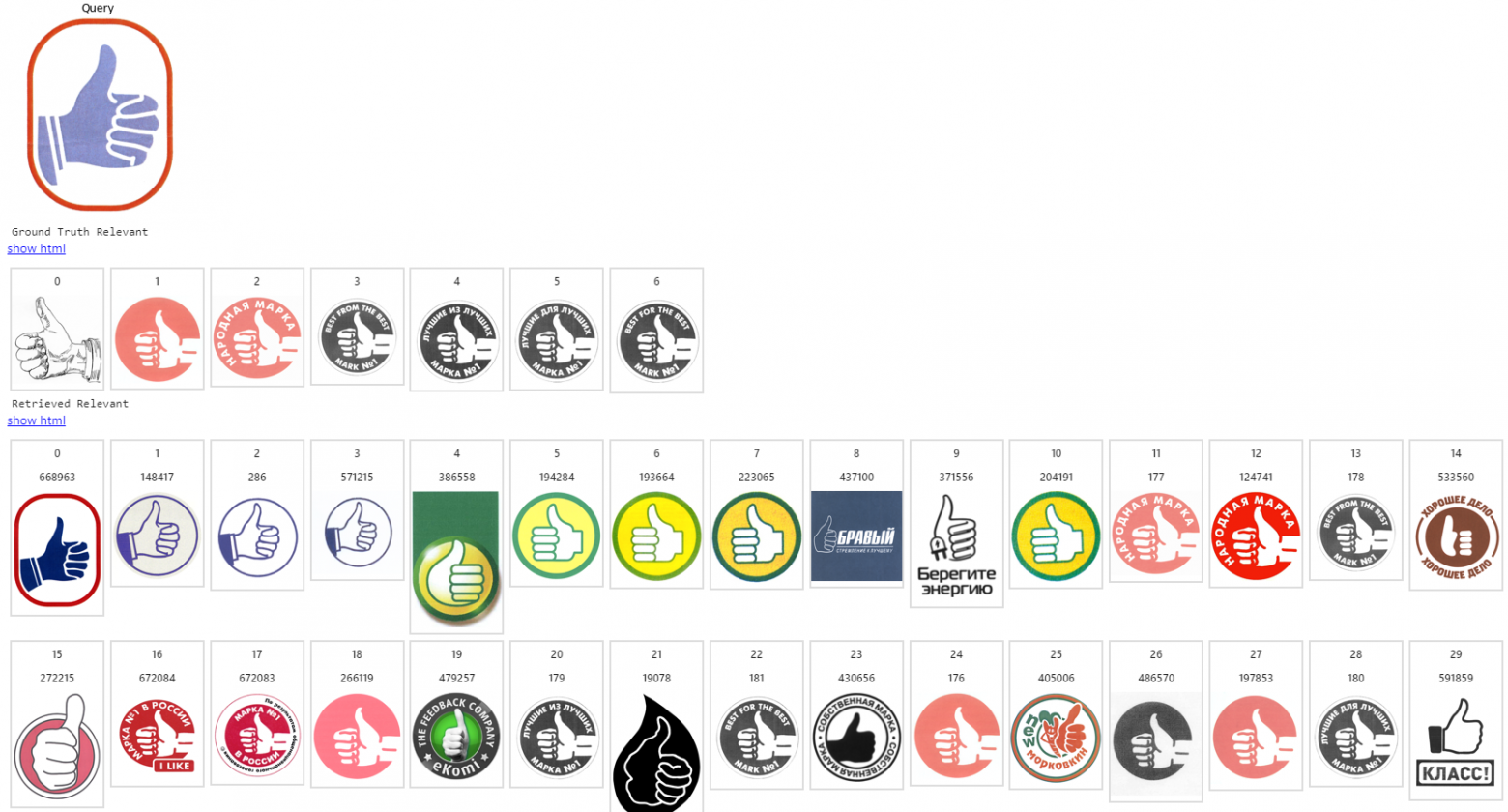
Заключение
На этом все. Это был обзорный материал. Надеюсь, те, кто строит или собирается строить системы поиска похожих изображений, извлекли какую-то пользу. И наоборот, если считаете, что я где-то не прав, скажите в комментариях, буду рад обратной связи.
