Comments 24
Впрочем обе эти вещи в свою очередь перпендикулярны разрыву между процедурным (императивным, value-level, Java, C#, Python) и комбинаторным (декларативным, function-level, SQL) программированием (тут в разделе Немного теории про этот разрыв подробнее). И у вас отлично может использоваться объектно-ориентированная парадигма вместе с комбинаторной (аля SQL), как это сделано в lsFusion, впрочем как и с процедурной.
Так что противопоставлять объектно-ориентированную парадигму с процедурной это как-то глупо на мой взгляд. Правильнее говорить о противопоставлении процедурной (C, Java) и комбинаторной парадигм (SQL).
По поводу смешения процедурного и ООП на проекте. Да, это постоянно происходит. Мне просто хотелось бы рассказать про мое понимание влияния соотношения. Т.е. у вас бизнес-логика более процедурная, либо более ООПшная… со всеми вытикающими. И опять же это прямо очень хорошо видно на примере того кода из книги Фаулера.
Т.е. у вас бизнес-логика более процедурная, либо более ООПшная
Нет. Это перпендикулярные понятия. Ну или у вас свое понимание процедурности.
То есть У вас вполне может быть логика очень активно использующая и наследование и полиморфизм и даже инкапсуляцию, при этом все это делать в комбинаторной парадигме (то есть высокоуровневых операторах аля SELECT… GROUP BY ...), а не процедурной (if'ах, циклах, переменных и вот этом вот всем). Например так в lsFusion делается.
Такое ощущение, что вы говорите больше про структурное программирование. А это не равно процедурному
Так что вы тогда под процедурным понимаете? Абстрагирование? Так оно и в SQL есть, представления называется. И опять таки перпендикулярно во многом ООП. Хотя согласен, наверное термин структурное правильнее в данном случае.
Чтож, в любом случае нужно максимально разделить бизнес-правила от логики хранения. Потому что бизнес-правила и безнес-логика и без того очень сложные и если их нагружать техническими деталями хранения (джойны, конвертации типов, условия фильтрации и обобщенные табличные выражения), то читать такой код сложнее
Джойны, условия фильтрации содержат бизнес-логику (то есть essential complexity). Другое дело, что да SQL почему-то до сих пор завис на уровне таблиц, не поднявшись на уровень функций (почитайте ссылку выше, что я кидал) и поэтому привносит большую accidental complexity. Но в императивных языках с этим не сильно лучше.
ООП в любом случае борется с такой сложностью очень хорошо
ООП именно с сложностью из абзаца выше не борется от слова вообще. ООП (а именно наследование / полиморфизм) мощный инструмент в декомпозиции / модульности, тут не поспоришь, но он не про детали хранения / вычисления.
Вот в таком случае логика будет в чистом виде, без технических деталей…
Нет, как раз C#, Java очень императивные языки и там accidental complexity не сильно меньше чем в SQL. Если уж хотите уйти от императивности и «технических деталей» нужно идти в что-то куда более декларативное (аля того же lsFusion).
Но вот про джойны и условия фильтрации хотелось бы ответись тут. Содержат ли они бизнес-логику? И да и нет.
С одной стороны если у нас есть сущность пользвателя и его адрес. Джой таблиц пользователя и адреса — да, содержит. Простая ассоциация.
Но, если у нас наследование? И мы из базового класса должны вытащить набор полей… тут мы опять же прибегаем к джойну, но это чистые технические детали. Как проверить? Вы говорите человеку далекому от техники (продук оунер, владелец, иногда аналитик) и он воспринимает это как что-то про реализацию, если вообще понимает о чем речь.
Далее давайте просто на синтаксис посмотрим. С одной стороны мы получаем user.Address с другой как минимум две строчки кода from user u… join adress a on u.address_id = a.id И еще про схему не забываем (тоже чистейшай техника). Очевидно, что на любом ООП языке код локаничение и можно проще сосредоточиться на самих правилах, чем на ньюансах хранения.
Все это приводит к мысли — выгрести в оперативку все таблицы, замепить их и условия фильтраци, ассоцииации — все делать в коде. Но даже любой джун вам скажет, что работать такое не будет, вот и получаются хранимые процедуры, методы репозиториев с SQL — по сути одно и то же… И да, они содержат там бизнес-логику. И да, за это приходится платить…
habr.com/ru/company/lsfusion/blog/458376/#rest
Да в структурном программировании композиция проще и понятнее (так как оперирует функциями, а не таблицами), чем join. Но скажем цикл, разбиение или примитивная рекурсия в комбинаторном (SQL) проще.
В любом случае непонятно какое отношении это к ООП имеет. ООП это прежде всего про наследование и полиморфизм (ООП может быть как в структурном, так и в комбинаторном программировании), вы же рассуждаете про то, что SQL оперирует таблицами, а не функциями. Да это создает дополнительную accidental complexity, но опять-таки причем тут ООП?
Но, если у нас наследование? И мы из базового класса должны вытащить набор полей
А причем тут наследование? Из базового класса вытащить набор полей это про инкапсуляцию скорее.
И причем тут хранимые процедуры? Это такая же императивщина как и обычные структурные языки, только что данные между сервером приложений и сервером БД чуть меньше гуляют. Но там такая же N+1 проблема есть, как и у Java, C#, Python.
Тут скорее вопрос, что в современном SQL нормально наследование / полиморфизм не поддерживаются. Но это проблема не ООП парадигмы, а конкретных SQL реализаций.
Там про другую бизнес-логику. В заметке по ссылке (спасибо за прекрасную заметку) — про бизнес-логику с точки зрения бизнес-аналитиков — декларативное описание системы или её части. В текущей заметке — про бизнес-логику в смысле реализованного разработчиками императивного набора команд для обработки запроса/данных. Одно напоминает другое меньше, чем известный демотиватор с деревом и качелями.
Кроме того, надо предусматривать, чтобы это решение, позволяло добавлять логику из «разных источников» (плагины, расширения и т.п.). Тогда, описание этой логики в «едином месте», должно проверяться на непротиворечивость, с возможностью указания разрешения конфликтов в этой логике (на конкретной сборке).
Приведем для дальнейших рассуждений лишь схему все из той же книги:
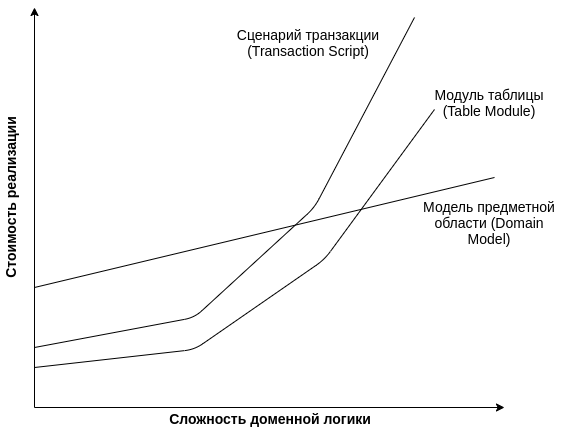
Ужасно я люблю такие схемы, ничего не могу с собой поделать. Для тех, кому интересно, она расположена на странице 29 (для издания Addison Wesley, 2010). К ней там есть интересное примечание:
Figure 2.4 is one of those nonscientific graphs that really irritate me because thy have utterly unqualified aces.
И, что важно, для этой схемы нет никакого обоснования, источника данных — ничего. Проще говоря, Фаулер ее придумал, а вы ему верите просто на слово. Но строите на этой вере дальнейшие рассуждения.
Нужно лишь понять к какой из этих двух категорий она ближе.
… а почему вы считаете, что категорий всего две? Почему вы не рассматриваете, например, функциональное программирование?
Поэтому и остается лишь одно — делиться знаниеми и идеями только так.
Функциональное программирование — да, формально не рассмотрено. Это опять же тема на будущее… Но опять же, при написании кода с помощью ООП языков сейчас, как правило, используют элементы и идеи функционального подхода. Стараются делать side effect free функции, моанада maybe, цепочки вызовов, делегаты и т.п. Т.е. формально это не чистое ООП.
И хоть у меня на текущий момент не нашлось места для функциональных языков на графике. Мне думается, что мысль, изложенная в статье полезна для анализа кода легаси проектов. И для формирования стратегии по развитии новых сервисов (т.е. как мы будем в случае чего отходить от модуля таблицы к модели предметной области — задаваться таким вопросом имеет смысл)
И в данном случае мой опыт совпадает с опытом Фаулера — на практике все подтвердилось.
Confirmation bias?
Второе — на самом деле все можно формализовать и реально подсчитать сложность и число действий.
Будет ли подсчитанная метрика коррелировать с реальной сложностью внесения изменений? Как это проверить?
Поэтому и остается лишь одно — делиться знаниеми и идеями только так.
Проблема в том, что вы делитесь не столько знаниями, сколько гипотезами. Наблюдениями, которые не обязательно универсальны. И при этом еще и основанными на очень зыбкой терминологической базе.
Но опять же при написании кода с помощью ООП языков сейчас как правило используют элементы и идеи функционального подхода. Стараются делать side effect free функции, моанада maybe, цепочки вызовов, делегаты и т.п. Т.е. формально это не чистое ООП.
Но на вашем графике-то "объектно-ориентированный стиль"! Это значит, что подобное "не чистое ООП" может этому графику никак не следовать.
Это как раз пример той самой неопределенной терминологической базы, о которой я выше писал.
т.е. как мы будем в случае чего отходить от модуля таблицы к модели предметной области — задаваться таким вопросом имеет смысл
Имеет смысл задаваться вопросом "как мы будем реализовывать бизнес-логику", и "как мы будем переходить от существующей реализации к другой, если существующая перестанет удовлетворять". А ориентироваться на Очень Общие Слова вида "объектно-ориентированный стиль" и "модель предметной области" — не стоит, потому что это оказывается неконструктивно.
Я вовсе не против, главное чтобы этой гипотезой можно было руководствоваться на практике. За неимением «ничего» — лучше обладать хотя бы гипотезой.
В том-то и дело, что руководствоваться на практике непроверенной гипотезой — плохо (надо пояснять, почему?).
Мне, кстати, интересно, а как конкретно формулируется ваша гипотеза? Потому что текста в посте много, а одной короткой формулировки — нет.
Мне подобного рода рассуждения не попадались
Гм. Мне казалось, рассуждений "как организовывать бизнес-логику" и, в частности, "как рефакторить код" — много. У Фаулера две книги (ровно по этим направлениям), у Эванса (DDD), у Мартина (Clean Architecture), Симан регулярно пишет про то, как он организует архитектуру с помощью функционального программирования, ну и так далее.
Или какие рассуждения вам не попадались?
Второе — на самом деле все можно формализовать и реально подсчитать сложность и число действий.
Я бы на это с удовольствием посмотрел. Кажется получится очередная вариация Колмогоровской сложности без какого-либо приложения к программированию.
Почему написал на ФБ что чушь.
- Вы сравняли паттерны доменной логики с парадигмой. Между тем, очень и очень многие системы начинаются одинаково, но в ходе своего развития вырисовываются какие-то конкретные.
- Вы путаете технологии и паттерны доменной логики. Агрегат вполне можно даже разместить в РСУБД (конечно это будет значительным извращением). Технологии в этой задаче вторичны — дело в парадигме декомпозиции.
Напишу скоро свою статью)
Вы путаете технологии и паттерны доменной логики. Агрегат вполне можно даже разместить в РСУБД (конечно это будет значительным извращением). Технологии в этой задаче вторичны — дело в парадигме декомпозиции.
Все таки они связаны, хоть и не явно… вы ведь сами в скобках пишите про то насколько это сложно с данной технологией…
В целом, как я и писал выше уже, меня точность формулировок и конкретные значения на графике мало интересуют. Больше важен инструмент общения между специалистами.
Формально это может быть так, что при проектировании очередного сервиса рассматриваются два варианта организации логики. Тогда можно было бы на графике для каждого из вариантов попробовать изобразить кривую. И сделать более взвешенный выбор.
Напишу скоро свою статью)
Почитаем… ;)
Организация бизнес-логики корпоративных приложений. Какие возможны варианты?