Comments 37
Выглядит круто, обидно что биндинги для всего есть, а для C# - нет. Вроде должно быть не сложнее чем для java.
Всё в ваших руках - проект опенсорсный. Тот же биндинг для Java от стороннего разработчика.
А зачем вам байндинги, если там уже сам парсер есть.
Да собсна тем же самым, чем и наличие байндингов, только без накладных расходов на индирекшн. Есть реализации tree-sitter написанных сразу на языке, и есть байндинги (читай shared library). Останется это дело интегрировать в свои редакторы и скормить ему некоторый набор правил целевого языка/языков. То бишь если хочется писать на C# - подключаем C# реализацию и скармливаем в него правила для любого из поддержанных языков. А уж найти языковые правила с увеличением развития языковых серверов думаю не составит больших проблем.
регулярные выражения, которые применяются построчно, для подсветки кода. Это приводит к тому, что, в отличие от редакторов опирающихся на синтаксические деревья, они не могут знать контекст и подсветка оставляет желать лучшего. Да и производительностью на больших объемах строк такой подход похвастаться не может.
Наоборот, построчный парсинг позволяет парсить код лениво - лишь те, строки, что собираешься показать, а не сразу весь файл. Вот пример. tree-sitter умеет так?
Но проблемы у редакторов использующих регулярные выражения возникают не только когда строк кода много, но и когда она всего одна, зато очень длинная. В этом случае такие редакторы ограничивают максимальную длину строки для подсветки, иначе парсинг регулярками занимал бы слишком много времени.
Регулярки - это такой же конечный автомат как и любой другой парсер. Нет ничего, что делало бы их принципиально медленнее tree-sitter. Опять же, выше пример - там парсится всё регуляркой.
Tree-sitter готов к использованию в виде библиотеки для следующих языков программирования
А как быть с длинным хвостом менее популярных языков? Мучаться без подсветки? Или для каждого языка, который хочешь позволить пользователям использовать, руками реализовывать парсер? Опять же, в примере выше универсальный парсер, которому не надо объяснять что за язык перед ним. tree-sitter умеет хотя бы автоматически язык определять?
Наоборот, построчный парсинг позволяет парсить код лениво - лишь те, строки, что собираешься показать, а не сразу весь файл
С этим соглашусь. Опять же, если строки небольшие.
tree-sitter умеет так?
Как именно? Парсить построчно? Конечно нет. Какое синтаксическое дерево вы хотите получить выдрав непонятный кусок из кода? Производительности tree-sitter хватает распарсить большой файл сразу. Об этом есть упоминание в статье.
Нет ничего, что делало бы их принципиально медленнее tree-sitter. Опять же, выше пример - там парсится всё регуляркой.
Я не знаю что за пример выше вы скинули. Нет ни описания, ни документации. Вы тоже никаких комментариев не дали. Подсунуть что-то в этот "текстовый редактор" не получилось. Минифицируйте код, что там есть в одну строку и проверьте как он себя поведёт - очень интересно посмотреть. Ни Sublime Text 4, ни VSCode не справились. Точнее, ST4 не справился, а VSC просто ограничил длину строки. Atom (c tree-sitter внутри) распарсил и подсветил всё.
А как быть с длинным хвостом менее популярных языков? Мучаться без
подсветки? Или для каждого языка, который хочешь позволить пользователям
использовать, руками реализовывать парсер?
Странный вопрос. Пока нет парсера, нет ни подсветки, ни свёртки, ни прочих прелестей синтаксического анализа. Магии не бывает.
Опять же, в примере выше универсальный парсер, которому не надо объяснять что за язык перед ним.
Очень интересно. Жаль туда ничего вписать не получается. Может вы подскажите за него что за язык перед вами: var x = 1;?
tree-sitter умеет хотя бы автоматически язык определять?
Ещё более странный вопрос. Зачем парсеру (не текстовому редактору, замечу) уметь распознавать язык? Он получает на вход грамматику и текст, а выдаёт синтаксическое дерево.
Какое синтаксическое дерево вы хотите получить выдрав непонятный кусок из кода?
Никакое, я хочу подсветку синтаксиса, даже если это не валидный кусок большого файла. Вот, смотрите, метод без класса:
async foo() {
return 'bar'
}Ни Sublime Text 4, ни VSCode не справились.
Нажмите Alt+Shift+F, не ломайте глаза.
Может вы подскажите за него что за язык перед вами:
var x = 1;?

Ещё более странный вопрос. Зачем парсеру (не текстовому редактору, замечу) уметь распознавать язык? Он получает на вход грамматику и текст, а выдаёт синтаксическое дерево.
Чтобы не приходилось перебирать все грамматики в поисках первой попавшейся, а сразу получать результат с наиболее подходящей.
я хочу подсветку синтаксиса
А я хочу подсветку синтаксиса, find usages, line folding и многие другие нужные и полезные мне фичи.
Нажмите
Alt+Shift+F, не ломайте глаза.
Если вы имеете в виду Format document, то в ST4 я этого не нашел, а VSCode сперва собралась взлететь, судя по рёву вентиляторов, но так ничего и не сделала (если вообще должна была что-то сделать). Проблему длинных строк вы подтверждаете, как я понимаю?
перебирать все грамматики
Я так и не понял зачем их вообще перебирать, тем более парсеру.
Я так понял, что у вас есть какой-то проект с "универсальной" подсветкой синтаксиса. Похвально. Попробуйте превратить его в полноценный текстовый редактор - может и всплывут какие-то проблемы, для решения которых авторы tree-sitter его и создали.
Вы встали в защитную позицию и на указание проблемных мест в предложенном подходе повторяете, какие у него есть достоинства. Достоинства никто не умаляет, тем не менее откройте глаза:

проблемных мест в предложенном подходе
Можно список этих проблемных мест? Я уже запутался о чём вы, т.к. мы ваш проект почему-то обсуждаем, а не tree-sitter.
тем не менее откройте глаза:
Я в typescript не разбираюсь. Зашел на https://www.typescriptlang.org/play и результат там не лучше:
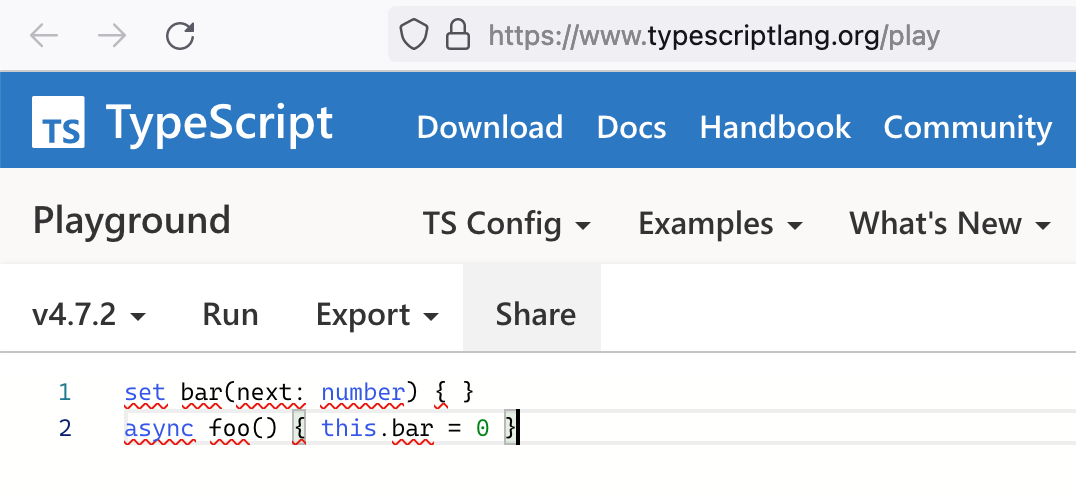
Вы хоть пишите что вы имеете в виду когда кидаете какие-то ссылки или скрины, иначе очень сложно понять что вы хотели сказать.
Ну вот можете обратить внимание, что синтаксис подсвечен независимо от того, что код не валидный. Проще говоря, парсер для подсветки синтаксиса и для стат анализа - это два совершенно разных парсера с совершенно разными требованиями.
Ну вот можете обратить внимание, что синтаксис подсвечен независимо от того, что код не валидный.
Где он подсвечен? В вашем комментарии этого нет. Или вы про скрин из TypeScript Playground? В Tree-sitter Playground такой опции и нет вовсе - это не текстовый редактор, а синтаксический парсер. Подсветкой вольны заниматься продукты на основе этого парсера, если им это нужно. Тот же Atom с tree-sitter внутри этот код подсвечивает, хотя, наверное, и не так красиво как мог бы, из-за наличия ошибок.
Проще говоря, парсер для подсветки синтаксиса и для стат анализа - это
два совершенно разных парсера с совершенно разными требованиями.
Определённо.
Чтобы не приходилось перебирать все грамматики в поисках первой попавшейся, а сразу получать результат с наиболее подходящей.
Это не задача парсера. Тут элементы парсинга, конечно, могут использоваться, но могут использоваться и другие методы, в том числе машинное обучение, так как надо очень быстро детектить. А после натравливать полноценный парсер для более качественного разбора.
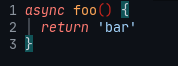
Никакое, я хочу подсветку синтаксиса, даже если это не валидный кусок большого файла. Вот, смотрите, метод без класса:
neovim + TS, подсветка синтаксиса:
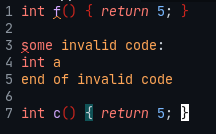
А вот ещё менее валидный код на плюсах (подчёркивание у f от проверки синтаксиса компилятором):
Наоборот, построчный парсинг позволяет парсить код лениво - лишь те, строки, что собираешься показать, а не сразу весь файл. Вот пример. tree-sitter умеет так?
В смысле "наоборот", вы хотите сказать, что на построчных регулярных выражениях можно собрать хоть сколько-то нормальный контекстно-зависимый парсер? Тут дай бог, чтобы не просто поток лексем, а какое-то синтаксическое дерево было.
А как быть с длинным хвостом менее популярных языков
Это биндинги.
Вас никто не заставляет использовать только tree-sitter, подсветку для неподдерживаемых ЯП можно реализовать любым способом.
Проект открыт, если вам нужен биндинг к другому языку, вы можете его написать
Или для каждого языка, который хочешь позволить пользователям использовать, руками реализовывать парсер
Вы не парсер пишете, а грамматику для него.
Опять же, в примере выше универсальный парсер, которому не надо объяснять что за язык перед ним
Вспомнил анекдот про секретаршу, которая печатает "9000 знаков в минуту". 3 строки CL, взятые из гугла, https://tree.hyoo.ru/#!source=(let* ((x 10) (y (%2B x 10))) (list x y)).
собрать хоть сколько-то нормальный контекстно-зависимый парсер
Я не он, но суть в том, что на регулярках можно парсить только те строки что показаны пользователю. Это позволяет сделать какую-нибудь подсветку без лагов.
Проект у @nin-jin интересный. Подойдёт отлично для какого-нибудь stackoverflow где случайные куски кода подсвечивать надо.
Для подсветки синтаксиса не нужен "сколько-то нормальный контекстно-зависимый парсер".
Смешной анекдот, да:


Так вы же его изменили, было:

Стало:
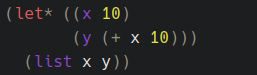
Долго будете изменять парсер под конкретные примеры, выдавая это за общий результат?
Ладно,

Не всё, что в кавычках, это просто строка, так можно и библиотеку подключить.
Почему у scope resolution operator первое двоеточие раскрашено я даже представить не могу.
structc(a) {}это не функция.
Ну и, для простой подсветки синтаксиса хватит и обычного парсера, а вот для хорошей нужен уже контекстно-зависимый.
Ну так, спасибо за бета-тест, баги поправил.
1 - Имя библиотеки задано строкой, всё правильно.
4 - Без понятия что это, с виду похоже на вызов инициализатора.
Для языка, на котором эта приблуда даже не тестировалась и ничего про него не знает, результат вообще отличный.
1. Подключение заголовков должно быть одного цвета.
4.Это инициализация переменной, после которой следует пустое тело ф-ции.
Ну так эта приблуда как раз переваривает всё то, что есть в языках с си-подобным синтаксисом. Шаг влево или вправо --- уже не так, как было с лиспом, как в плюсах.
Можно было вообще взять какой-то APL или идрис :).
Но, стоит признать, как fallback при невозможности определить язык --- вполне себе.
Что у вас на второй картинке и что вы хотите этим сказать?
Не иметь зависимостей, чтобы библиотека (написанная на чистом C) могла быть встроена в любое приложение.
Это странная фраза, сам язык C уже и есть зависимость (в браузере его не запустить).
Можно сравнение с ANTLR4? Все-таки инструменты довольно схожи. Если доработать ANTLR4, то в нем можно делать почти то же самое, что и описано в статье.
Я провел беглый анализ и заметил следующее:
Минусы:
- Формат грамматик: монструозный json сильно проигрывает лаконичному формату g4. Во всяком случае я такие видел для Java и JavaScript (странно, почему не заюзали что-нибудь более удобное?)
- Количество грамматик. Хоть по таргетам (биндингам) получается паритет (хотя не совсем корректно это сравнивать, поскольку tree-sitter написан на C, а ANTLR генерирует код под конкретный язык), по количетву грамматик ANTLR явно обходит tree-sitter: grammars-v4.
Плюсы:
- Инкрементальный парсинг — это все-таки очень важное преимущество для работы в реальном времени.
- Скорей всего большая производительность (я как major контрибьютер в ANTLR могу сказать что там есть проблемы)
Это странная фраза, сам язык C уже и есть зависимость (в браузере его не запустить).
Это цитата с официального сайта. Я ничего с этим поделать не могу. Для браузера есть WebAssembly-биндинг и он прекрасно работает, что можно проверить в песочнице.
Формат грамматик: монструозный json сильно проигрывает лаконичному формату g4.
JSON - это уже внутреннее представление. Грамматика там на JavaScript задаётся (соответственно Java и JavaScript). Почему выбрали именно такой формат не знаю. Возможно, стоило добавить пункт про создание грамматики в статью (update: добавил небольшой пункт про создание парсера).
Количество грамматик
ANTLR, судя по Википедии, был разработан в 1989, а вышел в 1992. Tree-sitter начал разрабатываться около 2014 и был представлен широкой публике в 2017 - проект только стартанул, можно сказать.
Плюсы
Ну в этом и есть суть tree-sitter. Сделать быстрый парсер, заточенный изначально под нужды текстовых редакторов, но не ограничиваясь ими.
Если нужно написать парсер для некоторого формального языка, то старые добрые ANTLR, YACC/Bison и т.п. всё также подходят.
Для браузера есть WebAssembly-биндинг и он прекрасно работает, что можно проверить в песочнице.
Только в браузере не всегда можно и нужно запускать WebAssembly. В ANTLR, например, есть полноценный JavaScript таргет, без зависимостей.
JSON — это уже внутреннее представление. Грамматика там на JavaScript задаётся (соответственно Java и JavaScript).
Посмотрел — на мой взгляд тоже неудачный формат. Самый главный минус — нет статических проверок (если, конечно, это обычный js, который исполняется как js). Менее существенные минусы: отношение разработчиков к этому языку и избыточность для описания языков.
ANTLR, судя по Википедии, был разработан в 1989, а вышел в 1992. Tree-sitter начал разрабатываться около 2014 и был представлен широкой публике в 2017 — проект только стартанул, можно сказать.
Все же корректней учитывать последнюю мажорную версию, а это 4, т.к. формат грамматик менялся. ANTLR 4 начал разрабатываться в 2010, а вышел году в 2011. Грамматики начали активно разрабатываться/портироваться и того позже. Так что разница не такая внушительная.
Если доработать ANTLR4, то в нем можно делать почти то же самоеНу так то «если доработать tree-sitter, он может компилить в js, а не в C». Тем более, никаких экстраординарных конструкций в сгенерированном коде я не вижу, лишь огромные switch-и и тернарные операторы 50-кратной вложенности (по сути, тоже switch-и для диапазонов).
VS Code вроде как использует Language Server'а для работы с кодом - я предполагал, что и парсинг идет через них. Зачем в таком случае используются регулярные выражения?
Действительно, в протоколе Language Server некоторое время назад (декабрь 2020) появилась возможность подсветки на основе semantic tokens. Но, во-первых, была подсветка и до этого, а, во-вторых, нужна подсветка когда LS нет. Для этого VSCode (как и Sublime Text) использует грамматики из редактора TextMate основанные на регулярных выражениях которые применяются построчно.
Интересная статья. Спасибо. Использую nvim в нем работает tree sitter. Единственное, как раз на больших строках в json, когда файл под несколько мегабайт, у меня все наоборот. Tree sitter намертво может повесить редактор nvim, так что кнопки перестают реагировать. Lsp отключал для проверки. А vscode наоборот , хоть и медленно, но остается в работоспособном состоянии, да еще и визуально преобразует строку (не форматируя) в читаемый вид, перенося построчно.
Может, конечно, другие плагины оказывают влияние, но при отключении tree sitter ситуация улучшается.
Tree-sitter: обзор инкрементального парсера