Вступление
Коллеги с соседнего отдела (
UCDN) обратились с довольно интересной и неожиданной проблемой: при тестировании raid0 на большом числе SSD, производительность менялась вот таким вот печальным образом:
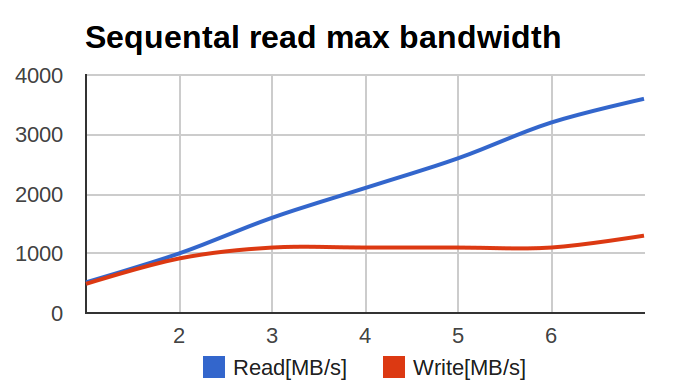
По оси X — число дисков в массиве, по оси Y — мегабайтов в секунду.
Я начал изучать проблему. Первичный диагноз был простой — аппаратный рейд не справился с большим числом SSD и упёрся в свой собственный потолок по производительности.
После того, как аппаратный рейд выкинули и на его место поставили HBA, а диски собрали в raid0 с помощью linux-raid (его часто называют 'mdadm' по названию утилиты командной строки), ситуация улучшилась. Но не прошла полностью -цифры возросли, но всё ещё были ниже рассчётных. При этом ключевым параметром были не IOPS'ы, а многопоточная линейная запись (то есть большие куски данных, записываемых в случайные места).
Ситуация для меня была необычной — я никогда не гонялся за чистым bandwidth рейдов. IOPS'ы — наше всё. А тут — надо многомногомного в секунду и побольше.
Адские графики
Я начал с определения baseline, то есть производительности единичного диска. Делал я это, скорее, для очистки совести.
Вот график линейного чтения с одной SSD.
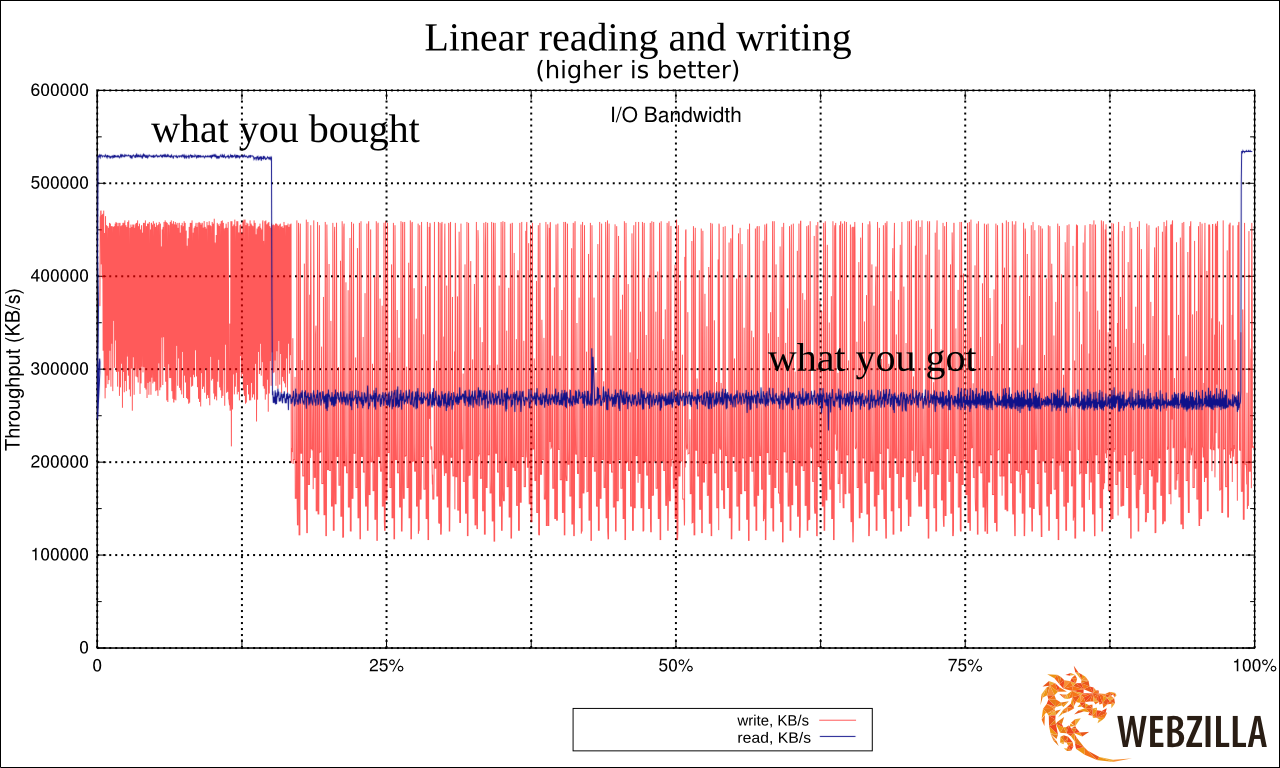
Увидев результат я реально взвился. Потому что это очень сильно напоминало ухищрения, на которые идут производители дешёвых USB-флешек. Они помещают быструю память в районы размещения FAT (таблицы) в FAT32 (файловой системе) и более медленную — в район хранения данных. Это позволяет чуть-чуть выиграть по производительности при работе с мелкими операциями с метаданными, при этом предполагая, что пользователи, копирующие большие файлы во-первых готовы подождать, а во вторых сами операции будут происходить крупными блоками. Подробнее про это душераздирающее явление:
lwn.net/Articles/428584




 Пожалуй, начну с того, что если перегружаться 15 раз в год, то любой «тюнинг» процесса загрузки отнимает больше времени, чем будет выиграно на перезагрузках за все время жизни системы. Однако, спортивный интерес берет свое, тем более, что
Пожалуй, начну с того, что если перегружаться 15 раз в год, то любой «тюнинг» процесса загрузки отнимает больше времени, чем будет выиграно на перезагрузках за все время жизни системы. Однако, спортивный интерес берет свое, тем более, что  Сегодня я расскажу вам немного о
Сегодня я расскажу вам немного о 