Обсуждение анонимности нужно начинать не со слов прокси/тор/впн, а с определения задачи: анонимно подключиться к чужому серверу по SSH это одно, анонимно поднять свой веб-сайт это другое, анонимно работать в инете это третье, etc. — и все эти задачи решаются по-разному. Эта статья о задаче «анонимно работать в интернете как пользователь».
В последнее время на хабре появилось много статей на тему обеспечения анонимности в интернете, но они все описывают подход «немножко анонимен». Быть «немножко анонимным» практически бессмысленно, но, судя по комментариям к этим статьям, многие этого не понимают.
Во-первых, нужно адекватно оценивать потенциального противника. Если вы хотите быть «анонимным», значит вы пытаетесь избежать возможности связывания вашей активности в интернете с вашим физическим расположением и/или настоящим именем. Обычные пользователи и так не имеют возможности вас отслеживать (технически, социальные методы когда по вашему нику на форуме легко гуглится ваш аккаунт в соц.сетях со всеми личными данными мы здесь не рассматриваем). Ваш провайдер/соседи могут иметь возможность прослушать большую часть вашего трафика, но, как правило, вы им не интересны (да, соседи могут украсть ваши пароли, но заниматься отслеживанием вашей активности или вашей деанонимизацией они не станут). Что же касается владельцев используемых вами ресурсов (веб-сайтов, прокси/vpn-серверов, etc.) то у них в распоряжении множество средств по отслеживаю вас (DNS-leaks, Flash/Java-плагины, баннерные сети, «отпечатки браузера», множество разных видов кук, etc.) плюс серьёзный коммерческий интерес к тому, чтобы надёжно вас отслеживать (для таргетирования рекламы, продажи данных, etc.). Ну а правительство и спец.службы могут получить доступ и к данным, которые на вас собирают веб-сайты, и к данным, которые собирают провайдеры. Таким образом получается, что те, кто имеют возможность и желание вас отслеживать — имеют доступ к большинству возможных каналов утечки.
Во-вторых, каналов утечки информации очень и очень много. И они очень разнообразны (от внезапно отключившегося VPN до получения реального IP через Flash/Java-плагины браузера или отправки серийника на свой сервер каким-нить приложением при попытке обновления). Более того, регулярно обнаруживаются (и создаются) новые. Поэтому попытка блокировать каждый из них в индивидуальном порядке, уникальными для каждого методами, просто не имеет смысла, всё-равно что-то где-то протечёт.
В-третьих, при «работе в интернете» используется не только браузер — большинство пользуются так же IM, торрентами, почтой, SSH, FTP, IRC… при этом часто информация передаваемая по этим каналам пересекается и позволяет их связать между собой (.torrent-файл скачанный с сайта под вашим аккаунтом грузится в torrent клиент, ссылка пришедшая в письме/IM/IRC открывается в браузере, etc.). Добавьте сюда то, что ваша ОС и приложения тоже регулярно лазят в инет по своим делам, передавая при этом кучу деанонимизирующей вас информации…
Из всего этого логически следует то, что пытаться добавить «немножко анонимности» путём использования браузера со встроенным Tor, или настройкой торрент-клиента на работу через SOCKS — нет смысла. Большинство вас не сможет отследить и без этих мер, а тех, кто имеет возможности и желание вас отследить эти меры не остановят (максимум — немного усложнят/замедлят их работу).









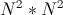 . Полный перебор крайне долгий, ведь время его работы растёт экспоненциально относительно размера входных данных. Например, время поиска максимального пути в графе из 15 вершин наивным перебором становится заметным, а при 20 — очень долгим.
. Полный перебор крайне долгий, ведь время его работы растёт экспоненциально относительно размера входных данных. Например, время поиска максимального пути в графе из 15 вершин наивным перебором становится заметным, а при 20 — очень долгим.