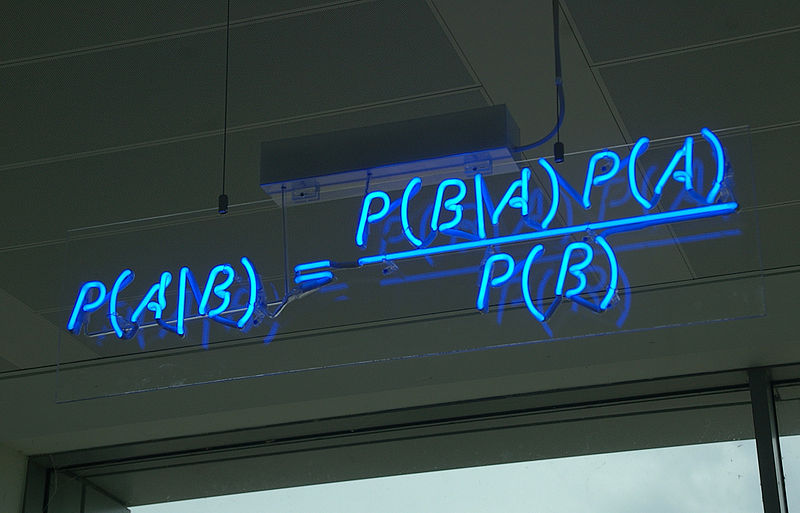Настоящая статья является продолжением предыдущей публикации «Инструменты DataScience как альтернатива классической интеграции ИТ систем». Основная цель — заострить внимание как разработчиков, так и руководителей среднего звена, на широком спектре возможностей, которые предоставляют современные инструменты из сферы Data Science за рамками классических задач статистических вычислений и модной нынче темы машинного обучения. В частности, возможности экосистемы R по состоянию на август 2016 года и применение этих возможностей на примере двух задач: одной из прикладной науки, другой – из среднего бизнеса.

Генрих @Ananiev_Genrih
аналитика и визуализация данных
Небольшое введение в параллельное программирование на R
8 min
Tutorial
Translation
Давайте поговорим об использовании и преимуществах параллельных вычислений в R.
Причина, по которой стоит об этом задуматься: заставляя компьютер больше работать (выполнять много расчетов одновременно), мы меньше времени ждем результатов наших экспериментов и можем выполнить еще. Это особенно важно для анализа данных (R как платформа обычно используется именно для этой цели), поскольку часто требуется повторить вариации одного и того же подхода, чтобы что-то узнать, вывести значения параметров, оценить стабильность модели.
Обычно, для того, чтобы заставить компьютер больше работать, сначала нужно потрудиться самому аналитику, программисту или создателю библиотеки, чтобы организовать вычисления в виде, удобном для параллелизации. В лучшем случае кто-то уже сделал это за вас:
Причина, по которой стоит об этом задуматься: заставляя компьютер больше работать (выполнять много расчетов одновременно), мы меньше времени ждем результатов наших экспериментов и можем выполнить еще. Это особенно важно для анализа данных (R как платформа обычно используется именно для этой цели), поскольку часто требуется повторить вариации одного и того же подхода, чтобы что-то узнать, вывести значения параметров, оценить стабильность модели.
Обычно, для того, чтобы заставить компьютер больше работать, сначала нужно потрудиться самому аналитику, программисту или создателю библиотеки, чтобы организовать вычисления в виде, удобном для параллелизации. В лучшем случае кто-то уже сделал это за вас:
- Хорошие параллельные библиотеки, например, многопоточные BLAS/LAPACK, включены в Revolution R Open (RRO, сейчас Microsoft R Open) (смотреть здесь).
- Специализированные параллельные расширения, предоставляющие свои собственные высокопроизводительные реализации важных процедур, например, методы rx от RevoScaleR или методы h2o от h2o.ai.
- Фреймворки абстрактной параллелизации, например, Thrust/Rth.
- Использование прикладных библиотек R, связанных с параллелизацией (в частности, gbm, boot и vtreat). (Некоторые из этих библиотек не используют параллельные операции, пока не задано окружение для параллельного выполнения.)
8 лекций, которые помогут разобраться в машинном обучении и нейросетях
2 min

Мы собрали интересные лекции, которые помогут понять, как работает машинное обучение, какие задачи решает и что нам в ближайшем будущем ждать от машин, умеющих учиться. Первая лекция рассчитана скорее на тех, кто вообще не понимает, как работает machine learning, в остальных много интересных кейсов.
Агрегирующие функции в dplyr
6 min
Translation
summarise() используется с агрегирующими функциями, которые принимают на вход вектор значений, а возвращают одно. Функция summarise_each() предлагает другой подход к summarise() с такими же результатами.Цель этой статьи — сравнить поведение
summarise() и summarise_each(), учитывая два фактора, которыми мы можем управлять:1. Сколькими переменными оперировать
- 1А, одна переменная
- 1В, более одной переменной
2. Сколько функций применять к каждой переменной
- 2А, одна функция
- 2В, более одной функции
Получается четыре варианта:
- Вариант 1: применить одну функцию к одной переменной
- Вариант 2: применить много функций к одной переменной
- Вариант 3: применить одну функцию к многим переменным
- Вариант 4: применить много функций к многим переменным
Также проверим эти четыре случая с и без опции
group_by().Анализ и визуализация реальных табличных данных в R
13 min
Tutorial
Материал будет полезен тем, кто осваивает язык R в качестве инструмента анализа табличных данных и хочет увидеть сквозной пример реализации основных шагов обработки.
Ниже демонстрируется загрузка данных из csv-файлов, разбор текстовых строк с элементами очистки данных, агрегация данных по аналитическим измерениям и построение диаграмм.
В примере активно используется функциональность пакетов data.table, reshape2, stringdist и ggplot2.
В качестве «реальных данных» взята информация о выданных разрешениях на осуществление деятельности по перевозке пассажиров и багажа легковым такси в Москве. Данные предоставлены в общее пользование Департаментом транспорта и развития дорожно-транспортной инфраструктуры города Москвы. Страница набора данных data.mos.ru/datasets/655
Исходные данные имеют следующий формат:
Ниже демонстрируется загрузка данных из csv-файлов, разбор текстовых строк с элементами очистки данных, агрегация данных по аналитическим измерениям и построение диаграмм.
В примере активно используется функциональность пакетов data.table, reshape2, stringdist и ggplot2.
В качестве «реальных данных» взята информация о выданных разрешениях на осуществление деятельности по перевозке пассажиров и багажа легковым такси в Москве. Данные предоставлены в общее пользование Департаментом транспорта и развития дорожно-транспортной инфраструктуры города Москвы. Страница набора данных data.mos.ru/datasets/655
Исходные данные имеют следующий формат:
ROWNUM;VEHICLE_NUM;FULL_NAME;BLANK_NUM;VEHICLE_BRAND_MODEL;INN;OGRN
1;"А248УЕ197";"ООО «ТАКСИ-АВТОЛАЙН»";"017263";"FORD FOCUS";"7734653292";"1117746207578"
2;"А249УЕ197";"ООО «ТАКСИ-АВТОЛАЙН»";"017264";"FORD FOCUS";"7734653292";"1117746207578"
3;"А245УЕ197";"ООО «ТАКСИ-АВТОЛАЙН»";"017265";"FORD FOCUS";"7734653292";"1117746207578"
```
1. Загрузка первичных данных
Данные можно загружать непосредственно с сайта. В процессе загрузки сразу переименуем колонки удобным образом.url <- "http://data.mos.ru/datasets/download/655"
colnames = c("RowNumber", "RegPlate", "LegalName", "DocNum", "Car", "INN", "OGRN", "Void")
rawdata <- read.table(url, header = TRUE, sep = ";",
colClasses = c("numeric", rep("character",6), NA),
col.names = colnames,
strip.white = TRUE,
blank.lines.skip = TRUE,
stringsAsFactors = FALSE,
encoding = "UTF-8")Создание приложений для СУБД Firebird с использованием различных компонент и драйверов: FireDac
29 min
Tutorial
В данной статье будет описан процесс создания приложений для СУБД Firebird с использованием компонентов доступа FireDac и среды Delphi XE5. FireDac является стандартным набором компонентов доступа к различным базам данных начиная с Delphi XE3.
Наше приложение будет работать с базой данных модель, которой представлена на рисунке ниже.
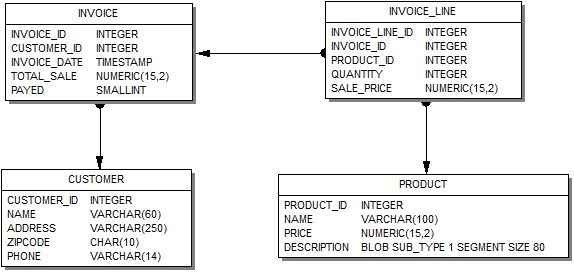
В конце данной статьи приведены ссылки на другие статьи, в которых описывается процесс создания базы данных с этой моделью и ссылка на скрипт создания базы данных.
Наше приложение будет работать с базой данных модель, которой представлена на рисунке ниже.
В конце данной статьи приведены ссылки на другие статьи, в которых описывается процесс создания базы данных с этой моделью и ссылка на скрипт создания базы данных.
| Внимание! Эта модель является просто примером. Ваша предметная область может быть сложнее, или полностью другой. Модель, используемая в этой статье, максимально упрощена для того, чтобы не загромождать описание работы с компонентами описанием создания и модификации модели данных. |
Корреляции для начинающих
6 min
Tutorial
Апдейт для тех, кто сочтет статью полезной и занесет в избранное. Есть приличный шанс, что пост уйдет в минуса, и я буду вынужден унести его в черновики. Сохраняйте копию!
Краткий и несложный материал для неспециалистов, рассказывающий в наглядной форме о различных методах поиска регрессионных зависимостей. Это все и близко не академично, зато надеюсь что понятно. Прокатит как мини-методичка по обработке данных для студентов естественнонаучных специальностей, которые математику знают плохо, впрочем как и автор. Расчеты в Матлабе, подготовка данных в Экселе — так уж повелось в нашей местности

Зачем это вообще надо? В науке и около нее очень часто возникает задача предсказания какого-то неизвестного параметра объекта исходя из известных параметров этого объекта (предикторов) и большого набора похожих объектов, так называемой учебной выборки. Пример. Вот мы выбираем на базаре яблоко. Его можно описать такими предикторами: красность, вес, количество червяков. Но как потребителей нас интересует вкус, измеренный в попугаях по пятибалльной шкале. Из жизненного опыта нам известно, что вкус с приличной точностью равен 5*красность+2*вес-7*количество червяков. Вот про поиск такого рода зависимостей мы и побеседуем. Чтобы обучение пошло легче, попробуем предсказать вес девушки исходя из ее 90/60/90 и роста.
Краткий и несложный материал для неспециалистов, рассказывающий в наглядной форме о различных методах поиска регрессионных зависимостей. Это все и близко не академично, зато надеюсь что понятно. Прокатит как мини-методичка по обработке данных для студентов естественнонаучных специальностей, которые математику знают плохо
Введение
Зачем это вообще надо? В науке и около нее очень часто возникает задача предсказания какого-то неизвестного параметра объекта исходя из известных параметров этого объекта (предикторов) и большого набора похожих объектов, так называемой учебной выборки. Пример. Вот мы выбираем на базаре яблоко. Его можно описать такими предикторами: красность, вес, количество червяков. Но как потребителей нас интересует вкус, измеренный в попугаях по пятибалльной шкале. Из жизненного опыта нам известно, что вкус с приличной точностью равен 5*красность+2*вес-7*количество червяков. Вот про поиск такого рода зависимостей мы и побеседуем. Чтобы обучение пошло легче, попробуем предсказать вес девушки исходя из ее 90/60/90 и роста.
Основы статистики: просто о сложных формулах
6 min
Статистика вокруг нас
Статистика и анализ данных пронизывают практически любую современную область знаний. Все сложнее становится провести границу между современной биологией, математикой и информатикой. Экономические исследования и регрессионный анализ уже практически неотделимы друг от друга. Один из известных методов проверки распределения на нормальность — критерий Колмогорова-Смирнова. А вы знали, что именно Колмогоров внес огромный вклад в развитие математической лингвистики?
Еще будучи студентом психологического факультета СПбГУ, я заинтересовался когнитивной психологией. Кстати, Иммануил Кант не считал психологию наукой, так как не видел возможности применять в ней математические методы. Мои текущие исследования посвящены моделированию психических процессов, и я надеюсь, что такие направления в современной когнитивной психологии, как вычислительные и коннективисткие модели, смягчили бы его отношение!
Визуализация многомерных данных с помощью диаграмм Эндрюса
2 min
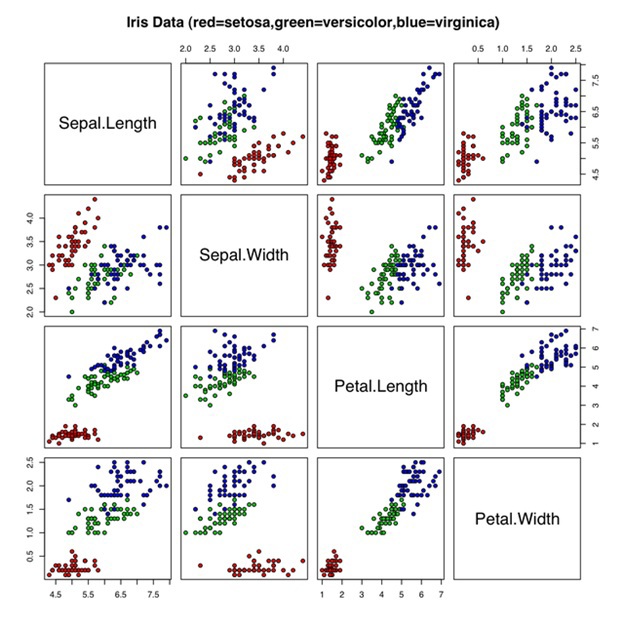
В эпоху Big Data графическое представление многомерных данных является весьма актуальной задачей. Однако результат визуализации не всегда соответствует ожиданиям. Вот пример не самого наглядного графика для изображения многомерных данных «Ирисы Фишера»:
Data tidying: Подготовка наборов данных для анализа на конкретных примерах
5 min
Данная статья возникла в результате переработки и перевода информации на русский язык, взятой из двух источников:
Для профессионалов в области анализа данных это, возможно, выглядит как давно выученная таблица умножения — вряд ли они найдут здесь что-то новое. А тех, кто как и я только знакомится с данной областью и возможностями языка R, приглашаю продолжить чтение.
- из статьи «Tidy Data»
- из соответствующего swirl урока по tidyr package
Для профессионалов в области анализа данных это, возможно, выглядит как давно выученная таблица умножения — вряд ли они найдут здесь что-то новое. А тех, кто как и я только знакомится с данной областью и возможностями языка R, приглашаю продолжить чтение.
Нефтяные ряды в R
6 min
«Графики цен великолепны, чтобы предсказывать прошлое»
Питер Линч
С временными рядами мне как-то не доводилось иметь дело на практике. Я, конечно, читал о них и имел некоторое представление в рамках учебного курса о том, как в общих чертах проводится анализ, но хорошо известно, что то, о чем рассказывают в учебниках по статистике и машинному обучению, не всегда отражает реальное положение дел.
Питер Линч
С временными рядами мне как-то не доводилось иметь дело на практике. Я, конечно, читал о них и имел некоторое представление в рамках учебного курса о том, как в общих чертах проводится анализ, но хорошо известно, что то, о чем рассказывают в учебниках по статистике и машинному обучению, не всегда отражает реальное положение дел.
Как узнать больше о ваших пользователях? Применение Data Mining в Рейтинге Mail.Ru
8 min

Любой интернет-проект можно сделать лучше. Реализовать новые фичи, добавить серверов, переделать интерфейс или выпустить новую версию API. Вашим пользователям это понравится. Или нет? И вообще, что это за люди? Молодые или в возрасте? Обеспеченные или скорее наоборот? Из Москвы? Питера? Сан-Франциско, штат Калифорния? И почему, в конце концов, те сто теплых пледов, что вы закупили еще в мае, пылятся на складе, а футболки с октокотами расходятся, как горячие пирожки? Получить ответы поможет проект Рейтинг Mail.Ru. Эта статья о том, как мы применяем data mining, чтобы ответить на самые сложные вопросы.
Русская документация по языку SQL СУБД Firebird 2.5
1 min
Firebird Project рад объявить о доступности русской документации по языку СУБД Firebird — «Руководство по языку SQL СУБД Firebird».
Руководство можно скачать с официального сайта FirebirdSQL.org или с домашней страницы проекта русской документации.
Русская документация СУБД FirebirdSQL появилась благодаря спонсорам — Московской Бирже (платиновый спонсор и один из крупнейших пользователей Firebird) и IBSurgeon/IBase.ru (золотой спонсор).
На этом работа над документацией по Firebird не заканчивается — будут выпускаться исправления и дополнения к документации по Firebird 2.5, в активной работе находятся разделы, посвященные Firebird 3. На будущий год запланирован выпуск «Руководства по эксплуатации СУБД Firebird» (Firebird Operations Guide).
Руководство можно скачать с официального сайта FirebirdSQL.org или с домашней страницы проекта русской документации.
Русская документация СУБД FirebirdSQL появилась благодаря спонсорам — Московской Бирже (платиновый спонсор и один из крупнейших пользователей Firebird) и IBSurgeon/IBase.ru (золотой спонсор).
На этом работа над документацией по Firebird не заканчивается — будут выпускаться исправления и дополнения к документации по Firebird 2.5, в активной работе находятся разделы, посвященные Firebird 3. На будущий год запланирован выпуск «Руководства по эксплуатации СУБД Firebird» (Firebird Operations Guide).
Если вы никого не злите, возможно вы не делаете ничего существенного
3 min
Это перевод статьи Оливера Эмбертона (Oliver Emberton) «If you’re not pissing someone off, you probably aren’t doing anything important». Оригинал можно найти здесь.
Боретесь с лишним весом? — «Нужно принять и любить своё тело таким, какое оно есть!»
Спасаете детей в Африке? — «Свою страну спасать нужно!»
Нашли лекарство от рака? — «А где ты раньше был?»

Что бы вы ни делали, вы обязательно кого-нибудь разозлите, а это порой не так уж плохо. Позвольте я покажу, как полезно иногда быть козлом.
Невероятно, но ваши значимые действия склонны раздражать окружающих
Боретесь с лишним весом? — «Нужно принять и любить своё тело таким, какое оно есть!»
Спасаете детей в Африке? — «Свою страну спасать нужно!»
Нашли лекарство от рака? — «А где ты раньше был?»
Что бы вы ни делали, вы обязательно кого-нибудь разозлите, а это порой не так уж плохо. Позвольте я покажу, как полезно иногда быть козлом.
Как выявить потери в продажах
3 min

Пример анализа данных на основе продуктового магазина от Datawiz.io.
Эта статья о том, как выявить потери в продажах. Потери в продажах — это дни, когда товар не продавался, или было продано аномально низкое количество единиц товара.
Зачастую потери в продажах случаются из-за недостаточного количества заказанного товара. Также часто товар, имеющийся на складе, не выставляется на полки. Ежедневный анализ данных помогает своевременно обнаружить такой «провал» в продажах. Далее, устраняем проблему — контролируем работу отдела закупок, оптимизируем поставки, контролируем работу торгового персонала.
Как мы кластеризуем подарки в ОК
4 min
Всем привет! Меня зовут Артур, я аналитик в отделе анализа данных департамента рекламных технологий Mail.Ru Group. И я попробую рассказать о том, как мы используем кластеризацию в своей работе.
Чего в этой статье не будет: я не буду рассказывать об алгоритмах кластеризации, об анализе качества или сравнении библиотек. Что будет в этой статье: я покажу на примере конкретной задачи, что такое кластеризация (с картинками), как ее делать если данных действительно много (ДЕЙСТВИТЕЛЬНО много) и что получается в результате.

Чего в этой статье не будет: я не буду рассказывать об алгоритмах кластеризации, об анализе качества или сравнении библиотек. Что будет в этой статье: я покажу на примере конкретной задачи, что такое кластеризация (с картинками), как ее делать если данных действительно много (ДЕЙСТВИТЕЛЬНО много) и что получается в результате.
Power Pivot: Оконные функции под соусом DAX (еще немного специй)
3 min

Продолжение статьи о сравнении возможностей оконных функций SQL Server и формул DAX
10 правил для бизнес-аналитика
4 min
Recovery Mode
Вступление
Я отработал 1,5 года в большой большой компании, которая занимается оптовыми и розничными поставками нефте-газового оборудования (оборот около 30ккк рублей). Внутри внедрена система управления (разработана на 1С), включающая несколько конфигураций для нескольких бухгалтерий, складов и т.д. Около 2к пользователей, работающих в системе ежедневно.
Поддерживает и развивает всю систему команда аналитиков. За это время у нас выработались правила, которые, по моему мнению, помогут всем аналитикам (бизнес, требований) и менеджерам, сотрудникам поддержки и даже немного разработчикам в крупном enterprise сегменте.
Item-based коллаборативная фильтрация своими руками
10 min

Одной из наиболее популярных техник для построения персонализированных рекомендательных систем (RS, чтобы не путать с ПиСи) является коллаборативная фильтрация. Коллаборативная фильтрация бывает двух типов: user-based и item-based. User-based часто используется в качестве примера построения персонализированных RS [на хабре, в книге Т.Сегаран,...]. Тем не менее, у user-based подхода есть существенный недостаток: с увеличением количества пользователей RS линейно увеличивается сложность вычисления персонализированной рекомендации.
Когда количество объектов для рекомендаций большое, затраты на user-based подход могут быть оправданы. Однако во многих сервисах, в том числе и в ivi.ru, количество объектов в разы меньше количества пользователей. Для таких случаев и придуман item-based подход.
В этой статье я расскажу, как за несколько минут можно создать полноценную персонализированную RS на основе item-based подхода.
О формуле Байеса, прогнозах и доверительных интервалах
9 min
На Хабре много статей по этой теме, но они не рассматривают практических задач. Я попытаюсь исправить это досадное недоразумение. Формула Байеса применяется для фильтрации спама, в рекомендательных сервисах и в рейтингах. Без нее значительное число алгоритмов нечеткого поиска было бы невозможно. Кроме того, это формула явилась причиной холивара среди математиков.