Спрос на Android-разработчиков весьма велик сейчас. Я решил подготовить список того, что нужно знать каждому разработчику под эту платформу. Это не только то, что вас могут спросить на собседовании, а весь спектр знаний, который скорее всего пригодится в работе. Бонусом идет пара интерсных вопросов про платформу.

Марат Бектимиров @Bektimirov
User
10 «однострочников», которые произведут впечатление на ваших друзей
13 min
За последнюю неделю появилось несколько топиков с названием «10 однострочников на <MY_LANGUAGE>, которые произведут впечатление на ваших друзей», которые содержат однострочное решение нескольких простых задач, демонстрирующее достоинства и «крутость» любимого языка программирования автора. Я решил перевести их и для сравнения собрать в одном топике. Вся волна началась (вроде как) со Scala.
Итак, поехали!
Итак, поехали!
Dropbox — продолжаем меряться
3 min
Скучно работается… Ну что же. попытаемся ещё больше автоматизировать то что предлагалось тут и здесь =)
На этот раз у нас остаётся лишь basy-скрипт. который позволяет довольно просто и вполне интерактивно нащёлкать себе рефералов. Да, MAC адрес автоматически обновляется, поэтому необходимость в виртуальной машине по сути отпадает… Хотя я бы всё же рекомендовал производить манипуляции со скриптом на ней. Ну просто потому что в процессе своей работы скриптик периодически затирает конфиг дроп-бокса.
Смотрим чего вышло и что с этим делать…
На этот раз у нас остаётся лишь basy-скрипт. который позволяет довольно просто и вполне интерактивно нащёлкать себе рефералов. Да, MAC адрес автоматически обновляется, поэтому необходимость в виртуальной машине по сути отпадает… Хотя я бы всё же рекомендовал производить манипуляции со скриптом на ней. Ну просто потому что в процессе своей работы скриптик периодически затирает конфиг дроп-бокса.
Смотрим чего вышло и что с этим делать…
Использование SPI механизма для создания расширений
5 min
Архитектура большинства Java(и не только) приложений сегодня предусматривает возможность расширения функционала посредством различного рода магических воздействий на код. В последнее время это также стало возможно, если использовать какой-нибудь модный фреймворк или IoC-контейнер. Но что делать, если приложение долгоживущее и слишком сложное для того, чтобы переводить его на использование какого либо фреймворка?
В последнем приложении, с которым я работал, был реализован на тот момент неизвестный мневелосипед SPI механизм, который искал в джарках текстовые файлы вида META-INF/services/<qualified interface name> и брал оттуда название нужного класса, реализующего этот интерфейс, далее этот класс использовался как расширение. Поискав в интернете, узнал, что Service Provider Interface(SPI) представляет собой программный механизм для поддержки сменных компонентов и что этот механизм уже довольно давно используется в Java Runtime Environment(JRE), например в Java Database Connectivity(JDBC):
Благодаря этому коду приложения больше не нуждаются в конструкции Class.forName(<driver class>) (хотя и с ней будут работать), JDBC драйверы будут подгружены автоматически при первом обращении к методам класса DriverManager.
SPI механизм также используется в Java Cryptography Extension(JCE), Java Naming and Directory Service(JNDI), Java API for XML Processing(JAXP), Java Business Integration(JBI), Java Sound, Java Image I/O.
Весь смысл в разделении логики на сервис(Service) и провайдеры(Service Providers). Ссылки на провайдеры сохраняются в джарках расширений в текстовом файле(UTF-8)META-INF/services/<qualified service class> , в каждой строке полное имя класса провайдера. Пустые строки и комментарии(начинающиеся с символа #) игнорируются. Ограничения на провайдеры: они должны реализовывать интерфейс либо наследоваться от класса сервиса и иметь конструктор по умолчанию(zero-argument public constructor).
В последнем приложении, с которым я работал, был реализован на тот момент неизвестный мне
ps = Service.providers(java.sql.Driver.class); try { while (ps.hasNext()) { ps.next(); } } catch (Throwable t) { // Do nothing }
Благодаря этому коду приложения больше не нуждаются в конструкции Class.forName(<driver class>) (хотя и с ней будут работать), JDBC драйверы будут подгружены автоматически при первом обращении к методам класса DriverManager.
SPI механизм также используется в Java Cryptography Extension(JCE), Java Naming and Directory Service(JNDI), Java API for XML Processing(JAXP), Java Business Integration(JBI), Java Sound, Java Image I/O.
Как это работает?
Весь смысл в разделении логики на сервис(Service) и провайдеры(Service Providers). Ссылки на провайдеры сохраняются в джарках расширений в текстовом файле(UTF-8)
Интересная фича Grub2: загрузка из ISO-файла
3 min
Собственно, захотелось мне посмотреть на Unity. По картинкам и видео – вроде ничего. Да вот беда. В виртуальной машине его не запустишь — 3D требует. Сам я KDEшник. Основной ОС на ноутбуке является kubuntu. Ну, думаю, можно поставить второй системой. Свободное место, вроде, есть.
Ок. Качаю образ Natty,прожигаю а вот хрен. Оказалось, не работает мой CD-ROM. Ноут уже довольно старенький. Загрузки с флешек в биосе тоже нет. После кратковременной паники было найдено решение.
Оказалось, что grub2 научился понимать формат ISO 9660 и может загружать ОС прямо из ISO-образа, расположеного на жестком диске. Как выяснилось далее, не все системы готовы к такому повороту событий. Многие по тем или иным причинам приходят в замешательство при загрузке. К счастью, Ubuntu не является одной из них.
Ок. Качаю образ Natty,
Оказалось, что grub2 научился понимать формат ISO 9660 и может загружать ОС прямо из ISO-образа, расположеного на жестком диске. Как выяснилось далее, не все системы готовы к такому повороту событий. Многие по тем или иным причинам приходят в замешательство при загрузке. К счастью, Ubuntu не является одной из них.
Текстурирование спрайтов с помощью (dis)placement map
3 min

Недавно, ковыряя с целью исследования один чужой проект, наткнулся на весьма любопытную и в то же время — очень простую технологию. Сразу скажу, что ковырял я флэшку, но данная технология может быть использована не только во флэше, а вообще — где угодно.
Если коротко, то технология позволяет иметь одну отрендеренную анимацию и накладывать на нее разнообразные скины, тем самым получая внешне различные объекты.
Суть в том, что в изучаемой мной игре есть большое количество анимированных спрайтов человечков (как я изначально считал — заранее отрендеренных). Человечки разные (по-разному одетые, разных цветов и т.п.).
Оптимизируем процесс работы в консоли
4 min
Все привыкли редактировать текст в текстовых редакторах, блокнотах, веб-формах и т.д. В процессе набора текста мы пользуемся привычными стрелками, кнопками «End» и «Home», более опытные зажимают «Ctrl» и стрелками шагают по словам (что, кстати, не всегда работает). И при переходе на консоль мы ориентируемся на те же самые правила, даже не зная, что bash предлагает очень удобные средства и комбинации клавиш, которые очень упрощают работу и минимизируют количество операций для выполнения задачи. К тому же, в bash есть удобные средства работы с историей, масса различных подстановок и других интересных функций. Самые часто используемые мной и любым опытным администратором я и опишу в этой статье.
Trie, или нагруженное дерево
4 min
Здравствуй, Хабрахабр. Сегодня я хочу рассказать о такой замечательной структуре данных как словарь на нагруженном дереве, известной также как префиксное дерево, или trie.
Нагруженное дерево — структура данных реализующая интерфейс ассоциативного массива, то есть позволяющая хранить пары «ключ-значение». Сразу следует оговорится, что в большинстве случаев ключами выступают строки, однако в качестве ключей можно использовать любые типы данных, представимые как последовательность байт (то есть вообще любые).
Что это ?
Нагруженное дерево — структура данных реализующая интерфейс ассоциативного массива, то есть позволяющая хранить пары «ключ-значение». Сразу следует оговорится, что в большинстве случаев ключами выступают строки, однако в качестве ключей можно использовать любые типы данных, представимые как последовательность байт (то есть вообще любые).
Визуализация графов. Метод связывания ребер
7 min
Иногда полезно представить граф в графической форме, так чтобы была видна структура. Можно привести десятки примеров, где это может пригодиться: визуализация иерархии классов и пакетов исходного кода какой-нибудь программы, визуализация социального графа (тот же Twitter или Facebook) или графа цитирования (какие публикации на кого ссылаются) и т.д. Но вот незадача: количество ребер в графе зачастую настолько велико, что нарисованный граф просто невозможно разобрать. Взгляните на эту картинку:
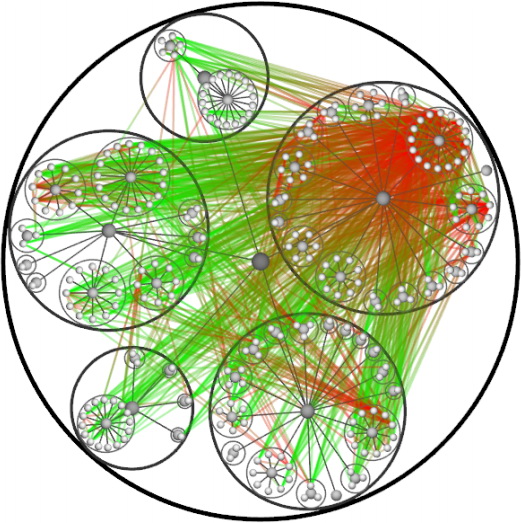
Это граф зависимостей некой программной системы. Он представляет собой дерево разбиения на пакеты (серые шарики — пакеты, белые — классы), на которое поверх наложены ребра зависимости одних классов от других. Чтобы не рисовать стрелки направления, ребра нарисованы в виде градиентных линий, где зеленый — это начало, а красный — конец ребра. Как видите, граф настолько визуально перегружен, что архитектуру программы невозможно проследить.
Под катом описание метода, решающего эту проблему.
Это граф зависимостей некой программной системы. Он представляет собой дерево разбиения на пакеты (серые шарики — пакеты, белые — классы), на которое поверх наложены ребра зависимости одних классов от других. Чтобы не рисовать стрелки направления, ребра нарисованы в виде градиентных линий, где зеленый — это начало, а красный — конец ребра. Как видите, граф настолько визуально перегружен, что архитектуру программы невозможно проследить.
Под катом описание метода, решающего эту проблему.
Примеры xpath-запросов к html
4 min
Xpath — это язык запросов к элементам xml или xhtml документа. Также как SQL, xpath является декларативным языком запросов. Чтобы получить интересующие данные, необходимо всего лишь создать запрос, описывающий эти данные. Всю «черную» работу за вас выполнит интерпретатор языка xpath.
Очень удобно, не правда ли? Давайте посмотри какие возможности предлагает xpath для доступа к узлам веб-страниц.
Очень удобно, не правда ли? Давайте посмотри какие возможности предлагает xpath для доступа к узлам веб-страниц.
Scala + Processing – интересный способ выучить новый язык
4 min
Недавно мне довелось на собственном опыте убедиться: чтобы научиться применять какие-то новые технологии, недостаточно прочитать пару книг по теме, потому что без практики теория мгновенно улетучивается из головы.
Но что можно сделать такого интересного на Scala? На самом деле, выбор не слишком большой. Я как-то придумал небольшую тулзу, неспешно написал ее, и «забил». А через несколько месяцев, к своему стыду, гуглил синтаксис «for loop»…
 Я решил, что дальше так дело не пойдет, и нужно найти какие-то небольшие проектики на основные возможности языка. Тут мне и пригодился Processing. Скучные учебные проекты он любому новичку (вроде меня) поможет превратить в визуальные инсталляции. А дальше можно выбрать, что покопать углубленно — например, генерацию фракталов, рендеринг частиц или визуализацию данных.
Я решил, что дальше так дело не пойдет, и нужно найти какие-то небольшие проектики на основные возможности языка. Тут мне и пригодился Processing. Скучные учебные проекты он любому новичку (вроде меня) поможет превратить в визуальные инсталляции. А дальше можно выбрать, что покопать углубленно — например, генерацию фракталов, рендеринг частиц или визуализацию данных.
Я переписал на Scala и выложил на GitHub парочку примеров. На скрине как раз один из них — MSA Fluids. Заинтересовавшихся прошу под кат.
Но что можно сделать такого интересного на Scala? На самом деле, выбор не слишком большой. Я как-то придумал небольшую тулзу, неспешно написал ее, и «забил». А через несколько месяцев, к своему стыду, гуглил синтаксис «for loop»…
Я решил, что дальше так дело не пойдет, и нужно найти какие-то небольшие проектики на основные возможности языка. Тут мне и пригодился Processing. Скучные учебные проекты он любому новичку (вроде меня) поможет превратить в визуальные инсталляции. А дальше можно выбрать, что покопать углубленно — например, генерацию фракталов, рендеринг частиц или визуализацию данных.Я переписал на Scala и выложил на GitHub парочку примеров. На скрине как раз один из них — MSA Fluids. Заинтересовавшихся прошу под кат.
Декартово дерево: Часть 1. Описание, операции, применения
15 min
Оглавление (на данный момент)
Часть 1. Описание, операции, применения.
Часть 2. Ценная информация в дереве и множественные операции с ней.
Часть 3. Декартово дерево по неявному ключу.
To be continued...
Декартово дерево (cartesian tree, treap) — красивая и легко реализующаяся структура данных, которая с минимальными усилиями позволит вам производить многие скоростные операции над массивами ваших данных. Что характерно, на Хабрахабре единственное его упоминание я нашел в обзорном посте многоуважаемого winger, но тогда продолжение тому циклу так и не последовало. Обидно, кстати.
Я постараюсь покрыть все, что мне известно по теме — несмотря на то, что известно мне сравнительно не так уж много, материала вполне хватит поста на два, а то и на три. Все алгоритмы иллюстрируются исходниками на C# (а так как я любитель функционального программирования, то где-нибудь в послесловии речь зайдет и о F# — но это читать не обязательно :). Итак, приступим.
Введение
В качестве введения рекомендую прочесть пост про двоичные деревья поиска того же winger, поскольку без понимания того, что такое дерево, дерево поиска, а так же без знания оценок сложности алгоритма многое из материала данной статьи останется для вас китайской грамотой. Обидно, правда?
Следующий пункт нашей обязательной программы — куча (heap). Думаю, также многим известная структура данных, однако краткий обзор я все же приведу.
Представьте себе двоичное дерево с какими-то данными (ключами) в вершинах. И для каждой вершины мы в обязательном порядке требуем следующее: ее ключ строго больше, чем ключи ее непосредственных сыновей. Вот небольшой пример корректной кучи:
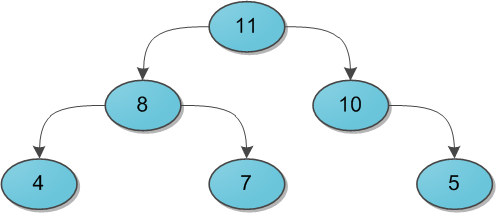
На заметку сразу скажу, что совершенно не обязательно думать про кучу исключительно как структуру, у которой родитель больше, чем его потомки. Никто не запрещает взять противоположный вариант и считать, что родитель меньше потомков — главное, выберите что-то одно для всего дерева. Для нужд этой статьи гораздо удобнее будет использовать вариант со знаком «больше».
Сейчас за кадром остается вопрос, каким образом в кучу можно добавлять и удалять из нее элементы. Во-первых, эти алгоритмы требуют отдельного места на осмотр, а во-вторых, нам они все равно не понадобятся.
Моноиды и их приложения: моноидальные вычисления в деревьях
20 min
Приветствую, Хабрахабр. Сегодня я хочу, в своём обычном стиле, устроить сообществу небольшой ликбез по структурам данных. Только на этот раз он будет гораздо более всеобъемлющ, а его применения и практичность — простираться далеко в самые разнообразные области программирования. Самые красивые применения, я, конечно же, покажу и опишу непосредственно в статье.
Нам понадобится капелька абстрактного мышления, знание какого-нибудь сбалансированного дерева поиска (например, описанного мною ранее декартова дерева), умение читать простой код на C#, и желание применить полученные знания.
Итак, на повестке сегодняшнего дня — моноиды и их основное применение для кеширования вычислений в деревьях.
Представьте себе множество чего угодно, множество, состоящее из объектов, которыми мы собираемся манипулировать. Назовём его M. На этом множестве мы вводим бинарную операцию, то есть функцию, которая паре элементов множества ставит в соответствие новый элемент. Здесь и далее эту абстрактную операцию мы будем обозначать "⊗", и записывать выражения в инфиксной форме: если a и b — элементы множества, то c = a ⊗ b — тоже какой-то элемент этого множества.
Например, рассмотрим все строки, существующие на свете. И рассмотрим операцию конкатенации строк, традиционно обозначаемую в математике "◦", а в большинстве языков программирования "+":
Или другой пример — функция fst, известная в функциональных языках при манипуляции с кортежами. Из двух своих аргументов она возвращает в качестве результата первый по порядку. Так,fst(5, 2) = 5 ; fst( . Безразлично, на каком множестве рассматривать эту бинарную операцию, так что в вашей воле выбрать любое.
Далее мы на нашу операцию "⊗" накладываем ограничение ассоциативности. Это значит, что от неё требуется следующее: если с помощью "⊗" комбинируют последовательность объектов, то результат должен оставаться одинаковым вне зависимости от порядка применения "⊗". Более строго, для любых трёх объектов a, b и c должно иметь место:
(a ⊗ b) ⊗ c = a ⊗ (b ⊗ c)
Легко увидеть, что конкатенация строк ассоциативна: не важно, какое склеивание в последовательности строк выполнять раньше, а какое позже, в итоге все равно получится общая склейка всех строк в последовательности. То же касается и функции fst, ибо:
fst(fst(a, b), c) = a
fst(a, fst(b, c)) = a
Цепочка применений fst к последовательности в любом порядке всё равно выдаст её головной элемент.
И последнее, что мы потребуем: в множестве M по отношению к операции должен существовать нейтральный элемент, или единица операции. Это такой объект, который можно комбинировать с любым элементом множества, и это не изменит последний. Формально выражаясь, если e — нейтральный элемент, то для любого a из множества имеет место:
a ⊗ e = e ⊗ a = a
В примере со строками нейтральным элементом выступает пустая строкаfst(e, a) = e всегда, и если a ≠ e , то свойство нейтральности мы теряем. Можно, конечно, рассмотреть fst на множестве из одного элемента, но кому такая скука нужна? :)
Каждую такую тройку <M, ⊗, e> мы и будем торжественно называть моноидом. Зафиксируем это знание в коде:
Больше примеров моноидов, а также где мы их, собственно, применять будем, лежит под катом.
Нам понадобится капелька абстрактного мышления, знание какого-нибудь сбалансированного дерева поиска (например, описанного мною ранее декартова дерева), умение читать простой код на C#, и желание применить полученные знания.
Итак, на повестке сегодняшнего дня — моноиды и их основное применение для кеширования вычислений в деревьях.
Моноид как концепция
Представьте себе множество чего угодно, множество, состоящее из объектов, которыми мы собираемся манипулировать. Назовём его M. На этом множестве мы вводим бинарную операцию, то есть функцию, которая паре элементов множества ставит в соответствие новый элемент. Здесь и далее эту абстрактную операцию мы будем обозначать "⊗", и записывать выражения в инфиксной форме: если a и b — элементы множества, то c = a ⊗ b — тоже какой-то элемент этого множества.
Например, рассмотрим все строки, существующие на свете. И рассмотрим операцию конкатенации строк, традиционно обозначаемую в математике "◦", а в большинстве языков программирования "+":
"John" ◦ "Doe" = "JohnDoe"Или другой пример — функция fst, известная в функциональных языках при манипуляции с кортежами. Из двух своих аргументов она возвращает в качестве результата первый по порядку. Так,
"foo", "bar") = "foo"Далее мы на нашу операцию "⊗" накладываем ограничение ассоциативности. Это значит, что от неё требуется следующее: если с помощью "⊗" комбинируют последовательность объектов, то результат должен оставаться одинаковым вне зависимости от порядка применения "⊗". Более строго, для любых трёх объектов a, b и c должно иметь место:
Легко увидеть, что конкатенация строк ассоциативна: не важно, какое склеивание в последовательности строк выполнять раньше, а какое позже, в итоге все равно получится общая склейка всех строк в последовательности. То же касается и функции fst, ибо:
fst(fst(a, b), c) = a
fst(a, fst(b, c)) = a
Цепочка применений fst к последовательности в любом порядке всё равно выдаст её головной элемент.
И последнее, что мы потребуем: в множестве M по отношению к операции должен существовать нейтральный элемент, или единица операции. Это такой объект, который можно комбинировать с любым элементом множества, и это не изменит последний. Формально выражаясь, если e — нейтральный элемент, то для любого a из множества имеет место:
a ⊗ e = e ⊗ a = a
В примере со строками нейтральным элементом выступает пустая строка
"": с какой стороны к какой строке её ни приклеивай, строка не поменяется. А вот fst в этом отношении нам устроит подлянку: нейтральный элемент для неё придумать невозможно. Ведь Каждую такую тройку <M, ⊗, e> мы и будем торжественно называть моноидом. Зафиксируем это знание в коде:
public interface IMonoid<T> {
T Zero { get; }
T Append(T a, T b);
}
Больше примеров моноидов, а также где мы их, собственно, применять будем, лежит под катом.
Garbage Collection наглядно
10 min
Translation
В последнее время я работаю с клиентами над вопросами настроек JVM. Смахивает ситуация на то, что далеко не все из разработчиков и администраторов знают о том, как работает garbage collection и о том, как JVM использует память. Поэтому я решил дать вводную в эту тему с наглядным примером. Пост не претендует на то, чтобы покрыть весь объем знаний о garbage collection или настройке JVM (он огромен), ну и, в конце концов, об этом много чего хорошего написано уже в Сети.
Знаешь ли ты JAVA, %username%? Часть вторая
5 min
 В начале января я написал пост с интересными тестовыми задачками по Java. Он вызвал достаточно большой интерес, интересные задачки еще остались, поэтому продолжим.
В начале января я написал пост с интересными тестовыми задачками по Java. Он вызвал достаточно большой интерес, интересные задачки еще остались, поэтому продолжим. Сразу отвечу на некоторые вопросы, ответы на которые могли затеряться в комментах.
Во-первых, спрашивали, что почитать по теме. Очень рекомендую эту книжку. На русском не встречал, но читается она почему-то гораздо легче большинства книг по программированию, так что для большинства это не должно стать проблемой. Во-вторых, спрашивали где взять таких задачек. Тут что-то конкретное не посоветую, задачи из разных источников, в том числе некоторых нефришных наборов тестов, поэтому как вариант можно обратить внимание на источники, ссылки на которые есть в комментах к первой части статьи.
Так получилось, что в данную часть попали более легкие задачи, так что результаты должны быть лучше. Итак, очередной тест под хабракатом (Осторожно, во второй половине ответы и пояснения).
Настройки в Android-приложениях
6 min
Translation
Интересуюсь темой разработки под Android. Пишу небольшое приложение. Столкнулся с тем, что не до конца понимаю как правильно делать настройки для приложения. Немного погуглил, нашел статью, которая помогла разобраться. Решил перевести статью для русскоязычного сообщества, включив некоторые комментарии к оригиналу.
Настройки являются важной частью приложений на Android (и не только на Android — здесь и далее примечание переводчика). Это очень важно — позволять пользователям изменять настройки приложения, в зависимости от их предпочтений.
Существует два пути работы с настройками в Android — можно создать файл preferences.xml в директории res/xml, либо работать с настройками из кода. В данной статье я покажу как работать с настройками, используя preferences.xml файл.
Настройки являются важной частью приложений на Android (и не только на Android — здесь и далее примечание переводчика). Это очень важно — позволять пользователям изменять настройки приложения, в зависимости от их предпочтений.
Существует два пути работы с настройками в Android — можно создать файл preferences.xml в директории res/xml, либо работать с настройками из кода. В данной статье я покажу как работать с настройками, используя preferences.xml файл.
Знаешь ли ты JAVA, %username%?
11 min
Недавно я сдавал экзамен Oracle Certified Professional Java Programmer (бывший Sun Certified), и за время подготовки прорешал огромное количество различных задачек. Отдельные задачки по джаве иногда появляются на хабре и вызывают немалый интерес, поэтому я решил поделиться накопленным и сделать небольшую подборку.Итак, ниже представлен десяток наиболее, на мой взгляд, интересных задач по Java SE из более чем 1000, проработанных мной. Сложность варьируется от средней до ооооооочень сложной. Решение большинства задач практически не требует знания API, достаточно логики и фундаментальных основ Java.
К слову, сложность экзамена Oracle Certified Professional Java Programmer гораздо ниже чем сложность данного теста, поэтому все, кто правильно ответит хотя бы на половину этих вопросов, может смело сдавать этот экзамен без всякой подготовки.
На самом деле количество очень понравившихся мне вопросов в несколько раз больше, поэтому через недельку я планирую написать продолжение данной темы. Если вопросы показались вам слишком легкими или наоборот, слишком сложными — дайте мне знать, внесем коррективы.
ВНИМАНИЕ: во второй половине статьи — ответы и подробные пояснения по соответствующим нюансам JAVA.