
Одной из самых нужных функций, которой нет в бесплатной версии GitLab, является возможность
Сделаем минимальный функционал сами — запретим Merge, пока несколько разработчиков не поставят «палец вверх» на MR.

Пользователь

В этой статье я хочу поделиться своим опытом портирования проекта распознавания музыкальных жанров аудиозаписей на ESP32-C3. Исходный проект взят из репозитория книги TinyML-Cookbook_2E.
При анализе речи или других звуков важно выделить такие характеристики, которые отражают строение сигнала, но при этом не зависят от конкретных слов, громкости и других мешающих факторов. Для этого используют cepstrum, mel-cepstrum и MFCC - это шаги преобразования, которые переводят звук в удобную для анализа форму.

Заголовок не совсем корректен, потому, что 3D версию можно сделать любого 2D материала: фильма, мультфильма, своих личных видео/фото и тд, да хоть скриншот с рабочего стола можно сделать в 3D. Но в данном материале мы будем делать 3D версию фильма.
В качестве материала возьмем Звездные войны. Эпизод IV: Новая надежда (Star Wars. Episode IV: A New Hope, 1977).

Меня давно интересовала тема апскейла изображений, отдельно - апскейла старых видео. Одно из первых решений, которое попалось в руки несколько лет назад - waifu2x (https://github.com/nagadomi/waifu2x). Но эта нейронка больше подходила для апскейла аниме (насколько я помню на них она и тренировалась). То есть, waifu2x подходила для довольно простых изображений без избытка деталей и сложности текстур.
Затем я поизучал ESRGAN (https://github.com/xinntao/ESRGAN) и Real-ESRGAN (https://github.com/xinntao/Real-ESRGAN). Довольно неплохие модельки, вполне годятся для апскейла изображений, но очень часто заметна синтетичность, особенно в сложных сценах, например когда на изображении есть деревья. Я даже попробовал дотренировать Real-ESRGAN, к слову это делать не сложно, на их гитхабе есть скрипты и инструкции (https://github.com/xinntao/Real-ESRGAN/blob/master/docs/Training.md), но пока дособирал свой датасет для тренировки на глаза попалась другая модель - SwinIR (https://github.com/JingyunLiang/SwinIR), потестировав которую понял - она покрывает мои текущие потребности, если не полностью, то по меньшей мере процентов на 80%. А потребности были - заапскейлить несколько старых фильмов, и чтобы после апскейла фильм смотрелся как фильм, а не как пластилиновый театр. В целом все получилось. Именно об этом эта статья.
Апскейлить будем фильм "Пираты Силиконовой долины" (1999г, США, DVD5). Он повествует о появлении домашнего ПК и становлении компаний Apple и Microsoft. Довольно интересный фильм с бунтарским духом той эпохи. Главные герои - молодые Стив Джобс, Стив Возняк, Билл Гейтс и другие участники "революции домашних ПК". Кстати, апскейлить фильм будем конечно же на домашнем ПК.

Так получилось, что неожиданно для меня, в 2022-м году я оказался в США в статусе сотрудника американской компании. Но уже через полтора года я вернулся обратно в Россию. И не думаю, что когда-нибудь опять окажусь в США. Часто мелькают статьи о том, что пора переезжать в США и прочие страны. Однако правда такова, что существенное их количество пишут по заказу компаний, оказывающих услуги по оформлению документов. Много статей от только что покинувших свою страну молодых людей, которым просто не с чем сравнивать то, что они увидели в новой стране из-за отсутствия жизненного опыта. Часть статей написана людьми с весьма странными идеологическими установками. Ну и не исключаю, что часть статей — это откровенная пропаганда, написанная по заказу спецслужб стран, которые в них рекламируются. Поскольку у меня есть свой опыт жизни и работы за рубежом, я решил поделиться некоторыми наблюдениями в отношении «страны мечты» у нескольких поколений наших и не только сограждан. Возможно, кому-то мой, в целом позитивный, опыт поможет не наделать непоправимых ошибок. У меня же всё закончилось благополучно и я вернулся домой.


В 2024 году уже незачем рассказывать об S3-интерфейсе и сравнивать его с другими вариантами организации объектного хранилища. Вот и мы в Ozon, конечно, предоставляем такое платформенное решение широкому спектру внутренних потребителей. От сервисов, которые хранят картинки товаров для каталога, до бэкапов баз данных. От собственных внутренних разработок, до open-source-решений, таких как Gitlab и Thanos.
Пока у вас десятки терабайт и сотни RPS, вас устраивают такие решения, как MinIO. Но по мере роста объёмов и запросов приходится смотреть в сторону таких решений, как Ceph с RGW (RADOS Gateway / Object Gateway). Ну, а когда у вас 3 дата-центра, десятки петабайт данных, миллиарды объектов и десятки тысяч запросов в секунду — в таких условиях и у RGW начинаются проблемы.
Эта история началась с того, что и мы с проблемами масштабирования столкнулись. Под хабракатом вы узнаете, как мы прошли через отрицание проблемы, гнев на Ceph, торг с CTO и разработку собственного решения. Как выбирали технологии, на какие грабли наступили, и что в итоге получилось.


Привет, Хабр! Когда‑то давно я наткнулся на ролик, где парень писал консольный клиент для YouTube. Идея была просто потрясающей!
Написать свой минималистичный и быстрый клиент, который не будет надоедать
лентами рекомендаций, рекламой, комментариями и т. д. Но вот беда, автор, не найдя возможности использовать YouTube API, решил спарсить одну из фронтенд обёрток над YouTube.
Стоит ли говорить о том, что такое решение сильно теряет в производительности и абсолютно нежизнеспособно на какой‑либо длительный период времени?
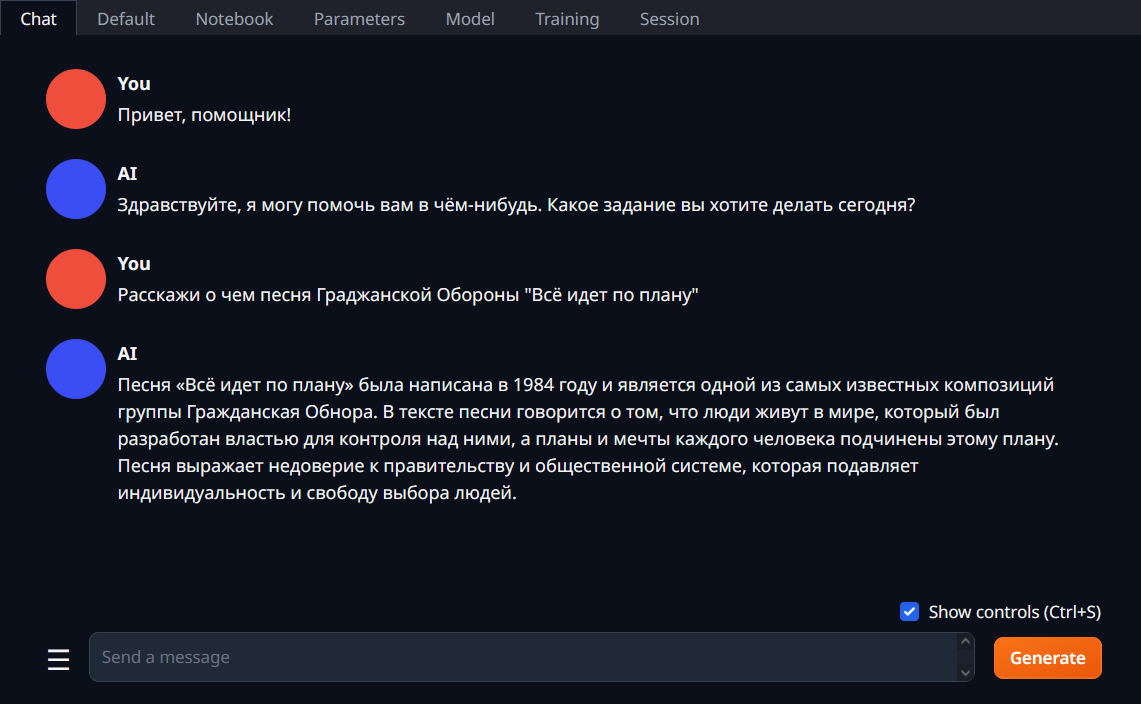
Зачем еще один калькулятор? Да незачем, просто как тестовый проект для рассмотрения GUI-библиотеки.
Изначально я хотел попробовать такие крейты, как GPUI, Floem и Xilem, но первая, кажется, пока работает только под MacOS и Linux, вторая не позволяет установить иконку окну и кушает оперативы побольше Webview в Tauri, а до третьей я так и не добрался, узнав об Slint.
Об Slint есть всего несколько новостных постов на Хабре, поэтому, возможно, вам будет интересно посмотреть, что это такое.

Предлагается пошаговое руководство по дообучению Whisper для любого многоязычного набора данных ASR с использованием Hugging Face ? Transformers. Эта заметка содержит подробные объяснения модели Whisper, набора данных Common Voice и теории дообучения, а также код для выполнения шагов по подготовке данных и дообучению. Для более упрощенной версии с меньшим количеством объяснений, но со всем кодом, см. соответствующий Google Colab.

Часто в криптомире слова децентрализация, смарт-контракты — это всего лишь оболочка для скама или, мягко говоря, нечестных схем.
Страждущие заработать на волнах хайпа оказываются перед проблемой исследования и поиска проектов, что приводит их к необходимость исследования данных из блокчейна и сбора информации о проекте.
Но блокчейн TON из-за свой асинхронной природы и шардируемости смарт-контрактов, сложен для извлечения данных, почти любое действие, представляет собой цепочки из нескольких взаимодействующих смарт-контрактов, которые пересылают друг другу сообщения. Поэтому на примере простой задачи я решил показать, как может быть устроен процесс поиска нужной информации.
В TON последние пару месяцев все внимание приковано к Жетонам - стандарту взаимозаменяемых токенов. Появляется много проектов и нужна какая-то отправная точка в исследованиях.
В этой статье мы разберемся как находить транзакции включающие в себя передачу жетонов и про ранжируем часть жетонов по количество транзакций. И все это с позиции, как вообще может быть устроен процесс раскопки данных.
Дисклеймер: Данная статье не рекламирует никакие проекты, а только лишь предлагает разобраться в сборе данных через индексатор блокчейна на небольшой прикладной задаче.
Откуда будем брать данные? - dton.io
Есть много локальных аналогов ChatGPT, но им не хватает качества, даже 65B модели не могут конкурировать хотя бы с ChatGPT-3.5. И здесь я хочу рассказать про 2 открытые модели, которые всё-таки могут составить такую конкуренцию.
Речь пойдет о OpenChat 7B и DeepSeek Coder. Обе модели за счет размера быстры, можно запускать на CPU, можно запускать локально, можно частично ускорять на GPU (перенося часть слоев на GPU, на сколько хватит видеопамяти) и для такого типа моделей есть графический удобный интерфейс.
И бонусом затронем новую модель для качественного подробного описания фото.
UPD: Добавлена информация для запуска на Windows с ускорением на AMD.
 Источник
ИсточникChaturvedi: «Может, откроете исходный код проекта?»
Andrej Karpathy: «Даже не знаю. Он такой страшный, что мне стыдно».

Кадр из фильма "Иван Васильевич меняет профессию"
Помните этот момент из легендарного произведения Гайдая? Удивительно, насколько по-разному может восприниматься один и тот же человек с одним и тем же лицом. А когда речь идет о миллионах разных людей и нужно найти одного единственного — даже человек уже бессилен, а сверточные нейросети продолжают справляться. Такое большое количество лиц вынуждает искать новые подходы к разграничению. Один из таких подходов — модификации функций потерь, которые помогают нам не потонуть в огромных датасетах при распознавании лиц, довольно точно определяя, кто есть кто.
Под катом мы рассмотрим различные модификации кросс-энтропии для задачи распознавания лиц.
print("hello world")$ python3 hello.py
hello worldreadelf, strace, ldd, debugfs, /proc, ltrace, dd и stat. Я не буду рассматривать относящиеся к Python части, только объясню, что происходит при выполнении динамически компонуемых исполняемых файлов.
Привет!
Меня зовут Стефан Серхир. Я мобильный разработчик в KTS. Пишу под Android, iOS и КММ (Kotlin Multiplatform Mobile) и веду курсы в школе Metaclass.
Недавно мы провели вебинар, в котором разобрали Model-View-Intent (MVI) в KMM на практике и посмотрели, как это выглядит в коде iOS и Android. Это статья написана по мотивам этого вебинара. Подход MVI в KMM полезен, потому что:
— Удобно шарить бизнес-логику между всеми платформами
— Можно выделять отдельный функционал в фича-модули
— Сам MVI позволяет легко разделять экран на различные состояния и менять их в зависимости от действий пользователя
— MVI очень легко ложится на Jetpack Compose (Android) и SwiftUi (iOS)
В статье я расскажу, что такое MVI и KMM вообще, опишу преимущества и недостатки MVI и разберу на практике подход MVI в KMM.

Как сделать зимнюю прогулку по городскому парку увлекательнейшим занятием и больше времени проводить на свежем воздухе? Используйте георадар-тюбинг – новый прибор скрытого пользования, предназначенный для обнаружения подземных аномалий. Статья содержит четыре раздела – введение, техническая реализация, результаты применения и заключение.


Мы решили проверить технологию, на которой основан ChatGPT, посмотреть актуальное состояние open-source GPT-like моделей и ответить на вопрос — можно ли обучить GPT-like модель в домашних условиях?
Для эксперимента выбрали LLaMA и GPT-J и не самый мощный ПК с видеокартой Nvidia GTX 1080TI с 11 GB VRAM. Оказалось, что этого достаточно не только, чтобы загрузить модель, но и дообучить ее (fine-tune). Рассказываем — как мы это сделали.