Сортировка данных является основной задачей для ученых и инженеров по обработке данных. Пользователи Python могут выбирать наиболее удобную из ряда библиотек со встроенными, оптимизированными опциями сортировки. Некоторые даже работают параллельно с GPU. На удивление, некоторые методы сортировки не используют указанные типы алгоритмов, а другие работают совсем не так, как ожидалось.
Выбор библиотеки и типа алгоритма сортировки не всегда прост, а нововведения меняются в быстром темпе. На данный момент документация Pandas не соответствует коду (хотя лично мое PR-обновление сортировочных опций было самым последним).
В этой статье я разъясню вам, что к чему, дам пару советов, которые помогут с разобраться с методами, и поделюсь результатами теста скорости.
UPD 17 июля 2019: В результаты оценки теста скорости теперь входят реализации GPU PyTorch и TensorFlow. TensorFlow также включает в себя результаты CPU как при
tensorflow==2.0.0-beta1, так и при
tensorflow-gpu==2.0.0-beta1. Интересные наблюдения: графический процессор PyTorch буквально летает, а GPU TensorFlow оказался медленнее CPU TensorFlow.
Контекст
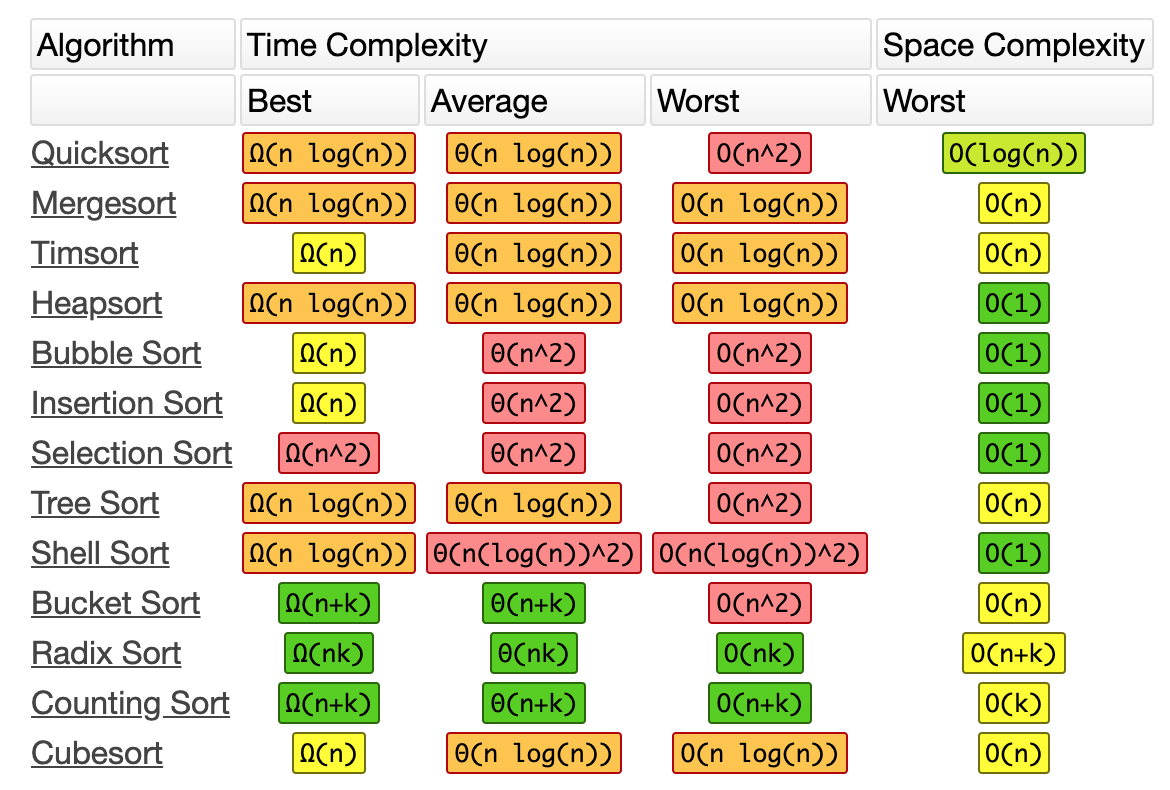
Базовых алгоритмов сортировки существует множество. Одни из них имеют высокую производительность и занимают меньше места, другие хорошо работают с большим числом данных. Для некоторых алгоритмов важно взаимное расположение элементов данных. На диаграмме в начале статьи можно увидеть ситуацию по времени и объему для самых распространенных алгоритмов.