Привет! Меня зовут Александр, я работаю в команде матчинга Ozon. Ежедневно мы имеем дело с десятками миллионов товаров, и наша задача — поиск и сопоставление одинаковых предложений (нахождение матчей) на нашей площадке, чтобы вы не видели бесконечную ленту одинаковых товаров.
На странице любого товара на Ozon есть картинки, заголовок, описание и дополнительные атрибуты. Всю эту информацию мы хотим извлекать и обрабатывать для решения разных задач. И особенно она важна для команды матчинга.
Чтобы извлекать признаки из товара, мы строим его векторные представления (эмбеддинги), используя различные текстовые модели (fastText, трансформеры) для описаний и заголовков и целый набор архитектур свёрточных сетей (ResNet, Effnet, NFNet) — для картинок. Далее эти векторы используются для генерации фичей и товарного сопоставления.
На Ozon ежедневно появляются миллионы обновлений — и считать эмбеддинги для всех моделей становится проблематично. А что, если вместо этого (где каждый вектор описывает отдельную часть товара) мы получим один вектор для всего товара сразу? Звучит неплохо, только как бы это грамотно реализовать…


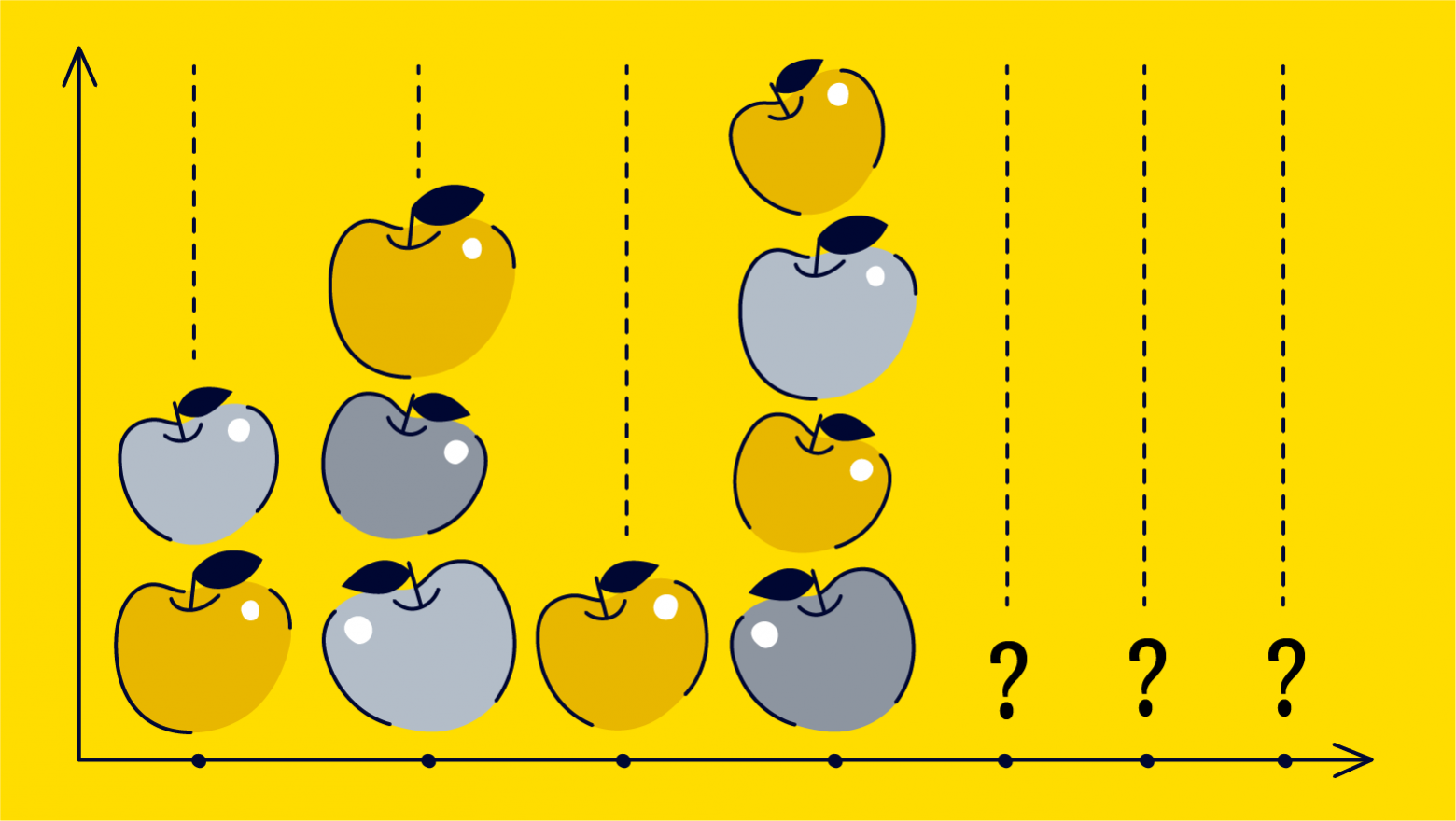






 Здравствуйте, коллеги. Рассмотрим обычный онлайн-эксперимент в некоторой компании «Усы и когти». У неё есть веб-сайт, на котором есть красная кнопка в форме прямоугольника с закругленными краями. Если пользователь нажимает на эту кнопку, то где-то в мире мурлычет от радости один котенок. Задача компании — максимизация мурлыкания. Также есть отдел маркетинга, который усердно исследует формы кнопок и то, как они влияют на конверсию показов в клико-мурлыкания. Потратив почти весь бюджет компании на уникальные исследования, отдел маркетинга разделился на четыре противоборствующие группировоки. У каждой группировки есть своя гениальная идея того, как должна выглядеть кнопка. В целом никто не против формы кнопки, но красный цвет раздражает всех маркетологов, и в итоге было предложено четыре альтернативных варианта. На самом деле, даже не так важно, какие именно это варианты, нас интересует тот вариант, который максимизирует мурлыкания. Маркетинг предлагает провести A/B/n-тест, но мы не согласны: и так на эти сомнительные исследования спущено денег немерено. Попробуем осчастливить как можно больше котят и сэкономить на трафике. Для оптимизации трафика, пущенного на тесты, мы будем использовать шайку многоруких байесовских бандитов (bayesian multi-armed bandits). Вперед.
Здравствуйте, коллеги. Рассмотрим обычный онлайн-эксперимент в некоторой компании «Усы и когти». У неё есть веб-сайт, на котором есть красная кнопка в форме прямоугольника с закругленными краями. Если пользователь нажимает на эту кнопку, то где-то в мире мурлычет от радости один котенок. Задача компании — максимизация мурлыкания. Также есть отдел маркетинга, который усердно исследует формы кнопок и то, как они влияют на конверсию показов в клико-мурлыкания. Потратив почти весь бюджет компании на уникальные исследования, отдел маркетинга разделился на четыре противоборствующие группировоки. У каждой группировки есть своя гениальная идея того, как должна выглядеть кнопка. В целом никто не против формы кнопки, но красный цвет раздражает всех маркетологов, и в итоге было предложено четыре альтернативных варианта. На самом деле, даже не так важно, какие именно это варианты, нас интересует тот вариант, который максимизирует мурлыкания. Маркетинг предлагает провести A/B/n-тест, но мы не согласны: и так на эти сомнительные исследования спущено денег немерено. Попробуем осчастливить как можно больше котят и сэкономить на трафике. Для оптимизации трафика, пущенного на тесты, мы будем использовать шайку многоруких байесовских бандитов (bayesian multi-armed bandits). Вперед.