Многим из вас знаком Wireshark — анализатор трафика, который помогает понять работу сети, диагностировать проблемы, и вообще умеет кучу вещей.
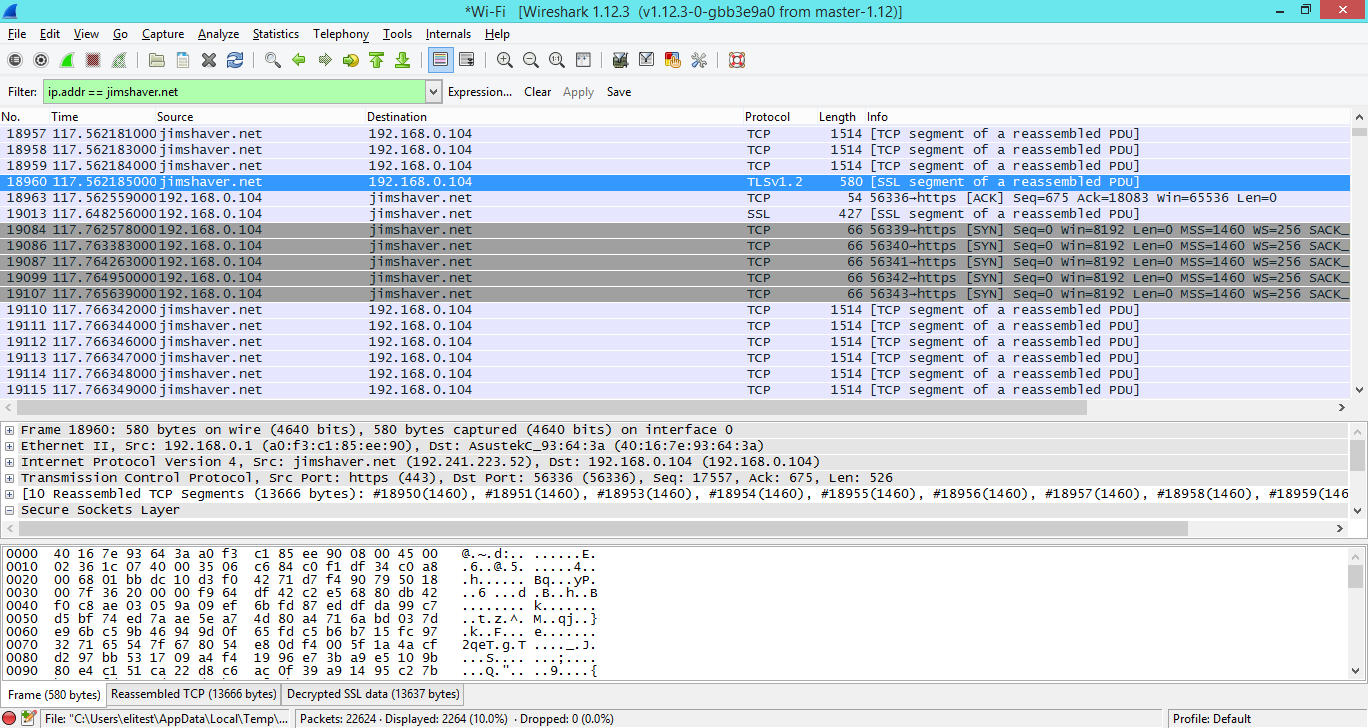
Одна из проблем с тем, как работает Wireshark, заключается в невозможности легко проанализировать зашифрованный трафик, вроде TLS. Раньше вы могли указать Wireshark приватные ключи, если они у вас были, и расшифровывать трафик на лету, но это работало только в том случае, если использовался исключительно RSA. Эта функциональность сломалась из-за того, что люди начали продвигать совершенную прямую секретность (Perfect Forward Secrecy), и приватного ключа стало недостаточно, чтобы получить сессионный ключ, который используется для расшифровки данных. Вторая проблема заключается в том, что приватный ключ не должен или не может быть выгружен с клиента, сервера или HSM (Hardware Security Module), в котором находится. Из-за этого, мне приходилось прибегать к сомнительным ухищрениям с расшифровкой трафика через man-in-the-middle (например, через
sslstrip).
Логгирование сессионных ключей спешит на помощь!
Что ж, друзья, сегодня я вам расскажу о способе проще! Оказалось, что Firefox и Development-версия Chrome поддерживают логгирование симметричных сессионных ключей, которые используются для зашифровки трафика, в файл. Вы можете указать этот файл в Wireshark, и (вуаля!) трафик расшифровался. Давайте-ка настроим это дело.







 Реляционные базы данных (РБД) используются повсюду. Они бывают самых разных видов, от маленьких и полезных SQLite до мощных Teradata. Но в то же время существует очень немного статей, объясняющих принцип действия и устройство реляционных баз данных. Да и те, что есть — довольно поверхностные, без особых подробностей. Зато по более «модным» направлениям (большие данные, NoSQL или JS) написано гораздо больше статей, причём куда более глубоких. Вероятно, такая ситуация сложилась из-за того, что реляционные БД — вещь «старая» и слишком скучная, чтобы разбирать её вне университетских программ, исследовательских работ и книг.
Реляционные базы данных (РБД) используются повсюду. Они бывают самых разных видов, от маленьких и полезных SQLite до мощных Teradata. Но в то же время существует очень немного статей, объясняющих принцип действия и устройство реляционных баз данных. Да и те, что есть — довольно поверхностные, без особых подробностей. Зато по более «модным» направлениям (большие данные, NoSQL или JS) написано гораздо больше статей, причём куда более глубоких. Вероятно, такая ситуация сложилась из-за того, что реляционные БД — вещь «старая» и слишком скучная, чтобы разбирать её вне университетских программ, исследовательских работ и книг.
