MySQL стал собственностью Oracle, есть ли альтернативы и как быстро движение вперед?.. Вроде как обобщающего обзорчика «who is who?» еще не было. Итак, обзорчик для тех кто «не в теме»

/devel
Трюки с CSS-анимациями: мгновенные изменения, отрицательные задержки, анимация transform-origin и другое
14 min
Translation
Применяя CSS-анимации в повседневной работе, я постепенно выработал привычку экспериментировать с ними в свободное время. Постоянно пытаясь реализовать очередную интересную задумку с использованием как можно меньшего числа элементов HTML, я обнаружил немало способов сделать с помощью CSS довольно неочевидные вещи. В этой статье я хочу поделиться некоторыми из них.
Обычно анимации используются для того, чтобы плавно менять свойства элементов со временем. Однако изменения могут также быть практически мгновенными. Для этого надо задать два ключевых кадра с очень маленьким интервалом, например в 0.001%:
Вот как я использовал этот приём для имитации мигающей неоновой вывески с помощью прозрачности и свойства

Быстрое изменение состояния посреди анимации
Обычно анимации используются для того, чтобы плавно менять свойства элементов со временем. Однако изменения могут также быть практически мгновенными. Для этого надо задать два ключевых кадра с очень маленьким интервалом, например в 0.001%:
@keyframes toggleOpacity {
50% { opacity: 1; } /* Turn off */
50.001% { opacity: 0.4; }
/* Keep off state for a short period */
52.999% { opacity: 0.4; } /* Turn back on */
53% { opacity: 1; }
}
Вот как я использовал этот приём для имитации мигающей неоновой вывески с помощью прозрачности и свойства
text-shadow:Mysql Отложенная репликация или Коммивояжеры с Mysql-slave
3 min
Недавно мне поставили такую задачу: Есть много коммивояжеров с ноутбуками которые разъезжают по стране и что-то кому-то впаривают продают.
Т.к. им нужны актуальные данные о наличии товара и ценах, время от времени они подключаются к центральному серверу через интернет и сливают себе обновленные данные.
Условия к задаче:
— Частота и периодичность выхода на связь коммивояжеров неизвестна, ровно как и длительность.
— Должно все работать максимально надежно, потому как коммивояжеры они такие «коммивояжеры».
— Решение должно быть на базе Mysql master-slave replication.
Выводы из условия:
— Для надежности, на стороне клиента(slave) минимум настроек, никаких скриптов по крону, все должно быть внутри mysql.
— Т.к. неизвестно когда и с какой периодичностью будут подключаться к master базе коммивояжеры, binlog на мастере нужно хранить так долго пока все slave не скачают его себе.
Решение:
— Информировать мастер, какие slave и сколько уже «скачали». А точнее в какой позиции самый «ленивый» slave.
— Все остальные binlog можно смело удалять.
Т.к. им нужны актуальные данные о наличии товара и ценах, время от времени они подключаются к центральному серверу через интернет и сливают себе обновленные данные.
Условия к задаче:
— Частота и периодичность выхода на связь коммивояжеров неизвестна, ровно как и длительность.
— Должно все работать максимально надежно, потому как коммивояжеры они такие «коммивояжеры».
— Решение должно быть на базе Mysql master-slave replication.
Выводы из условия:
— Для надежности, на стороне клиента(slave) минимум настроек, никаких скриптов по крону, все должно быть внутри mysql.
— Т.к. неизвестно когда и с какой периодичностью будут подключаться к master базе коммивояжеры, binlog на мастере нужно хранить так долго пока все slave не скачают его себе.
Решение:
— Информировать мастер, какие slave и сколько уже «скачали». А точнее в какой позиции самый «ленивый» slave.
— Все остальные binlog можно смело удалять.
Движок на MySQL за 5 минут
4 min
Tutorial
Начиная с версии 5.1 в MySQL реализована поддержка динамически подключаемых плагинов. А дистрибутив содержит примерный скелет кода под названием – example. Он описывает интерфейс и структуру базового обработчика – handler, копия которого создается отдельно для каждого соединения с БД. Также ему передаётся указатель на дескриптор таблицы TABLE *table и вспомогательный вектор TABLE_SHARE *share, используемый для синхронизации с другими обработчиками. Разработку плагина можно осуществлять по модульному принципу, реализуя только необходимые функции в первую очередь и закрывая заглушками более сложные операции.
Поскольку шаблон example описывает только интерфейс и не выполняет никаких операций, то в этом примере мы добавим в него реализацию CRUD-операций на основе одно-связного списка.
Поскольку шаблон example описывает только интерфейс и не выполняет никаких операций, то в этом примере мы добавим в него реализацию CRUD-операций на основе одно-связного списка.
Отказоустойчивый кластер Master-Slave на PostgreSQL
9 min
Приветствую, хаброжители!
В этой статье я хочу поделиться опытом развертывания кластера Master-slave на СУБД PostgreSQL. Отказоустойчивость достигается с помощью возможностей pgpool-II (failover, online recovery).
pgpool — это прекрасное средство для масштабирования и распределения нагрузки между серверами и, думаю, немногие знают о возможностях автоматического создания failover на ведомом сервере при отказе ведущего и как добавить новые мощности в уже работающий кластер без отключения всего кластера.
В этой статье я хочу поделиться опытом развертывания кластера Master-slave на СУБД PostgreSQL. Отказоустойчивость достигается с помощью возможностей pgpool-II (failover, online recovery).
pgpool — это прекрасное средство для масштабирования и распределения нагрузки между серверами и, думаю, немногие знают о возможностях автоматического создания failover на ведомом сервере при отказе ведущего и как добавить новые мощности в уже работающий кластер без отключения всего кластера.
Обзор важнейших фич Postgres 9.3: материализованные представления
7 min
Translation
PostgreSQL 9.3 выйдет с довольно-таки крутой фичей, называющейся материализованные представления. Фича была разработан Кевином Гриттнером и не так давно закоммичена:
commit 3bf3ab8c563699138be02f9dc305b7b77a724307
Дата: Воскресенье 4 Марта 18:23:31 2013 -0600
Автор: Кевин Гриттнер
Добавлены материализованные представления
У материализованного представления есть правило, так же как и у обычного представления, и куча, а также другие физические свойства, как у таблицы. Правило используется только для наполнения таблицы, ссылки в запросах указывают на материализованные данные.
Реализована минимальная функциональность, но и она может быть полезной во многих случаях. В настоящее время данные загружаются только “по требованию” инструкциями CREATE MATERIALIZED VIEW и REFRESH MATERIALIZED VIEW. Ожидается, что в будущих релизах будут добавлены инкрементальные обновления данных с различными настройками времени обновления, и будет дано более четкое определение самому понятию “свежие” данные. В какой-то момент даже запросы смогут использовать материализованные данные вместо данных самих таблиц, но это требует реализации описанного выше функционала в первую очередь.
Большая часть работы по составлению документации проделал Robert Haas. Ревью: Noah Misch, Thom Brown, Robert Haas, Marko Tiikkaja. Ревью по вопросам безопасности, включающее решение о том, как лучше реализовать sepgsql, ожидается от KaiGai Kohei.
PostgreSQL 9.3 Что нового?
9 min

Здравствуйте, хабрачеловеки! Не так уж давно вышел релиз PostgreSQL 9.3 и я хотел бы ознакомить Вас с наиболее важными новшествами, касающимися клиентской части, которые, возможно, пригодятся Вам. В этой статье рассмотрено следующее:
- материализированные представления
- обновляемые представления
- триггеры к событиям
- рекурсивные представления
- латеральное присоединение
- изменяемые внешние таблицы
- функции и операторы для работы с типом JSON
Magic Tester. Как неподготовленный человек замечает ошибки, и как научить тому же робота
11 min
Привет! Меня зовут Илья Кацев, и я представляю небольшое исследовательское подразделение в отделе тестирования в Яндексе. Вы уже могли читать о нашем экспериментальном проекте Роботестер — роботе, который умеет проделывать за тестировщика заметную часть рутинной работы.
Наша основная цель — изобрести принципиально новые подходы для нахождения ошибок в Яндексе. Я очень люблю порассуждать на тему того, какая часть работы в будущем ляжет на плечи роботов. Они уже отлично пишут спортивные репортажи и переносят грузы для солдат. И вообще мне кажется, что человеческий прогресс непосредственно зависит от того объема работы, который мы сможем передать роботам — у людей в этом случае появляется свободное время и они придумывают новые крутые штуки.

Есть такой тезис, сторонником которого я лично являюсь, — любую ошибку, которую может заметить неподготовленный пользователь, может обнаружить и робот. Именно это мы и попытались проверить. Но тут возникает вопрос: что именно человек считает ошибкой?
Искусственный интеллект пока никто не изобрёл (хотя Хокинг, например, считает, что это к лучшему), но кое-каких успехов нам удалось добиться. В этом посте я расскажу о том, как мы формулировали опыт, которым обладают тестировщики-люди и постарались научить ему наших роботов, и что из этого вышло.
Наша основная цель — изобрести принципиально новые подходы для нахождения ошибок в Яндексе. Я очень люблю порассуждать на тему того, какая часть работы в будущем ляжет на плечи роботов. Они уже отлично пишут спортивные репортажи и переносят грузы для солдат. И вообще мне кажется, что человеческий прогресс непосредственно зависит от того объема работы, который мы сможем передать роботам — у людей в этом случае появляется свободное время и они придумывают новые крутые штуки.
Есть такой тезис, сторонником которого я лично являюсь, — любую ошибку, которую может заметить неподготовленный пользователь, может обнаружить и робот. Именно это мы и попытались проверить. Но тут возникает вопрос: что именно человек считает ошибкой?
Искусственный интеллект пока никто не изобрёл (хотя Хокинг, например, считает, что это к лучшему), но кое-каких успехов нам удалось добиться. В этом посте я расскажу о том, как мы формулировали опыт, которым обладают тестировщики-люди и постарались научить ему наших роботов, и что из этого вышло.
Делать Алгоритмы Маркова — это весело
3 min
Писать Нормальные Алгоритмы Маркова, это безумно интересно и забавно. Интересно ли узнать о том, как мы делали лучшую в мире IDE для Нормальных Алгоритмов Маркова?
Долой оковы MongoDB
6 min
Многие из нас в свое время бросились с энтузиазмом осваивать MongoDB, действительно красота — удобный JSON формат, гибкая схема (точнее полное ее отсутствие), от установки системы до первого использования проходят буквально минуты. Но через некоторое время, уже когда Mongo надежно «зашита» в наш проект наступает разочарование. Простейшие запросы требуют постоянного тыкания в документацию, чуть более сложные способны убить почти целый день рабочего времени, а уж если понадобится join разных коллекций — то увы…
И вот уже кто-то возвращается к Постгресу с его частичной поддержкой JSON…
Но, к счастью, уже куется, уже спешит к нам полноценная замена Mongo, полноценная полу-структурированная Big Data СУБД AsterixDB. Этот проект возглавляет профессор UCI Michael Carey, ученик легендарного пионера СУБД Майкла Стоунбрейкера.
Проект стартовал просто как исследовательское начинание в области Big Data и изначально ориентировался на создание общего стэка для MapReduce и SQL. Но, буквально несколько лет назад, было принято решение построить Big Data JSON СУБД. По словам Майкла Кери, «AsterixDB is Mongo done right.» В чем же основные фишки AsterixDB?
И вот уже кто-то возвращается к Постгресу с его частичной поддержкой JSON…
Но, к счастью, уже куется, уже спешит к нам полноценная замена Mongo, полноценная полу-структурированная Big Data СУБД AsterixDB. Этот проект возглавляет профессор UCI Michael Carey, ученик легендарного пионера СУБД Майкла Стоунбрейкера.
Проект стартовал просто как исследовательское начинание в области Big Data и изначально ориентировался на создание общего стэка для MapReduce и SQL. Но, буквально несколько лет назад, было принято решение построить Big Data JSON СУБД. По словам Майкла Кери, «AsterixDB is Mongo done right.» В чем же основные фишки AsterixDB?
Параллельные и распределенные вычисления. Лекции от Яндекса для тех, кто хочет провести праздники с пользой
3 min
Tutorial
Праздничная неделя подходит к концу, но мы продолжаем публиковать лекции от Школы анализа данных Яндекса для тех, кто хочет провести время с пользой. Сегодня очередь курса, важность которого в наше время сложно переоценить – «Параллельные и распределенные вычисления».
Что внутри: знакомство с параллельными вычислениями и распределёнными системами обработки и хранения данных, а также выработка навыков практического использования соответствующих технологий. Курс состоит из четырех основных блоков: concurrence, параллельные вычисления, параллельная обработка больших массивов данных и распределенные вычисления.
Лекции читает Олег Викторович Сухорослов, старший научный сотрудник Центра грид-технологий и распределенных вычислений ИСА РАН. Доцент кафедры распределенных вычислений ФИВТ МФТИ. Кандидат технических наук.
Что внутри: знакомство с параллельными вычислениями и распределёнными системами обработки и хранения данных, а также выработка навыков практического использования соответствующих технологий. Курс состоит из четырех основных блоков: concurrence, параллельные вычисления, параллельная обработка больших массивов данных и распределенные вычисления.
Лекции читает Олег Викторович Сухорослов, старший научный сотрудник Центра грид-технологий и распределенных вычислений ИСА РАН. Доцент кафедры распределенных вычислений ФИВТ МФТИ. Кандидат технических наук.
Лекции от Яндекса для тех, кто хочет провести каникулы с пользой. Дискретный анализ и теория вероятностей
3 min
Tutorial
Для тех, кому одного курса на праздники мало и кто хочет больше, продолжаем нашу серию курсов от Школы анализа данных Яндекса. Сегодня подошла очередь курса «Дискретный анализ и теория вероятностей» – даже более фундаментального, чем предыдущий. Но без него нельзя представить ещё большую часть современной обработки данных.
В рамках курса рассматриваются основные понятия и методы комбинаторного, дискретного и асимптотического анализа, теории вероятностей, статистики и на примере решения классических задач демонстрируется их применение.

Читает курс Андрей Райгородский. Доктор физико-математических наук. Профессор кафедры математической статистики и случайных процессов механико-математического факультета МГУ им. М. В. Ломоносова. Заведующий кафедрой Дискретной математики ФИВТ МФТИ. Профессор и научный руководитель бакалавриата кафедры «Анализ данных» факультета инноваций и высоких технологий МФТИ. Руководитель отдела теоретических и прикладных исследований компании «Яндекс». (Ещё больше можно узнать в статье о нём на Википедии).
В рамках курса рассматриваются основные понятия и методы комбинаторного, дискретного и асимптотического анализа, теории вероятностей, статистики и на примере решения классических задач демонстрируется их применение.
Читает курс Андрей Райгородский. Доктор физико-математических наук. Профессор кафедры математической статистики и случайных процессов механико-математического факультета МГУ им. М. В. Ломоносова. Заведующий кафедрой Дискретной математики ФИВТ МФТИ. Профессор и научный руководитель бакалавриата кафедры «Анализ данных» факультета инноваций и высоких технологий МФТИ. Руководитель отдела теоретических и прикладных исследований компании «Яндекс». (Ещё больше можно узнать в статье о нём на Википедии).
Machine Learning. Курс от Яндекса для тех, кто хочет провести новогодние каникулы с пользой
8 min
Tutorial
Новогодние каникулы – хорошее время не только для отдыха, но и для самообразования. Можно отвлечься от повседневных задач и посвятить несколько дней тому, чтобы научиться чему-нибудь новому, что будет помогать вам весь год (а может и не один). Поэтому мы решили в эти выходные опубликовать серию постов с лекциями курсов первого семестра Школы анализа данных.
Сегодня — о самом важном. Современный анализ данных без него представить невозможно. В рамках курса рассматриваются основные задачи обучения по прецедентам: классификация, кластеризация, регрессия, понижение размерности. Изучаются методы их решения, как классические, так и новые, созданные за последние 10–15 лет. Упор делается на глубокое понимание математических основ, взаимосвязей, достоинств и ограничений рассматриваемых методов. Отдельные теоремы приводятся с доказательствами.
Читает курс лекций Константин Вячеславович Воронцов, старший научный сотрудник Вычислительного центра РАН. Заместитель директора по науке ЗАО «Форексис». Заместитель заведующего кафедрой «Интеллектуальные системы» ФУПМ МФТИ. Доцент кафедры «Математические методы прогнозирования» ВМиК МГУ. Эксперт компании «Яндекс». Доктор физико-математических наук.
Сегодня — о самом важном. Современный анализ данных без него представить невозможно. В рамках курса рассматриваются основные задачи обучения по прецедентам: классификация, кластеризация, регрессия, понижение размерности. Изучаются методы их решения, как классические, так и новые, созданные за последние 10–15 лет. Упор делается на глубокое понимание математических основ, взаимосвязей, достоинств и ограничений рассматриваемых методов. Отдельные теоремы приводятся с доказательствами.
Читает курс лекций Константин Вячеславович Воронцов, старший научный сотрудник Вычислительного центра РАН. Заместитель директора по науке ЗАО «Форексис». Заместитель заведующего кафедрой «Интеллектуальные системы» ФУПМ МФТИ. Доцент кафедры «Математические методы прогнозирования» ВМиК МГУ. Эксперт компании «Яндекс». Доктор физико-математических наук.
Ввод паролей при сборке проектов с помощью gradle
3 min
Translation
При сборке проектов для Android Gradle позволяет указать некоторые параметры, позволяющие собрать и подписать пакет, готовый для загрузки в Google Play. Однако, вряд ли стоит загружать некоторые данные, такие как пароль от приватного ключа в публичный репозиторий. В статье, перевод которой ниже, автор рассматривает способы ввода приватной информации, такой как пароли, во время сборки проекта.
Gradle позволяет получить доступ к консоли с помощью метода System.console(). Консоль предоставляет метод для чтения паролей, поэтому для ввода пароля можно использовать:
Теперь можно использовать пароль в любом месте скрипта сборки, и все готово… ой, тогда это будет слишком короткий пост, поэтому теперь поговорим о проблемах.
Gradle позволяет получить доступ к консоли с помощью метода System.console(). Консоль предоставляет метод для чтения паролей, поэтому для ввода пароля можно использовать:
def password = System.console().readPassword("\nPlease enter key passphrase: ")
Теперь можно использовать пароль в любом месте скрипта сборки, и все готово… ой, тогда это будет слишком короткий пост, поэтому теперь поговорим о проблемах.
Налоговый вычет для программистов (авторов программ)
4 min
IT отрасль в целом и создание продуктов интеллектуальной собственности (компьютерные программы и многое другое) в частности – немалая движущая сила современной экономики и мирового прогресса.
Специфика отрасли заключается в том, что профессионалы не всегда могут и не всегда хотят работать in-house и являются фрилансерами. Оно и закономерно – интеллектуальный труд не обязан предполагать рамки рабочего дня и стены офиса.
Безусловно я понимаю общий градус нелюбви к нашим законам и законодателям и то, что львиная доля специалистов работает «в черную», однако почти любой крупный заказчик будет работать с вами на договорной основе (соблюдая в том числе и налоговое законодательство), да и вам, как физическому лицу или индивидуальному предпринимателю важно знать о тех расходах, которые вы можете вернуть себе обратно в карман, не отдавая их государству в виде налогов.
Специфика отрасли заключается в том, что профессионалы не всегда могут и не всегда хотят работать in-house и являются фрилансерами. Оно и закономерно – интеллектуальный труд не обязан предполагать рамки рабочего дня и стены офиса.
Безусловно я понимаю общий градус нелюбви к нашим законам и законодателям и то, что львиная доля специалистов работает «в черную», однако почти любой крупный заказчик будет работать с вами на договорной основе (соблюдая в том числе и налоговое законодательство), да и вам, как физическому лицу или индивидуальному предпринимателю важно знать о тех расходах, которые вы можете вернуть себе обратно в карман, не отдавая их государству в виде налогов.
Конспект по веб-безопасности
3 min
Tutorial
Простите, но накипело.
Много шишек уже набито на тему безопасности сайтов. Молодые специалисты, окончившие ВУЗы, хоть и умеют программировать, но в вопросе безопасности сайта наступают на одни и те же грабли.
Этот конспект-памятка о том, как добиться относительно высокой безопасности приложений в вебе, а также предостеречь новичков от банальных ошибок. Список составлялся без учета языка программирования, поэтому подходит для всех. А теперь позвольте, я немного побуду КО.

Итак, каким должен быть безопасный сайт?
Много шишек уже набито на тему безопасности сайтов. Молодые специалисты, окончившие ВУЗы, хоть и умеют программировать, но в вопросе безопасности сайта наступают на одни и те же грабли.
Этот конспект-памятка о том, как добиться относительно высокой безопасности приложений в вебе, а также предостеречь новичков от банальных ошибок. Список составлялся без учета языка программирования, поэтому подходит для всех. А теперь позвольте, я немного побуду КО.
Итак, каким должен быть безопасный сайт?
О срезании углов
2 min
Translation
Давным-давно, когда разрабатывалась файловая система Unix, в ней появились «псевдо-файлы»
Правильнее было бы реализовать эту проверку более развёрнуто:
У этого было два далеко идущих последствия.
. и .., чтобы упростить перемещение между каталогами. Кажется, .. был добавлен в Версии 2, когда файловая система стала иерархической (в первой версии она была устроена совсем по-другому). Но эти «псевдо-файлы» засоряли вывод ls, и то ли Кен, то ли Деннис добавил в код ls простую проверку:if (name[0] == '.') continue;На самом деле программы тогда писались на ассемблере, но суть проверки была в точности такой.
Правильнее было бы реализовать эту проверку более развёрнуто:
if (strcmp(name, ".") == 0 || strcmp(name, "..") == 0) continue;— но какая разница, главное что всё работало.
У этого было два далеко идущих последствия.
Пишем файловую систему в ядре Linux
10 min
Tutorial
Для кого эта статья

Данная статья составлена по материалам практики по курсу операционных систем в Академическом университете . Материал готовился для студентов, и ничего сложного здесь не будет, достаточно базового знания командной строки, языка C, Makefile и общих теоретических знаний о файловых системах.
Весь материал разбит на несколько частей, в данной статье будет описана вводная часть. Я коротко расскажу о том, что понадобится для разработки в ядре Linux, затем мы напишем простейший загружаемый модуль ядра, и наконец напишем каркас будущей файловой системы — модуль, который зарегистрирует довольно бесполезную (пока) файловую систему в ядре. Люди уже знакомые (пусть и поверхностно) с разработкой в ядре Linux не найдут здесь ничего интересного.
Изолирование приложения с IP-адресом из VPN другой страны на примере Steam
7 min
Tutorial
Abstract: Изоляция приложения на уровне сети использованием network namespaces Линукса. Организация SSH-туннелей.
Традиционно, большая часть статьи будет посвящена теории, а скучные скрипты — в конце статьи. В качестве субъекта для экспериментов будет использоваться Steam, хотя написанное применимо к любому приложению, включая веб-браузеры.
Вместо вступления. Я просто покажу эту картинку:
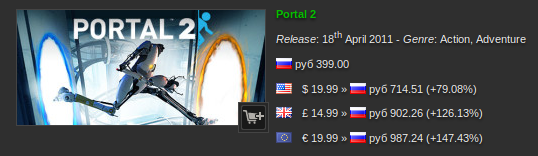
147%… Что-то мне это напоминает. Впрочем, хабр не для политики.
Цена на игры в Стиме зависит от региона. Регион — от IP'шника. Есть желание иметь цены в рублях, а не в евро.
Для этого мы используем VPN через SSH с использованием tun-устройств, плюс network namespaces для изоляции приложения от всех остальных сетевых устройств.
Традиционно, приложение, запускающееся даже с правами пользователя, имеет полный доступ в сеть. Оно может использовать любой сетевой адрес, существующий в системе для отправки пакетов.
Более того, большинство десктопных приложений вообще ничего не понимает в интерфейсах, так как предполагают, что у системы есть только один сетевой интерфейс и не даёт возможности указать, каким из интерфейсов надо пользоваться. Серверное ПО обычно имеет эту опцию (какой адрес использовать в качестве адреса отправителя), но для десктопов это непозволительная роскошь.
Если у нас есть несколько интерфейсов (один из которых относится к VPN), то нет штатных методов сказать стиму, что надо использовать его, а не eth0/wlan0. Точнее, мы можем «завернуть» весь трафик в VPN, но это не всегда желательно. Как минимум — рост latency и снижение скорости (даже если VPN ведёт на супербыстрый сервер, увеличение latency, оверхед от туннеля и фиксированная ширина локального канала ставят TCP в положение, когда приходится резать скорость). Как максимум — одно дело «покупать через русский VPN», другое дело — пускать туда весь трафик. Меня совсем не прельщает использование VPN для получения защиты роскомнадзором от оппозиции и вольнодумства.
В этих условиях возникает большое желание оставить один на один конкретное приложение и заданный сетевой интерфейс. Один. Сконфигурированный для нужд только этого приложения.
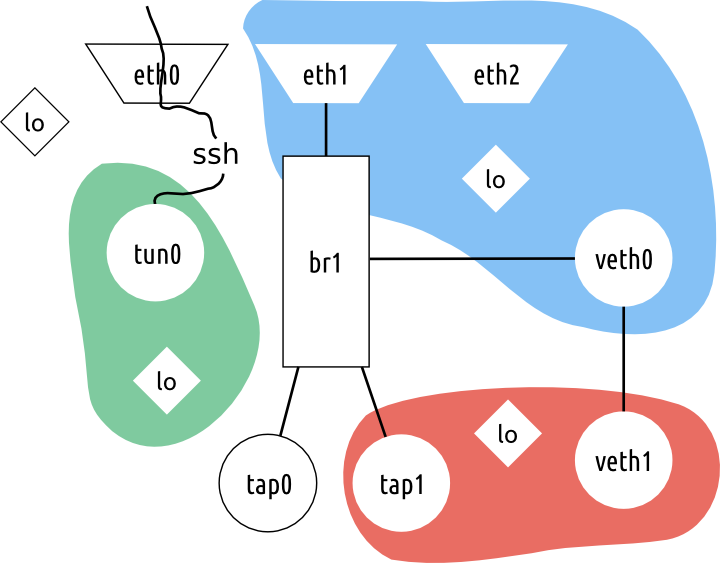
Для решения этой задачи в Linux, уже довольно давно (аж с 2007 года) существует технология, называемая network namespaces, то есть пространства имён для сетей. Суть технологии: над сетевыми интерфейсами создаётся подобие «каталогов», в каждом каталоге может быть несколько сетевых интерфейсов и приложений. Приложение, оказавшееся в заданном сетевом пространстве имён, может использовать (и видит) только те сетевые интерфейсы, которые отнесены к этому пространству.
Картинка ниже поясняет происходящее:
Традиционно, большая часть статьи будет посвящена теории, а скучные скрипты — в конце статьи. В качестве субъекта для экспериментов будет использоваться Steam, хотя написанное применимо к любому приложению, включая веб-браузеры.
Вместо вступления. Я просто покажу эту картинку:
147%… Что-то мне это напоминает. Впрочем, хабр не для политики.
Цена на игры в Стиме зависит от региона. Регион — от IP'шника. Есть желание иметь цены в рублях, а не в евро.
Для этого мы используем VPN через SSH с использованием tun-устройств, плюс network namespaces для изоляции приложения от всех остальных сетевых устройств.
Network namespaces
Традиционно, приложение, запускающееся даже с правами пользователя, имеет полный доступ в сеть. Оно может использовать любой сетевой адрес, существующий в системе для отправки пакетов.
Более того, большинство десктопных приложений вообще ничего не понимает в интерфейсах, так как предполагают, что у системы есть только один сетевой интерфейс и не даёт возможности указать, каким из интерфейсов надо пользоваться. Серверное ПО обычно имеет эту опцию (какой адрес использовать в качестве адреса отправителя), но для десктопов это непозволительная роскошь.
Если у нас есть несколько интерфейсов (один из которых относится к VPN), то нет штатных методов сказать стиму, что надо использовать его, а не eth0/wlan0. Точнее, мы можем «завернуть» весь трафик в VPN, но это не всегда желательно. Как минимум — рост latency и снижение скорости (даже если VPN ведёт на супербыстрый сервер, увеличение latency, оверхед от туннеля и фиксированная ширина локального канала ставят TCP в положение, когда приходится резать скорость). Как максимум — одно дело «покупать через русский VPN», другое дело — пускать туда весь трафик. Меня совсем не прельщает использование VPN для получения защиты роскомнадзором от оппозиции и вольнодумства.
В этих условиях возникает большое желание оставить один на один конкретное приложение и заданный сетевой интерфейс. Один. Сконфигурированный для нужд только этого приложения.
Для решения этой задачи в Linux, уже довольно давно (аж с 2007 года) существует технология, называемая network namespaces, то есть пространства имён для сетей. Суть технологии: над сетевыми интерфейсами создаётся подобие «каталогов», в каждом каталоге может быть несколько сетевых интерфейсов и приложений. Приложение, оказавшееся в заданном сетевом пространстве имён, может использовать (и видит) только те сетевые интерфейсы, которые отнесены к этому пространству.
Картинка ниже поясняет происходящее:
Практические рекомендации: устраняйте неполадки, используя команду 'Top' в Linux
8 min
Translation
Сейчас мы работаем над новой фичей нашего сервиса мониторинга, для того чтобы можно было мониторить не только внешние параметры сервера, но и внутренние, такие как загрузку системы, состояние жестких дисков, оперативной памяти и других. В процессе разработки мы натолкнулись на полезную статью, которая рассказывает о параметрах системы которые можно получить с помощью системной команды top, перевод этой статьи мы представляем вашему вниманию.
Load average может представлять собой непростой для понимания показатель производительности сервера. В этой статье мы попытаемся дать некоторое представление о том, что означают те величины, которые можно найти в выводе команды «top» и в других linux-командах. В статье, также объясняются параметры специфичные для виртуального хостинга, которые обычно не отображается в стандартном выводе команды top.
Load average может представлять собой непростой для понимания показатель производительности сервера. В этой статье мы попытаемся дать некоторое представление о том, что означают те величины, которые можно найти в выводе команды «top» и в других linux-командах. В статье, также объясняются параметры специфичные для виртуального хостинга, которые обычно не отображается в стандартном выводе команды top.