Список переведённых частей серии:
- Приготовления (вы тут)
- Компиляция с Emscripten
- Конвертация avi в mp4
Из этой части вы узнаете:
- Зачем это всё нужно
- Как скомпилировать FFmpeg в Docker
Зачем это всё нужно
Главные задачи у серии публикаций такие:
- Создать туториал по использованию Emscripten для компиляции C/C++ библиотек в JavaScript (более детальный и полезный, чем написанные ранее)
- Персональная памятка
Почему FFmpeg?
FFmpeg — это свободный проект с открытым исходным кодом, состоящий из обширного набора библиотек и программ для обработки видео, аудио и других мультимедийных файлов/трансляций. (из Википедии)
Библиотеки JavaScript, которая предоставляла бы подобные возможности, попросту не существует. Если вы погуглите «ffmpeg.js», то найдёте несколько решений, подобных тому что мы собираемся сделать:
Эти библиотеки, конечно, можно использовать, но у них есть свои недостатки:
- Используемые версии как FFmpeg, так и Emscripten устарели
- Проекты не поддерживаются уже долгое время
Изначально я планировал заняться поддержкой какой-нибудь из двух библиотек, но так как за годы накопилось слишком много изменений, решил сделать всё с чистого листа, попутно создав туториал по использованию Emscripten для компиляции большой C/C++ библиотеки.










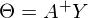 , где
, где 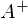 — псевдообратная матрица. Это решение наглядное, точное и короткое. Но есть проблема, которую можно решить численно. Градиентный спуск — метод численной оптимизации, который может быть использован во многих алгоритмах, где требуется найти экстремум функции — нейронные сети, SVM, k-средних, регрессии. Однако проще его воспринять в чистом виде (и проще модифицировать).
— псевдообратная матрица. Это решение наглядное, точное и короткое. Но есть проблема, которую можно решить численно. Градиентный спуск — метод численной оптимизации, который может быть использован во многих алгоритмах, где требуется найти экстремум функции — нейронные сети, SVM, k-средних, регрессии. Однако проще его воспринять в чистом виде (и проще модифицировать).
