Букварь по дизайну систем (Часть 1 с дополнениями по микросервисам)
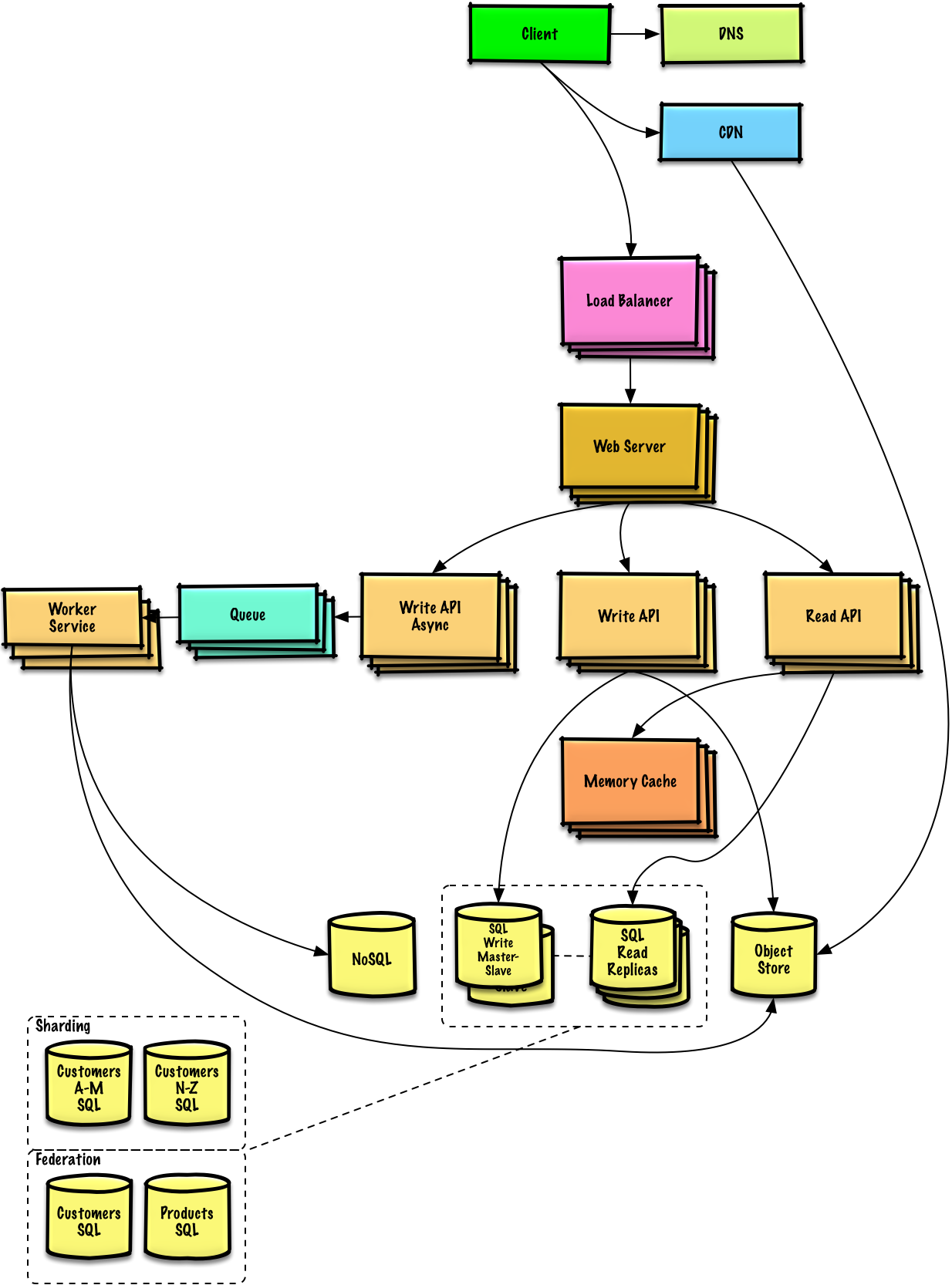
Несколько лет назад, для закрытия одного их предметов мне довелось перевести данный букварь. Де-факто этот вариант стал официальным переводом. Но развитию этого перевода мешает, тот факт, что он был написан в Google Drive и закрыт на редактирования. Сегодня я уделил время на переформатирования всего этого текста в MD формат с помощью редактора Хабра, с радостью публикую здесь и вскоре отдам текущим контрибьюторам.
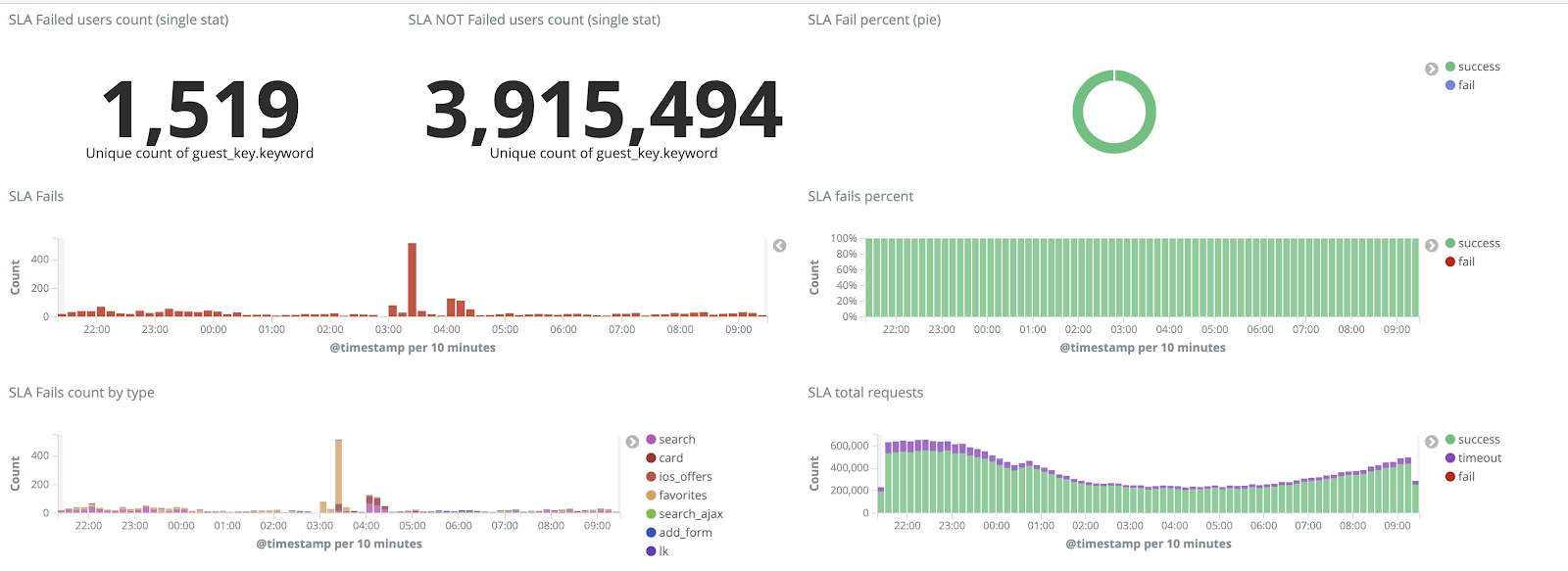
Словарь
Node — нода — узел с каким либо ресурсом
Content — контент — данныe
Traffic — трафик — запрос/ответ, данные которые передаются от сервера клиенту и наоборот
Hardware — железо — аппаратная часть
Instance — инстанс — созданный объект какой либо сущности. Например инстанс сервера API
Headers — хедеры — заголовки (как правило TCP пакета, но может быть и HTTP запроса)




 Docker одна из горячих тем в разработке. Большинство новых проектов строится именно на Docker. Как минимум, он отлично зарекомендовал себя для распространения ПО, например, наша система поиска по документам
Docker одна из горячих тем в разработке. Большинство новых проектов строится именно на Docker. Как минимум, он отлично зарекомендовал себя для распространения ПО, например, наша система поиска по документам