
В этой статье я хотел бы поделиться своим опытом создания SaaS-сервиса на базе LAMP стека, Postio и доведения сервиса до состояния, когда он стал приносить 3 700 долларов ежемесячно (до обрушения рубля было почти 7 000). Сразу надо сказать, что эта история не имеет ничего общего с инвесторами, с золотой лихорадкой Кремниевой долины и с какой-то сверхсовременной технологией. Просто незамысловатая история от независимого разработчика о создании прибыльного SaaS-сервиса, который может сделать любой. Этот веб-сервис был сделан для внутреннего рынка России, поэтому я перевёл всё на английский и в доллары для удобства (пожалуйста, обратите внимание, что это перевод моей статьи, которая изначально была написана для англоязычной аудитории). Но, с другой стороны, этот опыт является довольно универсальным и может быть применён везде. По сути, это инструкция по созданию проектов такого рода.
Три года назад я решил заняться SMM, и самым простым способом сделать это показалось запустить свою собственную группу в какой-нибудь нише и попытаться развить её. Facebook был уже, мягко говоря, довольно конкурентным на тот момент, поэтому я запустил свою тестовую группу на базе «ВКонтакте». Я выбрал очень популярную нишу, потому что всё, что я хотел, — это научиться, а не доминировать на рынке.
Наверное, я должен немного отвлечься и сказать, что VK.com имел и до сих пор имеет процветающую «экосистему» таких групп, которая приносит прибыль их владельцам. Это — своеобразный рынок, который Facebook прикрыл уже давно. И этот базар является прекрасной средой для обучения и экспериментов.
Три года назад я решил заняться SMM, и самым простым способом сделать это показалось запустить свою собственную группу в какой-нибудь нише и попытаться развить её. Facebook был уже, мягко говоря, довольно конкурентным на тот момент, поэтому я запустил свою тестовую группу на базе «ВКонтакте». Я выбрал очень популярную нишу, потому что всё, что я хотел, — это научиться, а не доминировать на рынке.
Наверное, я должен немного отвлечься и сказать, что VK.com имел и до сих пор имеет процветающую «экосистему» таких групп, которая приносит прибыль их владельцам. Это — своеобразный рынок, который Facebook прикрыл уже давно. И этот базар является прекрасной средой для обучения и экспериментов.

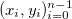 и соответствующий им набор положительных весов
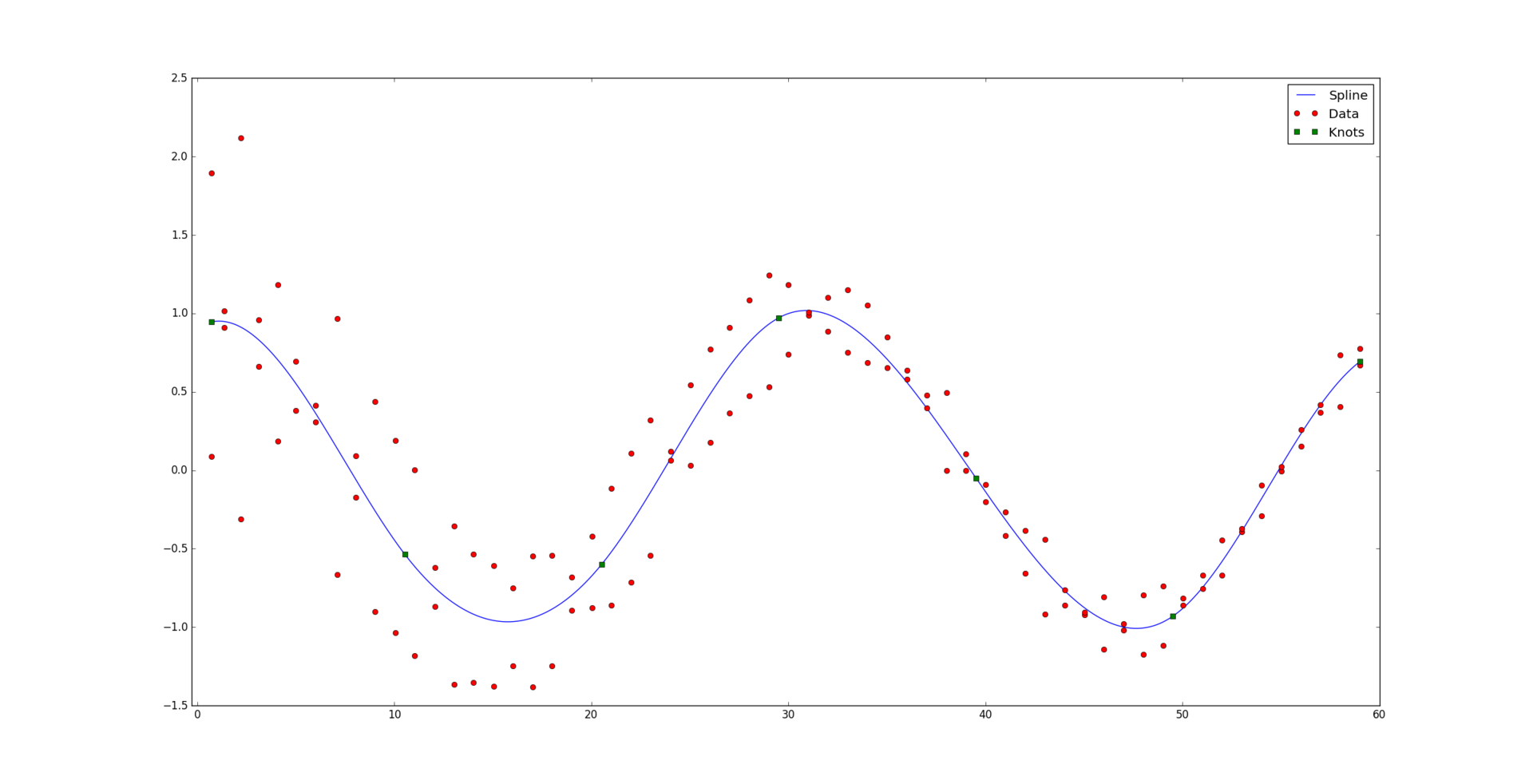
и соответствующий им набор положительных весов 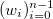 . Мы считаем, что некоторые точки могут быть важнее других (если нет, то все веса одинаковые). Неформально говоря, мы хотим, чтобы на соответствующем интервале была проведена красивая кривая таким образом, чтобы она «лучше всего» проходила через эти данные.
. Мы считаем, что некоторые точки могут быть важнее других (если нет, то все веса одинаковые). Неформально говоря, мы хотим, чтобы на соответствующем интервале была проведена красивая кривая таким образом, чтобы она «лучше всего» проходила через эти данные. 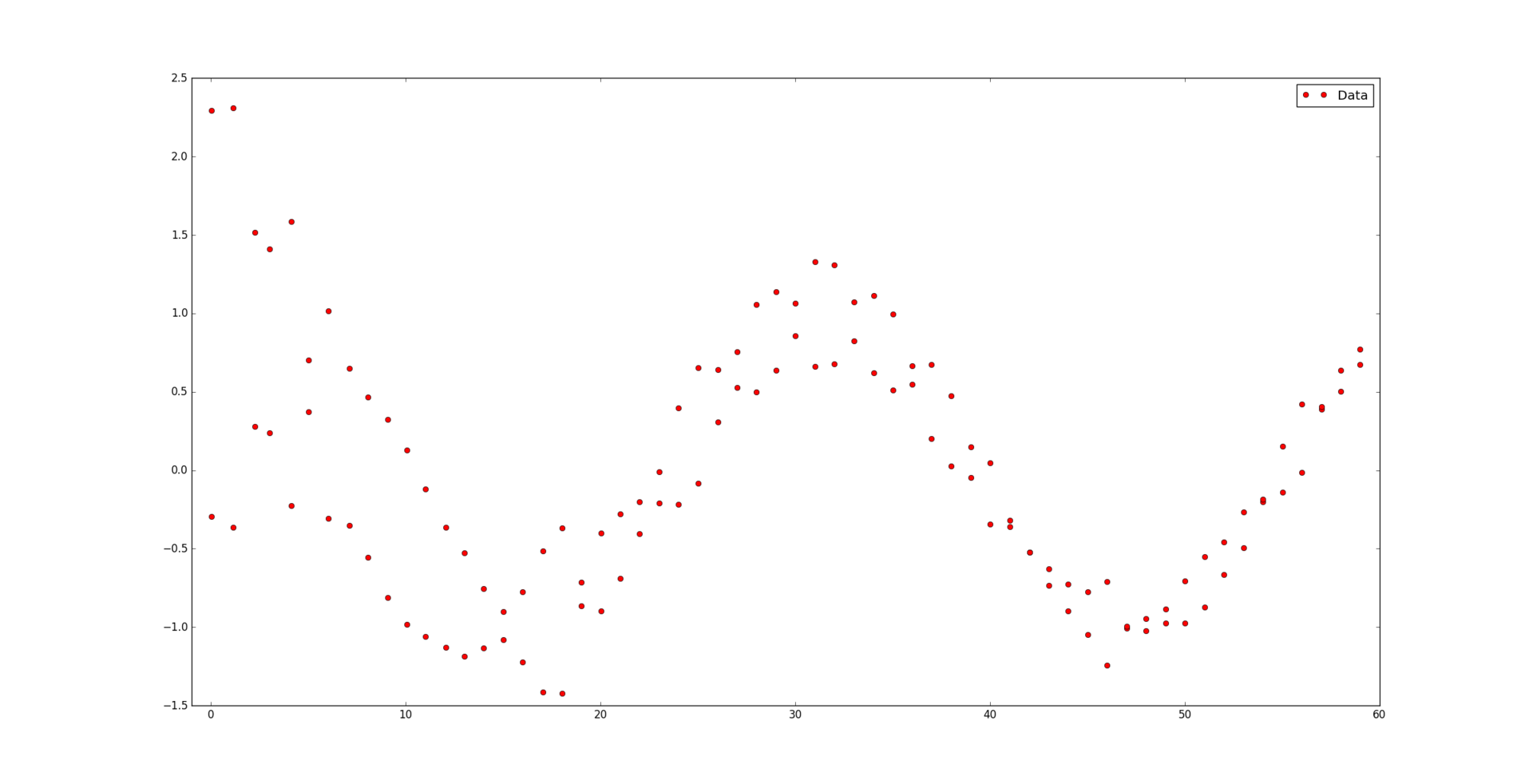




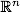 . Координаты вектора описывают отдельные аттрибуты объекта. Например, цвет c, заданный в модели RGB, является вектором в трехмерном пространстве: c=(red, green, blue).
. Координаты вектора описывают отдельные аттрибуты объекта. Например, цвет c, заданный в модели RGB, является вектором в трехмерном пространстве: c=(red, green, blue).  Доброго времени суток, читатель.
Доброго времени суток, читатель.