
Вышла 127 версия браузера Google Chrome.
Вы уже предвкушавшие, что статья будет посвящена обзору нововведений в популярном браузере? Вообще-то да, только в очередной раз делать это будем через отладчик x64dbg (или любой другой по вкусу, кроме gdb).

User
Вышла 127 версия браузера Google Chrome.
Вы уже предвкушавшие, что статья будет посвящена обзору нововведений в популярном браузере? Вообще-то да, только в очередной раз делать это будем через отладчик x64dbg (или любой другой по вкусу, кроме gdb).

Данная сфера очень быстро развивается и, вероятно, данная статья устареет очень быстро, потому следует обозначить то что пишется она в конце мая 2024 года.

Результаты российского кинотеатрального проката предсказуемы. До начала съемок самого фильма. С помощью ансамблевых моделей машинного обучения и исторических данных по прокату и характеристикам творческой группы.

WaveSync — новый алгоритм для детального, нелинейного и быстрого анализа сходства эмбеддингов и векторов.
Алгоритм является в большинстве задач заменой линейному косиносному сходству. Он позволяет улучшить точность обработки языка и открывает новые перспективы для разработчиков и исследователей в области NLP.
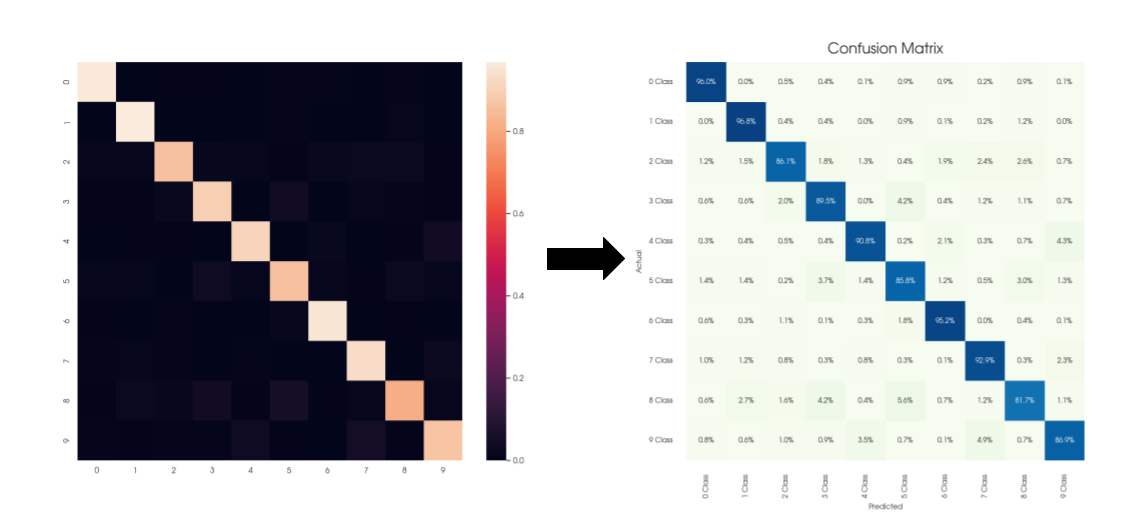
Привет, Хабр!
Часто в работе аналитика данных при подготовке очередного отчета или презентации, колоссальное количество времени уходит именно на графическую составляющую подготовки.
Ведь все хотят сделать отчет не только информативным, но и визуально привлекательным.
В этой статье мы разберем основные шаги, которые помогут сделать ваши матрицы стильными и продающими ваши результаты, используя лишь две основные библиотеки визуализации в Python - Seaborn и Matplotlib.

Второе занятие посвящено визуализации данных в Python. Сначала мы посмотрим на основные методы библиотек Seaborn и Plotly, затем поанализируем знакомый нам по первой статье набор данных по оттоку клиентов телеком-оператора и подглядим в n-мерное пространство с помощью алгоритма t-SNE. Есть и видеозапись лекции по мотивам этой статьи в рамках второго запуска открытого курса (сентябрь-ноябрь 2017).
UPD 01.2022: С февраля 2022 г. ML-курс ODS на русском возрождается под руководством Петра Ермакова couatl. Для русскоязычной аудитории это предпочтительный вариант (c этими статьями на Хабре – в подкрепление), англоговорящим рекомендуется mlcourse.ai в режиме самостоятельного прохождения.
Сейчас статья уже будет существенно длиннее. Готовы? Поехали!

Да, всего 20 строк кода и бот:
1) по качеству ответов будет соизмерим с ChatGPT-4o;
2) будет отвечать очень быстро т.к. подключим мы его через Groq который в среднем в 10 раз быстрее других аналогичных сервисов;
3) будет поддерживать диалог и запоминать последние сообщения.
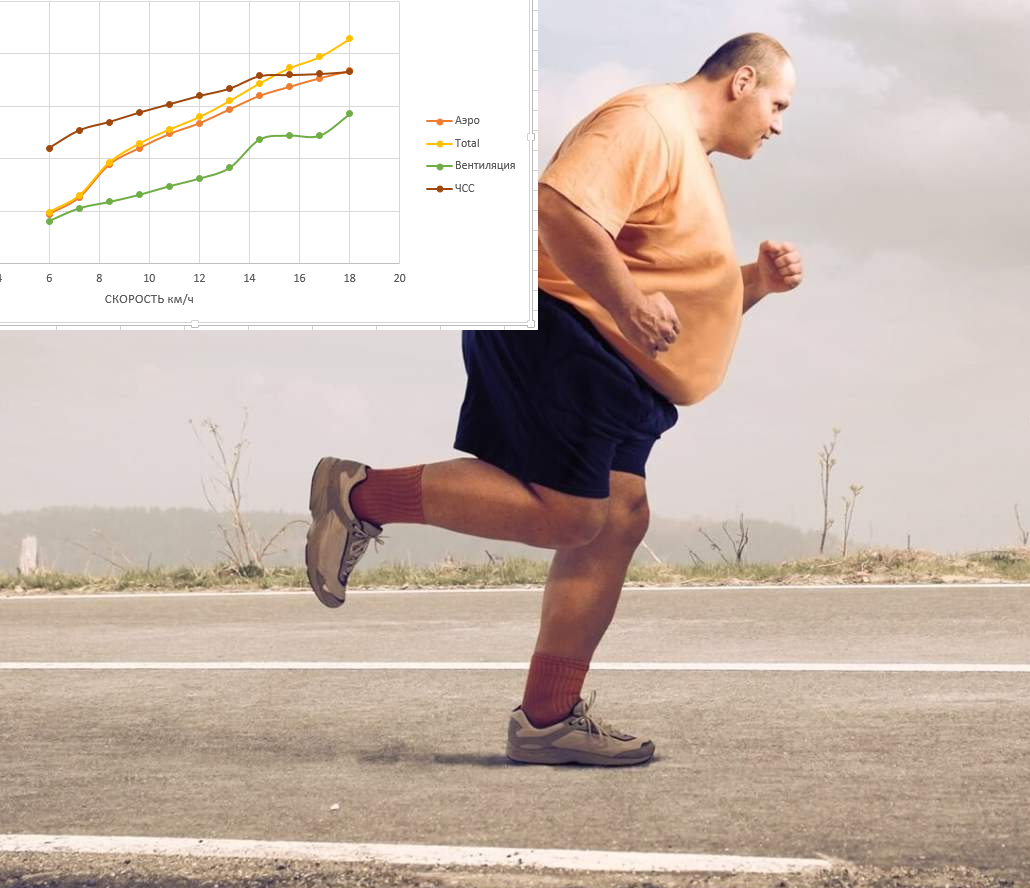
Нередко попадаются видео и статьи с примерным смыслом, что начал бегать в 45+ лет, через месяц уже бегал по 10 км, через год уже марафон и похудел со 120 до 70 кг. Но это не мой случай. Начинал с 300 метров (>>моя статья как это было), прогресс шел очень тяжело, тренировки давались очень трудно, прогресс за 2023 год за 10 месяцев дошел до очень медленного бега 1 раз 10 км (в основном 4..5 км), а к концу года и вовсе начался регресс и спад. Вес тела снизился с 88 кг до 82 кг, а потом возрос до 85 кг и стабилизировался. То есть самая лучшая и популярная методика тренировок в виде очень медленного бега трусцой в перемешку с ходьбой на ЧСС 120 в моём случае дала очень слабенькие результаты, намного хуже того, что пишут обычно другие начинающие. В 2024 году перестал бегать. 3 месяца был только тренажерный зал, ОФП, СБУ, сауна, плавание 2..3 раза в неделю. И вот в марте 2024 снова вышел на пробежки. Читайте, что из этого получилось... (в том числе анализ ЧСС и пульсовой стоимости, числа сокращений сердца на 1 км бега).

Никто доподлинно не знает, что происходит на рынке IT-образования.
Бизнес по торговле людьми явно более честный, прозрачный и социально ориентированный, чем то, что происходит в EdTech. Во всяком случае, чем дольше провожу исследование IT-курсов, тем сильнее у меня именно такие ощущения.
И чем больше подобных ощущений, тем сложнее оставаться эмоционально выключенным и непредвзятым.
Здравствуйте, продолжение статьи про методы создания эмбедингов предложений. В этом гайде мало слов и много кода, готово для Ctrl+с, Ctrl+v, улучшений и дальнейших тестов.
Часть1 обязательна для ознакомления
from deeppavlov.core.common.file import read_json
from deeppavlov import build_model, configs
from deeppavlov.models.embedders.elmo_embedder import ELMoEmbedder
# ссылка для скачивания моделей http://docs.deeppavlov.ai/en/master/features/pretrained_vectors.htmlclass RU_BERT_CLASS:
def __init__(self, name):
bert_config = read_json(configs.embedder.bert_embedder)
bert_config['metadata']['variables']['BERT_PATH'] = os.path.join('./.', name)
self.m = build_model(bert_config)
def vectorizer(self, sentences):
return [sentence.split() for sentence in sentences]
def predict(self, tokens):
_, _, _, _, sent_max_embs, sent_mean_embs, _ = self.m(tokens)
return sent_mean_embs
bert = RU_BERT_CLASS('rubert_cased_L-12_H-768_A-12_pt')
get_similarity_values = similarity_values_wrapper(bert.predict, bert.vectorizer, distance_function=cosine_distances)
evaluate(get_similarity_values, 'rubert')'rubert: 2895.7'
Представте себе, как было бы удобно, написать предложение и найти похожее к нему по смыслу. Для этого нужно уметь векторизовать всё предложение, что может быть очень не тривиальной задачей.
По специфике своей работы, я должен искать похожие запросы в службу поддержки и даже имея достаточно большую разметку, бывает тяжело собрать необходимое количество сообщений подходящих по тематике, но написанных другими словами.
Ниже обзорное исследование на способы векторизации всего предложения и не просто векторизации, а попытка векторизовать предложение с учётом его смысла.
Например две фразы 'эпл лучше самсунг' от 'самсунг лучше эпл', должны быть на противоположном конце по одному из значений вектора, но при этом совпадать по другим.
Можно привести аналогию с картинкой ниже. По шкале от кекса до собаки они находятся на разных концах, а по количеству чёрных точек и цвету объекта на одном.


Привет, Хабр!
Продолжая развитие темы рекомендательных систем с моей последней статьи, я бы хотел рассказать о подходе, до которого мы с моей командой самостоятельно дошли и воплотили в жизнь на существующем проекте. Речь идёт о настраиваемом автоэнкодере, но совсем не важно, как я его обозвал, важно то, как он работает - прейдём к сути!

Про SVD разложение и PCA. Решение задачи восстановления user-item matrix с помощью stochastic gradient descent.

Кто-то гадает по звёздам и кофе, кто-то — по фото, а нам в ВТБ пришлось обучить модель предсказания по телефонным звонкам. А заодно пройтись по граблям обработки текстов и звука, выяснить, какие фичи можно извлечь из аудио, как привлечь ML и прикрутить к нему нейросеть, — и сделать всё на основе opensource.
Меня зовут Алексей Климачев, и я data scientist ВТБ. В прошлом году банк доверил мне провести исследование аудиоданных для целей collection. Если вам интересно, чем может быть полезна правильно обученная модель, анализирующая звонки и прогнозирующая их исход, что использовать для её обучения, с какими сложностями можно столкнуться в процессе и как их обойти, заглядывайте в статью.
В этой статья я хочу поделиться опытом использования open source систем Zabbix и Grafana для визуализации работы производственных линий. Информация может быть полезна тем, кто ищет быстрый способ визуального отображения или аналитики собранных данных в проектах промышленной автоматизации или IoT. Статья не является подробным руководством, это скорее концепция системы мониторинга, основанная на открытом программном обеспечении для производственного предприятия.

Позавчера, 15 января ночью, по всему Рунету пошли сигналы, что протоколы WireGuard/OpenVPN массово «отвалились». Судя по всему, с понедельника Роскомнадзор снова взялся за VPN, экспериментируя с блокировками OpenVPN и Wireguard в новом масштабе.
Мы в Xeovo заметили это по большому наплыву пользователей, которые вообще не знали что протоколы блокируются (где они были все это время). Уже учения были много раз, и мы предупреждали клиентов, но, видимо, OpenVPN и WireGuard до сих пор очень хорошо работали у всех. На настоящий момент блокировка продолжается. Возможно, тестируют, как все работает перед выборами.
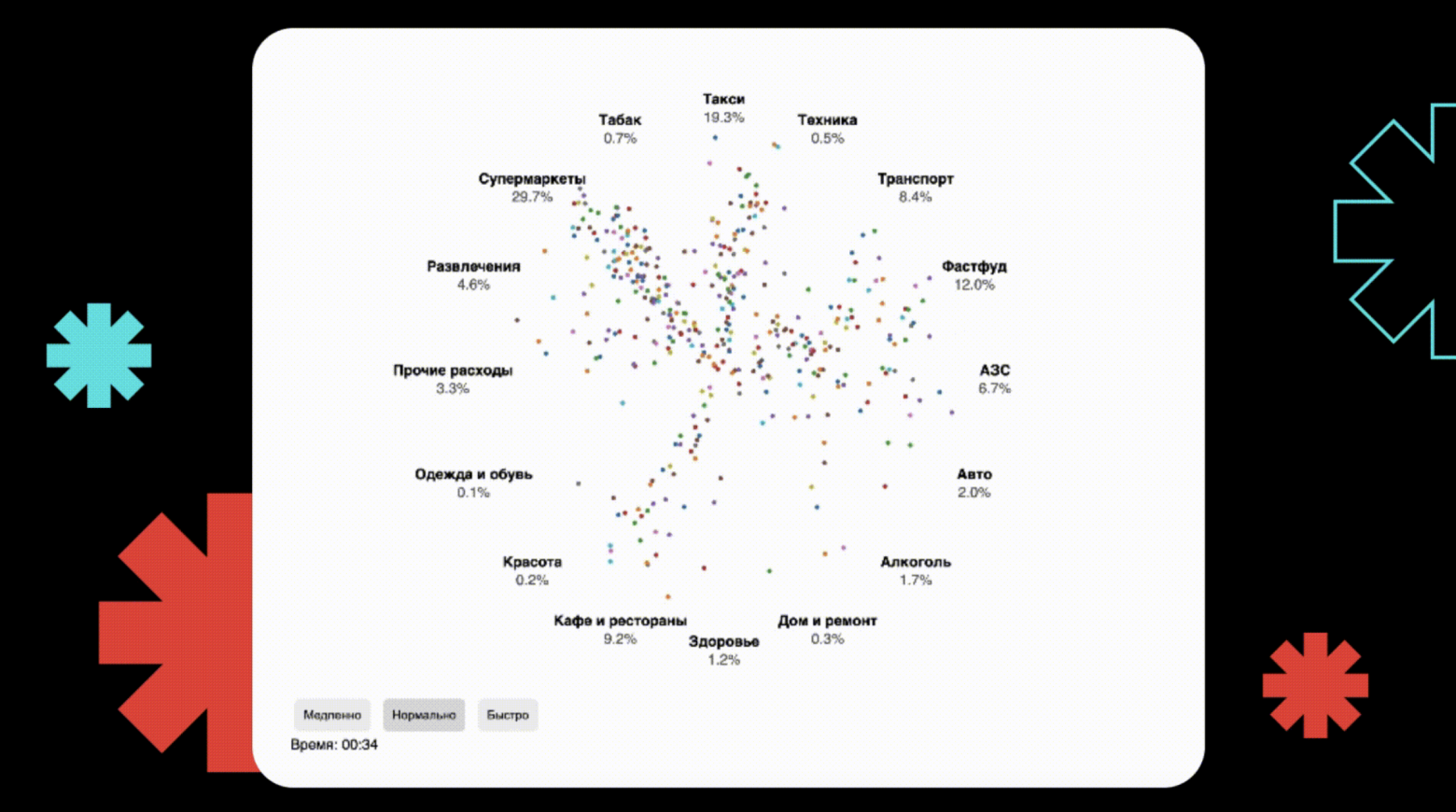
Привет, Хабр! Меня зовут Тагир, я занимаюсь аналитикой игровых механик. Недавно я наткнулся на статью, в которой визуализировали жизни тысяч людей с точностью до минуты — люди отмечали, на что они тратят свое время в течение дня, а автор агрегрировал эти данные и сделал визуализацию, разбив активности по категориям.
Я переложил эту логику на банковские транзакции, чтобы посмотреть, на что люди тратят свои деньги в определенный момент времени, и получил статистику, о которой все и так вроде бы знают. На обед люди ходят в ближайшее кафе и заправляют машину, после работы — в супермаркет, а на выходных — отдыхают в увеселительных заведениях. Но визуализировав эти данные, увидел, что выглядит это весьма залипательно.

Детское программирование стремительно набирает популярность. Многие школьники, интересующиеся видеоиграми, нередко задумываются о создании собственного виртуального мира. К счастью, сейчас для этого есть множество технических возможностей: в большинстве современных семей есть компьютеры, а дети идут в первый класс уже со смартфонами.

Лекция, в которой есть ключевые моменты современной спортивной физиологии. Все бесплатно в открытом доступе, ничего не продается, рекламы нет.

Идея написать блог о том, как злоумышленники используют для перемещения в инфраструктуре жертвы возможности службы Windows Remote Management (WinRM) (Т1021.006), возникла у Антона Величко, руководителя Лаборатории компьютерной криминалистики компании F.A.C.C.T., еще в январе 2022 года. И виной тому стали не затянувшиеся новогодние праздники и наличие свободного времени, как может показаться, а как раз наоборот. В тот момент криминалисты F.A.C.C.T. столкнулись с очередным «праздничным» всплеском кибератак на российские компании, и в процессе реагирования на инцидент у одного из наших клиентов обнаружили интересный кейс, о котором Антон Величко и его соавтор — Кирилл Полищук захотели подробно рассказать.