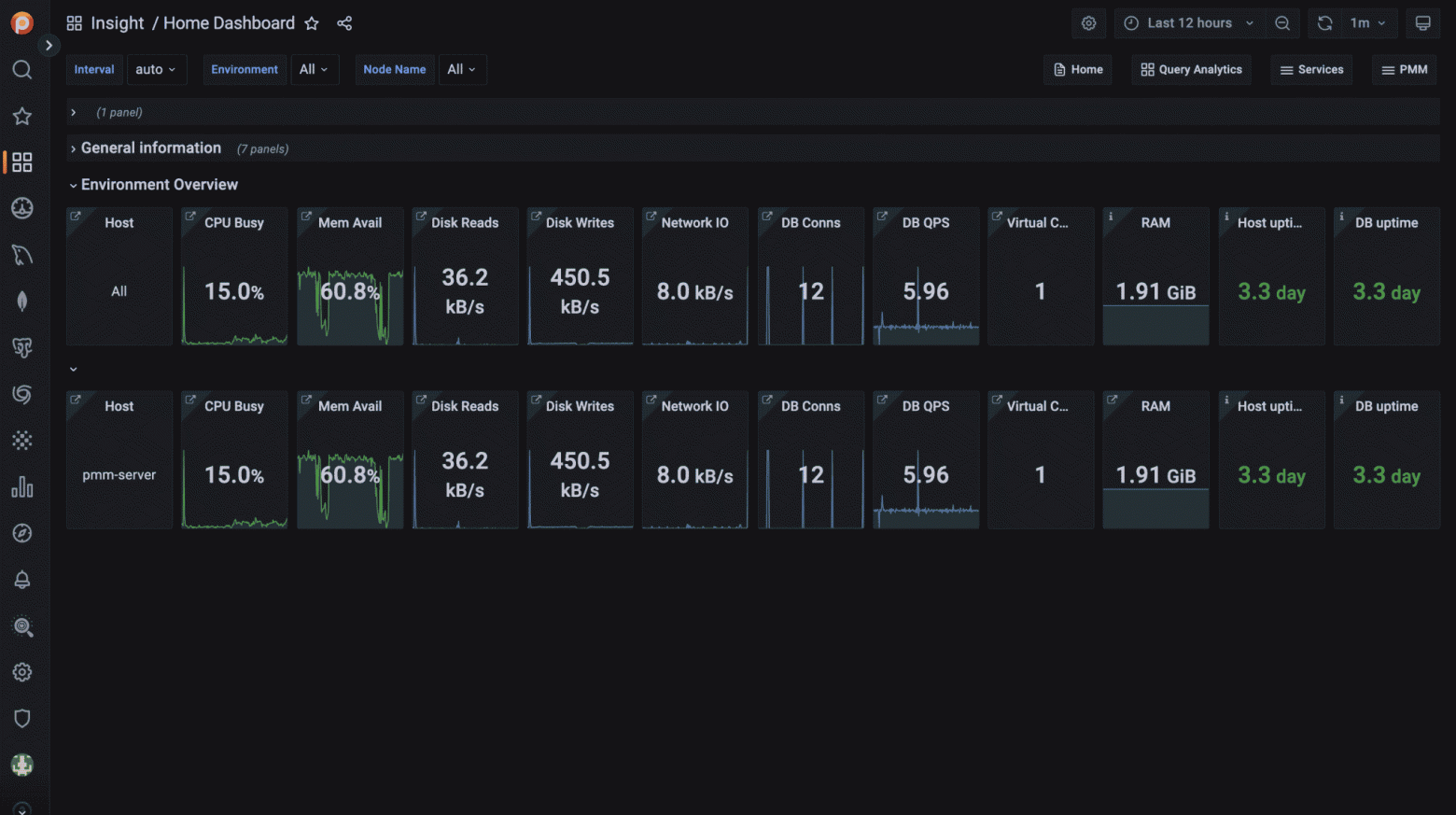
Всех приветствую! Я планирую создать цикл статей, демонстрирующий распространенные ошибки, влияющие на производительность приложения со стороны бэкенда, а также методы их поиска и устранения. Для этого, я написал приложение, в котором специально допустил различные ошибки, чтобы по порядку найти и исправить их.
В текущей статье, рассмотрим темы - n+1, пагинация и индексы. Приятного чтения!
Описание приложения
Рассматриваемый проект - это веб-журнал посещений различных мест людьми с возможностью выгрузки и загрузки журнала в формате XML. Пользователь может загрузить журнал посещений в формате XML через форму на странице /upload, и на основе информации из файла будет заполнена база данных. Вся информация о посещениях будет отображаться на главной странице /index. Экспорт из системы осуществляется через команду, которая преобразует информацию из системы в формат XML и выгружает ее в файл (data.xml).