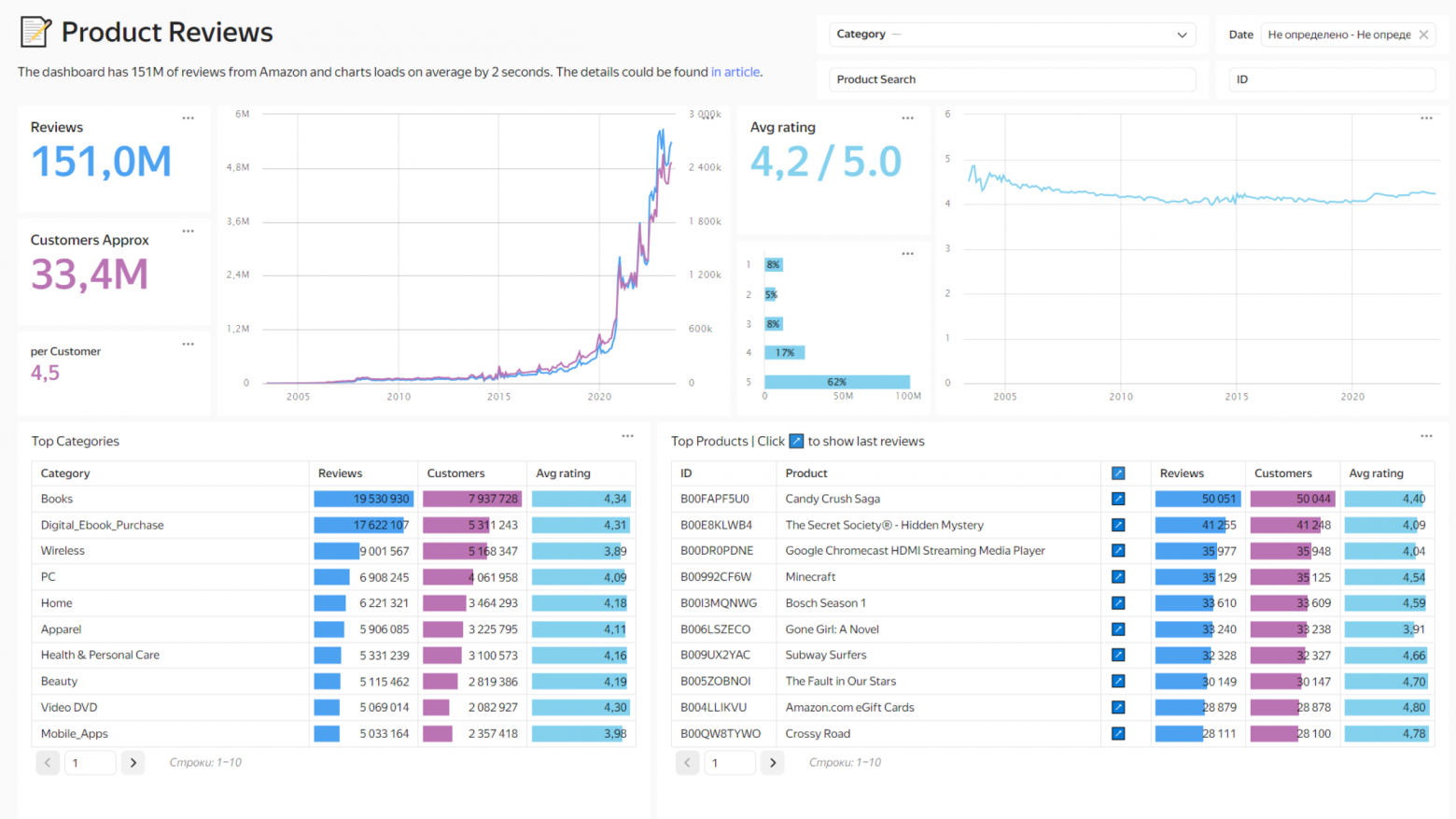
Привет! Меня зовут Роман Бунин, я BI-евангелист Yandex DataLens. При росте объёма данных, что неизбежно для любой компании, загрузка дашбордов может замедляться до десятков секунд. И чем больше появляется данных, тем медленнее становятся дашборды, особенно если вы хотите строить их по детализированным таблицам.Связка базы данных ClickHouse и BI-системы Yandex DataLens — популярное решение для анализа данных: эти инструменты нативно интегрируются и быстро работают вместе. В этой статье вместе с моим коллегой, архитектором Yandex Cloud Игорем Путятиным, покажем, как на основе таблицы из 150 миллионов строк построить максимально быстрый дашборд, и расскажем о технических ограничениях.