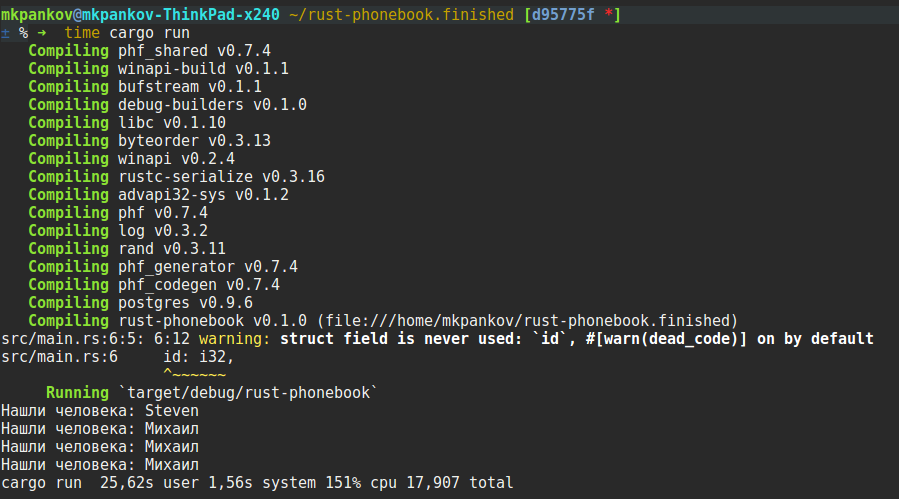
Вы тоже находите смайлы презабавнейшим феноменом?
В доисторические времена, когда я еще был школьником и только начинал постигать прелести интернета, с первых же добавленных в ICQ контактов смайлы ежедневно меня веселили: ну действительно, представьте, что ваш собеседник корчит рожу, которую шлет вам смайлом!
С тех пор утекло много воды, а я так и не повзрослел: все продолжаю иногда улыбаться присланным мне смайлам, представляя отправителя с глазами разного размера или дурацкой улыбкой на все лицо. Но не все так плохо, ведь с другой стороны я стал разработчиком и специалистом в анализе данных и машинном обучении! И вот, в прошлом году, мое внимание привлекла относительно новая, но интересная и будоражащая воображение технология глубокого обучения. Сотни умнейших ученых и крутейших инженеров планеты годами работали над его проблемами, и вот, наконец, обучать глубокие нейронные сети стало не сложнее "классических" методов, вроде обычных регрессий и деревянных ансамблей. И тут я вспомнил про смайлы!
Представьте, что чтобы отправить смайл, вы и вправду могли бы скорчить рожу, как бы было круто? Это отличное упражнение по глубокому обучению, решил я, и взялся за работу.
Глубокое обучение в гараже — Братство данных
Глубокое обучение в гараже — Две сети
Глубокое обучение в гараже — Возвращение смайлов



 Многие системные администраторы, задумываясь о безопасности данных своей компании и, в частности, о безопасности базы данных 1С, пренебрегают простым, но эффективным решением – изолировать сервер от пользователей. В данной статье проанализированы угрозы безопасности, возникающие при размещении клиентской части 1С и серверов 1С в одном сегменте сети, и рассмотрен процесс перевода серверной части 1С в другой сегмент сети. Данная статья не содержит принципиально новых решений, но может служить справочным пособием, которое объединяет информацию из различных источников.
Многие системные администраторы, задумываясь о безопасности данных своей компании и, в частности, о безопасности базы данных 1С, пренебрегают простым, но эффективным решением – изолировать сервер от пользователей. В данной статье проанализированы угрозы безопасности, возникающие при размещении клиентской части 1С и серверов 1С в одном сегменте сети, и рассмотрен процесс перевода серверной части 1С в другой сегмент сети. Данная статья не содержит принципиально новых решений, но может служить справочным пособием, которое объединяет информацию из различных источников.


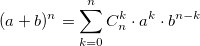 также использует биномиальные коэффициенты. Для их расчета можно использовать формулу, выражающую биномиальный коэффициент через факториалы:
также использует биномиальные коэффициенты. Для их расчета можно использовать формулу, выражающую биномиальный коэффициент через факториалы: 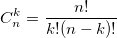 или использовать рекуррентную формулу:
или использовать рекуррентную формулу: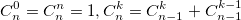 Из бинома Ньютона и рекуррентной формулы ясно, что биномиальные коэффициенты — целые числа. На данном примере хотелось показать, что даже при решении несложной задачи можно наступить на грабли.
Из бинома Ньютона и рекуррентной формулы ясно, что биномиальные коэффициенты — целые числа. На данном примере хотелось показать, что даже при решении несложной задачи можно наступить на грабли.