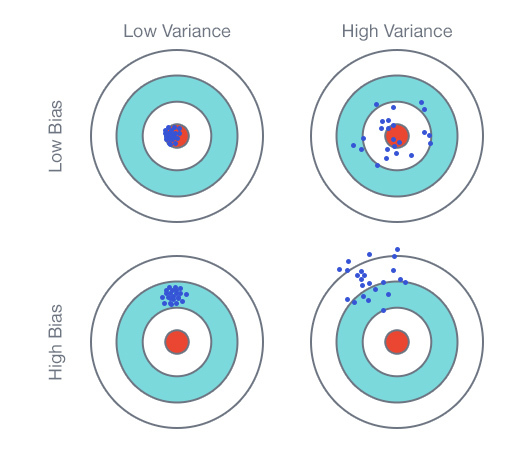
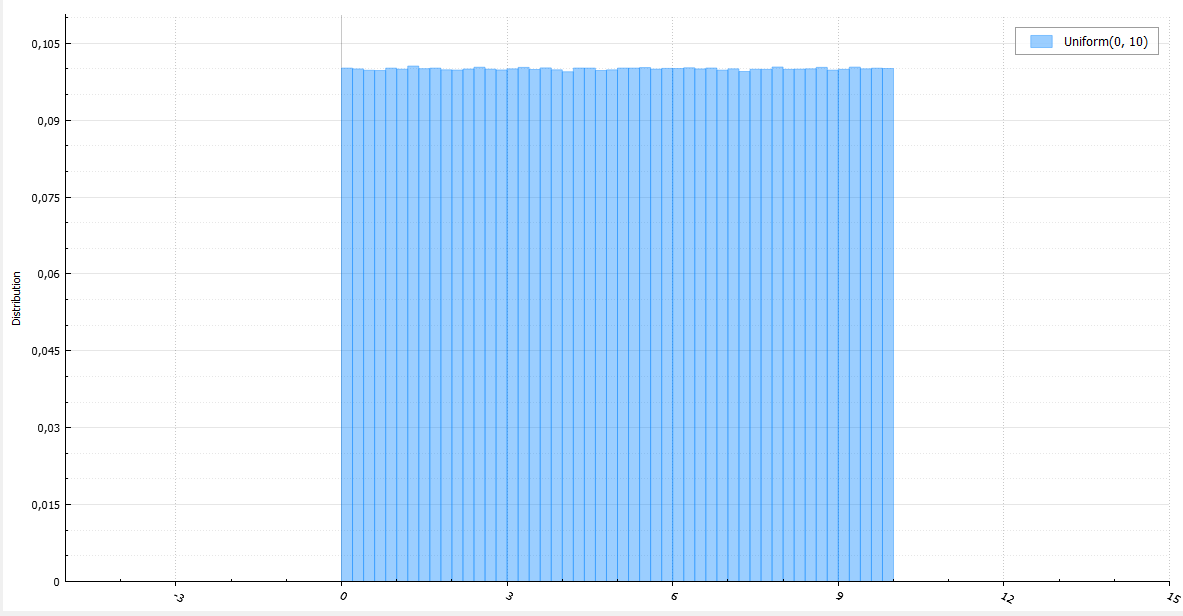
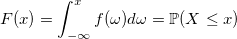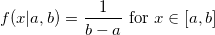Мы уже упоминали, что в этом году тематика конференции
PG Day’17 Russia значительно расширилась. Совместно с компанией
Percona мы сформировали отдельный поток выступлений по
MySQL/NoSQL. Помимо докладов от ведущих специалистов по открытым базам данных и no sql решениям, в рамках конференции состоятся также 2 эксклюзивных мастер-класса от ведущих специалистов Percona —
Петра Зайцева и
Светы Смирновой.

На мастер-классах будут рассмотрены самые различные темы по базам MySQL: создание и использование тестового сервера, тонкости отладки медленных запросов, особенности систем блокировок, влияние оборудования и конфигурации на производительность, сбор данных с минимальной нагрузкой на сервер.
Сегодня предлагаем вашему вниманию
перевод небольшого обзора, в котором
Света Смирнова ‒ старший инженер службы технической поддержки Percona и
Анастасия Распопина, специалист по маркетингу, сравнивают как PostgreSQL и MySQL справляются с миллионами запросов в секунду.
5-го июля для участников
PG Day’17 Светлана более подробно расскажет про архитектуру MySQL сервера и специфику работы с разными его частями, такими как оптимизатор, табличные движки, системы блокировок.
Анастасия: Могут ли базы данных с открытым исходным кодом справиться с миллионом запросов в секунду? Многие защитники открытого исходного кода ответят «да». Однако утверждений недостаточно для обоснованных доказательств. Именно поэтому в этой статье мы делимся результатами тестов от Александра Короткова (директора отдела разработки,
Postgres Professional) и Светы Смирновой (главный инженер по техническому обслуживанию, Percona). Сравнительное исследование производительности PostgreSQL 9.6 и MySQL 5.7 будет особенно полезно для сред с несколькими базами данных.


 15 марта состоялся вебинар, посвященный особенностям платежного бизнеса и интернет-эквайринга в странах ЕС. Соорганизатором онлайн-мероприятия стала наша процессинговая компания
15 марта состоялся вебинар, посвященный особенностям платежного бизнеса и интернет-эквайринга в странах ЕС. Соорганизатором онлайн-мероприятия стала наша процессинговая компания 



 Реляционные базы данных (РБД) используются повсюду. Они бывают самых разных видов, от маленьких и полезных SQLite до мощных Teradata. Но в то же время существует очень немного статей, объясняющих принцип действия и устройство реляционных баз данных. Да и те, что есть — довольно поверхностные, без особых подробностей. Зато по более «модным» направлениям (большие данные, NoSQL или JS) написано гораздо больше статей, причём куда более глубоких. Вероятно, такая ситуация сложилась из-за того, что реляционные БД — вещь «старая» и слишком скучная, чтобы разбирать её вне университетских программ, исследовательских работ и книг.
Реляционные базы данных (РБД) используются повсюду. Они бывают самых разных видов, от маленьких и полезных SQLite до мощных Teradata. Но в то же время существует очень немного статей, объясняющих принцип действия и устройство реляционных баз данных. Да и те, что есть — довольно поверхностные, без особых подробностей. Зато по более «модным» направлениям (большие данные, NoSQL или JS) написано гораздо больше статей, причём куда более глубоких. Вероятно, такая ситуация сложилась из-за того, что реляционные БД — вещь «старая» и слишком скучная, чтобы разбирать её вне университетских программ, исследовательских работ и книг.