Как я и ChatGPT писали текстовый генератор. Есть несколько изюминок
Модель нейросети больше, чем предложил чат-бот и она обучается нестандартным способом.

User
Как я и ChatGPT писали текстовый генератор. Есть несколько изюминок
Модель нейросети больше, чем предложил чат-бот и она обучается нестандартным способом.

В статье расскажу о новой функции Stable Diffusion, которая позволяет генерировать изображения в любом стиле без прописывая промта. Речь пойдет про IP-адаптер — это новая модель ControlNet, которая преобразует референсное изображение в материал для генерации. В отличие от похожих функций в Midjourney и Stable Diffusion, этот алгоритм работает невероятно точно. Он снимает стиль с заданной картинки и смешивает его с другим изображением, промтом или картой глубины. С его помощью можно создавать стилизованные портреты, пейзажи и композиции, подбирая их внешний вид простым переключением картинки-референса.

Всем привет! В этой обзорной статье мы расскажем как установить владельца сайта с помощью OSINT. Материал рассчитан на неспециалистов. Так что начнeм с самых элементарных вещей, а затем пройдeмся и по неочевидным методам, которые позволят нам узнать, кто владеет тем или иным веб-ресурсом. За подробностями добро пожаловать под кат!

Недавно мы выпустили новую значительную версию Picodata — распределенной in-memory СУБД с открытым исходным кодом. Это продукт на основе Tarantool c поддержкой плагинов на Rust и некоторыми другими интересными особенностями, о которых можно почитать в статье Picodata: простое масштабирование Tarantool.
Одно из главных улучшений в новом релизе Picodata 23.12 — возможность выполнять распределенные (кластерные) SQL-запросы непосредственно из консоли Picodata, без дополнительных настроек. Можно управлять глобальными и шардированными таблицами (DDL), модифицировать данные в них (DML) и, разумеется, читать из них (DQL). Также, мы теперь поддерживаем централизованное управление пользователями, ролями и привилегиями на основе списков контроля доступа (ACL), опять же — в рамках всего кластера.
В этой статье я сосредоточусь на нескольких примерах простых SQL-запросов и покажу, как они выполняются для таблиц, распределенных по нескольким шардам. Это позволит лучше понять, как устроены такие таблицы и какие задачи мы решаем для работы с ними.
Приветствую!
Давно не писал статей, все руки не доходили, наконец то, выбралось время и решил поделиться с Вами решением одной задачи.
Немного предыстории
В конце 2018 довелось участвовать в создание инфраструктуры одной поликлиники и одна из задач была организация почтового сервера. По желанию заказчика, предпочтение было отдано внешним службам, а именно pdd.yandex.ru. На тот момент требовалось не более 3-5 пользователей, и это решение посчитали оптимальным и самым быстрым. Но время шло, задачи менялись и в конце 2022 г. число учетных записей выросло до 95 из них активных, в повседневной работе, 25. Когда Яндекс ввел плату за каждого пользователя, было принято решение о переводе всей почты на локальное размещение. К тому же, весь доступ к почте, предполагает только локальное использование, без доступа из внешней сети. Перелопатив кучу вариантов, от коробочных решений до самосборной конфигурации, пал выбор на Kolab Groupware. Выбор был обусловлен желанием работы через WEB интерфейс, с общей адресной книгой, календарем, списком дел и файловым облаком. Плюшек хватало с лихвой, но возник ряд трудностей, о способах решения которых, я напишу ниже.

TLDR — это не готовое решение, это попытка самостоятельно разобраться, подобрать архитектуру и обучить генеративно-состязательную модель (GAN) для увеличения картинок в 2 или 4 раза. Я не претендую на то, что моя модель или путь рассуждений лучше каких-то других. Кроме того, относительно недавно стали популярны трансформеры и diffusion модели — заметки не про них.
С заметками не получилось линейной структуры повествования — есть отступления "в сторону" и уточнения. Можно пропускать нерелевантные заметки. Например, описание подготовки данных нужно, если вы хотите воспроизвести эксперименты — а в остальных случаях можно пропустить. Я написал каждую отдельную заметку по-возможности цельной и независимой от других.
Я уже был знаком со свёрточными сетками, но мне хотелось попробовать генеративно-состязательные сети. Понять, почему используют те или иные подходы. Попробовать свои идеи. Посмотреть, насколько быстро можно научить модель и насколько хорошо она будет работать.
Для обучения оказалось достаточно возможностей моего ПК. Какие-то простые эксперименты занимали десятки минут или несколько часов, самый длинный с обучением финальной большой модели — трое суток.

Разработчики машинного перевода часто рассказывают об использовании предварительно обученных моделей. Захотелось дообучить такую модель самому, но пришлось приложить усилия, чтобы найти понятный пример. Поэтому после того, как код заработал, решил поделиться скриптами.
В предыдущих статьях мы рассказали, как создать фотогалерею с собственной поисковой системой [1,2]1. Но где нам найти изображения для нашей галереи? Нам придется вручную искать источники «хороших» изображений, а затем вручную проверять, является ли каждое изображение «хорошим». Можно ли автоматизировать обе эти задачи? Ответ — да.

Недавно опять разгорелась дискуссия, как можно похудеть, работая в IT. Так вот, хороший (и научный) способ есть, и он на самом деле проще, чем можно было бы ожидать.
Конечно, если ничего не делать, то будешь только толстеть. Средний офисный сотрудник сегодня сидит больше 10 часов в день. Мы с вами, чувствую, ещё больше, особенно если на досуге играем, читаем Хабр или смотрим ютуб. Лично меня от компьютера вообще не оттащить. Хотя читал полно исследований, говорящих о больших проблемах со здоровьем, возникающих из-за малоподвижного образа жизни.
Например, было доказано, что независимо от уровня физической активности слишком много сидения увеличивает риск сердечных заболеваний, диабета, деменции и серьезных проблем со спиной. Более половины всех людей в мире сегодня уже страдают от этих проблем, и больше 80% людей в возрасте 60+.
Решение, конечно, простое — упражнения, в любой возможной форме. Но если вы такие как я, то тренироваться скучно и тяжело, правда? Большинство из нас ненавидят физкультуру. К тому же, на это нет лишнего времени. Бонусные часы каждый день магически не появятся.
Но похоже, есть способ ускорить обмен веществ в организме, даже сидя за ПК. И точно избежать проблем с метаболизмом и ожирением. Несколько недель назад вышла работа ученых под руководством Марка Гамильтона из Хьюстонского университета. Они разработали технику, позволяющую задействовать неожиданное свойство икроножных мышц, и делать для своего организма полноценную тренировку, не вставая со стула. Оказывается, похудеть, работая в IT, — это не так уж и сложно. Испытываю на себе, полёт нормальный. А какие у вас ноги будут прокачанные!

Collagen работает на новой ссылке: https://sergey1234ovechkin.github.io/collagen_2/index.html
Редактор позволяет вырезать, обрабатывать части изображений, создавать спрайты, коллажи, рисовать, добавлять текст, сохранять спрайты, сжимать и растягивать части изображений, работать с цветом, создавать маски, также поддерживает работу со слоями, имеется сетка для удобного позиционирования, поддерживает интернет шрифты например Google fonts.

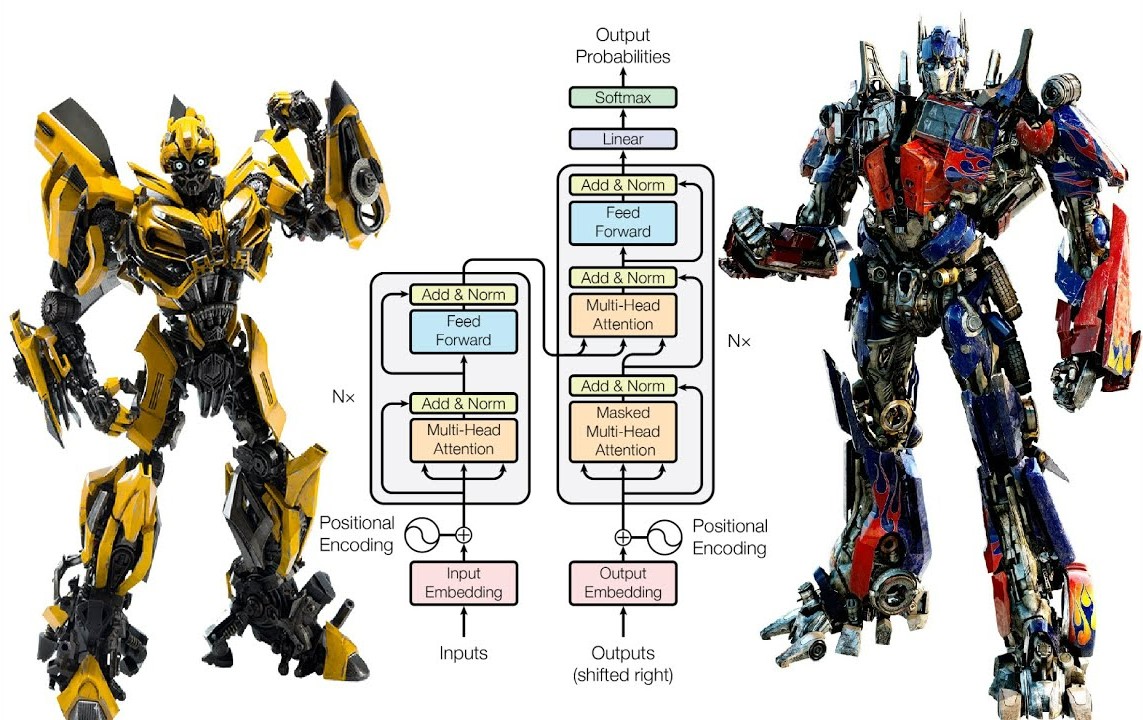
Примечание переводчика: Недавно на Хабре мы рассказывали о статьях, которые нужно прочитать, если вы хотите заниматься искусственным интеллектом. Среди них была культовая статья Attention is all you need, выпущенная в 2017 году. С неё началось развитие больших языковых моделей, в том числе всем известного чат-бота ChatGPT. Оказалось, что у такой важной статьи нет перевода на русский язык. Мы решили исправить это. Ниже вы найдёте перевод первой части статьи, вторая часть доступна по ссылке.

Что мы знаем о капче? Капча - автоматизированный тест тьюринга, помогающий отсеивать подозрительные действия недобросовестных роботов от реальных людей. Но, к сожалению ( или к счастью, смотря для кого ), текстовая капча сильно устарела. Если еще 10 лет назад она была более-менее эффективным методом защиты от роботов, то сейчас ее может взломать обойти любой желающий робот, более-менее разбирающийся в компьютере.
В данной статье-мануале я покажу, как создать собственную нейросеть по распознанию капч, имея под рукой домашний компьютер, базовые знания в python и немножко примеров капч.

Мы решили проверить технологию, на которой основан ChatGPT, посмотреть актуальное состояние open-source GPT-like моделей и ответить на вопрос — можно ли обучить GPT-like модель в домашних условиях?
Для эксперимента выбрали LLaMA и GPT-J и не самый мощный ПК с видеокартой Nvidia GTX 1080TI с 11 GB VRAM. Оказалось, что этого достаточно не только, чтобы загрузить модель, но и дообучить ее (fine-tune). Рассказываем — как мы это сделали.

В связи с быстро меняющимися технологиями разработчикам предоставляются невероятные инструменты и технологии.
Но было замечено, что различные функции и возможности API не так активно используются, и многие даже не знают о некоторых из них.
Давайте взглянем на некоторые полезные веб-API, которые могут помочь вам поднять ваш сайт до небес! (ну или около того)

Всем привет! В данной статья я хочу рассказать про XSS уязвимости, какие они бывают и откуда их можно ждать. Сразу хочу сказать, что статья предназначена скорее для новичков в теме и не претендует на уникальность или очень глубокое погружение в тему.
Так как я работаю в банке и последнее время занимаюсь разработкой фронта системы авторизации и аутентификации пользователей, мне приходится довольно много времени уделять безопасности приложения, потому что последнее чего хочет клиент банка — это компрометации его авторизационных данных:). Поэтому я решил собрать все свои знания и опыт в этой области в кучу и поделиться ими с вами. Ну и вообще тема безопасности сейчас кажется очень актуальной, тк мы чуть ли ни каждую неделю слышим истории об утечках данных даже у самых крупных и прогрессивных российских IT компаниях.

У нас несколько сервисов, где пользователи загружают файлы, отправляют файлы, обмениваются файлами.
И делать в каждом сервисе свой сервер, где можно было бы получить ссылку на файл, передать через очередь, отправить, обработать - может быть не надо?
В одном сервисе - это загрузка аватарок, в другом - это различные пользовательские файлы, по сути в транзите, в третьем - это файлы, загружаемые для конфигурирования сервиса, используются время от времени.
В каждом сервисе надо было делать директорию для файлов, следить чтобы там было достаточно места, выставить права на запись, монтировать или синхронизировать с хранилищем по необходимости.
Поэтому появился filebump - простой http сервер, где мы можем загружать, хранить и скачивать файлы.

Автоматизация сбора информации с различных ресурсов - обычная задача для людей разных сфер деятельности. Жаль, что не всегда бывает достаточно сделать простой GET запрос и разобрать полученный html. Веб-сайты, с которых собираются данные, принимают защитные меры для предотвращения автоматизированных запросов. Одной из таких мер является использование cloudflare. Сегодня мы посмотрим, как cloudflare выявляет ботов через javascript и коснёмся темы деобфускации скриптов.

Я был в восторге, когда узнал об утечке проприетарного исходного кода Яндекса. И после анализа данных я должен сказать, что выводы оказались весьма интересными! Итак, без лишних слов, давайте окунемся в основные выводы, которые я сделал.