
Пару слов о распознавании образов
13 мин
Туториал
Давно хотел написать общую статью, содержащую в себе самые основы Image Recognition, некий гайд по базовым методам, рассказывающий, когда их применять, какие задачи они решают, что возможно сделать вечером на коленке, а о чём лучше и не думать, не имея команды человек в 20.

Какие-то статьи по Optical Recognition я пишу давненько, так что пару раз в месяц мне пишут различные люди с вопросами по этой тематике. Иногда создаётся ощущение, что живёшь с ними в разных мирах. С одной стороны понимаешь, что человек скорее всего профессионал в смежной теме, но в методах оптического распознавания знает очень мало. И самое обидное, что он пытается применить метод из близрасположенной области знаний, который логичен, но в Image Recognition полностью не работает, но не понимает этого и сильно обижается, если ему начать рассказывать что-нибудь с самых основ. А учитывая, что рассказывать с основ — много времени, которого часто нет, становится всё ещё печальнее.
Какие-то статьи по Optical Recognition я пишу давненько, так что пару раз в месяц мне пишут различные люди с вопросами по этой тематике. Иногда создаётся ощущение, что живёшь с ними в разных мирах. С одной стороны понимаешь, что человек скорее всего профессионал в смежной теме, но в методах оптического распознавания знает очень мало. И самое обидное, что он пытается применить метод из близрасположенной области знаний, который логичен, но в Image Recognition полностью не работает, но не понимает этого и сильно обижается, если ему начать рассказывать что-нибудь с самых основ. А учитывая, что рассказывать с основ — много времени, которого часто нет, становится всё ещё печальнее.



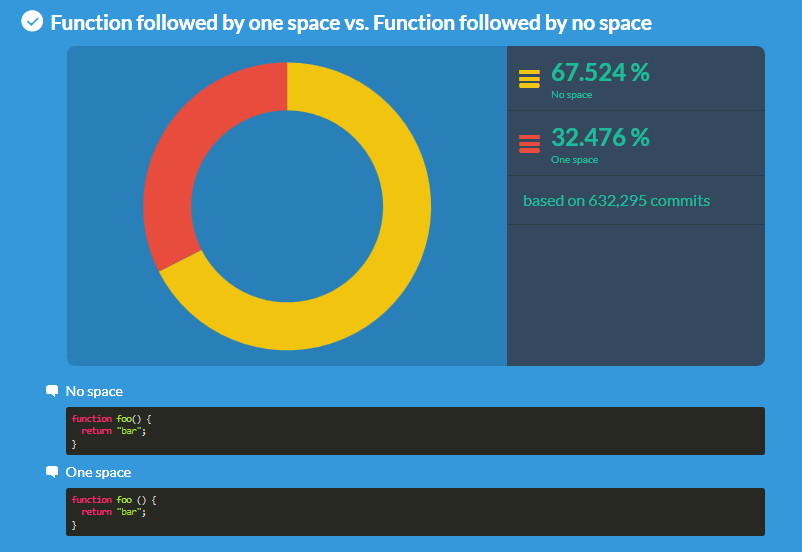


 abstract: В статье описаны продвинутые функций OpenSSH, которые позволяют сильно упростить жизнь системным администраторам и программистам, которые не боятся шелла. В отличие от большинства руководств, которые кроме ключей и -L/D/R опций ничего не описывают, я попытался собрать все интересные фичи и удобства, которые с собой несёт ssh.
abstract: В статье описаны продвинутые функций OpenSSH, которые позволяют сильно упростить жизнь системным администраторам и программистам, которые не боятся шелла. В отличие от большинства руководств, которые кроме ключей и -L/D/R опций ничего не описывают, я попытался собрать все интересные фичи и удобства, которые с собой несёт ssh. Благодаря кодам Рида-Соломона можно прочитать компакт-диск с множеством царапин, либо передать информацию в условиях связи с большим количеством помех. В среднем для компакт-диска избыточность кода (т.е. количество дополнительных символов, благодаря которым информацию можно восстанавливать) составляет примерно 25%. Восстановить при этом можно количество данных, равное половине избыточных. Если емкость диска 700 Мб, то, получается, теоретически можно восстановить до 87,5 Мб из 700. При этом нам не обязательно знать, какой именно символ передан с ошибкой. Также стоит отметить, что вместе с кодированием используется перемежевание, когда байты разных блоков перемешиваются в определенном порядке, что в результате позволяет читать диски с обширными повреждениями, локализированными близко друг к другу (например, глубокие царапины), так как после операции, обратной перемежеванию, обширное повреждение оборачивается единичными ошибками во множестве блоков кода, которые поддаются восстановлению.
Благодаря кодам Рида-Соломона можно прочитать компакт-диск с множеством царапин, либо передать информацию в условиях связи с большим количеством помех. В среднем для компакт-диска избыточность кода (т.е. количество дополнительных символов, благодаря которым информацию можно восстанавливать) составляет примерно 25%. Восстановить при этом можно количество данных, равное половине избыточных. Если емкость диска 700 Мб, то, получается, теоретически можно восстановить до 87,5 Мб из 700. При этом нам не обязательно знать, какой именно символ передан с ошибкой. Также стоит отметить, что вместе с кодированием используется перемежевание, когда байты разных блоков перемешиваются в определенном порядке, что в результате позволяет читать диски с обширными повреждениями, локализированными близко друг к другу (например, глубокие царапины), так как после операции, обратной перемежеванию, обширное повреждение оборачивается единичными ошибками во множестве блоков кода, которые поддаются восстановлению.