
Так получилось, что у меня с детства сложилась любовь к мозаикам. Те, что из детства, в стиле соцреализма про космонавтов, учёных, рабочих напоминают о мечтах о покорении космоса, и вообще о том что «трава зеленее».

Пользователь
Так получилось, что у меня с детства сложилась любовь к мозаикам. Те, что из детства, в стиле соцреализма про космонавтов, учёных, рабочих напоминают о мечтах о покорении космоса, и вообще о том что «трава зеленее».

Все мы в курсе про углеродный след. Но кто-то может представить, что в будущем нам будет не хватать таких привычных вещей, как пресная вода или песок?
В статье разберем ресурсы, с нехваткой которых при текущем уровне потребления и росте популяции человечество столкнется уже в ближайшее 50 лет. Ну и порассуждаем, к чему это приведет и что можно предпринять. Сразу оговорюсь, что банальных нефти, газа или угля в статье не будет — только не самые очевидные штуки. И да, про арабов из заголовка тоже поговорим.

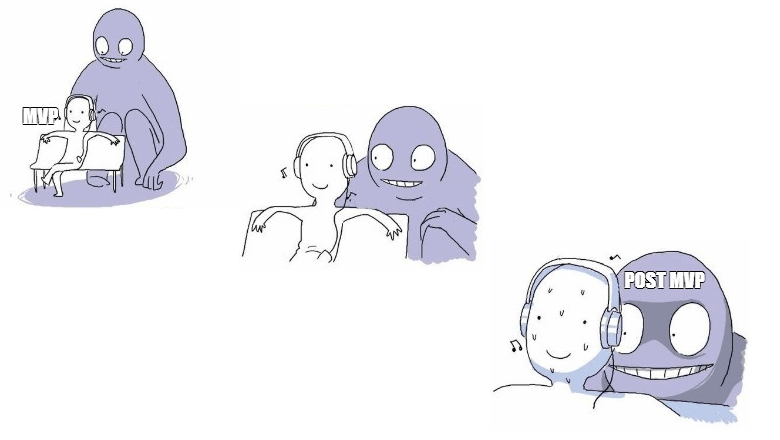
Вопрос скорости и качества стоит в разработке особенно остро. Мы привыкли думать, что чем больше времени было потрачено на разработку продукта, тем лучше результат, и наоборот. Но так ли это на самом деле?
В этой статье я предложу несколько вариантов работы над MVP, которые позволят ускорить процесс и получить продукт который впоследствии можно будет развивать многие годы.
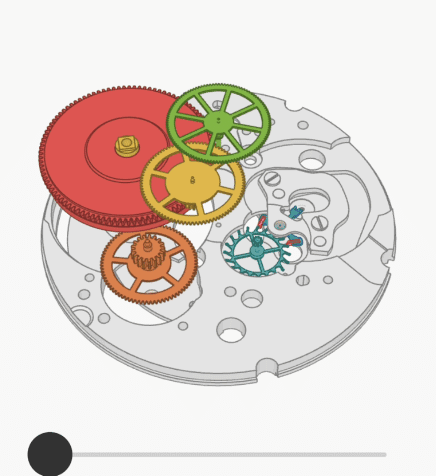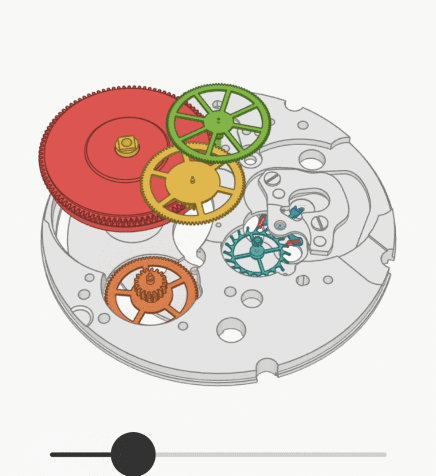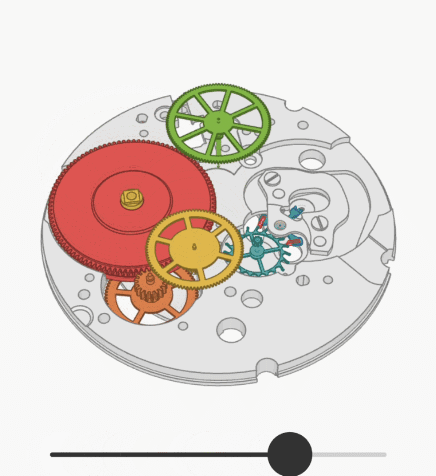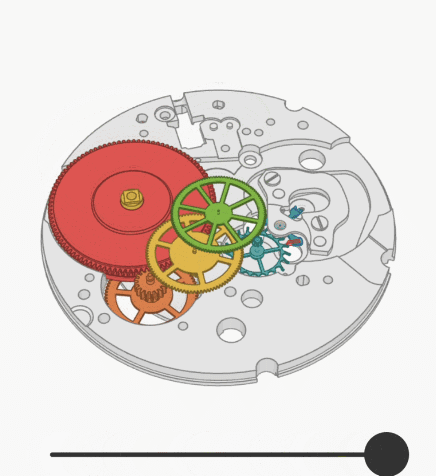


Хотел бы продемонстрировать сообществу экспериментальный подход к решению проблемы ограниченного размера контекста в GPT-4. Модель GPT-4 имеет ограничение в 8 тысяч токенов (32 тысячи токенов пока еще недоступны?), что эквивалентно примерно 32 Кбайт английского текста (128 Кбайт для 32 тысяч токенов). Это ограничение подразумевает, что суммарный размер вашего запроса и ответа модели должен быть в пределах этих ограничений. В результате модель не может отвечать на вопросы о больших документах (или обширных программных проектах), так как они не умещаются в контексте модели.

На этой неделе в издательстве Individuum вышел сборник рассказов «Пытаясь проснуться», написанных писателем и художником Павлом Пепперштейном и генеративной нейросетью ruGPT-3, разработанной командой SberDevices.
«Пытаясь проснуться» — это первый в мире сборник рассказов, родившийся в результате сотрудничества писателя и его «двойника»-нейросети. Из 24 текстов в нём только половина принадлежит Пепперштейну — ещё дюжину сочинила генеративная нейросеть ruGPT-3, дополнительно обученная на рассказах Павла.
В этом тексте мы расскажем, как обучали Нейроличность — двойника писателя — и что теперь будет с литературой (спойлер: а всё очень даже хорошо будет!).
Хайп вокруг нейросетей, выровненных при помощи инструкций и человеческой оценки (известных в народе под единым брендом «ChatGPT»), трудно не заметить. Люди разных профессий и возрастов дивятся примерами нейросетевых генераций, используют ChatGPT для создания контента и рассуждают на темы сознания, а также повсеместного отнимания нейросетями рабочих мест. Отдадим должное качеству продукта от OpenAI — так и подмывает использовать эту технологию по любому поводу — «напиши статью», «исправь код», «дай совет по общению с девушками».
Но как достичь или хотя бы приблизиться к подобному качеству? Что играет ключевую роль при обучении — данные, архитектура, ёмкость модели или что-то ещё? Создатели ChatGPT, к сожалению, не раскрывают деталей своих экспериментов, поэтому многочисленные исследователи нащупывают свой путь и опираются на результаты друг друга.
Мы с радостью хотим поделиться с сообществом своим опытом по созданию подобной модели, включая технические детали, а также дать возможность попробовать её, в том числе через API. Итак, «Салют, GigaChat! Как приручить дракона?»

Уже много времени прошло с момента публикации наших последних языковых моделей ruT5, ruRoBERTa, ruGPT-3. За это время много что изменилось в NLP. Наши модели легли в основу множества русскоязычных NLP-сервисов. Многие коллеги на базе наших моделей выпустили свои доменно-адаптированные решения и поделились ими с сообществом. Надеемся, что наша новая модель поможет вам поднять метрики качества, и ее возможности вдохновят вас на создание новых интересных продуктов и сервисов.
Появление ChatGPT и, как следствие, возросший интерес к методам обучения с подкреплением обратной связью от человека (Reinforcement Learning with Human Feedback, RLHF), привели к росту потребности в эффективных архитектурах для reward-сетей. Именно от «интеллекта» и продуктопригодности reward-модели зависит то, насколько эффективно модель для инструктивной диалоговой генерации будет дообучаться, взаимодействуя с экспертами. Разрабатывая FRED-T5, мы имели в виду и эту задачу, поскольку от качества её решения будет во многом зависеть успех в конкуренции с продуктами OpenAI. Так что если ваша команда строит в гараже свой собственный ChatGPT, то, возможно, вам следует присмотреться и к FRED’у. Мы уже ранее рассказывали в общих чертах об этой модели, а сейчас, вместе с публичным релизом, настало время раскрытия некоторых технических подробностей.
Появление новых, более производительных GPU и TPU открывает возможности для использования в массовых продуктах и сервисах всё более емких моделей машинного обучения. Выбирая архитектуру своей модели, мы целились именно в ее пригодность к массовому realtime-инференсу, поскольку время выполнения и доступное оборудование — это основные факторы, лимитирующие возможность создания массовых решений на основе нейросетевых моделей. Если вы уже используете в своем решении модель ruT5, то подменив ее на FRED-T5 вы, вероятно, получите заметное улучшение значений ваших целевых метрик. Конечно, в скором будущем мы обучим еще более емкие варианты модели FRED-T5 и проверим их возможности — мы планируем и дальнейшее развитие линейки энкодер-декодерных моделей для обработки русского языка.

Как я решил проблему т.н. "галлюцинаций" большой языковой модели в своем сервисе с помощью двойных зеркальных вопросов.

Все тестировалось на очень тупеньких запросах о написании python кода, написании рассказа на русском, cоздания playbook для Ansible c дефолтовыми threads = 4 и number of tokens to predict = 200

GPT-4 позволяет достаточно просто писать boilerplate код с использованием различных языков, технологий и библиотек. Но, есть небольшая проблема, данные GPT-4 не совсем актуальные и ограничены серединой 2021 года.
Проблема ясна, надо как то решать, потому что работать по-старому совсем не хочется. Уже привык, что можно достаточно просто попросить объяснить и сгенерировать код, пускай даже достаточно простого и можно сказать примитивного, но этого зачастую хватает, чтобы быстро понять как можно сделать задачу или найти нужную информацию.

В этой статье посмотрим как можно влиять на так называемые «галлюцинации» ChatGPT.
А что такое эти «галлюцинации»? По сути это придумывание фактов нейронной сетью, ну или просто — враньё. Управление «галлюцинациями» позволит получать то что мы хотим, ну или по крайней мере улучшит вероятность получения правдивого ответа.
Привет всем, хочу поделиться своим сборником всяких портабелек нейронок разного пошиба для винды, где уже всё установлено и надо приложить минимальные усилия, чтобы всё это запустить. Вообще все эти штуки я собирал и делал для себя, но когда я выложил это всё на itch, то оказалось, что они кому-то пригодились, и я решил репостнуть всё это безобразие на хабр. Здесь напишу небольшой список того, что реально может кому-нибудь быть полезно. Полный список с ссылками на скачивание здесь.
KoboldAI - удобный граф. интерфейс для запуска вообще всех GPT-подобных текстовых нейронок, которые поддерживает библиотека transformers. Онлайн версия со всякими модельками.
Vicuna 1.1 - очень хороший чат-бот на базе слитой LLaMa от фейсбука на 7 миллиардов, специально квантованная в 4бита и сконвертированная в формат ggml для быстрой работы на ЦПУ с граф. интерфейсом koboldcpp. Умеет в русский. Требует от 4гб RAM и процессор с AVX (любой после 2009 года вроде). Koboldcpp тоже может запускать почти всё текстовое в ggml. Онлайн версию 1.0 можно попробовать здесь.
NLLB - переводчик от фейсбука между 200 языками. Запуск не совсем однокнопочный и в jupytere, на цпу. Жрёт 4 гига оперативы. Онлайн демка.
FreeVC - не очень хороший, зато открытый клонер голоса с одного аудио на другое. Запуск тоже немножко через консоль, зато с вебгуем и на цпу. Онлайн потыкать здесь.
Whisper - транскрибатор на 60 языках от openai, работает на ЛЮБОМ гпу, даже на встроенном в ноутах(на цпу тоже, но немного помендленнее), ест мало видеопамяти, но есть и большие прожорливые модельки. Очень хорошая онлайн демка.

В конце марта 2023г., компания Databricks выпустила Dolly, большую языковую модель, подобную ChatGPT, дообученную на платформе Databricks Machine Learning Platform. Результат оценки работы модели Dolly показывает, что модель с открытым исходным кодом двухлетней давности (GPT-J) при дообучении на публичном датасете, собранном в Стэнфорде (Stanford Alpaca), на небольшом наборе данных из 50 000 диалогов (вопросов и ответов), может демонстрировать удивительно высокое качество обучения, не характерное для родительской модели (GPT-J), на которой она основана.
Но с первой версией модели Dolly существует одна проблема - датасет от Stanford Alpaca был собран с помощью автоматизированных скриптов от ChatGPT, что нарушает лицензию и правила использования моделей OpenAI.
Чтобы исправить эту проблему, в апреле 2023г. Databricks выпустила
Dolly 2 - большую языковую модель с открытым исходным кодом и открытой лицензией для научных и коммерческих целей.
Dolly 2 - это языковая модель с 12 млрд. параметров, основанная на семействе моделей EleutherAI pythia и дообученная исключительно на новом датасете высокого качества, созданном сотрудниками Databricks с использованием RL from Human Feedback (RLHF).
Databricks открыли исходный код Dolly 2, включая код обучения, сам датасет и веса модели, подходящие для коммерческого использования. Это означает, что любая организация может создавать, владеть и настраивать комплексные модели, не платя за доступ к API или передавая данные третьим сторонам.

Всем привет, я — Кирилл, frontend разработчик компании Usetech.
Сегодня поговорим о глубоком и поверхностном клонировании объекта, посмотрим различные примеры и способы как это можно реализовать, а также разберём отличия, плюсы и минусы данного подхода, уделим внимание новому встроенному методу глубокого клонирования — structuredClone.
Глубокое клонирование:
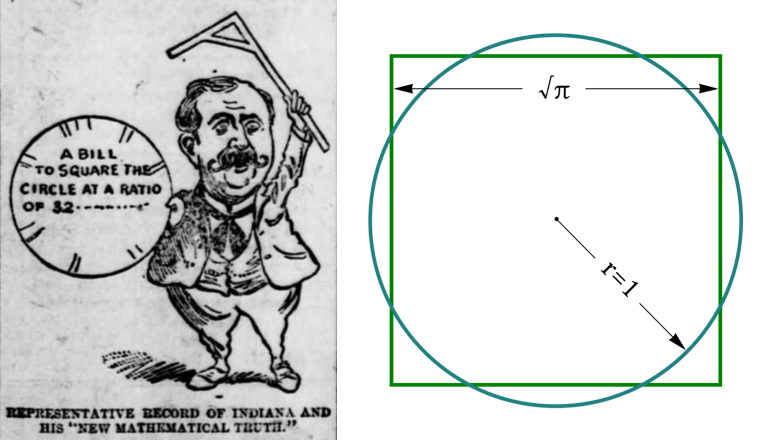
Поздравляю всех с днем числа Пи! (день числа Пи отмечается 14 марта, поскольку эта дата в американском формате записывается в как 3.14 - прим. перев.) Чтобы отметить его как следует, я хочу ненадолго отвлечься от программного обеспечения и поговорить о чем-то особом. Возможно, вы слышали байку о том, как в штате Индиана пытались законодательно приравнять число Пи к чем-то типа 3, или 4, или 3.15. Обычно ее рассказывают в качестве доказательства того, что жители Индианы - бестолковая деревенщина, но это далеко не вся история. Зачем они пытались поменять значение π и на что они рассчитывали?
Я занялся исследованием, и теперь могу рассказать историю целиком. Чтобы вы поняли контекст, мне придется объяснить кое-какие математические концепции.
Мне придется объяснить немало математических концепций.