TLB — это кэш, но все операции доступа к памяти (в нормальных режимах) проходят через него и не могут завершиться без выдачи физадреса из tlb. При промахе всех уровней tlb будет совершен (в MMU) pt walk, заполнение строки в tlb, трансляция физадреса + проверка прав. Т.е. инструкция работы с памятью не может завершиться, пока не ответил TLB.
TLB — это часть MMU, см http://www.cs.vu.nl/~giuffrida/papers/anc-ndss-2017.pdf "Fig. 2. Memory organization in a recent Intel processor.… The MMU performs the translation from the virtual address to the physical address using the TLB before accessing the data or the instruction since the caches that store the data are tagged with physical addresses (i.e., physically-tagged caches).".
https://googleprojectzero.blogspot.ru/2018/01/reading-privileged-memory-with-side.html
The underlying idea is that the permission check for accessing an address might not be on the critical path for reading data from memory to a register, where the permission check could have significant performance impact. Instead, the memory read could make the result of the read available to following instructions immediately and only perform the permission check asynchronously, setting a flag in the reorder buffer that causes an exception to be raised if the permission check fails.
Это иллюстрация другой методики, когда на двух разных виртуальных машинах работает специальный код, пересылающий данные между ними по скрытому каналу через кэш-память
Black Hat Asia 2017: Hello From the Other Side https://www.youtube.com/watch?v=a9sGk7FtnYk SSH Over Robust Cache Covert Channels in the Cloud (от тех же Daniel Gruss и ко) https://gruss.cc/files/hello.pdf
Especially cache covert channels allow the transmission of several hundred kilobits
per second between unprivileged user programs in separate virtual machines… Our errorcorrecting and error-handling high-throughput covert channel can sustain transmission rates of more than 45 KBps on Amazon EC2, which is 3 orders of magnitude higher than previous covert channels demonstrated on Amazon EC2. Our robust and errorfree channel even allows us to build an SSH connection between two virtual machines, where all existing covert channels fail.
… Covert channels are unauthorized communication channels between two parties, a sender and a receiver.… At a high level, the sender transmits bits by evicting cache lines from the receiver. The receiver constantly probes a set in his L1 cache. These cache lines are also present in the lastlevel cache due to the inclusive property. To transmit a ‘0’, the
sender does nothing. The lines thus stay in the L1 cache of the receiver, which thus observes a short timing to probe its lines. To transmit a ‘1’, the sender accesses cache lines that are mapped to the same set in the last-level cache as the receiver’s.
По Spectre для примера в статье заявлена скорость порядка килобайтов в сек https://spectreattack.com/spectre.pdf The unoptimized code in Appendix A reads approximately 10KB/second on an i7 Surface Pro 3.
Для meltdown быстрее — https://meltdownattack.com/meltdown.pdf we can dump kernel and physical memory with up to 503 KB/s… With exception handling, we achieved average reading speeds of 123 KB/s when leaking 12 MB of kernel memory
Cache attacks on x86 CPUs employ the unprivileged rdtsc instruction to obtain a sub-nanosecond resolution timestamp. The ARMv7-A architecture does not provide an instruction for this purpose… We broaden the attack surface by exploiting timing sources that are accessible without any privileges or permissions.
Dedicated thread timer. If no interface with sufficient accuracy is available, an attacker can run a thread that increments a global variable in a loop, providing a fair approximation of a cycle counter. Our experiments show that this approach works reliably on smartphones as well as recent x86 CPUs. The resolution of this threaded timing information is as high as with the other methods.
Intel and other vendors had planned to disclose this issue next week when more software and firmware updates will be available. However, Intel is making this statement today because of the current inaccurate media reports.
We were gonna say something next week, but those bastards at The Register blew the lid on it early so
The preferred phrase at present is "coordinated disclosure." "Responsible disclosure" suggests the media and security researchers have been irresponsible for reporting on this issue before Intel was ready to go public. Once we get into assigning blame, that invites terms like "responsible microarchitecture design" or "responsible sales of processors known to contain vulnerabilities" or "responsible handling of security disclosures made last June."
The AMD microarchitecture does not allow memory references, including speculative references, that access higher privileged data when running in a lesser privileged mode
when that access would result in a page fault.
Почему, несмотря на более высокую тактовую частоту и широко разрекламированные маркетинговым отделом Intel архитектурные особенности Net Burst (такие, как Trace Cache, Rapid Execution Engine, Quad-Pumped Bus, Hardware prefetch и даже Hyper-Treading), призванные увеличить число команд, исполняемых за такт, процессоры Pentium 4 умудряются часто проигрывать своим менее частотным собратьям и конкурентам в лице семейств Pentium M и AMD Athlon?
Представитель amd заявил, что их микроархитектура не допускает доступа к более привилегированной памяти из менее привилегированного контекста (в т.ч. спекулятивного) и предложил не включать "kpti" на AMD https://lkml.org/lkml/2017/12/27/2 Tom Lendacky (amd)
AMD processors are not subject to the types of attacks that the kernel
page table isolation feature protects against. The AMD microarchitecture
does not allow memory references, including speculative references, that
access higher privileged data when running in a lesser privileged mode
when that access would result in a page fault.
Disable page table isolation by default on AMD processors by not setting
the X86_BUG_CPU_INSECURE feature, which controls whether X86_FEATURE_PTI
is set.
- /* Assume for now that ALL x86 CPUs are insecure */
- setup_force_cpu_bug(X86_BUG_CPU_INSECURE);
+ if (c->x86_vendor != X86_VENDOR_AMD)
+ setup_force_cpu_bug(X86_BUG_CPU_INSECURE);
Сам TLB работает быстро, он транслирует виртуальные адреса в физические. Точнее L1 TLB работает очень быстро (1 такт?), но он очень небольшой (64 записи, одна запись описывает трансляцию одной страницы — чаще всего — 4КБ), его промахи попадают в L2 TLB, который уже медленнее (8 тактов), зато 1.5 тыс записей (физически такое количество записей сложно/невозможно адресовать за 1 такт высокой частоты).
Медленно обрабатываются промахи в (L2) TLB, когда TLU-блок процессора начинает хождение по таблице (дереву) страниц. В замерах http://www.7-cpu.com/cpu/Zen.html на разных размерах страниц заметно:
2 MB pages (32-bit)
2MB Data TLB L1: 64 items. full assoc. Miss Penalty = 8 cycles. Parallel miss:? cycles per access
2MB Data TLB L2: 1536 items. 2-way?. Miss Penalty =? cycles. Parallel miss:? cycles per access
4 KB pages mode (64-bit)
Data TLB L1: 64 items. full assoc. Miss penalty = 8 cycles. Parallel miss: 1 cycle per access
Data TLB L2: 1536 items. 8-way?. Miss penalty = 34? cycles. Parallel miss: 18? cycles per access (read from L3)
PDE cache =? items. Miss penalty =? cycles.
Size Latency Increase Description
32 K 4
64 K 11 7 + 13 (L2)
128 K 14 3
256 K 16 2
512 K 20 4 + 8 (L1 TLB miss)
1 M 35 15 + 23 (L3)
2 M 42 7
4 M 45 3
8 M 63 + 5 ns 18 + 5 ns + 34 ? (L2 TLB miss)
16 M 72 + 48 ns 9 + 43 ns + 90 ns (RAM)
32 M 82 + 70 ns 10 + 22 ns
64 M 87 + 81 ns 5 + 11 ns
128 M 97 + 86 ns 10 + 5 ns
256 M 109 + 88 ns 10 + 2 ns
512 M 113 + 89 ns 4 + 1 ns
1024 M 125 + 90 ns 12 + 1 ns
Not having the required federal permits plus mechanical problems with his "motorhome/rocket launcher" forced self-taught rocket scientist "Mad" Mike Hughes to put his experiment on hold.
The U.S. Bureau of Land Management (BLM) "told me they would not allow me to do the event… at least not at that location," Hughes said in a YouTube announcement, amid international attention over his plans to launch into the 'atmosflat.'
О каких иных технологиях не знает WD, изготавливая оба вида памяти? Пространственная плотность NAND уже давно выше чем у HDD, но магнитные пластины больше по площади и дешевле в производстве.
Например, когда мы видим 2 терабайтный T3 SSD 2016 года с 4 "чипами" https://m.eet.com/images/eetimes/2016/04/1329360/2.jpg — реально это 4 корпуса, в каждом из которых запаковано 16 кристаллов (по 256 Гбит — 256∗16∗4 / 8 = 2 ТБ) общей площадью 99mm² ∗16∗4=6336 mm². Кристаллы утончили до рекордных 40 µm, что позволило уместить стопку из 16 в корпусе высотой 1.1 мм. Берем калькулятор http://www.silicon-edge.co.uk/j/index.php/resources/die-per-wafer и получаем около 600 кристаллов (8.25х12мм) с одной 300 мм пластины — всего 19 — 23 терабайта (602∗256/8 через 256gbit die; 70000 mm²∗2.6/8 через плотность). С плотностями nand 2017 года — 34 — 38 ТБ с 300 мм пластины.
Себестоимость пластины неизвестна, по порядку величины — тысячи долларов (и многослойные 3d nand дороже планарных nand). T3 2TB (nand + контроллер + dram + uasp мост + корпус) и T5 2TB (тоже 256Гбит кристаллы, но уже VNAND V4 — 64 слоя вместо 48) продавали по 800 USD.
Происхождение золота также описано в Википедии: "Поскольку сразу после своего возникновения Земля была в расплавленном состоянии, почти всё золото в настоящее время на Земле находится в ядре.… (среднее) Содержание золота в земной коре очень низкое — 4,3·10^-10 % по массе[4] (0,5-5 мг/т[25][26])"
https://pubs.usgs.gov/gip/prospect1/goldgip.html — Though scarce, gold is concentrated by geologic processes to form commercial deposits of two principal types: lode (primary) deposits and placer (secondary) deposits.
Lode deposits are the targets for the "hardrock" prospector seeking gold at the site of its deposition from mineralizing solutions. Geologists have proposed various hypotheses to explain the source of solutions from which mineral constituents are precipitated in lode deposits.
One widely accepted hypothesis proposes that many gold deposits, especially those found in volcanic and sedimentary rocks, formed from circulating ground waters driven by heat from bodies of magma (molten rock) intruded into the Earth's crust within about 2 to 5 miles of the surface. Active geothermal systems, which are exploited in parts of the United States for natural hot water and steam, provide a modern analog for these gold-depositing systems. Most of the water in geothermal systems originates as rainfall, which moves downward through fractures and permeable beds in cooler parts of the crust and is drawn laterally into areas heated by magma, where it is driven upward through fractures. As the water is heated, it dissolves metals from the surrounding rocks. When the heated waters reach cooler rocks at shallower depths, metallic minerals precipitate to form veins or blanket-like ore bodies.
Another hypothesis suggests that gold-bearing solutions may be expelled from magma as it cools, precipitating ore materials as they move into cooler surrounding rocks. This hypothesis is applied particularly to gold deposits located in or near masses of granitic rock, which represent solidified magma.
A third hypothesis is applied mainly to gold-bearing veins in metamorphic rocks that occur in mountain belts at continental margins. In the mountain-building process, sedimentary and volcanic rocks may be deeply buried or thrust under the edge of the continent, where they are subjected to high temperatures and pressures resulting in chemical reactions that change the rocks to new mineral assemblages (metamorphism). This hypothesis suggests that water is expelled from the rocks and migrates upwards, precipitating ore materials as pressures and temperatures decrease. The ore metals are thought to originate from the rocks undergoing active metamorphism.
Another use for hardware injection in Initial LIGO were “blind injections” which were hardware injections known only to a small team [11,12]. Blind injections simulate the detection and characterization of a real astrophysical signal. No blind injections were carried out during Advanced LIGO’s first observing run. There are no plans to perform blind injections in future observing runs.

TLB — это кэш, но все операции доступа к памяти (в нормальных режимах) проходят через него и не могут завершиться без выдачи физадреса из tlb. При промахе всех уровней tlb будет совершен (в MMU) pt walk, заполнение строки в tlb, трансляция физадреса + проверка прав. Т.е. инструкция работы с памятью не может завершиться, пока не ответил TLB.
Физадрес из tlb cam надо сразу выдавать в сторону кэш-памяти для параллельной сверки тэгов в VIPT L1 (приблизительно/условно так http://images.slideplayer.com/39/10978514/slides/slide_23.jpg http://images.slideplayer.com/23/6620421/slides/slide_16.jpg). Выдаются ли права доступа в сторону кэша — неясно (для них неважно, будет ли попадание в кэш), их надо проверить и выдать в какое-то устройство OOO-конвейера — ROB / MOB / retire...
TLB — это часть MMU, см http://www.cs.vu.nl/~giuffrida/papers/anc-ndss-2017.pdf "Fig. 2. Memory organization in a recent Intel processor.… The MMU performs the translation from the virtual address to the physical address using the TLB before accessing the data or the instruction since the caches that store the data are tagged with physical addresses (i.e., physically-tagged caches).".
Права доступа негде хранить, кроме как в TLB (их оригинал хранится в PT data structure, в PTE, но до настоящей pte далеко). Так как права должны быть проверены к моменту retire каждой инструкции, работающей с памятью, они не могут читаться из памяти или из обычных кэшей (всё чтение в L1 включая попадание в TLB и проверку прав занимает 4 такта). При этом права из TLB могут быть выдаваться в какие-то другие направления…
https://xem.github.io/minix86/manual/intel-x86-and-64-manual-vol3/o_fe12b1e2a880e0ce-140.html
https://xem.github.io/minix86/manual/intel-x86-and-64-manual-vol3/o_fe12b1e2a880e0ce-141.html
Each entry in a TLB… contains the… The access rights from the paging-structure entries…
https://xem.github.io/minix86/manual/intel-x86-and-64-manual-vol3/o_fe12b1e2a880e0ce-133.html
https://googleprojectzero.blogspot.ru/2018/01/reading-privileged-memory-with-side.html
The underlying idea is that the permission check for accessing an address might not be on the critical path for reading data from memory to a register, where the permission check could have significant performance impact. Instead, the memory read could make the result of the read available to following instructions immediately and only perform the permission check asynchronously, setting a flag in the reorder buffer that causes an exception to be raised if the permission check fails.
Это иллюстрация другой методики, когда на двух разных виртуальных машинах работает специальный код, пересылающий данные между ними по скрытому каналу через кэш-память
Black Hat Asia 2017: Hello From the Other Side
https://www.youtube.com/watch?v=a9sGk7FtnYk SSH Over Robust Cache Covert Channels in the Cloud (от тех же Daniel Gruss и ко)
https://gruss.cc/files/hello.pdf
По Spectre для примера в статье заявлена скорость порядка килобайтов в сек https://spectreattack.com/spectre.pdf The unoptimized code in Appendix A reads approximately 10KB/second on an i7 Surface Pro 3.
Для meltdown быстрее — https://meltdownattack.com/meltdown.pdf we can dump kernel and physical memory with up to 503 KB/s… With exception handling, we achieved average reading speeds of 123 KB/s when leaking 12 MB of kernel memory
Для замера времени без TSC иногда предлагают запустить второй поток, который будет просто постоянно инкрементировать счетчик в общей памяти. Метод от тех же самых Graz UoT… (Можно запретить потоки, запретить запускать свой код, запретить наличие кодогенераторов, см iOs: https://stackoverflow.com/questions/5054732/is-it-prohibited-using-of-jitjust-in-time-compiled-code-in-ios-app-for-appstor "3.3.2 An Application may not download or install executable code...")
https://news.ycombinator.com/item?id=16066871&ref=hvper.com Timer coarsening is a bad idea. Turns out [1], a simple timer thread is a good enough poor man's cycle counter. What are you going to do: ban variables?
https://www.usenix.org/system/files/conference/usenixsecurity16/sec16_paper_lipp.pdf ARMageddon: Cache Attacks on Mobile Devices (Moritz Lipp, Daniel Gruss et al, Graz, August 10–12, 2016) 3.3 Accurate Unprivileged Timing ..
https://blog.mozilla.org/security/2018/01/03/mitigations-landing-new-class-timing-attack/
, mitigation we are disabling or reducing the precision of several time sources in Firefox. This includes both explicit sources, like performance.now(), and implicit sources that allow building high-resolution timers, viz., SharedArrayBuffer.
KAISER еще раньше начали делать: https://github.com/IAIK/KAISER (https://gruss.cc/files/kaiser.pdf JUNE 3, 2017), уже пару месяцев их патч адаптировали к включению в ядро. Были посты https://cyber.wtf/2017/07/28/negative-result-reading-kernel-memory-from-user-mode/ и http://pythonsweetness.tumblr.com/post/169166980422/the-mysterious-case-of-the-linux-page-table.
О баге подробно написал The Register, из-за информацию огласили раньше (на неделю?), чем планировали: https://www.theregister.co.uk/2018/01/02/intel_cpu_design_flaw/
https://www.theregister.co.uk/2018/01/04/intel_meltdown_spectre_bugs_the_registers_annotations/
В https://lkml.org/lkml/2017/12/27/2 представитель amd Tom Lendacky писал, что все операции доступа в память, в т.ч. спекулятивные у амд проверяют уровни доступа (и отключил kpti для amd — https://github.com/torvalds/linux/commit/694d99d40972f12e59a3696effee8a376b79d7c8):
https://fcenter.ru/online/hardarticles/processors/12033-Replay_neizvestnye_osobennosti_funkcionirovaniya_yadra_Netburst "Replay: неизвестные особенности функционирования ядра Netburst" 25.02.2005
С тех пор HypedThreading переделали...
Представитель amd заявил, что их микроархитектура не допускает доступа к более привилегированной памяти из менее привилегированного контекста (в т.ч. спекулятивного) и предложил не включать "kpti" на AMD
https://lkml.org/lkml/2017/12/27/2 Tom Lendacky (amd)
Первая публикация "по мотивам" была Jun 24, 2017 https://gruss.cc/files/kaiser.pdf, патчи Linux уже несколько месяцев пишут — https://lkml.org/lkml/2017/12/4/709 https://lkml.org/lkml/2017/12/4/709 [patch 00/60] x86/kpti: Kernel Page Table Isolation (was KAISER)
на базе пакета патчей, готового к 1 ноября 2017 https://github.com/IAIK/KAISER "Kernel Address Isolation to have Side-channels Efficiently Removed"
Latest commit 6112890 Nov 1, 2017 @dgruss
Для вызовов отрисовки — да — http://dri.sourceforge.net/doc/dri_control_flow.html, см стрелки в обход kernel: Direct rendering program (3D):
Direct rendering (3D data) -> 3D data -> Graphics Hardware
https://en.wikipedia.org/wiki/Direct_Rendering_Manager / https://en.wikipedia.org/wiki/Direct_Rendering_Infrastructure
2 гигабайта в секунду, причем даже на небольших размерах очереди:
http://www.techradar.com/news/meet-intels-insanely-fast-optane-ssd-900p-drives
Optane SSD 900P sequential read speed rating of 2,500MB/s and a sequential write speed of 2,000MB/s.
https://www.anandtech.com/show/11953/the-intel-optane-ssd-900p-review/8 The Intel Optane SSD 900P 280GB Review
https://www.anandtech.com/show/12136/the-intel-optane-ssd-900p-480gb-review/6 The Intel Optane SSD 900p 480GB Review: Diving Deeper Into 3D XPoint
Эквивалентно при какой ширине шины?
900 миллионов долларов 2009 года на марсоход: https://space.stackexchange.com/questions/5449/cost-breakdown-for-curiosity-development
Одного плутония-238 в батарейке у него 4.8 кг, при цене килограмма в 8 миллионов долларов (и отсутствии запасов).
Процессоры RAD750 — сотни тысяч долларов за штуку.
Сам TLB работает быстро, он транслирует виртуальные адреса в физические. Точнее L1 TLB работает очень быстро (1 такт?), но он очень небольшой (64 записи, одна запись описывает трансляцию одной страницы — чаще всего — 4КБ), его промахи попадают в L2 TLB, который уже медленнее (8 тактов), зато 1.5 тыс записей (физически такое количество записей сложно/невозможно адресовать за 1 такт высокой частоты).
Медленно обрабатываются промахи в (L2) TLB, когда TLU-блок процессора начинает хождение по таблице (дереву) страниц. В замерах http://www.7-cpu.com/cpu/Zen.html на разных размерах страниц заметно:
2 MB pages (32-bit)
2MB Data TLB L1: 64 items. full assoc. Miss Penalty = 8 cycles. Parallel miss:? cycles per access
2MB Data TLB L2: 1536 items. 2-way?. Miss Penalty =? cycles. Parallel miss:? cycles per access
4 KB pages mode (64-bit)
Data TLB L1: 64 items. full assoc. Miss penalty = 8 cycles. Parallel miss: 1 cycle per access
Data TLB L2: 1536 items. 8-way?. Miss penalty = 34? cycles. Parallel miss: 18? cycles per access (read from L3)
PDE cache =? items. Miss penalty =? cycles.
TLB работает на частоте процессорного ядра, оба D TLB находятся "рядом" (перед/параллельно) с L1 кэшем данных (попадание в L1 Tlb и L1d занимает в сумме 4 такта) — https://images.anandtech.com/doci/10591/HC28.AMD.11.png (I TLB — перед L1 кэшем инструкций — https://images.anandtech.com/doci/11170/AMD%20Ryzen%20Tech%20Day%20-%20Architecture%20Keynote-07%20-%20Copy%20%282%29.jpg; иллюстрации AMD из Anand 11170)
https://space.stackexchange.com/questions/18885/why-does-blue-origin-land-the-crew-capsule-separate-from-the-booster
Предположения: Пустая ступень с тяжелой капсулой сверху будет нестабильна, механизм расстыковки упрощает систему аварийного спасения (" launch escape system that can separate the capsule from the booster rocket anywhere during the ascent.", https://www.youtube.com/watch?v=N5i-f-D_A-M), увеличение безопасности (например, при ошибках посадки ступени).
Отменил ракетный запуск чтобы "доказать, что земля плоская":
https://www.usatoday.com/story/news/nation-now/2017/11/25/mad-mike-hughes-cancels-rocket-launch-prove-earth-flat/894762001/
'Mad' Mike Hughes cancels rocket launch to prove Earth is flat; Nov. 27, 2017
Правительство явно что-то скрывает: https://www.livescience.com/61026-flat-earther-rocket-delay.html US Government Shuts Down Flat-Earther's Rocket Launch — November 27, 2017
https://geektimes.ru/post/295685/#comment_10467171 -> http://meduza.io/feature/2017/11/26/amerikanets-postroil-samodelnuyu-raketu-chtoby-dokazat-chto-zemlya-ploskaya-start-otmenili-v-posledniy-moment
Новостей в FB нет https://www.facebook.com/madmikehughes/, сайт madmikehughes.com не работает.
Есть некий видеопост от December 2 2017 https://www.youtube.com/watch?v=l63VCQvjU3A, предыдущие видео встречаются у пользователя https://www.youtube.com/user/ezenvelope/videos?disable_polymer=1
IDC в этом году предсказывал снижение разрыва в цене за ТБ: SSD могут стать всего в 2.2 раза дороже HDD в 2021 году.
Но есть такой прогноз стоимости за ТБ от производителя и HDD и SSD — десятикратный разрыв в стоимости за ТБ между SSD и HDD сохранится в ближайшие десять лет:
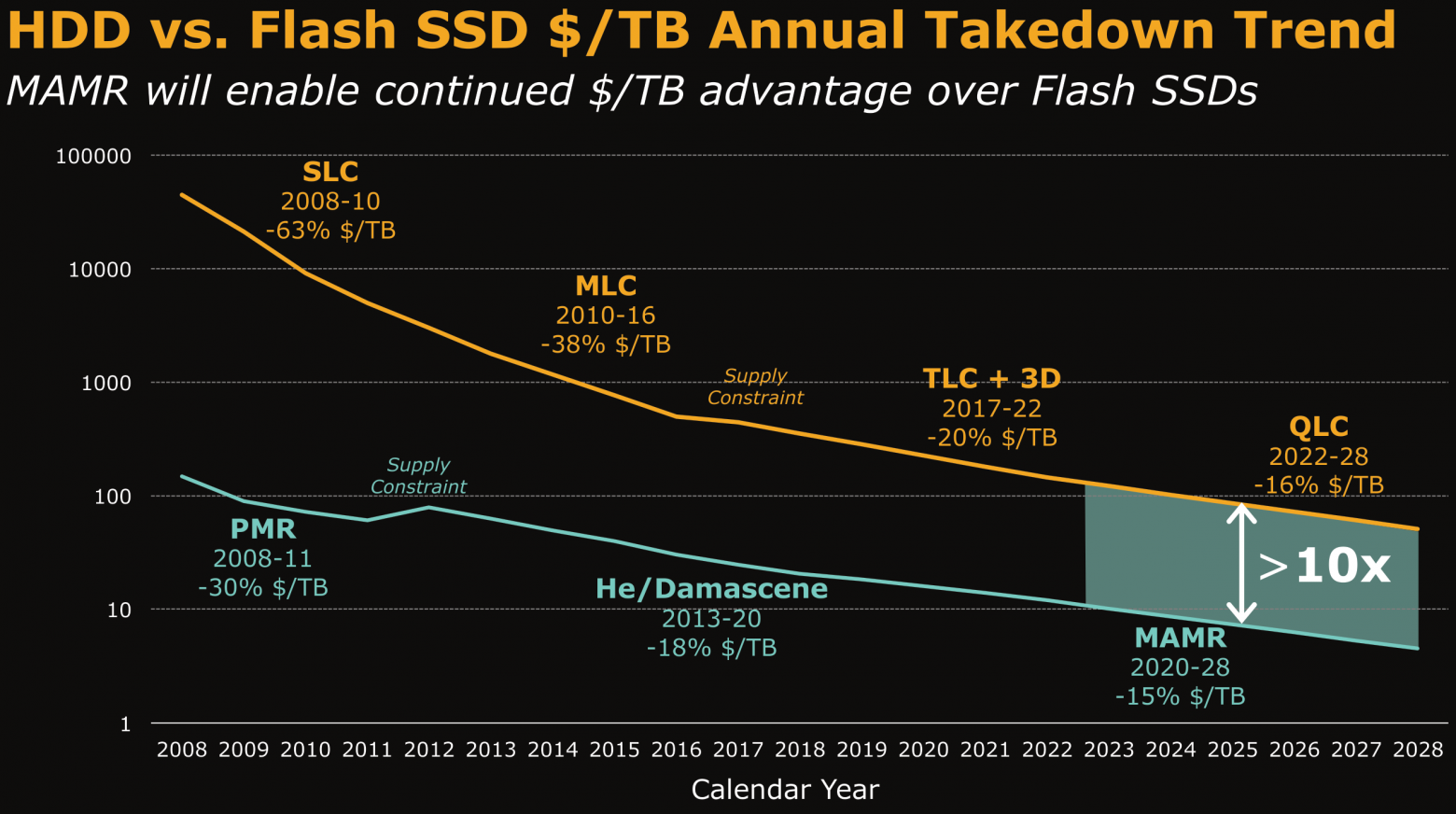
https://images.anandtech.com/doci/11925/02_-_flash-hdd-cpgb.png "HDD vs Flash SSD $/TB Annual Takedown Trend"
из статьи от October 12, 2017.
О каких иных технологиях не знает WD, изготавливая оба вида памяти? Пространственная плотность NAND уже давно выше чем у HDD, но магнитные пластины больше по площади и дешевле в производстве.
Себестоимость чипов можно примерно оценить из плотности, для SSD: https://www.eetimes.com/author.asp?section_id=36&doc_id=1329360 2016-04-06
Density (Mb/mm²)
http://thememoryguy.com/64-layer-3d-nand-chips-revealed-at-isscc/ February 11, 2017
https://www.anandtech.com/show/11454/techinsights-publishes-preliminary-analysis-of-3d-xpoint-memory 2017
Например, когда мы видим 2 терабайтный T3 SSD 2016 года с 4 "чипами" https://m.eet.com/images/eetimes/2016/04/1329360/2.jpg — реально это 4 корпуса, в каждом из которых запаковано 16 кристаллов (по 256 Гбит — 256∗16∗4 / 8 = 2 ТБ) общей площадью 99mm² ∗16∗4=6336 mm². Кристаллы утончили до рекордных 40 µm, что позволило уместить стопку из 16 в корпусе высотой 1.1 мм. Берем калькулятор http://www.silicon-edge.co.uk/j/index.php/resources/die-per-wafer и получаем около 600 кристаллов (8.25х12мм) с одной 300 мм пластины — всего 19 — 23 терабайта (602∗256/8 через 256gbit die; 70000 mm²∗2.6/8 через плотность). С плотностями nand 2017 года — 34 — 38 ТБ с 300 мм пластины.
Себестоимость пластины неизвестна, по порядку величины — тысячи долларов (и многослойные 3d nand дороже планарных nand). T3 2TB (nand + контроллер + dram + uasp мост + корпус) и T5 2TB (тоже 256Гбит кристаллы, но уже VNAND V4 — 64 слоя вместо 48) продавали по 800 USD.
Свежий прогноз стоимости за ТБ от производителя HDD и SSD: https://images.anandtech.com/doci/11925/02_-_flash-hdd-cpgb.png
из https://www.anandtech.com/show/11925/western-digital-stuns-storage-industry-with-mamr-breakthrough-for-nextgen-hdds, October 12, 2017
Самородки золота создаются в гидротермальных процессах, концентрируясь уже в составе планет за длительное время: http://wiki.web.ru/wiki/Золото_самородное
https://en.wikipedia.org/wiki/Ore_genesis#Gold "The gold is transported up faults by hydrothermal waters and deposited when the water cools too much to retain gold in solution."
(при этом разрабатываются руды с 1 граммом золота на тонну породы "эндогенные золотоносные руды — гидротермального происхождения")
Происхождение золота также описано в Википедии: "Поскольку сразу после своего возникновения Земля была в расплавленном состоянии, почти всё золото в настоящее время на Земле находится в ядре.… (среднее) Содержание золота в земной коре очень низкое — 4,3·10^-10 % по массе[4] (0,5-5 мг/т[25][26])"
Сообщают также о биологических путях при помощи https://en.wikipedia.org/wiki/Cupriavidus_metallidurans / https://en.wikipedia.org/wiki/Delftia_acidovorans "it plays a vital role, together with the species Delftia acidovorans, in the formation of gold nuggets, by precipitating metallic gold from a solution of gold(III) chloride, a compound highly toxic to most other microorganisms"; https://nplus1.ru/material/2017/03/10/gold-mining ("… Вероятно, бактерии сыграли существенную роль в истории миграции и перераспределения золота на Земле.")
Также — https://www.reddit.com/r/askscience/comments/78pycw/why_are_elements_like_gold_found_in_chunks_and/ и https://www.reddit.com/r/askscience/comments/1iht1x/how_do_gold_atoms_accumulate_in_one_place_in_the/
https://pubs.usgs.gov/gip/prospect1/goldgip.html — Though scarce, gold is concentrated by geologic processes to form commercial deposits of two principal types: lode (primary) deposits and placer (secondary) deposits.
Статья про калибровочные вбросы с упоминанием об отказе от слепых вбросов — https://arxiv.org/abs/1612.07864 / https://dspace.mit.edu/openaccess-disseminate/1721.1/109797 Validating gravitational-wave detections: The Advanced LIGO hardware injection system, PHYSICAL REVIEW D 95, 062002 (2017)