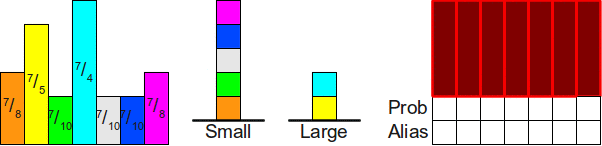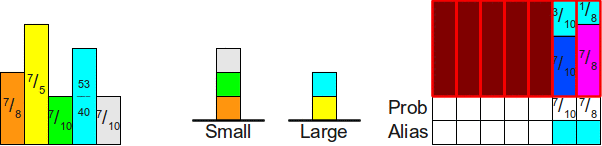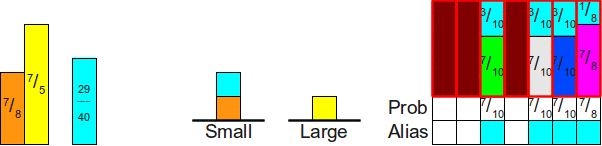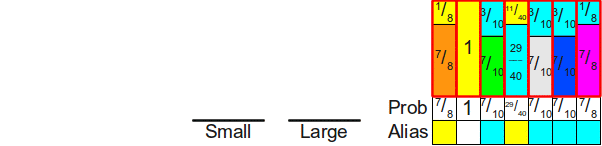
Однажды я задал на Stack Overflow вопрос о
структуре данных для шулерских игральных костей. В частности, меня интересовал ответ на такой вопрос: «Если у нас есть n-гранная кость, у грани которой i есть вероятность выпадения p
i. Какова наиболее эффективная структура данных для симуляции бросков такой кости?»
Такую структуру данных можно использовать для многих задач. Например, можно применять её для симуляции бросков честной шестигранной кости, присвоив вероятность
каждой из сторон кости, или для симуляции честной монетки имитацией двусторонней кости, вероятность выпадения каждой из сторон которой равна
. Также можно использовать эту структуру данных для непосредственной симуляции суммы двух честных шестигранных костей, создав 11-гранную кость (с гранями 2, 3, 4, ..., 12), каждая грань которой имеет вес вероятности, соответствующий броскам двух честных костей. Однако можно также использовать эту структуру данных и для симуляции шулерских костей. Например, если вы играете в
«крэпс» с костью, которая, как вы точно знаете, не идеально честная, то можно использовать эту структуру данных для симуляции множества бросков костей и анализа оптимальной стратегии. Также можно попробовать симулировать аналогичным образом неидеальное
колесо рулетки.
Если выйти за пределы игр, то можно применить эту структуру данных в симуляции роботов, датчики которых имеют известные уровни отказа. Например, если датчик дальности имеет 95-процентную вероятность возврата правильного значения, 4-процентную вероятность слишком маленького значения, и 1-процентную вероятность слишком большого значения, то можно использовать эту структуру данных для симуляции считывания показаний датчика генерацией случайного результата и симуляцией считывания датчиком этого результата.