С потерей данных я впервые столкнулся, когда лишился своей коллекции тщательно отредактированных переводов любимой книги во время банальной переустановки ОС. Это было очень давно, однако воспоминания о часах кропотливого труда, потраченного на доведение до ума нескольких миллионов знаков текста до сих пор не дают мне покоя. Тогда ещё не было различных облачных технологий типа дропбокса, поэтому потеря оказалась практически невосполнимой. Конечно, не всё и не всегда так трагично – если сам носитель всё ещё есть в наличии, потерянные данные можно восстановить. Эх, знал бы, где упаду…
Поэтому я решил, что правильнее всего будет посвятить свой первый пост в блоге компании, занимающейся восстановлением данных тому, как эти данные чаще всего теряются. Итак, вашему вниманию представляется топ-20 причин, по которым юзеры обычно остаются без своей драгоценной информации. Даже если вы гуру системного администрирования, например, освежить азы будет не лишним — чтобы соломку подстелить.

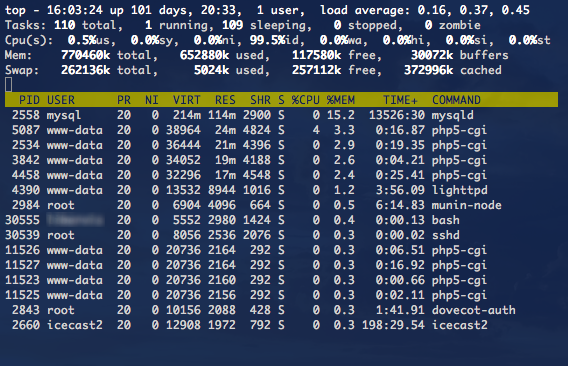
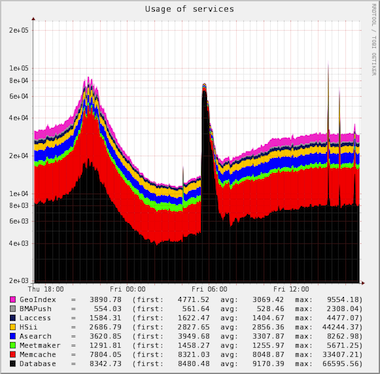 Давайте представим себе типичный, набирающий популярность стартап, использующий, например, PHP или Python. Сначала все находится на одном сервере — PHP (или Python), Apache, MySQL. Затем вы выносите MySQL на отдельный сервер, устанавливаете nginx для раздачи контента, возможно, добавляете memcached для кеширования и еще несколько серверов приложений…
Давайте представим себе типичный, набирающий популярность стартап, использующий, например, PHP или Python. Сначала все находится на одном сервере — PHP (или Python), Apache, MySQL. Затем вы выносите MySQL на отдельный сервер, устанавливаете nginx для раздачи контента, возможно, добавляете memcached для кеширования и еще несколько серверов приложений…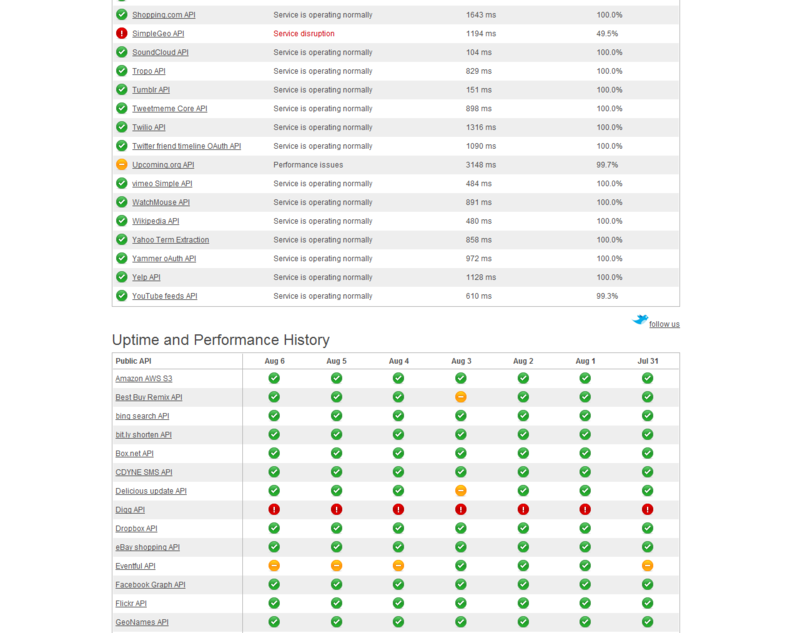



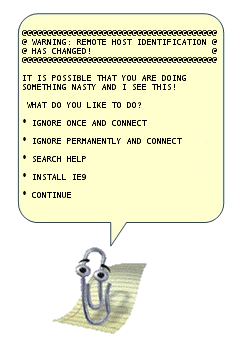 abstract: В статье описаны продвинутые функций OpenSSH, которые позволяют сильно упростить жизнь системным администраторам и программистам, которые не боятся шелла. В отличие от большинства руководств, которые кроме ключей и -L/D/R опций ничего не описывают, я попытался собрать все интересные фичи и удобства, которые с собой несёт ssh.
abstract: В статье описаны продвинутые функций OpenSSH, которые позволяют сильно упростить жизнь системным администраторам и программистам, которые не боятся шелла. В отличие от большинства руководств, которые кроме ключей и -L/D/R опций ничего не описывают, я попытался собрать все интересные фичи и удобства, которые с собой несёт ssh.