
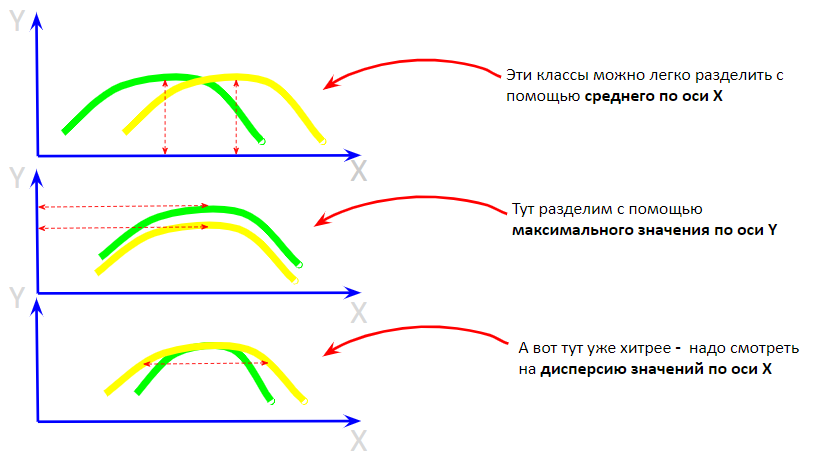
Разберем способы поднять точность модели!
Привет, чемпион! Возможно, перед тобой сейчас стоит задача построить предиктивную модель, или ты просто фармишь Kaggle, и тебе не хватает идей, тогда эта статья будет тебе полезна!
Наверное, уже только ленивый не слышал про Data Science и то, как модели машинного обучения помогают прогнозировать будущее, но самое крутое в анализе данных, на мой взгляд, - это хакатоны! Будь-то Kaggle или локальные соревнования, везде примерно одна задача - получить точность выше, чем у других оппонентов (в идеале еще пригодную для продакшена модель). И тут возникает проблема...



 В мире все примерно распределяется в соответствии с принципом Паретто. Меньшая часть — богатые, большая часть — бедные (читающий, ты входишь в золотой миллиард). Тоже касается и материалов о программировании. Порой очень сложно найти хоть что-нибудь не начального уровня.
В мире все примерно распределяется в соответствии с принципом Паретто. Меньшая часть — богатые, большая часть — бедные (читающий, ты входишь в золотой миллиард). Тоже касается и материалов о программировании. Порой очень сложно найти хоть что-нибудь не начального уровня.

