AntipovSN and MihhaCF
UPD Часть вторая здесь
UPD Часть третья здесь
Часть первая, в которой Граф еще не стал Атосом, не встретил Миледи и все у него хорошо
Вступление от авторов:
Добрый день! Сегодня мы начинаем цикл статей, посвященных скорингу и использованию в оном теории графов (Т.Г.). Надеюсь, нам хватит запала, сил и терпения, т.к. тема достаточно объемная и, на наш взгляд, интересная.
Несмотря на шуточное название, мы постараемся затронуть отнюдь не шуточные темы, которые уже сейчас влияют на жизнь многих из нас, а в ближайшем будущем могут коснуться всех, без исключения.
Все шуточные аллегории, вставки и прочее призваны немного разгрузить повествование и не позволить ему свалиться в нудную лекцию. Всем, кому не зайдет наш юмор, заранее приносим извинения
А теперь к делу.
Цель данной статьи: не более, чем за 30 минут, ввести читателя в проблематику исследования, определить уровень рассмотрения проблемы, описать основную концепцию исследования и познакомить с базовыми терминами.
Термины и определения:
- Скоринг – система бальной оценки объекта, основанная на численных статистических методах.
- Граф – способ моделирования связей объектов. Представьте, что Вы с друзьями играете в покер и хотите смоделировать, кто кому сейчас должен. Например, «Д’Артаньян должен Атосу 10 луидоров»

Полный граф может выглядеть следующим образом:
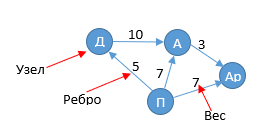
Арамис всегда был хитрож… себе на уме, ему должен даже Атос. Портос, пока не встретил госпожу Кокнар, перевязь не мог себе нормальную купить и умудрился задолжать нищеброду Д’артаньяну, хотя, честно говоря, они всю дорогу что-то мутили вместе…