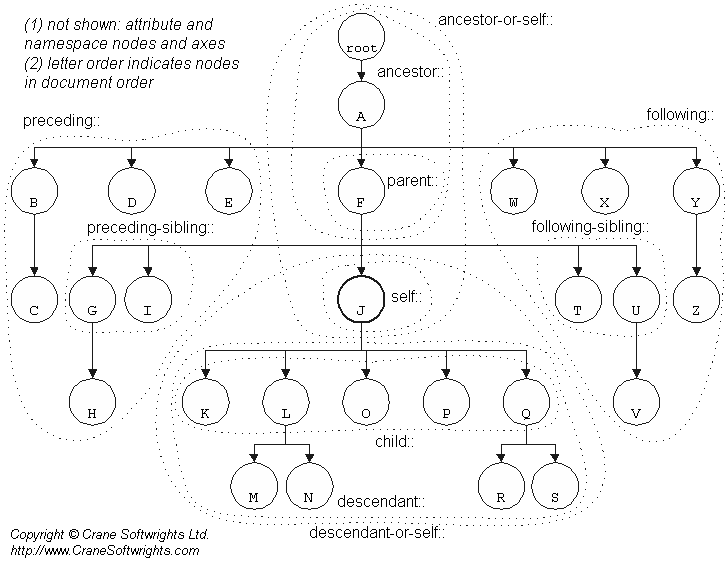
В последнее время стало модным использовать термины «Web-приложение», «front-end-архитектура», «Web 2.0», «HTML5-приложения». Но, к сожалению, в большинстве случаев контекст использования этих терминов не всегда верен, поскольку не учитывает всю специфику реализации и использования архитектуры Web-приложения. Сегодня речь будет идти именно об архитектуре.
Толчком к написанию данной статьи послужила публикация в блоге
http://blog.pamelafox.org/2013/05/frontend-architectures-server-side-html.html. Стоит заметить, что она достаточно сжата и не учитывает возможности конверсии HTML5/Mobile. Здесь же мы попытались рассмотреть архитектуру более подробно, с учетом последних трендов в Web и некоторых ключевых моментов для заказчика приложения (таких, как безопасность).
Для начала мы рассмотрим самые распространенные архитектуры для Web-приложений, их достоинства и недостатки с трех точек зрения: заказчика, разработчика и пользователя. Возможны и другие варианты, но они все равно являются подтипами рассматриваемых архитектур и сводятся к основным трем.
Начнем с определения Web-приложения как такового. Википедия даст нам следующее определение: клиент-серверное приложение, в котором клиентом выступает браузер, а сервером — веб-сервер. Логика веб-приложения распределена между сервером и клиентом, хранение данных осуществляется преимущественно на сервере, а обмен информацией происходит по сети.
Здесь начинается путаница, связанная непосредственно с архитектурой, с помощью которой реализовано Web-приложение. Дело в том, что логика работы приложения может располагаться как на сервере, так и на клиенте. Разные архитектуры по-разному распределяют логику между клиентом и сервером.


 Как и раньше я буду стараться ссылаться на общеизвестные трактовки законов. Я не выражаю своего отношения, моё мнение может не совпадать с опубликованным в тексте.
Как и раньше я буду стараться ссылаться на общеизвестные трактовки законов. Я не выражаю своего отношения, моё мнение может не совпадать с опубликованным в тексте. 
 Я думаю, многие в своей жизни сталкивались с ситуацией, когда у вас под рукой нет MySQL (по разным причинам, например хостер не позволяет), а все-таки иметь что-то подобное, или даже сам MySQL хочется. Теперь у вас есть надежда :)! Я и
Я думаю, многие в своей жизни сталкивались с ситуацией, когда у вас под рукой нет MySQL (по разным причинам, например хостер не позволяет), а все-таки иметь что-то подобное, или даже сам MySQL хочется. Теперь у вас есть надежда :)! Я и 
 От переводчика: Это вторая статья из
От переводчика: Это вторая статья из  От переводчика: Это первая статья из
От переводчика: Это первая статья из