Когда-то давно, в начале 2014 года, я назвал состояние безопасности большинства реализаций UEFI "полумифическим". С тех пор минуло полтора года, дело осторожно двигается с мертвой точки, но до сих пор очень многие производители ПК для конечного пользователя не обращают на эту самую безопасность почти никакого внимания — «пипл хавает».
Когда-то давно, в начале 2014 года, я назвал состояние безопасности большинства реализаций UEFI "полумифическим". С тех пор минуло полтора года, дело осторожно двигается с мертвой точки, но до сих пор очень многие производители ПК для конечного пользователя не обращают на эту самую безопасность почти никакого внимания — «пипл хавает».В этой статье речь пойдет о модели угроз и векторах атаки на UEFI, а также о защитах от перезаписи содержимого микросхемы BIOS — самой разрушительной по возможным последствиям атаки.
Если вам интересно, как устроена защита UEFI и какие именно уязвимости в ней так и остаются неисправленными на большинстве современных систем — добро пожаловать под кат.


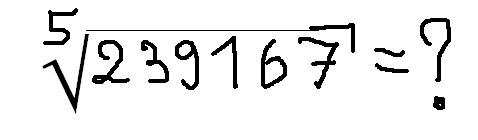


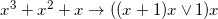 , которая на 6 джаве с выключенным JIT у меня давала около 10% ускорения, при этом на первый взгляд даже не очевидно что эти формулы эквивалентны (ОТКУДА ТУТ OR? ЭТО ВООБЩЕ ЗАКОННО?!), хотя это так. Под катом я расскажу, как именно получались такие результаты и каким образом компьютер придумывал лучший код чем тот, который мог написать я сам.
, которая на 6 джаве с выключенным JIT у меня давала около 10% ускорения, при этом на первый взгляд даже не очевидно что эти формулы эквивалентны (ОТКУДА ТУТ OR? ЭТО ВООБЩЕ ЗАКОННО?!), хотя это так. Под катом я расскажу, как именно получались такие результаты и каким образом компьютер придумывал лучший код чем тот, который мог написать я сам.