Вторая часть заметок об объектной системе python'a (первая часть тут). В этой статье рассказывается, что такое классы, метаклассы, type, object и как происходит поиск атрибутов в классе.

bya @bya
User
Мониторинг выполнения задач в IPython Notebook
2 min
Хотел бы поделиться простым, но полезным инструментом. Когда много работаешь с данными, часто возникают примитивные, но долгие операции, например: «скачать 10 000 урлов», «прочитать файл на 2Гб, и что-то сделать с каждой строчкой», «распарсить 10 000 html-файлов и достать заголовки». Долго смотреть в зависший терминал тревожно, поэтому долгое время я использовал следующий гениальный код: 
Эта функция прекрасна, больше года она кочевала у меня из задачи в задачу. Но недавно я заметил в стандартной поставке Jupyter виджет IntProgress и понял, что пора что-то менять:
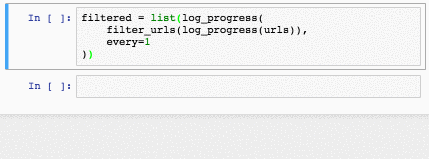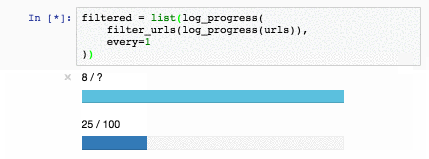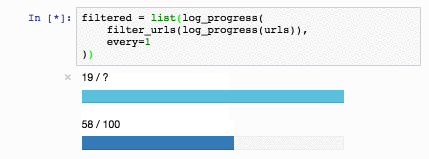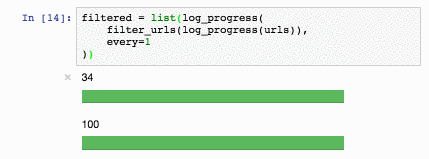
def log_progress(sequence, every=10):
for index, item in enumerate(sequence):
if index % every == 0:
print >>sys.stderr, index,
yield item
Эта функция прекрасна, больше года она кочевала у меня из задачи в задачу. Но недавно я заметил в стандартной поставке Jupyter виджет IntProgress и понял, что пора что-то менять:
Доступ к таблицам из Си расширений для Postgres
8 min
Tutorial

Всем привет!
В этот раз я расскажу не про использование Python или очередной трюк с CSS/HTML и, увы, не про то, как я 5 лет портировал Вангеры, а про один важный аспект написания расширений для замечательной СУБД PostgresSQL.
На самом деле, уже есть достаточно много статей о том, как написать расширение для Postgres на Си (к примеру, эта), в том числе и на русском языке. Но, как правило, в них описываются достаточно простые случаи. В этих статьях и инструкциях авторы реализуют функции, которые получают на вход данные, как-то их обрабатывают, а затем возвращают одно число, строку или пользовательский тип. В них нет пояснений, что делать, если из Си кода нужно пробежаться по обычной таблице, существующей в базе, или индексу.
К таблицам из Си можно получить доступ через хорошо описанный но медленный SPI (Server Programming Interface), также есть очень сложный способ, через буферы, а я расскажу про компромиссный вариант. Под катом я постарался дать примеры кода с подробными пояснениями.
Как защитить свои данные
3 min
Recovery Mode
Рассматривается ситуация, когда злоумышленники (доброумышленники) могут заполучить Ваш сервер для подробного изучения.
Основная идея
- Поставить хорошее шифрование на физические тома.
- Включение нужных сервисов через сеть.
- Самое слабое звено человек, и хорошо если тот, кто знает пароли находится далеко от сервера, например в другой стране.
- Изучение винчестеров должно показать обычную систему, т.е. ничего и еще большой не отформатированный кусок винчестера.
Тройки Хоара
11 min
Tutorial
Recovery Mode
Я больше 15 лет при программировании использую логику Хоара и нахожу этот подход очень полезным и хочу поделится опытом. Естественно не надо «стрелять из пушки по воробьям», но при написании достаточно сложных алгоритмов или нетривиальных кусков кода применение логики Хоара сэкономит Ваше время и позволит внести элементы некоторого «промышленного» стандарта при программировании.
Hash array mapped trie
5 min
Hash array mapped trie — это ассоциативный контейнер, который обладает свойствами хэш таблиц и trie. Операции вставки пары ключ-значение и поиск по ключу — О(1) операции.
Про trie на хабре уже писали.
Про trie на хабре уже писали.
Как работает реляционная БД
51 min
Tutorial
Translation
 Реляционные базы данных (РБД) используются повсюду. Они бывают самых разных видов, от маленьких и полезных SQLite до мощных Teradata. Но в то же время существует очень немного статей, объясняющих принцип действия и устройство реляционных баз данных. Да и те, что есть — довольно поверхностные, без особых подробностей. Зато по более «модным» направлениям (большие данные, NoSQL или JS) написано гораздо больше статей, причём куда более глубоких. Вероятно, такая ситуация сложилась из-за того, что реляционные БД — вещь «старая» и слишком скучная, чтобы разбирать её вне университетских программ, исследовательских работ и книг.
Реляционные базы данных (РБД) используются повсюду. Они бывают самых разных видов, от маленьких и полезных SQLite до мощных Teradata. Но в то же время существует очень немного статей, объясняющих принцип действия и устройство реляционных баз данных. Да и те, что есть — довольно поверхностные, без особых подробностей. Зато по более «модным» направлениям (большие данные, NoSQL или JS) написано гораздо больше статей, причём куда более глубоких. Вероятно, такая ситуация сложилась из-за того, что реляционные БД — вещь «старая» и слишком скучная, чтобы разбирать её вне университетских программ, исследовательских работ и книг.На самом деле, мало кто действительно понимает, как работают реляционные БД. А многие разработчики очень не любят, когда они чего-то не понимают. Если реляционные БД используют порядка 40 лет, значит тому есть причина. РБД — штука очень интересная, поскольку в ее основе лежат полезные и широко используемые понятия. Если вы хотели бы разобраться в том, как работают РБД, то эта статья для вас.
Способ написания синтаксических анализаторов на c++
11 min
В этой статье рассказывается, как писать синтаксические анализаторы с помощью этой небольшой библиотеки на с++.
Обычно, текст на машинном языке состоит из предложений, те — из подпредложений, а те, в свою очередь, из подподпредложений, и так вплоть до символов.
Например, элемент xml состоит из открывающего тега, содержимого и закрывающего тега. —> Открывающий тег состоит из '<', имени тега, возможно пустого списка атрибутов и '>'. —> Закрывающий тег состоит из '</', имени тега и '>'. —> Атрибут состоит из имени, знаков '=', '"', строки символов и снова '"'. —> Содержимое в свою очередь тоже может содержать элементы. —> И т.д. Таким образом, после разбора получается синтаксическое дерево.
Такие языки удобно описывать формой Бэкуса-Наура (БНФ), где каждый нетерминал соответствует некоторому предложению языка. Когда мы пишем программы, мы обычно разбиваем их на функции и подфункции, и раз мы собрались писать синтаксический анализатор, пусть каждому нетерминалу БНФ соответствует одна функция нашего анализатора, и пусть каждая такая функция:
Например для БНФ вида
Обычно, текст на машинном языке состоит из предложений, те — из подпредложений, а те, в свою очередь, из подподпредложений, и так вплоть до символов.
Например, элемент xml состоит из открывающего тега, содержимого и закрывающего тега. —> Открывающий тег состоит из '<', имени тега, возможно пустого списка атрибутов и '>'. —> Закрывающий тег состоит из '</', имени тега и '>'. —> Атрибут состоит из имени, знаков '=', '"', строки символов и снова '"'. —> Содержимое в свою очередь тоже может содержать элементы. —> И т.д. Таким образом, после разбора получается синтаксическое дерево.
Такие языки удобно описывать формой Бэкуса-Наура (БНФ), где каждый нетерминал соответствует некоторому предложению языка. Когда мы пишем программы, мы обычно разбиваем их на функции и подфункции, и раз мы собрались писать синтаксический анализатор, пусть каждому нетерминалу БНФ соответствует одна функция нашего анализатора, и пусть каждая такая функция:
- пытается разобрать это предложение с заданной позиции
- возвращает, удалось ли ей это сделать
- возвращает позицию, где закончился разбор или произошла ошибка
- а также, возможно, возвращает некоторые дополнительные данные, которые мы хотим получить в результате разбора
Например для БНФ вида
expr ::= expr1 expr2 expr3 будем писать такую функцию:Фурье-вычисления для сравнения изображений
10 min
Традиционная техника “начального уровня”, сравнения текущего изображения с эталоном основывается на рассмотрении изображений как двумерных функций яркости (дискретных двумерных матриц интенсивности). При этом измеряется либо расстояние между изображениями, либо мера их близости.
Как правило, для вычисления расстояний между изображениями используется формула, являющаяся суммой модулей или квадратов разностей интенсивности:
Если помимо простого сравнения двух изображений требуется решить задачу обнаружения позиции фрагмента одного изображения в другом, то классический метод “начального уровня”, заключающийся в переборе всех координат и вычисления расстояния по указанной формуле, как правило, терпит неудачу практического использования из-за требуемого большого количества вычислений.
Одним из методов, позволяющих значительно сократить количество вычислений, является применение Фурье преобразований и дискретных Фурье преобразований для расчёта меры совпадения двух изображений при различных смещениях их между собой. Вычисления при этом происходят одновременно для различных комбинаций сдвигов изображений относительно друг друга.
Наличие большого числа библиотек, реализующих Фурье преобразований (во всевозможных вариантах быстрых версий), делает реализацию алгоритмов сравнения изображений не очень сложной задачей для программирования.
Как правило, для вычисления расстояний между изображениями используется формула, являющаяся суммой модулей или квадратов разностей интенсивности:
d(X,Y) = SUM ( X[i,j] — Y[i,j] )^2
Если помимо простого сравнения двух изображений требуется решить задачу обнаружения позиции фрагмента одного изображения в другом, то классический метод “начального уровня”, заключающийся в переборе всех координат и вычисления расстояния по указанной формуле, как правило, терпит неудачу практического использования из-за требуемого большого количества вычислений.
Одним из методов, позволяющих значительно сократить количество вычислений, является применение Фурье преобразований и дискретных Фурье преобразований для расчёта меры совпадения двух изображений при различных смещениях их между собой. Вычисления при этом происходят одновременно для различных комбинаций сдвигов изображений относительно друг друга.
Наличие большого числа библиотек, реализующих Фурье преобразований (во всевозможных вариантах быстрых версий), делает реализацию алгоритмов сравнения изображений не очень сложной задачей для программирования.
Maple: составление уравнений Лагранжа 2 рода и метод избыточных координат
9 min
Предисловие
По роду профессиональной и научной деятельности я механик. Преподаю теоретическую механику в университете, пишу докторскую диссертацию в области динамики подвижного состава железных дорог. В общем, эта наука поглощает большую часть моего рабочего и даже свободного времени.
С Maple (на кафедре была 6-я версия, а у лоточников домой была куплена 8-я) познакомился ещё студентом, когда начинал работать над будущей кандидатской под крылом моего первого (ныше покойного) научного руководителя. Были и добрые люди, что помогли на самом первом этапе разобраться с пакетом и начать работать.
И вот так постепенно на его плечи была переложена большая часть вычислительной работы по подготовке диссертации. Диссертация была защищена, а Maple навсегда остался надёжным помошником в научном труде. Часто бывает необходимо быстро оценить какую-нибудь задачу, составить уравнения, исследовать их аналитически, быстро получить численное решение, построить графики. В этом отношении Maple просто незаменим для меня (ни в коем разе не хочу обидеть приверженцев других пакетов).
Сделать всё то, что будет предложено читателю под катом, меня подвигла задача принесенная ученицей (приходится ещё заниматься и репетиторством) со школьной олимпиады. Условие задачи таково:
Груз, висящий на нити длины L = 1,1 м, привязанной к гвоздю, толкнули так, что он поднялся, а затем ударился в гвоздь. Какова его скорость в момент удара о гвоздь? Ускорение свободного падения g = 10 м/с2.
Если не придираться к некоторонной туманности условия, то задача достаточно проста, а её решение, полученное путем довольно громоздких для школьника выкладок, в общем виде дает результат

И вот тут захотелось проверить решение, полученное с оглядкой на школьную программу по физике независимым способом, например составив дифференциальные уравнения движения этого маятника, да не просто, а с учетом освобождения от связи (в процессе движения нить, считаемая невесомой, провисает и маятник движется как свободная точка).
Это послужило катализатором для того, чтобы взять да и откопать свои старые задумки, накопленные ещё со времен работы в оргкомитете Всероссийской Олимпиады студентов по теоретической механике — три года подряд занимался там подготовкой задач компьютерного конкурса. Задумки касались автоматизации построения уравнений движений для механических систем с неудерживающими связями и трением, используя известные всем уравнения Лагранжа 2 рода
 - \frac{\partial T}{\partial q_i} = Q_i, \quad i=\overline{1,s}")
поборов стереотип многих преподавателей о том, что уравнения эти неприменимы к системам с неудерживающими связями и трением.
Что касается Maple, то его библиотека для решения задач вариационного исчисления дает возможность быстро получить уравнения Эйлера-Лагранжа, решение которых минимизирует действие по Гамильтону, что применимо для консервативных систем
 - \frac{\partial L}{\partial q_i} = 0, \quad i=\overline{1,s}")
где
 — функция Лагранжа, равная разности кинетической и потенциальной энергий системы.
— функция Лагранжа, равная разности кинетической и потенциальной энергий системы. Так как расматриваемые задачи не относятся к классу консервативных, то автором была предпринята попытка самостоятельно реализовать автоматизацию построения и анализа уравнений движений. Что из этого вышло, изложено под катом
Готовим к публикации пост с формулами
2 min
В последнее время на хабре появилось много постов с математическими формулами. Например, нельзя не вспомнить серию статей maisvendoo о теоретической механике.
В связи с этим стал актуальным вопрос о выборе удобного инструмента для создания и подготовки таких постов. SeptiM предложил скрипт, преобразующий маркдаун-разметку + латех в html-код. Я решил развить идею и упростить инструмент, и сделал для этих же целей онлайн-редактор с поддержкой латеха и маркдауна:
Глобалы — мечи-кладенцы для хранения данных. Деревья. Часть 2
8 min
 Начало — см. часть 1.
Начало — см. часть 1.3. Варианты структур при использовании глобалов
Такая структура как упорядоченное дерево имеет разные частные случаи. Рассмотрим те, которые имеют практическую ценность при работе с глобалами.
3.1 Частный случай 1. Один узел без ветвей
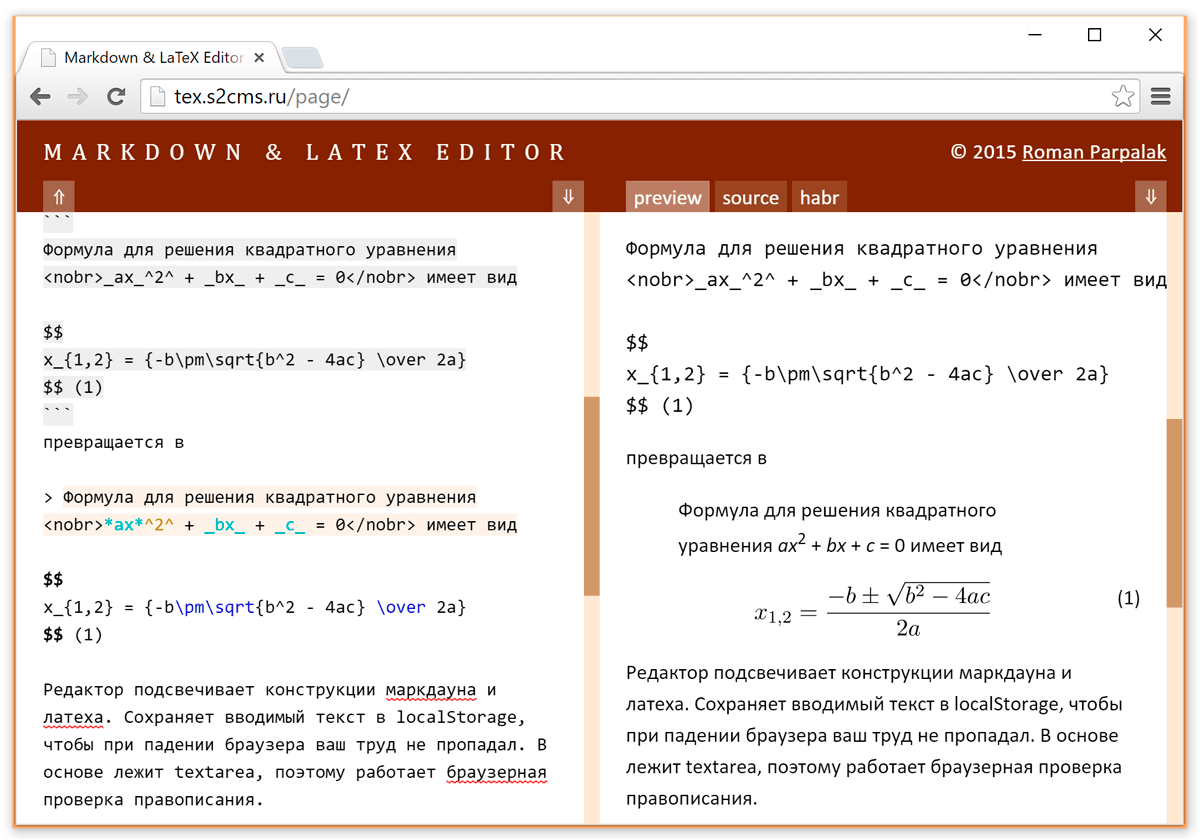
Как написать пост с формулами: markdown + LaTeX
3 min
Tutorial
Привет! На Хабре периодически появляются статьи, где авторы хотят вставить математические формулы:  ,
,  или даже
или даже

У некоторых это получается, у некоторых — с трудом. parpalak сделал web-сервис для вставки svg формул, и это очень круто. Я хочу дополнить его небольшим скриптом, с которым вставка многих формул сведется к одной команде.

У некоторых это получается, у некоторых — с трудом. parpalak сделал web-сервис для вставки svg формул, и это очень круто. Я хочу дополнить его небольшим скриптом, с которым вставка многих формул сведется к одной команде.
Qt: шаблон для корректной работы с потоками
13 min
Всем хабрапривет!
Как-то понадобилось мне в Qt 5.1.1 для WinXP в VS2009 реализовать многопоточное приложение с интенсивным обменом сигналами. Взял я Шлее, вычитал у него, что нужно унаследовать класс от QThread и — вуаля, велком в многопоточность! На всякий случай заглянул в документацию Qt — там никто не возражал против наследования от QThread своего класса. Ну что же — порядок, сделано! Запускаю — вроде как работает, но как-то не так… Начинаю в режиме отладки отслеживать — а там творится черт знает что! То сигналы не выходят, то выходят, но как-то криво и из другого потока. Одним словом, полный бардак! Пришлось основательно по-google-ить и разобраться в теме (мне помогли статьи тут, здесь и там). В итоге я сделал шаблон класса на С++ (вернее, целую иерархию оных), что мне позволило в итоге писать (относительно) небольшой код класса, живущего в другом потоке, который работает правильно и стабильно.
Upd: в комментариях мне подсказали более качественный подход — я его описал в новой статье.
Как-то понадобилось мне в Qt 5.1.1 для WinXP в VS2009 реализовать многопоточное приложение с интенсивным обменом сигналами. Взял я Шлее, вычитал у него, что нужно унаследовать класс от QThread и — вуаля, велком в многопоточность! На всякий случай заглянул в документацию Qt — там никто не возражал против наследования от QThread своего класса. Ну что же — порядок, сделано! Запускаю — вроде как работает, но как-то не так… Начинаю в режиме отладки отслеживать — а там творится черт знает что! То сигналы не выходят, то выходят, но как-то криво и из другого потока. Одним словом, полный бардак! Пришлось основательно по-google-ить и разобраться в теме (мне помогли статьи тут, здесь и там). В итоге я сделал шаблон класса на С++ (вернее, целую иерархию оных), что мне позволило в итоге писать (относительно) небольшой код класса, живущего в другом потоке, который работает правильно и стабильно.
Upd: в комментариях мне подсказали более качественный подход — я его описал в новой статье.
9 анти-паттернов, о которых должен знать каждый программист
9 min
Translation
В программировании самокритика – это умение распознать контрпродуктивные решения в дизайне, коде, процессах и поведении. Знание о вредных шаблонах решений полезно для программиста. В этой статье я опишу анти-паттерны, которые я встречал на своём личном опыте время от времени.
Некоторые из них напрямую или косвенно связаны с когнитивными искажениями человеческого сознания – в этих случаях я даю ссылки на соответствующие вики-статьи. Также интересен список известных когнитивных искажений.
Оптимизация, проводимая до того, как у вас есть вся информация, необходимая для принятия взвешенных решений по поводу того, где и как нужно её проводить.
На практике сложно предсказать, где встретится узкое место. Попытки навести оптимизацию до получения эмпирических результатов приведут к усложнению кода и появлению ошибок, а пользы не принесут.
Сначала пишите чистый, читаемый, работающий код, используя известные и проверенные алгоритмы и инструменты. При необходимости используйте инструменты для профилирования для поиска узких мест. Полагайтесь на измерения, а не на догадки и предположения.
Некоторые из них напрямую или косвенно связаны с когнитивными искажениями человеческого сознания – в этих случаях я даю ссылки на соответствующие вики-статьи. Также интересен список известных когнитивных искажений.
1 Преждевременная оптимизация
В 97% случаев надо забыть об эффективности малых частей программы: преждевременная оптимизация – корень всех зол. Но в 3% случаев об оптимизации забывать не нужно.
Дональд Кнут
Хотя никогда зачастую лучше, чем прямо сейчас
Тим Питерс, Зен языка Python
Что это
Оптимизация, проводимая до того, как у вас есть вся информация, необходимая для принятия взвешенных решений по поводу того, где и как нужно её проводить.
Почему плохо
На практике сложно предсказать, где встретится узкое место. Попытки навести оптимизацию до получения эмпирических результатов приведут к усложнению кода и появлению ошибок, а пользы не принесут.
Как избежать
Сначала пишите чистый, читаемый, работающий код, используя известные и проверенные алгоритмы и инструменты. При необходимости используйте инструменты для профилирования для поиска узких мест. Полагайтесь на измерения, а не на догадки и предположения.
Пишем SSL туннель на python
6 min
Возникла задача: есть приложение под Windows, которое делает HTTPS-запросы к серверу и получает ответы. После обновления сервера приложение перестало работать. Выяснилось, что на сервере изменилась версия SSL (перешли с SSLv3 на TLSv1), а наше приложение умеет работать только по SSLv3. Приложение никто не поддерживает уже давно и менять, перекомпилировать, тестировать не хотелось. Решено было сделать прослойку между приложением и сервером, которая будет транслировать SSLv3 в TLSv1 и наоборот. Я поискал какой-нибудь прокси в интернете, но сходу не нашел (плохо искал). Решил сделать прокси на питоне. Я не профессионал в питоне, но мне показалось что для этой задачи он хорошо подходит, и интересно параллельно по изучать питон на примере реальной задачи.
Введение в функциональное программирование на Python
10 min
Translation
Рассуждая о функциональном программировании, люди часто начинают выдавать кучу «функциональных» характеристик. Неизменяемые данные, функции первого класса и оптимизация хвостовой рекурсии. Это свойства языка, помогающие писать функциональные программы. Они упоминают мапирование, каррирование и использование функций высшего порядка. Это приёмы программирования, использующиеся для написания функционального кода. Они упоминают распараллеливание, ленивые вычисления и детерменизм. Это преимущества функциональных программ.
Забейте. Функциональный код отличается одним свойством: отсутствием побочных эффектов. Он не полагается на данные вне текущей функции, и не меняет данные, находящиеся вне функции. Все остальные «свойства» можно вывести из этого.
Нефункциональная функция:
Функциональная функция:
Вместо проходов по списку используйте map и reduce
Забейте. Функциональный код отличается одним свойством: отсутствием побочных эффектов. Он не полагается на данные вне текущей функции, и не меняет данные, находящиеся вне функции. Все остальные «свойства» можно вывести из этого.
Нефункциональная функция:
a = 0
def increment1():
global a
a += 1
Функциональная функция:
def increment2(a):
return a + 1
Вместо проходов по списку используйте map и reduce
Построение диаграмм и графов в Doxygen
9 min
Данная статья входит в получившийся цикл статей о системе документирования Doxygen:
- Документируем код эффективно при помощи Doxygen
- Оформление документации в Doxygen
- Построение диаграмм и графов в Doxygen
Она завершает цикл статей о системе документации Doxygen. На этот раз статья посвящена построению различных диаграмм и графов в Doxygen. В ней мы рассмотрим основные их виды, различные способы их настройки и оформления, а также приведём ряд примеров и советов по их использованию.
Лекции Технопарка. 1 семестр. С/С++
6 min
Tutorial
Мы продолжаем наши еженедельные публикации учебных материалов Технопарка. Предыдущие лекции были посвящены web-технологиям в целом, а также алгоритмам и структурам данных. В третьем блоке лекций рассказывается о языках С и С++.
Лекция начинается с введения в язык С: рассказывается об истории его появления, особенностях, преимуществах и недостатках, о сферах применения. Описываются основы препроцессорной обработки, рассматриваются вопросы управления памятью (модели управления памятью, области видимости объектов хранения) и производительность программ на языке С. Обсуждается связывание объектов хранения и их инициализация. Затем рассказывается о классах памяти в языке С. Следующая часть лекции посвящена проблематике указателей, а также работе с одномерными массивами. В заключение рассматривается стандарт POSIX и вопросы переносимости.
Лекция 1. Язык С. Основы организации и использования оперативной и сверхоперативной памяти
Лекция начинается с введения в язык С: рассказывается об истории его появления, особенностях, преимуществах и недостатках, о сферах применения. Описываются основы препроцессорной обработки, рассматриваются вопросы управления памятью (модели управления памятью, области видимости объектов хранения) и производительность программ на языке С. Обсуждается связывание объектов хранения и их инициализация. Затем рассказывается о классах памяти в языке С. Следующая часть лекции посвящена проблематике указателей, а также работе с одномерными массивами. В заключение рассматривается стандарт POSIX и вопросы переносимости.
Арифметика с контролем диапазонов в Haskell с помощью Type-Level Literals
6 min
Функциональное программирование (ФП), как известно, способствует написанию надёжного (безошибочного) кода.
Ясно, что это максима. Программ без ошибок не бывает. Однако ФП в сочетании со строгой статической типизацией и развитостью системы типов позволяет, в значительной степени, выявлять неизбежные ошибки программиста ещё на стадии компиляции. Я говорю о Haskell, хотя, наверное, к OCaml это тоже относится.
Однако если мы зададимся целью написания надёжного кода, то немедленно обнаружим, что возможности Haskell тут не безграничны. Не всё, что существует для этой цели (построения безопасного кода) в других языках легко реализуется на Haskell. Хорошо бы меня тут поправили, но, увы.
Ясно, что это максима. Программ без ошибок не бывает. Однако ФП в сочетании со строгой статической типизацией и развитостью системы типов позволяет, в значительной степени, выявлять неизбежные ошибки программиста ещё на стадии компиляции. Я говорю о Haskell, хотя, наверное, к OCaml это тоже относится.
Однако если мы зададимся целью написания надёжного кода, то немедленно обнаружим, что возможности Haskell тут не безграничны. Не всё, что существует для этой цели (построения безопасного кода) в других языках легко реализуется на Haskell. Хорошо бы меня тут поправили, но, увы.